大家好,又见面了,我是你们的朋友全栈君。
综述
在计算广告中,CTR是非常重要的一环。对于特征组合来说,业界通用的做法主要有两大类:FM系列和Tree系列。这里我们来介绍一下FM系列。
在传统的线性模型中,每个特征都是独立的,如果需要考虑特征与特征之间的相互作用,可能需要人工对特征进行交叉组合。非线性SVM可以对特征进行核变换,但是在特征高度稀疏的情况下,并不能很好的进行学习。现在有很多分解模型可以学习到特征之间的交互隐藏关系,基本上每个模型都只适用于特定的输入和场景。推荐系统是一个高度系数的数据场景,由此产生了FM系列算法。
本文主要涉及三种FM系列算法:FM,FFM,DeepFM
一、FM算法(Factorization Machines)
背景
FM(Factorization Machine)主要是为了解决数据稀疏的情况下,特征怎样组合的问题。已一个广告分类的问题为例,根据用户与广告位的一些特征,来预测用户是否会点击广告。数据如下:


对于ctr点击的分类预测中,有些特征是分类变量,一般进行one-hot编码,以下是对组合特征的one-hot:

one-hot会带来数据的稀疏性,使得特征空间变大。
另外,对于普通的线性模型,我们将各个特征独立考虑,并没有考虑特征与特征之间的关系,因此有很多方法对特征进行组合,数据模型上表达特征xi,xj的组合用xixj表示,即所说的多项式模型,通常情况下只考虑两阶多项式模型,也就是特征两两组合的问题,模型表达如下:
其中n表示样本的特征数量,这里的特征是离散化后的特征。与线性模型相比,FM的模型多了后面的特征组合的部分。
FM求解
Wij求解的思路是通过矩阵分解的方法,为了求解Wij,我们队每一个特征分量xi引入辅助向量 Vi=(vi1,vi2,...,vik) V i = ( v i 1 , v i 2 , . . . , v i k )
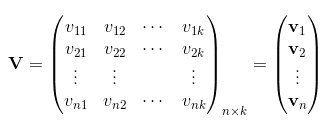
然后用 vivTj v i v j T 对 wij w i j 进行求解
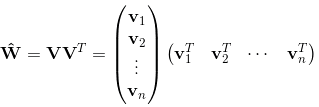
从上式可以看出二项式的参数数量由原来的 n(n−1)2 n ( n − 1 ) 2 个减少为nk个wik,远少于多项式模型的参数数量。另外,参数因子化使得 xhxi x h x i 的参数和 xhxj x h x j 的参数不再相互独立,因为有了 xh x h 特征关联。因此我们可以在样本系数的情况下相对合理地估计FM的二次项参数。
具体来说, xhxi x h x i 和 xhxj x h x j 的系数分别为< vh,vi v h , v i >,< vh,vj v h , v j >,它们之间的共同项vi,因此所有包含xi的非零组合特征的样本都可以用来学习隐向量vi,很大程度上避免了数据稀疏性造成的影响。
求解< vi,vj v i , v j >,主要采用公式 (a+b+c)2−a2−b2−c2 ( a + b + c ) 2 − a 2 − b 2 − c 2 求出交叉项,具体过程如下:
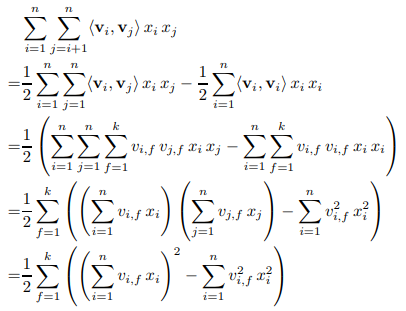
FM的复杂度为 O(kn2) O ( k n 2 ) ,通过上述等式,FM的二次项化简为只与 vi,f v i , f 有关的等式。因此,FM可以在线性时间对新样本做出预测,复杂度和LR模型一样,且效果提升不少。
在训练FM是,加入使用SGD来优化模型,训练时各个参数的梯度如下:
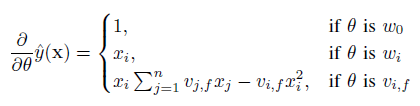
∑nj=1vj,fxj ∑ j = 1 n v j , f x j 只与f有关,只要求出一次所有的f元素,就能够计算出所有 vi,f v i , f 的梯度,而f是矩阵V中的元素,计算复杂度为O(kn)。当已知 ∑nj=1vj,fxj ∑ j = 1 n v j , f x j 时计算每个参数梯度的复杂度是O(1),更新每个参数的复杂度为O(1),因此训练FM模型的复杂度也是O(kn)
扩展到多维,模型表达式为:
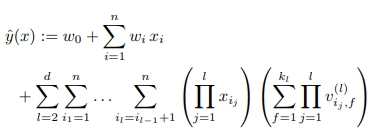
FM vs SVM
SVM和FM的主要区别在于:
- SVM的二元特征交叉参数是独立的,而FM的二元特征交叉参数是两个k维的向量vi、vj,交叉参数就不是独立的,而是相互影响的。
- FM可以在原始形式下进行优化学习,而基于kernel的非线性SVM通常需要在对偶形式下进行
- FM的模型预测是与训练样本独立,而SVM则与部分训练样本有关,即支持向量
为什么线性SVM在和多项式SVM在稀疏条件下效果会比较差呢?线性svm只有一维特征,不能挖掘深层次的组合特征在实际预测中并没有很好的表现;而多项式svn正如前面提到的,交叉的多个特征需要在训练集上共现才能被学习到,否则该对应的参数就为0,这样对于测试集上的case而言这样的特征就失去了意义,因此在稀疏条件下,SVM表现并不能让人满意。而FM不一样,通过向量化的交叉,可以学习到不同特征之间的交互,进行提取到更深层次的抽象意义。
参考:
1. https://blog.csdn.net/jiangjiang_jian/article/details/80631180
2. https://www.csie.ntu.edu.tw/~b97053/paper/Rendle2010FM.pdf
3.https://www.csie.ntu.edu.tw/~b97053/paper/Factorization%20Machines%20with%20libFM.pdf
3. https://blog.csdn.net/tiangcs/article/details/76601643?locationNum=9&fps=1
4. https://www.cnblogs.com/AndyJee/p/7879765.html
二、FFM算法(Field-aware Factorization Machine)
在CTR预估中,通常会遇到one-hot类型的变量,会导致数据特征的稀疏。未解决这个问题,FFM在FM的基础上进一步改进,在模型中引入类别的概念,即field。将同一个field的特征单独进行one-hot,因此在FFM中,每一维特征都会针对其他特征的每个field,分别学习一个隐变量,该隐变量不仅与特征相关,也与field相关。
假设样本的n个特征属于f个field,那么FFM的二次项有nf个隐向量。而在FM模型中,每一维特征的隐向量只有一个。FM可以看做FFM的特例,把所有特征都归属到一个field的FFM模型。其模型方程为:
如果隐向量的长度为k,那么FFM的二次参数有nfk个,远多于FM模型的nk个。
FFM实现
-
损失函数
FFM将问题定义为分类问题,使用的是logistic loss,同时加入正则项
minw∑i=1Llog(1+exp(−yiϕ(w,xi)))+λ2||w||2 m i n w ∑ i = 1 L l o g ( 1 + e x p ( − y i ϕ ( w , x i ) ) ) + λ 2 | | w | | 2 -
梯度下降
梯度下降方法有很多种,根据为提高效率分别衍生了批量梯度下降,随机梯度下降及小批量梯度下降,根据需求选择即可
FFM应用
在DSP或者推荐场景中,FFM主要用来评估站内的CTR和CVR,即一个用户对一个商品的潜在点击率和点击后的转化率。
CTR和CVR预估模型都是在线下训练,然后线上预测。两个模型采用的特征大同小异,主要分三类:
-
用户相关的特征
年龄、性别、职业、兴趣、品类偏好、浏览/购买品类等基本信息,以及用户近期点击量/购买量/消费额等统计信息 -
商品相关的特征
商品所属品类、销量、价格、评分、历史CTR/CVR等信息 -
用户-商品匹配特征
浏览/购买品类匹配、浏览/购买商家匹配、兴趣偏好匹配等
为了使用FFM方法,所有的特征必须转换成“field_id:feat_id:value”格式,field_id代表特征所属field的编号,feat_id是特征编号,value是特征的值。数值型的特征比较容易处理,只需分配单独的field编号,如用户评论得分、商品的历史CTR/CVR等。categorical特征需要经过One-Hot编码成数值型,编码产生的所有特征同属于一个field,而特征的值只能是0或1,如用户的性别、年龄段,商品的品类id等。除此之外,还有第三类特征,如用户浏览/购买品类,有多个品类id且用一个数值衡量用户浏览或购买每个品类商品的数量。这类特征按照categorical特征处理,不同的只是特征的值不是0或1,而是代表用户浏览或购买数量的数值。按前述方法得到field_id之后,再对转换后特征顺序编号,得到feat_id,特征的值也可以按照之前的方法获得。
【举例说明】
– 原始数据:

-
特征编号:
-
特征组合:
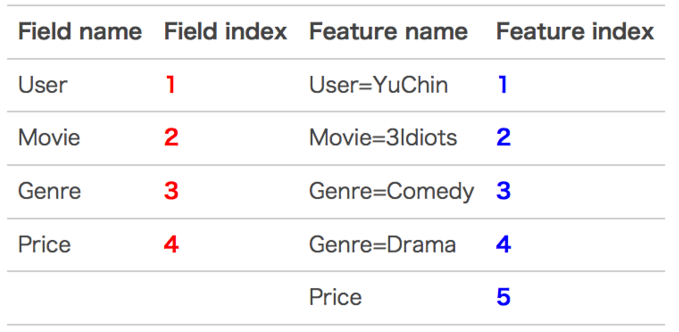

在训练FFM的过程中,有许多小细节值得特别关注。
- 样本归一化:FFM默认是进行样本数据的归一化,即 为真;若此参数设置为假,很容易造成数据inf溢出,进而引起梯度计算的nan错误。因此,样本层面的数据是推荐进行归一化的。
- 特征归一化:CTR/CVR模型采用了多种类型的源特征,包括数值型和categorical类型等。但是,categorical类编码后的特征取值只有0或1,较大的数值型特征会造成样本归一化后categorical类生成特征的值非常小,没有区分性。例如,一条用户-商品记录,用户为“男”性,商品的销量是5000个(假设其它特征的值为零),那么归一化后特征“sex=male”(性别为男)的值略小于0.0002,而“volume”(销量)的值近似为1。特征“sex=male”在这个样本中的作用几乎可以忽略不计,这是相当不合理的。因此,将源数值型特征的值归一化到 是非常必要的。
- 省略零值特征:从FFM模型的表达式可以看出,零值特征对模型完全没有贡献。包含零值特征的一次项和组合项均为零,对于训练模型参数或者目标值预估是没有作用的。因此,可以省去零值特征,提高FFM模型训练和预测的速度,这也是稀疏样本采用FFM的显著优势。
参考:
1. https://www.jianshu.com/p/781cde3d5f3d
2. https://blog.csdn.net/u012102306/article/details/51322194
三、DeepFM
FM通过对于每一位特征的隐变量内积来提取特征组合,最后的结果也不错,虽然理论上FM可以对高阶特征组合进行建模,但实际上因为计算复杂度原因,一般都只用到了二阶特征组合。对于告诫特征组合来说,我们很自然想到多层神经网络DNN。
FM的结构
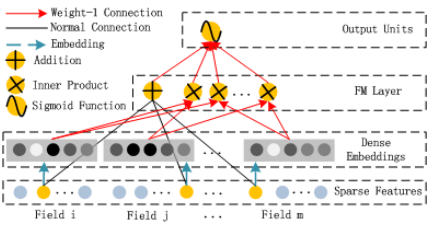
DNN结构
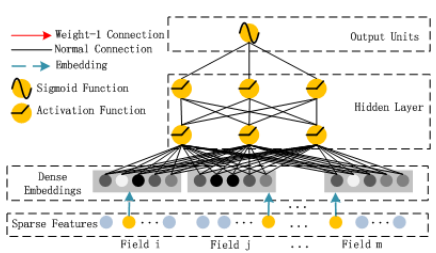
DeepFM结构
FM和DNN的特征结合
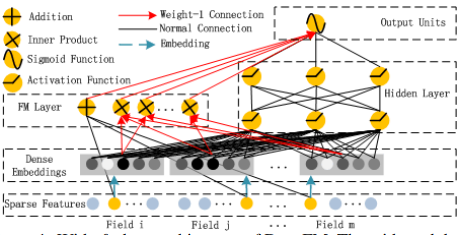
DeepFM目的是同时学习低阶和高阶的特征交叉,主要由FM和DNN两部分组成,底部共享同样的输入。模型可以表示为:
FM部分
原理如上,数学表达为
Deep部分
深度部分是一个前馈神经网络,与图像或语音类的输入不同,CTR的输入一般是极其稀疏的,因此需要重新设计网络结构。在第一层隐藏层之前,引入一个嵌入层来完成输入向量压缩到低位稠密向量:
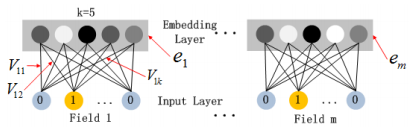
嵌入层的结构如上图所示,有两个有趣的特性:
1) 尽管不同field的输入长度不同,但是embedding之后向量的长度均为k
2) 在FM中得到的隐变量 Vik V i k 现在作为嵌入层网络的权重
嵌入层的输出为 a(0)=[e1,e2,...,em] a ( 0 ) = [ e 1 , e 2 , . . . , e m ] ,其中 ei e i 是嵌入的第i个filed,m是field的个数,前向过程将嵌入层的输出输入到隐藏层为
其中l是层数,
σ σ
是激活函数,
W(l) W ( l )
是模型的权重,
b(l) b ( l )
是l层的偏置
因此,DNN得预测模型表达为:
|H|为隐藏层层数
模型对比
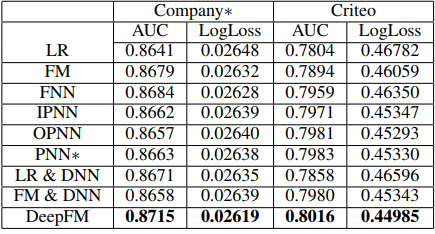
有学者将DeepFM与当前流行的应用于CTR的神经网络做了对比
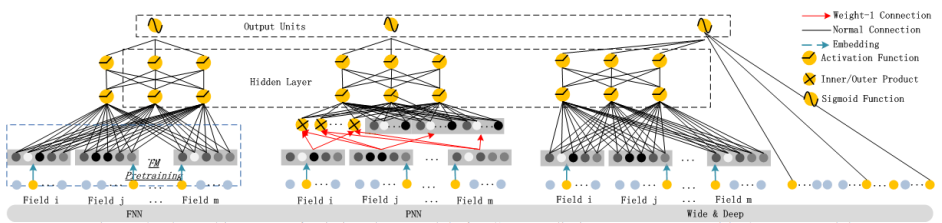
从预训练,特征维度以及特征工程的角度进行对比,发现
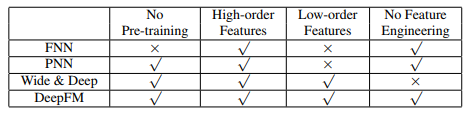
从实验效果来看,DeepFM的效果较好
参考:
1. https://arxiv.org/pdf/1703.04247.pdf
2. https://www.jianshu.com/p/6f1c2643d31b
3. https://blog.csdn.net/zynash2/article/details/79348540
4. https://blog.csdn.net/zynash2/article/details/79360195
实践参考:https://blog.csdn.net/john_xyz/article/details/78933253
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/131689.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
