大家好,又见面了,我是你们的朋友全栈君。
https://www.cnblogs.com/the-wolf-sky/articles/10192363.html
https://blog.csdn.net/weixin_37947156/article/details/83146141
基于神经网络的表示一般称为词向量、词嵌入(word embdding)或分布式表示。
神经网络的词向量和其他分布式类似,都基于分布式表达方式,核心依然是上下文的表示以及上下文与目标词之间的关系映射。主要通过神经网络对上下文,以及上下文和目标词之间的关系进行建模,之所以神经网络可以进行建模,主要是由于神经网络的空间非常大,所以这种方法可以表达复杂的上下文关系。
- 词向量
nlp中最常见的第一步是创建一个词表库并把每个词顺序编号,one-hot表达就是一种。这种方法把每个词顺序编号,但每个词就变成一个很长的向量,向量的维度就是词表的大小,只有对应位置上的数字为1,其他都为0。这种方式的弊病是很显然的,就是无法捕捉到词与词之间的相似度,也称为“语义鸿沟“。one-hot的基本假设是词与词之间的语义和语法关系是相互独立的,仅仅靠两个向量是无法看出两个词之间的关系的。其次,维度爆炸问题也是one-hot表达方法的很大的一个问题,随着词典的规模的增大,句子构成的词袋模型的维度变得越来越大,矩阵也变得越稀疏。所以此时构建上下文与目标词之间的关系,最为理想的方式是使用语言模型。
分布式表示的基本细想是通过训练将每个词映射成k维实数向量(k一般为模型中的超参数),然后通过词之间的距离来判断它们之间的语义相似度。而word2vec使用的就是这种分布式表示的词向量表示方式。
- 词向量模型
词向量模型是基于假设:衡量词之间的相似性,在于其相邻词汇是否相识,这是基于语言学的“距离相似性“原理。词汇和它的上下文构成一个象,当从语料库当中学习到相识或相近的象时,他们在语义上总是相识的。
而典型的就是word2vec了,它可以分为CBOW(continuous bag-of-words 连续的词袋模型)和skip-gram两种。word2vec通过训练,可以把对文本内容的处理简化为k维向量空间中的向量运算,而向量空间上的相似度可以用来表示文本语义上的相似度,因此word2vec输出的词向量是一个基础性的工作,比如聚类、同义词、词性分析等。还有一个word2vec被广泛使用的原因是其向量的加法组合和高效性。
2.1 NNLM模型
关于该模型的介绍可以参考:https://blog.csdn.net/lilong117194/article/details/82018008
这里需要注意的是整个网络分为两部分:
第一部分是利用词特征矩阵C获得词的分布式表示(即词嵌入)。
第二部分是将表示context的n个词的词嵌入拼接起来,通过一个隐藏层和一个输出层,最后通过softmax输出当前的p(wt|context)(当前上下文语义的概率分布,最大化要预测的那个词的概率,就可以训练此模型)。
第一部分词嵌入的获取如下图所示:
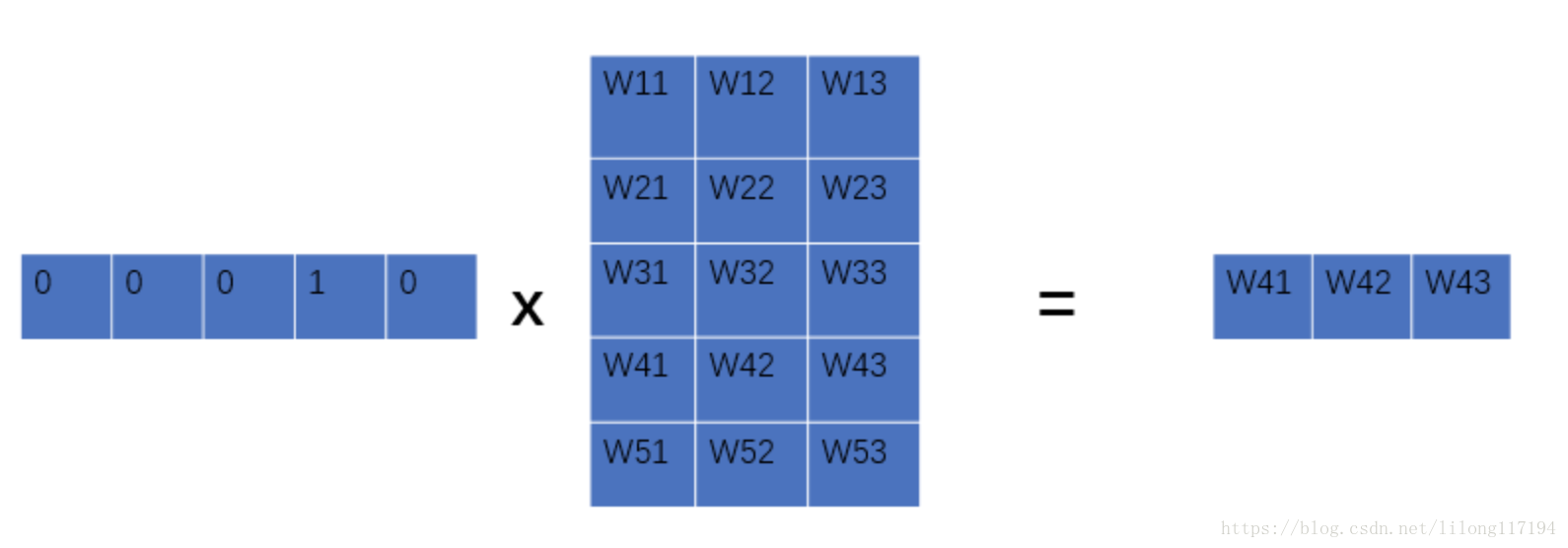

这里可以看到最初的输如其实是词的one-hot表示,而这里的中间的w矩阵就是c矩阵。
其中第i行对应的是one-hot表示中第i项为1的词向量的词嵌入。词向量与矩阵相乘后就可以得到自己的词嵌入了。由于C是神经网络的参数,所以词的词嵌入会随着模型的训练不断得到优化。
在网络的第二部分中,表示context的n个词嵌入通过隐藏层进行语义组合,最后经过输出层使用softmax输出预测的词向量,因为本模型是基于n-gram模型,所以只要最大化正确预测当前词即可。最后不但训练了一个用神经网络表示的语言模型,而且还获得了词语的词嵌入(存在矩阵C中)
从第二部分的输入到输出层有一个直连边,一般情况下该直连边的权重矩阵可以设为0,在最后的实验中,Bengio 发现直连边虽然不能提升模型效果,但是可以少一半的迭代次数。同时他也猜想如果没有直连边,可能可以生成更好的词向量。
nnlm模型的其他细节可以参考上面的连接。
2.2 C&W模型
首先要明确:nnlm模型的目标是构建一个语言概率模型,而C&W模型则是以生成词向量为目的模型。
在nnlm中最废时间的是隐藏层到输出层的权重计算。由于C&W模型没有采用语言模型的方式求解词语上下文的条件概率,而是直接对n元短语打分,这是一种更快速获取词向量的方式。
而其简单来讲就是:如果n元短语在语料库中出现过,那么模型会给该短语打高分;如果是未出现在语料库中的短语则会得到较低的评分。
优化的目标函数是:∑(w,c)∈D∑w′∈Vmax(0,1−score(w,c)+score(w′,c))∑(w,c)∈D∑w′∈Vmax(0,1−score(w,c)+score(w′,c))
其中(w,c)(w,c)为 语料库中抽取的n元短语,为保证上下文词数的一致性,n为奇数。
其中ww是目标词,c是目标词的上下文语境
其中w′w′是从词典中随机抽取的一个词语。
C&W模型采用的是成对的词语方式对目标函数进行优化。这里(w,c)表示正样本,(w’,c)表示负样本,负样本是将正样本序列中的中间词替换为其他词得到的。一般而言,如果用一个随机的词语替代正确文本序列的中间词,得到的新的文本序列基本上都是不符合语法习惯的错误序列,这种构造负样本的方法是合理的。同时由于负样本仅仅修改了正样本的一个词得到的,故其基本的语境没有改变,因此不会对分类效果造成太大的影响。
与nnlm模型的目标词所在输出层不同,C&W模型的输入层就包含了目标词,其输出层也变为了一个节点,该节点输出值的大小就代表n元短语的打分高低。相应的,C&W模型的最后一层运算次数是|h|,远低于nnlm的|v|x|h|次。
C&W模型设计了2个网络来完成词性标注 (POS)、短语识别(CHUNK)、命名实体识别(NER) 和语义角色标注 (SRL)这些nlp任务。其中一个模型叫window approach,另一个叫sentence approach。其中词嵌入的预训练用的是window approach,只是把输出层的神经原个数改成了1个,window approach网络结构见下图
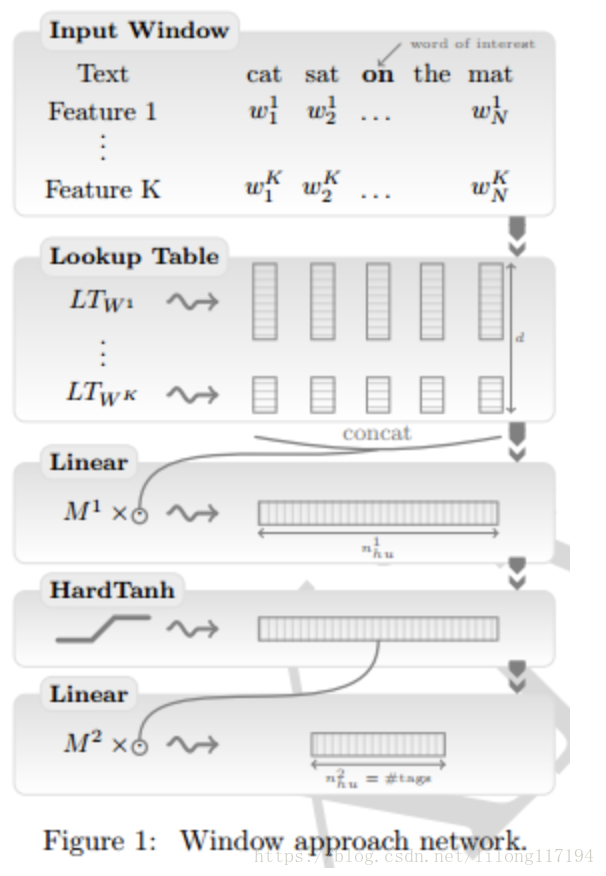
其中,窗口大小为n,中心的那个词为中心词,上下文各(n-1)/2个词。作者利用该模型以无监督的方法预训练词嵌入来提高在具体工作上的效果,最后的输出层只有一个神经元,表示该中心词与上下文语义关联程度的得分。得分高则说明该中心词在当前位置是符合上下文语义的,得分低则说明该中心词在当前位置不符合上下文语义。
2.3 CBOW模型
上面说多的nnlm模型以训练语言模型为目标,同时得到了词表示。而word2vec包含了CBOW和Skip-gram两个得到词向量为目标的模型。
这里要注意的地方是:CBOW和Skip-gram模型当中,目标词wtwt是一个词串联的词,也即是该词是在一句话的中间某个词,并拥有上下文。而nnlm的wtwt是最后一个词,并作为要预测的词。
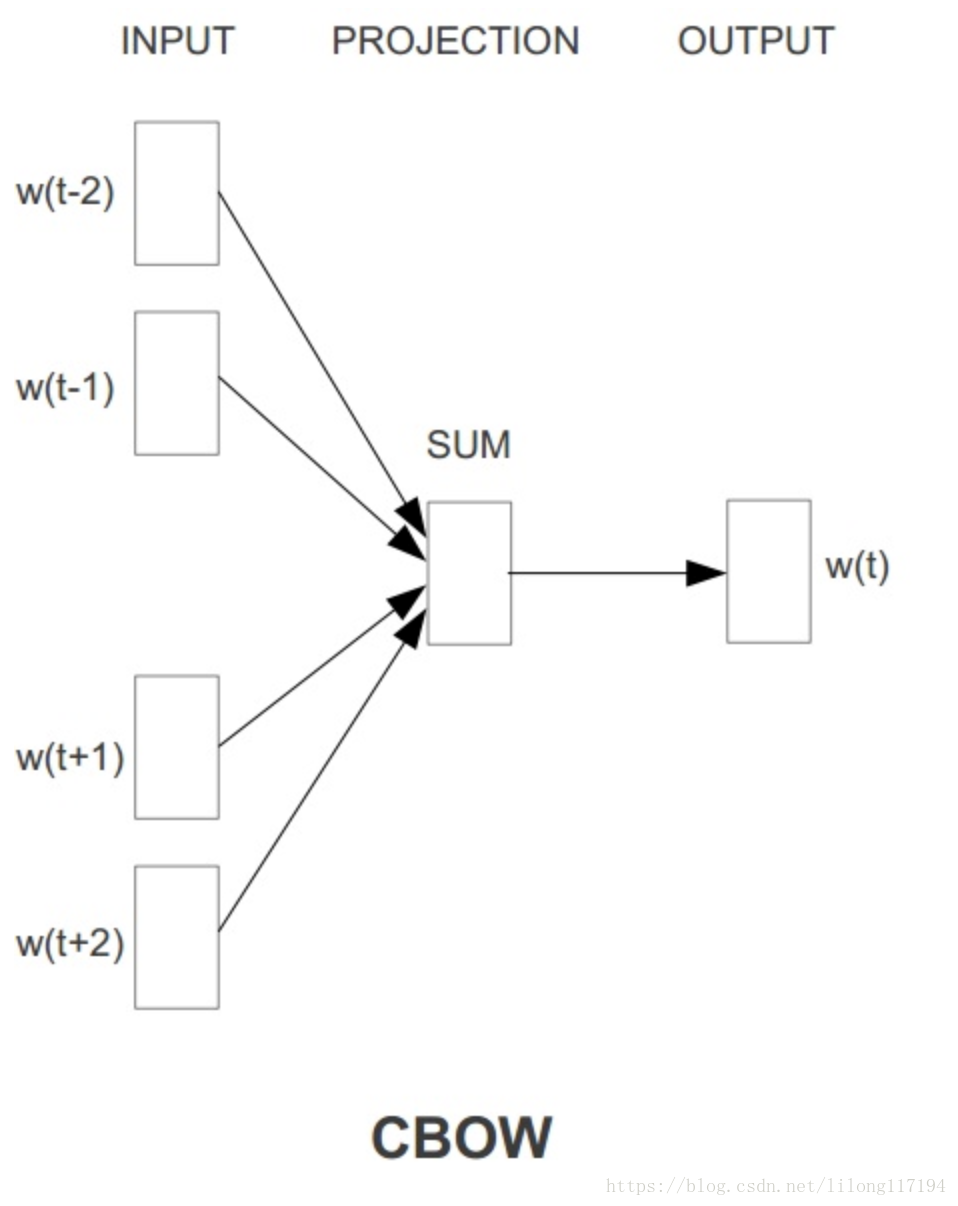
由图可知,该模型使用一段文本的的中间词作为目标词,同时cbow模型去掉了隐藏层,大大提高了预运算速度,也因此其输入层就是语义上下文的表示。此外cbow模型,使用上下文各词的词向量的平均值替代nnlm模型各个拼接的词向量。
整体流程:
首先明确输入是周围词的词向量,而输出则是当前词的词向量,也就是通过上下文来预测当前的词。
CBOW包含了输入层、投影层、以及输出层(没有隐藏层)。其运算流程如下:
随机生成一个所有单词的词向量矩阵,每一个行对应一个单词的向量
对于某一个单词(中心词),从矩阵中提取其周边单词的词向量
求周边单词的的词向量的均值向量
在该均值向量上使用logistic regression 进行训练,softmax作为激活函数
期望回归得到的概率向量可以与真实的概率向量(即中心词的one-hot编码向量)相匹配

2.4 Skip-gram模型
Skip-gram模型的结构如下:
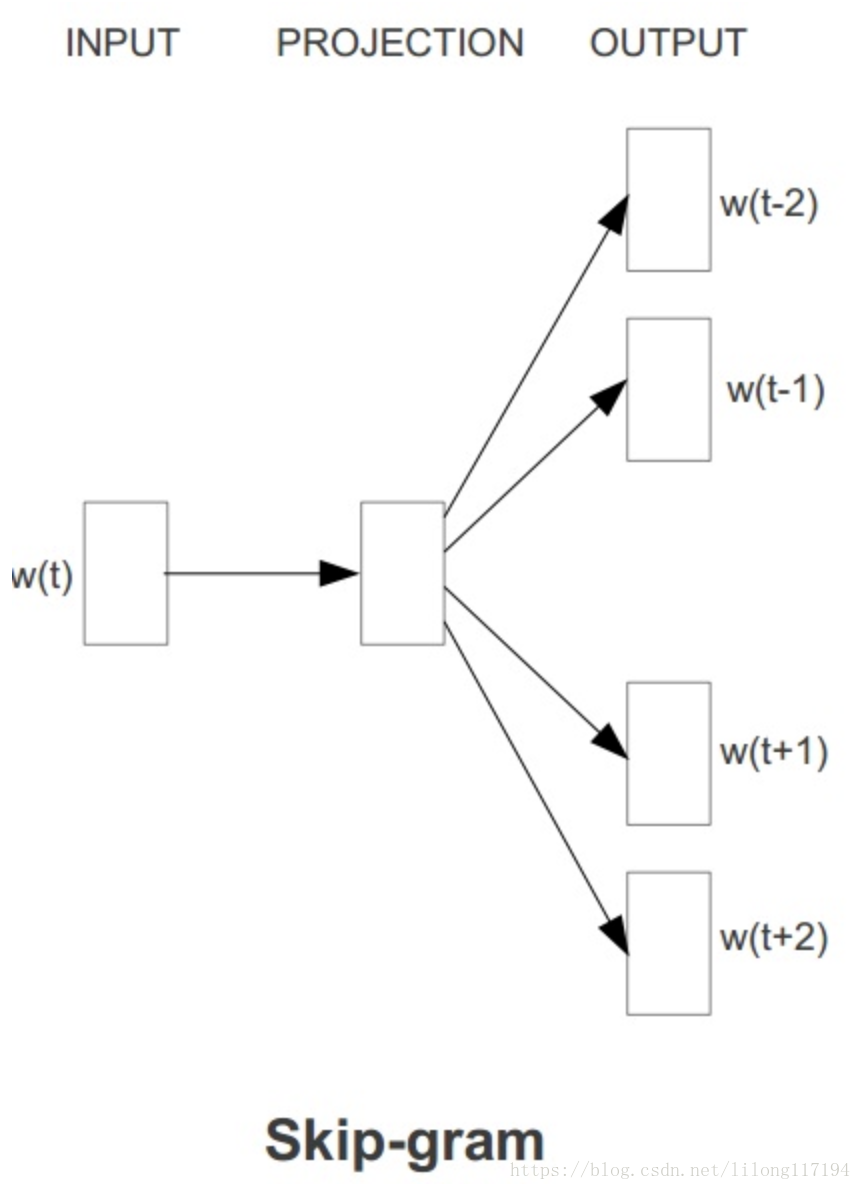
由图可知, Skip-gram模型同样没有隐藏层,但与CBOW模型的输入上下文词的平均向量不同, Skip-gram模型是从目标词w的上下文中选择一个词,将其词向量组成上下文的表示。
Skip-gram模型的目标函数:
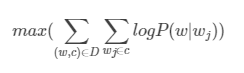
2.5 CBOW和Skip-gram模型的对比
其中CBOW是周围的词预测中间的词,最大化对w(t)的预测。Skip-gram是中间的词预测周围的词,最大化对w(t-2),w(t-1),w(t+1),w(t+2)的预测之和。由于没有隐藏层,所以2个网络都是线性模型。正因为如此,模型的训练时间比较短,只花了一天就训练了16亿单词的语料。且获得的词嵌入质量很好,还具有“king”-“man”+“women”=“queen”的语义规律。
论文中使用了两种训练方法,一种是哈夫曼树结构的Hierarchical Softmax,另一种是Negative Sampling,它们的使用都是为了缩短训练时间。由于这两个技术这是加快训练的技术,不是网络结构。
不过正是这2个技术的运用缩短了训练时间(另外一个缩短时间的原因是删掉隐藏层),使其更快地生成了质量好的词嵌入,值得重视。

网络对比:
对比上面介绍的模型我们发现,后面的模型都是以NNLM为基础进行修改的。其中主要修改有3个部分:输入层,隐藏层,输出层。其中输入层是存储词嵌入的层,隐藏层是做语义重组的层,输出层是根据目标构造输出语义的层。
以NNLM作为对比对象。后面几个模型的修改情况如下:
C&W:修改了输入和输出层
CBOW :去除了隐藏层,输出层优化
skip-gram:去除了隐藏层,修改了输入层,输出层优化
根据上面的对比,总结一下:
对与每个模型来说,输入是上下文,输出是预测,这些模型的核心是用上下文做预测。
C&W只是为了具体任务来做词嵌入的预训练,所以它把要预测的和上下文放在一起,以得分的形式进行判断,最大化正例和反例的得分差。
CBOW没有隐藏层,直接叠加构造语义输出,或许正是如此所以训练的词嵌入具有线性语义特征。其当前的预测是作为上下文语义的词嵌入的线性叠加。
Skip-gram以一个单词作为上下文,多次预测周围的词。它的成功是否表明预测是可逆的,即A可预测B,则B可预测A,而其根本原因是A与B具有相似语义。而这种相似的产生是因为模型没有隐藏层,只有线性变换?

3.ELMo–动态词向量
ELMo官网:https://allennlp.org/elmo
艾伦研究所开发,并于6月初在NAACL 2018年发布ELMo(深度语境化的单词表示)。
ELMO(Embeddings from Language Models) ,被称为时下最好的通用词和句子嵌入方法,来自于语言模型的词向量表示,也是利用了深度上下文单词表征,该模型的优势:
(1)能够处理单词用法中的复杂特性(比如句法和语义)
(2)这些用法在不同的语言上下文中如何变化(比如为词的多义性建模)
ELMo与word2vec最大的不同:
Contextual: The representation for each word depends on the entire context in which it is used.
(即词向量不是一成不变的,而是根据上下文而随时变化,这与word2vec或者glove具有很大的区别)
举个例子:针对某一词多义的词汇w=“苹果”
文本序列1=“我 买了 六斤 苹果。”
文本序列2=“我 买了一个 苹果 7。”
上面两个文本序列中都出现了“苹果”这个词汇,但是在不同的句子中,它们我的含义显示是不同的,一个属于水果领域,一个属于电子产品呢领域,如果针对“苹果”这个词汇同时训练两个词向量来分别刻画不同领域的信息呢?答案就是使用ELMo。
ELMo是双向语言模型biLM的多层表示的组合,基于大量文本,ELMo模型是从深层的双向语言模型(deep bidirectional language model)中的内部状态(internal state)学习而来的,而这些词向量很容易加入到QA、文本对齐、文本分类等模型中,后面会展示一下ELMo词向量在各个任务上的表现。
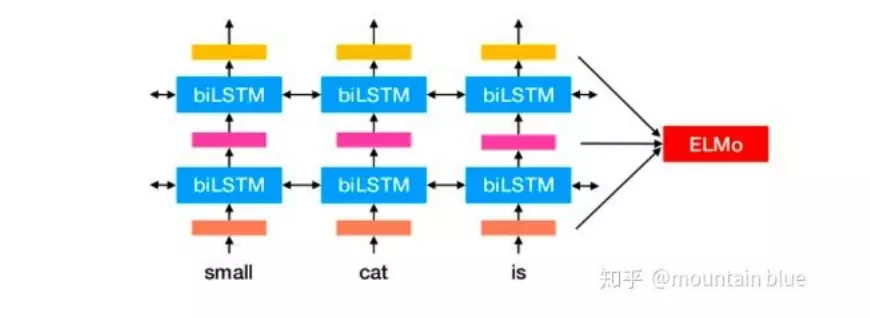
它首先在大文本语料库上预训练了一个深度双向语言模型(biLM),然后把根据它的内部状态学到的函数作为词向量。实验表明,这些学到的词表征可以轻易地加入到现有的模型中,并在回答问题、文本蕴含、情感分析等 6 个不同的有难度的 NLP 问题中大幅提高最佳表现。实验表明显露出预训练模型的深度内部状态这一做法非常重要,这使得后续的模型可以混合不同种类的半监督信号。
3.1 ELMo的安装与使用
AllenNLP是一个相对成熟的基于深度学习的NLP工具包,它构建于 PyTorch之上,该工具包中集成了ELMo方法。
可以直接使用pip安装:
pip install allennlp
适用于python3.6以上的版本
或者,也可以直接clone源码到本地[https://github.com/allenai/allennlp]

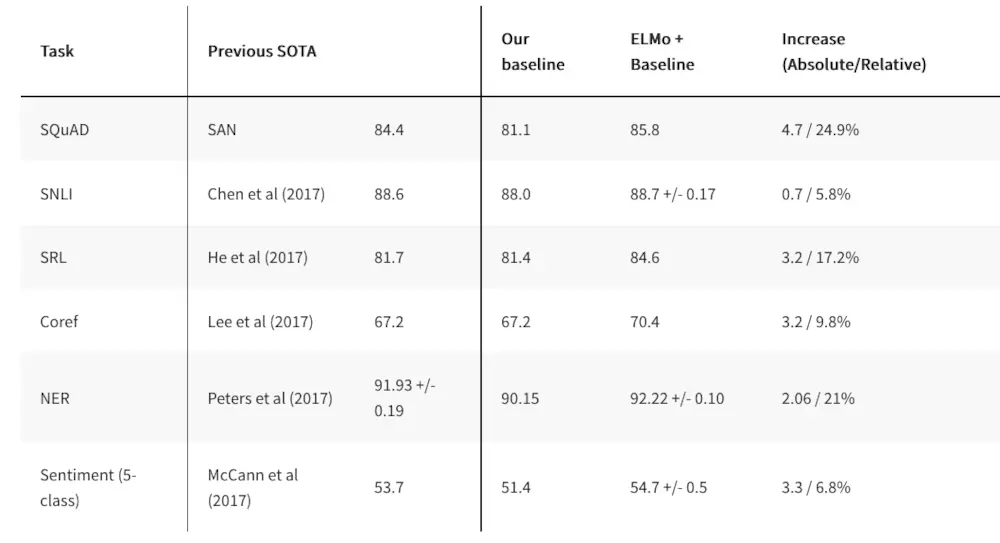
使用ELMo获得词向量替换Glove的词向量作为多项特定NLP模型的输入,在ELMo的论文实验中表明具有一定的效果提升:
BERT的诞生过程:
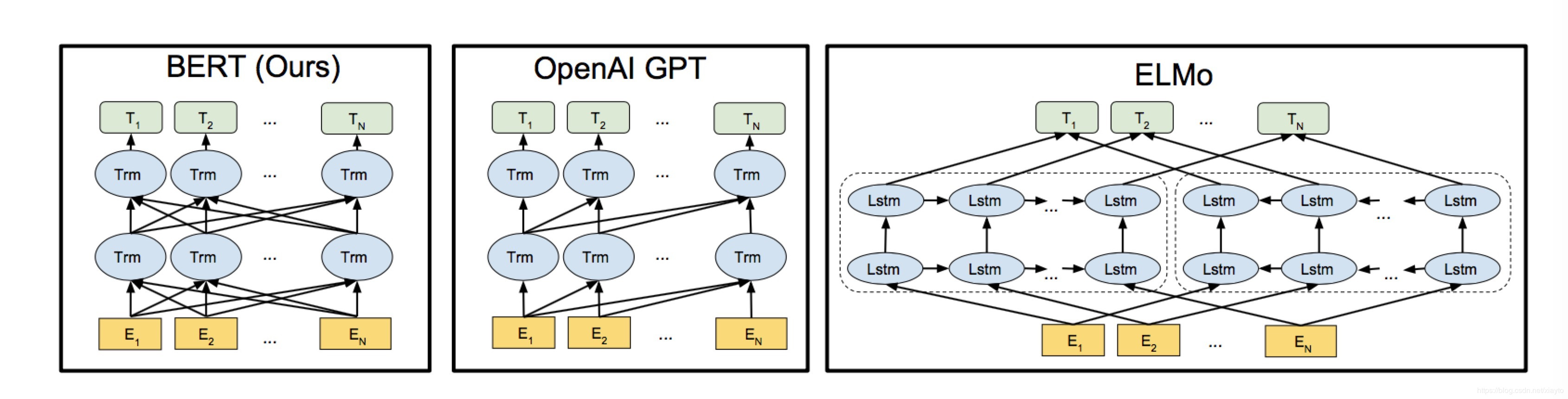
BERT的工作方式跟ELMo是类似的,但是ELMo存在一个问题,它的语言模型使用的是LSTM,而不是google在2017最新推出的Transformer(来自论文《Attention is all you need》)。LSTM这类序列模型最主要的问题有两个,一是它单方向的,即使是BiLSTM双向模型,也只是在loss处做一个简单的相加,也就是说它是按顺序做推理的,没办法考虑另一个方向的数据;二是它是序列模型,要等前一步计算结束才可以计算下一步,并行计算的能力很差。
所以在ELMo之后,一个新模型GPT(来自论文《Improving Language Understanding by Generative Pre-Training》)推出了,它用Transformer来编码。但是它的推理方式跟ELMo相似,用前面的词去预测下一个词,所以它是单方向,损失掉了下文的信息。
然后BERT诞生了,它采用了Transformer进行编码,预测词的时候双向综合的考虑上下文特征。这里作者做了一个改进,原来没办法综合利用双向的特征是因为目标是用前面的词逐个的预测下一个词,如果你能看到另一个方向,那就等于偷看了答案。BERT的作者说受到了完形填空的启发,遮盖住文章中15%的词,用剩下85%的词预测这15%的词,那就可以放心的利用双向上下文的特征了。
Transformer:
Transformer是论文《Attention is all you need》中的模型,它把attention机制从配角搬上了主角的位置,没有采用CNN或者RNN的结构,完全使用attention进行编码。Transformer应该会取代CNN和RNN成为NLP主流的编码方式,CNN提取的是局部特征,但是对于文本数据,忽略了长距离的依赖,CNN在文本中的编码能力弱于RNN,而RNN是序列模型,并行能力差,计算缓慢,而且只能考虑一个方向上的信息。Transformer可以综合的考虑两个方向的信息,而且有非常好的并行性质,简单介绍一下Transformer的结构。
https://jalammar.github.io/illustrated-transformer/ 这一篇博客上有非常详细的介绍,详细了解Transformer可以看一下这一个博客。
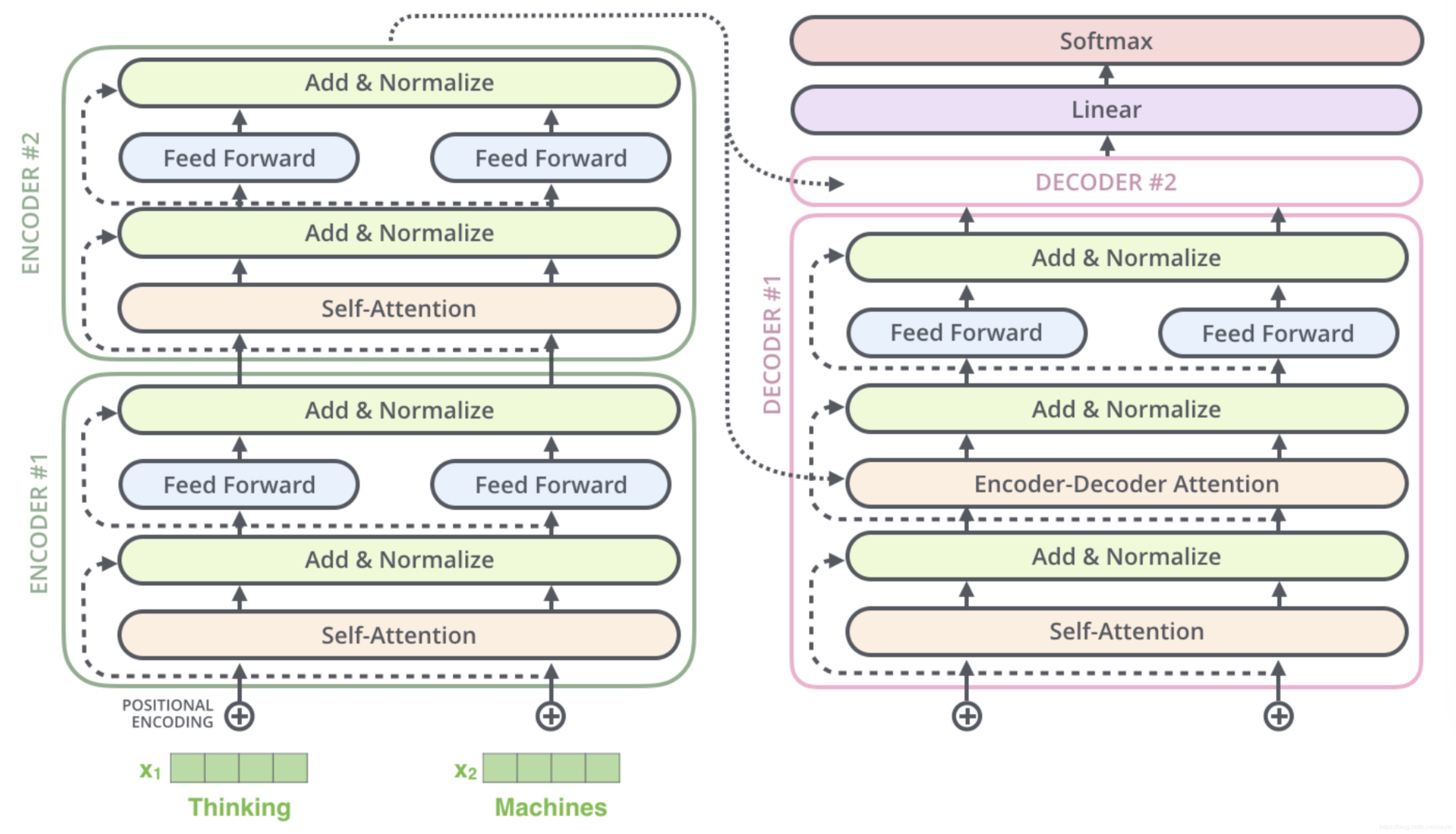
整个Transformer的结构如上图所示,它分为两个部分,一边是encoder,另一边是decoder,一个encoder或decoder看作一个block,encoder和decoder又有多个block串行相连,图中是2个,原文中使用了6个。
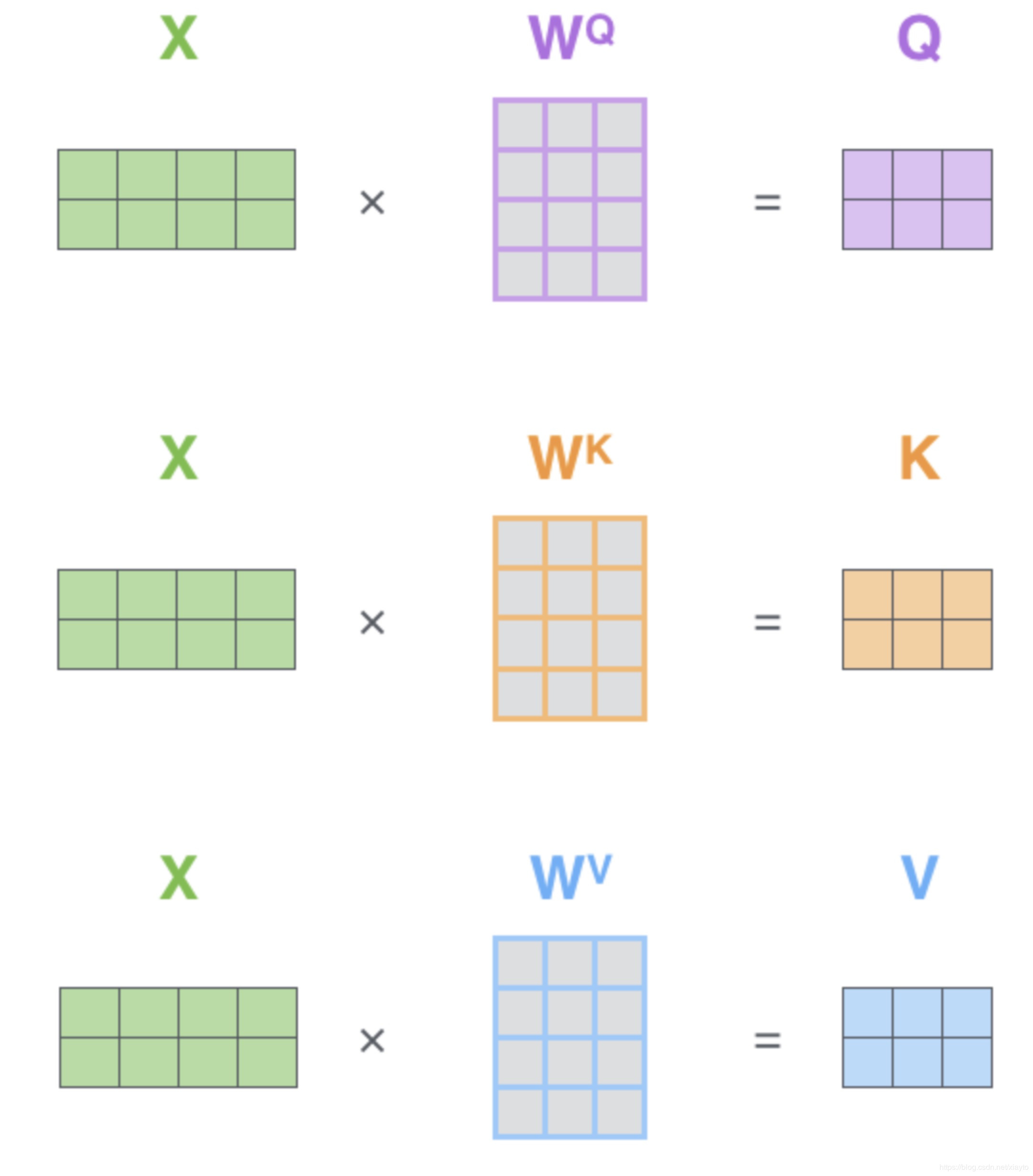
先看encoder,单独看一个block,输入一行句子,先经过一个Self-Attention,Self-Attention首先是对每个Token的embedding通过3个不同的矩阵映射成3个向量,Query(Q)、Key(K)和Value(V)。

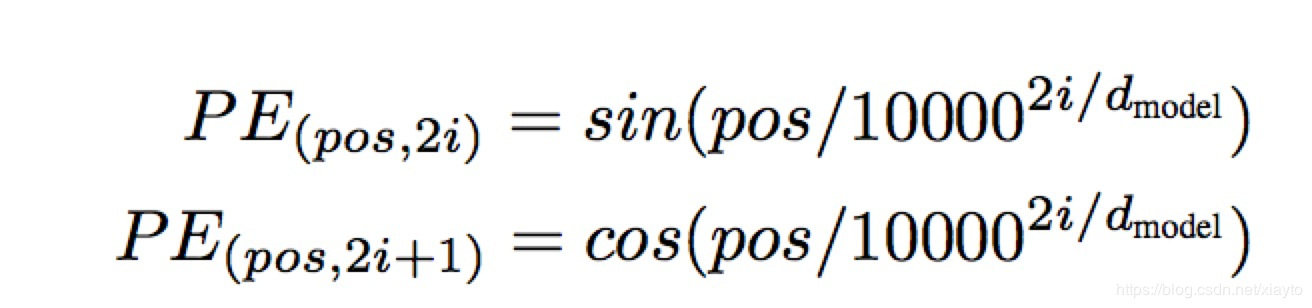
每个pos的位置用一个d维的向量表示,这个向量的偶数位置用sin,奇数位置用cos计算,得到-1到1之间的值,之所以用三角函数是利用了三角函数和差变换可以线性变换的特性,因为BERT中没有采用这种计算方式,所以不作详细的介绍。
然后经过一个Feed Forward的神经网络再经过Add&Normalize完成一个encoder,传向下一个encoder。Decoder的结构和运算机制与encoder基本一致,不同的是encoder顶层的K、V向量会传到Decoder的每个Block的Encoder-Decoder Attention部件中。最后经过一个线性的变换和Softmax分类器得到最后的结果。
BERT的实现方式:
Mask Language Model
受到完形填空的启发,它不同于传统的语言模型,它是盖住整篇文章15%的词,然后用其他的词预测这15%的词。被盖住的词用[mask]这样的一个标记代替,但是由于下游任务中没有[mask]这个符号,为了削弱这个符号的影响,15%被盖住的词中:
80%的词就用[mask]符号盖住
10%的词保留原来真实的词
10%的词用随机的一个词替代
编码方式:
采用Transformer为编码方式,实验结果最好的结构是BERT:L=24,H=1024,A=16。L=24也就是Transformer中提到的Block数,H=1024是隐藏层的维度,也就是Token经过矩阵映射之后K、Q、V向量的维度,A=16是Attention的头数,叠加了16层相互独立的Self-Attention。非常的google,money is all you need,如此复杂的结构,一般人是玩不了的,所幸的是google开源了pre-train的参数,只要用pre-train的参数对下游任务进行fine-tuning就可以使用google的BERT。
BERT的Transformer结构与Attention is all you need中有一个不同是对于位置信息的编码,论文中的Transformer是采用cos和sin函数计算,而BERT用了更为简单粗暴的方法,每一个位置赋予一个向量,例如句子的截断长度固定为50,那么0-49这50个位置各赋予一个向量,将这个向量加到self-attention的embedding上。
获取句间的关系:
目前为止只获得了Token级别的特征,但是对于一些句间关系的推理,对话系统、问答系统需要捕捉一些句子的特征。BERT采用给定2个句子,判断它们是否是连续的句子的方式捕捉句子级别的特征:
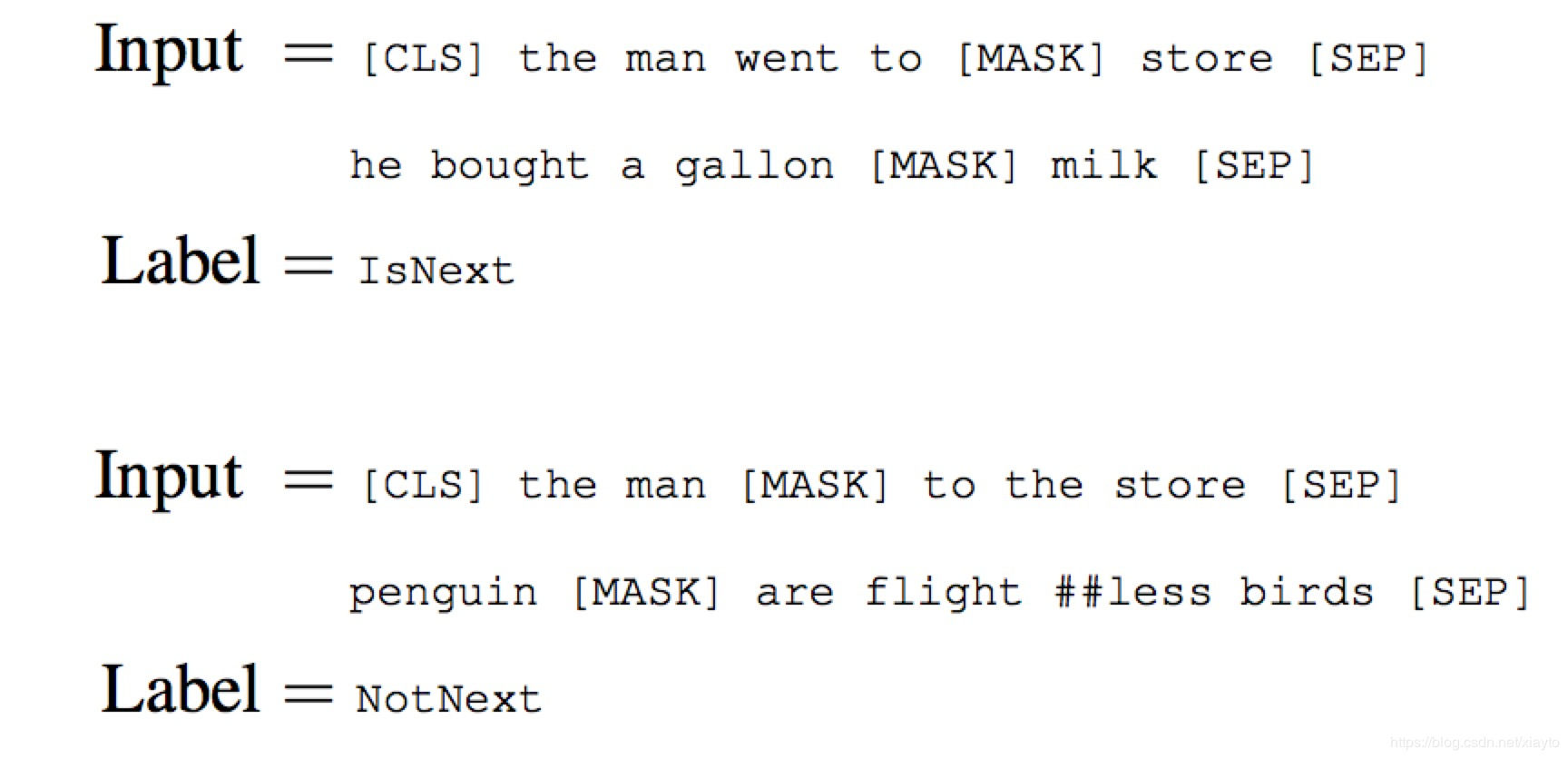
具体的实现方式是两个连续的句子,开始和结束打上符号,两句之中打上分隔符,然后中一个二分类,反例的生成采用类似于word2vec的负采样。
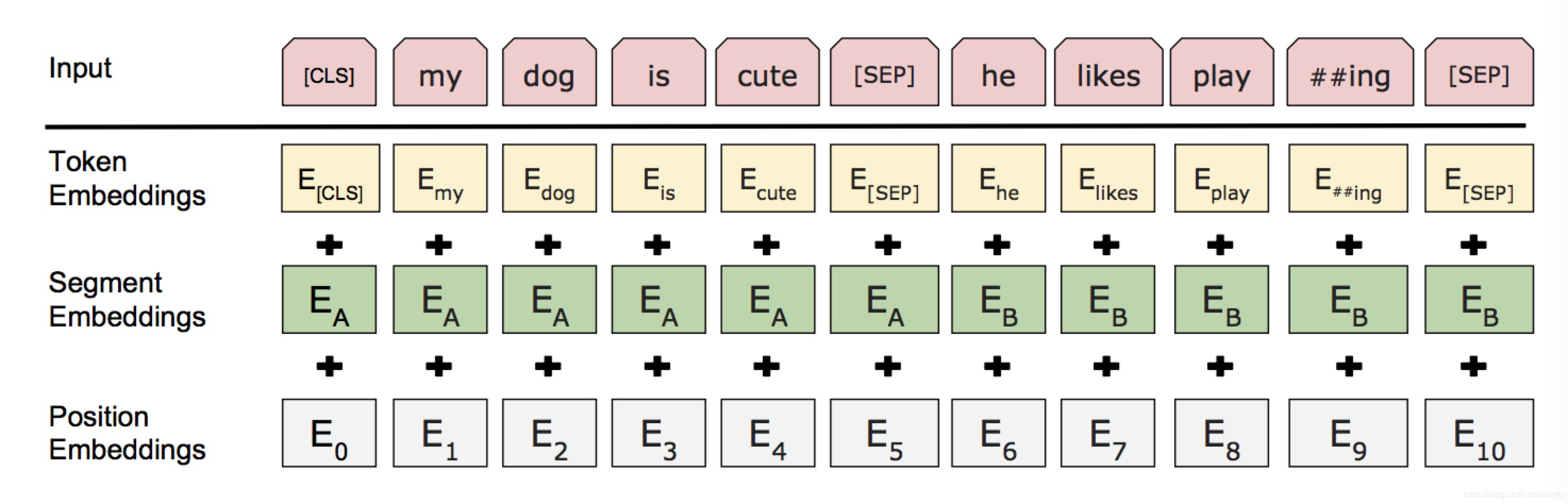
这是整体的编码方式,Token Embedding是Transformer的embedding,加上segment embedding A和B,捕捉句子级别的特征,区分第一句和第二句,如果只有一个句子的情况就只有embedding A,加上每个位置赋予的Position embedding得到最终的embedding。
BERT的实验结果:
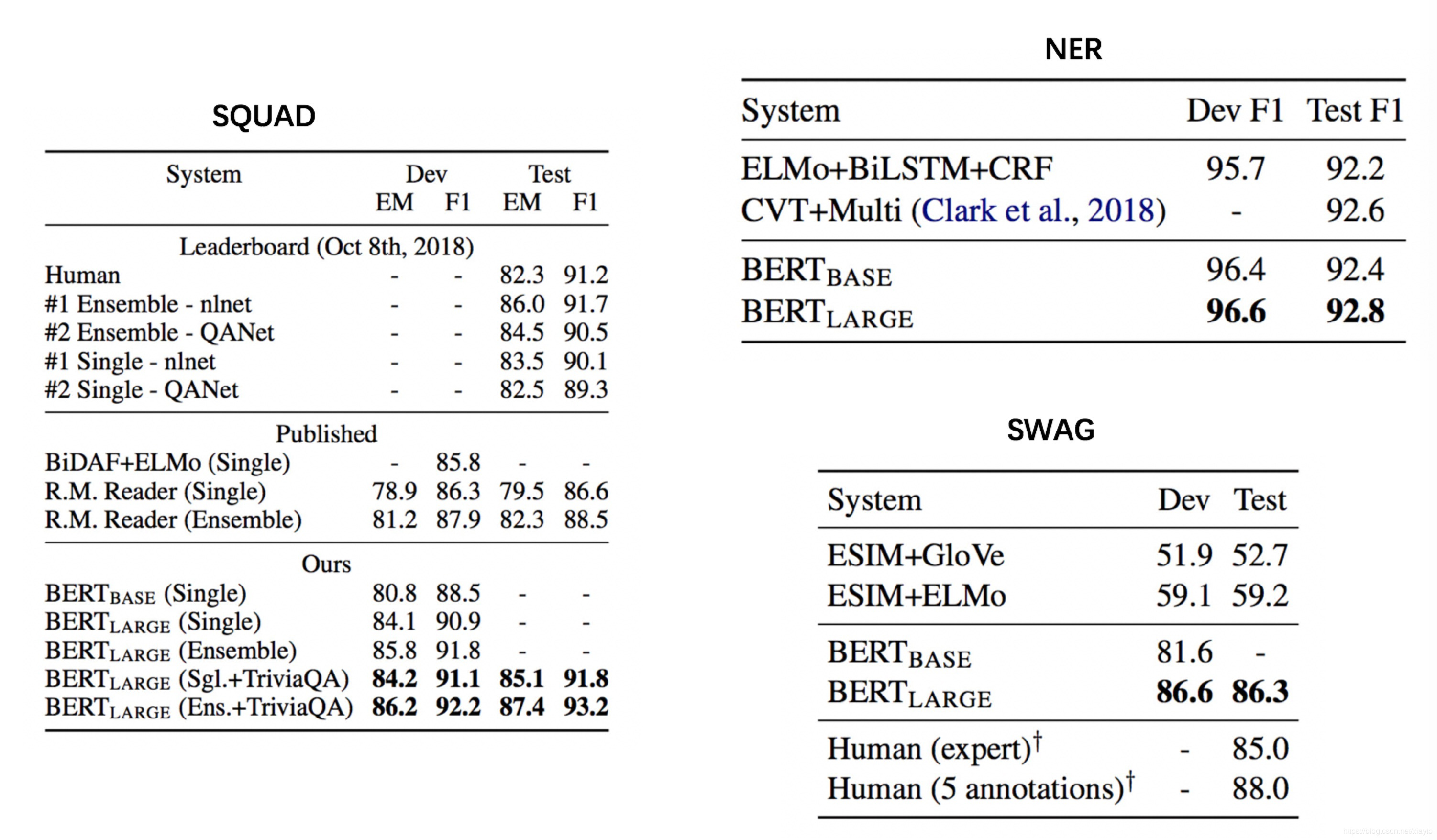
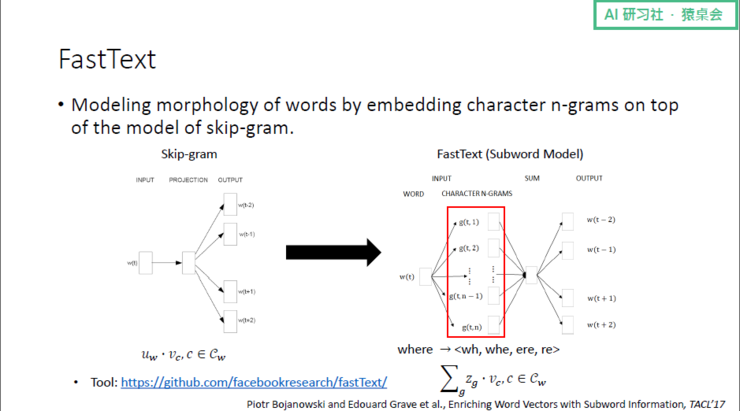
在 NLP 具体任务中应用的效果来看:效果最差的是 CBOW;其次是 Skip-gram(GloVe 跟 Skip-gram 差不多);效果最好的是 FastText。其中,FastText 能很好地处理 OOV(Out of Vocabulary)问题,最小粒度介于word和character之间 问题,并能很好地对词的变形进行建模,对词变形非常丰富的德语、西班牙语等语言都非常有效;
从效率(训练时间)上来看:CBOW 的效率是最高的,其次是 GloVe;之后是 Skip-gram;而最低的是 FastText。
https://blog.csdn.net/sinat_26917383/article/details/83041424
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/131933.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
