大家好,又见面了,我是你们的朋友全栈君。
因为工作中负责维护的产品中有使用消息中间件kafuka的系统 ,所以把工作中的理解和遇到的问题总结出来,方便后期查看,好记性不如烂笔头。kafuka是一个分布式的、分区化、可复制提交的发布订阅消息系统,使用kafuka需要对其中的一些概念做简单了解。
一、kafuka基础
1、topic主题: Kafka中用于区分不同类别信息的类别名称。由producer指定
2、Producer:将消息发布到Kafka特定的Topic的对象
3、Consumers:订阅并处理特定的Topic中的消息的对象
4、broker(Kafka服务集群):已发布的消息保存在一组服务器中,称之为Kafka集群。集群中的每一个服务器都是一个代理(Broker). 消费者可以订阅一个或多个话题,并从Broker拉数据,从而消费这些已发布的消息,通俗的说broker就是一台服务器,一个节点。
5、Message:消息,是通信的基本单位,每个producer可以向一个topic(主题)发送一些消息。
6、 Partition(分区): Topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)
分区具体在服务器上面表现起初就是一个目录,一个主题下面有多个分区,这些分区会存储到不同的服务器上面,或者说,其实就是在不同的主机上建了不同的目录。多个分区多个线程,多个线程并行处理提高性能,其中中topic主题只是逻辑概念,而partition就是分布式存储单元,这个设计是保证了海量数据处理的基础。

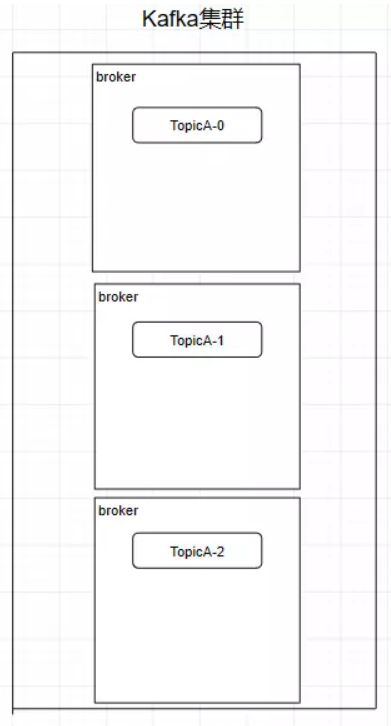
二、kafuka集群架构
创建一个TopicA的主题,3个分区分别存储在不同的服务器,也就是broker下面。Topic是一个逻辑上的概念,并不能直接在图中把Topic的相关单元画出
需要注意:kafka在0.8版本以前是没有副本机制的,所以在面对服务器宕机的突发情况时会丢失数据,所以尽量避免使用这个版本之前的kafka
Consumer Group – 消费者组
我们在消费数据时会在代码里面指定一个group.id,这个id代表的是消费组的名字,而且这个group.id就算不设置,系统也会默认设置: conf.setProperty(“group.id”,“chenqi”);
consumerA: group.id = a
consumerB: group.id = a
consumerC: group.id = b
consumerD: group.id = b
对于消费者组,如现在consumerA去消费了一个topicA里面的数据,再让consumerB也去消费TopicA的数据,它是消费不到了,但是我们在consumerC中重新指定一个另外的group.id,consumerC是可以消费到topicA的数据的。而consumerD也是消费不到的,所以 在kafka中,不同组可有唯一的一个消费者去消费同一主题的数据。 所以消费者组就是让多个消费者并行消费信息而存在的,而且它们不会消费到同一个消息
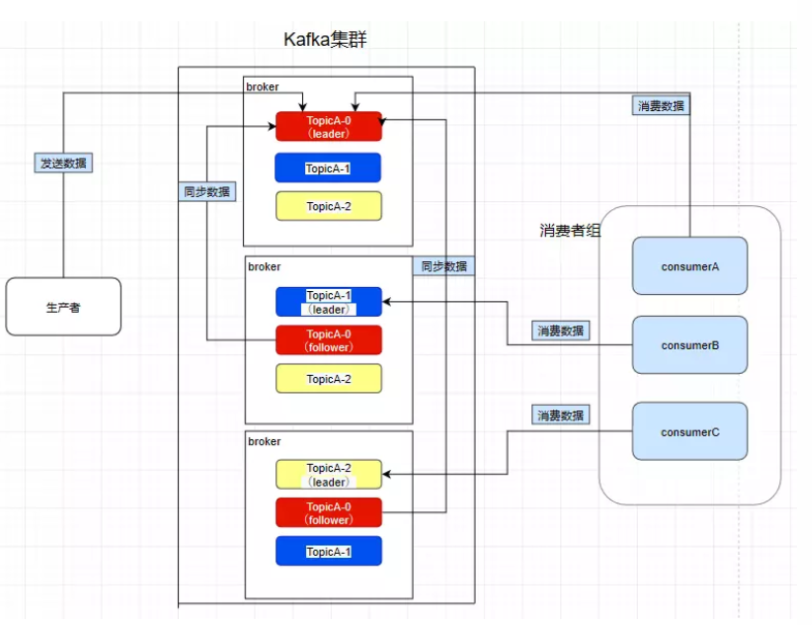
消费者会直接和leader建立联系,所以它们分别消费了三个leader,所以 一个分区不会让消费者组里面的多个消费者去消费 ,但是在消费者不饱和的情况下, 一个消费者是可以去消费多个分区的数据的 。
三、结合实际问题
实际工作中使用的kafuka集群是四个分区,一个消费者组,但是消费者有四台主机,因为业务量的扩大需要将消费者增加到8个,但是在新主机测试的时候发现,老主机是可以接受到kafuka的消息的,但是新主机接收不到kafuka的消息,如果将老主机进程停止,新主机从新启动,后启动的四台主机是由kafuka消息的,而先启动的就接收不到消息,结合上面的分析,不难看出,是因为分区数小于了当前的消费者组内的消费者数量, 同一个消费组内,消费者数目大于分区数目后,消费者会有空余=分区数-消费者数,所以有四台主机无法接收消息,此时需要结合kafuka的性能去增加分区数,最好是分区数=消费者数,此时效率最高。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/131717.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
