大家好,又见面了,我是你们的朋友全栈君。
深度优先搜索是图的遍历的一种重要方法,在一些网络拓补结构、DNA 网络等复杂图形分析中有很广泛的应用。传统的深度优先搜索,从某一节点开始,依次遍历此节点所有相邻且未被访问的节点,其下一跳节点的选择往往不是最优的。文章通过对当前节点所有未被访问的下一跳节点计算其到所有未访问节点路径总和,选择最优的一个节点作为下一跳节点,使得深度优先搜索在图的遍历过程中总的搜索路径大大减少。
深度优先搜索算法对图的遍历分析
图的遍历是指从图的某个节点开始,沿着某条路径对图中所有节点依次访问。解决图的遍历问题,目前主要有两种算法,广度优先搜索算法和深度优先搜索算法。
深度优先搜索算法基本思想为,首先从图中某个节点 出发, 然后依次从 相邻的节点出发深度优先遍
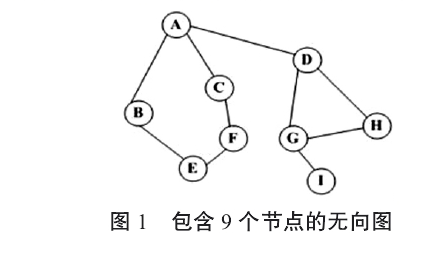
历,直至图中所有与 路径想通的节点都被访问。若此时尚有节点未被访问,则从中选一个节点作为起点,重复上述过程,直到所有的顶点都被访问。在传统的深度优先搜索算法中,若某个节点包含多个未被访问的节点,一般按照节点编号从小到大依次选择节点作为下一跳节点,算法中对下一跳节点的选择做出的判断往往不是最优的,这就导致了当遍历完所有节点时,总的路径不是最短的。如图 1 为包含 9个节点的无向图。假设从 A 点出发,按照深度优先搜索算法会包含如下两条路径选择,如果每两个联通节点的距离权值为 1,明显可以看出,路径 2 遍历完所有节点花费的代价较小。出现上述问题的原因在于每次节点对相邻未访问节点的选择不同所造成的。
A->D->G->I->G->H->D->A->C->F->E->B(1)
A->B->E->F->C->A->D->H->G->I (2)

优化
为了解决 DFS 在图的遍历问题中,由于下一跳节点的选择所带来的路径非最优问题,本文提出了一种下一跳节点选择策略,可以有效的缩短搜索总路径,提高搜索效率。主要思想及过程如下,从图的某一顶点开始遍历,对于该顶点下所有未被访问的子节点,分别计算每个节点到图中剩余未被访问的节点路径总和,选择路径总和最大的节点作为下一跳节点;若该顶点下所有节点都被访过,则计算所有被访问的节点,到剩余未被访问的节点距离总和,选择距离总和最小的节点作为下一跳节点。
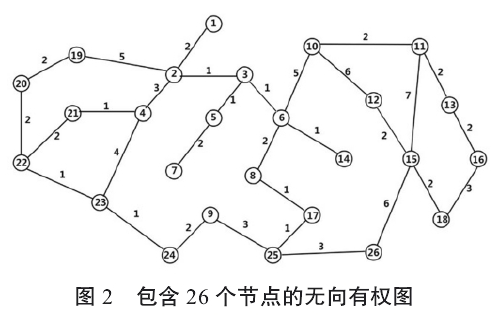
为了验证算法的有效性,选择一个包含 26 个节点的无向有权图进行验证,如图 2 所示,分别计算优化前后的两种路径,一种默认使用小节点编号作为下一跳节点,另一种使用本文介绍的下一跳节点选择策略。假定起始点为 22 号节点,结果如下
[22, 20, 19, 2, 1, 2, 4, 23, 24, 9, 25, 26, 15, 18,16, 13, 11, 10, 12, 15, 26, 25, 17, 8, 6, 14, 6, 3, 5, 7, 5,3, 2, 4, 21]
[22, 20, 19, 2, 1, 2, 3, 5, 7, 5, 3, 6, 10, 11, 13, 16,18, 15, 12, 15, 26, 25, 9, 24, 23, 4, 21, 4, 23, 24, 9, 25,17, 8, 17, 25, 26, 15, 18, 16, 13, 11, 15, 11, 10, 12, 10,6, 14, 6, 6, 3, 2, 2, 19, 20, 22]
从计算结果可以看出使用本文提出的优化策略,需要 35 步完成所有节点的遍历,而未进行优化遍历整个图需要 57 步。搜索效率有了明显的提高。图 2 包含 26 个节点的无向有权图
DFS 作为图的遍历的一种比较成熟的算法,在图的遍历下一跳节点选择的过程中,如果不对节点选择进行策略优化,往往会使最终遍历的总路径增加,使搜索效率下降,速度变慢,本文在 DFS 的基础上,通过对未访问节点计算其到剩余未访问节点距离之和,选取最大值作为下一跳节点,较大的缩减了图的遍历总路径,提高了搜索效率。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/131992.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
