大家好,又见面了,我是你们的朋友全栈君。
SpatialDropout是Tompson等人在图像领域提出的一种dropout方法。普通的dropout会随机地将部分元素置零,而SpatialDropout会随机地将部分区域置零,该dropout方法在图像识别领域实践证明是有效的。
dropout
dropout是怎么操作的?一般来说,对于输入的张量x,dropout就是随机地将部分元素置零,然后对结果做一个尺度变换。比如,我们随机初始化一个5×10的二维矩阵,即;
import numpy as np
x = np.random.random((4,5))
print(x)
def Dropout(x,drop_proba):
return x * np.random.choice(
[0,1],
x.shape,
p = [drop_proba,1-drop_proba]
) / (1. - drop_proba)
print(Dropout(x,0.5))
# x
[[0.56189429 0.03603615 0.97580132 0.36180956 0.55606632]
[0.81176104 0.47364453 0.97262952 0.04289464 0.42820463]
[0.26016082 0.61274373 0.10307323 0.84194222 0.48404058]
[0.37371407 0.88847782 0.37580269 0.97473358 0.7809447 ]]
# dropout(x,0.5)
[[0. 0.07207229 0. 0. 1.11213264]
[1.62352208 0. 1.94525904 0.08578928 0. ]
[0.52032163 1.22548745 0. 0. 0. ]
[0. 1.77695563 0.75160539 1.94946716 0. ]]
可以看到,Dropout操作随机地将部分元素置零,并且对非零部分做了一个尺度变换。尺度变换的幅度跟初始化的drop_rate有关。
作用
一般,我们会将dropout理解为“一种低成本的集成策略”,这是对的,具体过程可以大概这样理解:
经过上述置零操作后,我们可以认为零的部分是被丢弃的,丢失了一部分信息。因而,逼着模型用剩下的信息区拟合目标。然而每次dropout是随机的。我们就不能侧重于某些节点,所以总的来说就是—每次逼着模型用少量的特征学习,每次被学习的特征又不同,那么就是说,每个特征都应该对
模型的预测有所贡献(而不是侧重于部分特征,导致过拟合)。
SpatialDropout
接下来,我们来详细看看keras模块中SpatialDropout具体做了啥,如下图所示:
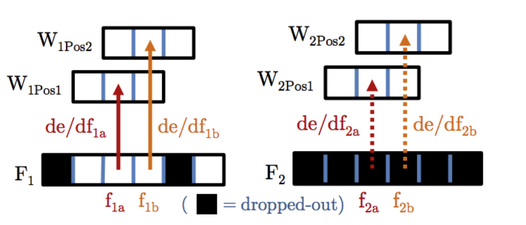

左:普通的dropout,右:SpatialDropout
首先,让我们看看SpatialDropout1D的输入和输出。SpatialDropout1D的输入是三维张量(samples,timesteps,channels),输出的纬度与输入的纬度相同。
我们以文本为例,一个文本的三维张量可以表示为(samples,sequence_length,embedding_dim),其中:
- sequence_length表示句子的长度
- embedding_dim表示词向量的纬度
如下图所示:

当我们对该张量使用dropout技术时,你会发现普通的dropout会随机独立地将部分元素置零,而SpatialDropout1D会随机地对某个特定的纬度全部置零,如下图所示:
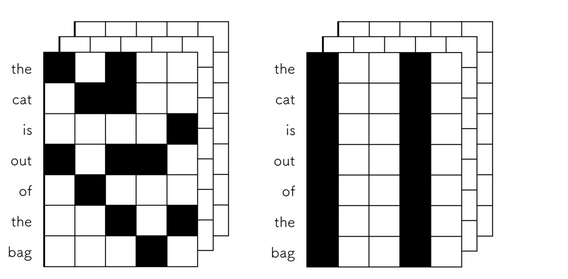
左:普通的dropout,右:SpatialDropout1D
接下来,我们简单的以一个简单的案例说明,首先,我们初始化一个1x7x5的三维张量,如下所示:
#encoding:utf-8
import numpy as np
import keras.backend as K
ary = np.arange(35).reshape((1, 7, 5))
inputs = K.variable(ary)
print(ary)
# result
[[[ 0 1 2 3 4]
[ 5 6 7 8 9]
[10 11 12 13 14]
[15 16 17 18 19]
[20 21 22 23 24]
[25 26 27 28 29]
[30 31 32 33 34]]]
接下来,我们将分别对该张量使用dropout和SpatialDropout1D技术。
首先,我们先对该张量测试普通的dropout,其中dropout_rate为0.5:
dropout_1 = K.eval(K.dropout(inputs, level=0.5))
print(dropout_1)
# result
[[[ 0. 2. 4. 6. 8.]
[ 0. 0. 14. 16. 18.]
[ 0. 0. 24. 0. 28.]
[ 0. 32. 34. 0. 0.]
[40. 0. 0. 0. 48.]
[ 0. 52. 0. 56. 0.]
[ 0. 62. 64. 0. 0.]]]
从结果中,我们可以看到普通的dropout随机地将部分元素置零,并且是无规律的,也就是说下次可能是另外一部分元素置零。
接下来,然后我们对该张量测试SpatialDropout1D,要达到SpatialDropout1D的效果。我们需要指定dropout的shape,对应dropout函数中的参数noise_shape。
noise_shape是一个一维张量,说白了就是一个一维数组,长度必须跟inputs.shape一样,而且,noise_shape的元素,只能是1或者inputs.shape里面对应的元素。比如inputs.shape= (3,4,5)
,那么noise_shape就只能是以下8种情况:
(3,4,5),(1,4,5),(3,1,5),(3,4,1),(1,1,5),(1,4,1),(3,1,1,),(1,1,1)
实际上,哪个轴为1,哪个轴就会被一致的dropout,比如(3,4,5)是就是普通的dropout,没有任何约束
因此,从上图中,我们想要实现SpatialDropout1D,noise_shape应为(input_shape[0], 1, input_shape[2]),即:
input_shape=K.shape(inputs)
noise_shape=(input_shape[0], 1, input_shape[2])
dropout_2 = K.eval(K.dropout(inputs, 0.5, noise_shape))
print(dropout_2)
# result
[[[ 0. 2. 0. 6. 8.]
[ 0. 12. 0. 16. 18.]
[ 0. 22. 0. 26. 28.]
[ 0. 32. 0. 36. 38.]
[ 0. 42. 0. 46. 48.]
[ 0. 52. 0. 56. 58.]
[ 0. 62. 0. 66. 68.]]]
可以看到,与普通的dropout不同的是,SpatialDropout1D随机地将某块区域全部置零。
实际上,我们也可以横向将部分区域全部置零,只需修改noise_shape即可,即:
noise_shape = (input_shape[0], input_shape[1], 1)
dropout_3 = K.eval(K.dropout(inputs, 0.5, noise_shape))
print(dropout_3)
# result
[[[ 0. 2. 4. 6. 8.]
[ 0. 0. 0. 0. 0.]
[20. 22. 24. 26. 28.]
[ 0. 0. 0. 0. 0.]
[40. 42. 44. 46. 48.]
[50. 52. 54. 56. 58.]
[60. 62. 64. 66. 68.]]]
所以,通过修改noise_shape,本质上我们可以实现任意功能的dropout。
在keras模块中,一般我们实现一个新的dropout,会按照下列模板进行,比如;
class TimestepDropout(Dropout):
def __init__(self, rate, **kwargs):
super(TimestepDropout, self).__init__(rate, **kwargs)
self.input_spec = InputSpec(ndim=3)
def _get_noise_shape(self, inputs):
input_shape = K.shape(inputs)
noise_shape = (input_shape[0], input_shape[1], 1)
return noise_shape
注:本质上是修改noise_shape,新类TimestepDropout继承了Dropout,我们知道当子类中存在与父类相同的函数时,子类的函数会更新父类函数。所以本质上就是修改获取noise_shape的函数。
备注:最近刚开始学习pytorch
pytorch
import torch.nn as nn
from itertools import repeat
class Spatial_Dropout(nn.Module):
def __init__(self,drop_prob):
super(Spatial_Dropout,self).__init__()
self.drop_prob = drop_prob
def forward(self,inputs):
output = inputs.clone()
if not self.training or self.drop_prob == 0:
return inputs
else:
noise = self._make_noise(inputs)
if self.drop_prob == 1:
noise.fill_(0)
else:
noise.bernoulli_(1 - self.drop_prob).div_(1 - self.drop_prob)
noise = noise.expand_as(inputs)
output.mul_(noise)
return output
def _make_noise(self,input):
return input.new().resize_(input.size(0),*repeat(1, input.dim() - 2),input.size(2))
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/131854.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
