大家好,又见面了,我是你们的朋友全栈君。


全栈工程师开发手册 (作者:栾鹏)
架构系列文章
应用往Kafka写数据的原因有很多:用户行为分析、日志存储、异步通信等。多样化的使用场景带来了多样化的需求:消息是否能丢失?是否容忍重复?消息的吞吐量?消息的延迟?
kafka介绍
Kafka属于Apache组织,是一个高性能跨语言分布式发布订阅消息队列系统[7]。它的主要特点有:
- 以时间复杂度O(1)的方式提供消息持久化能力,并对大数据量能保证常数时间的访问性能;
- 高吞吐率,单台服务器可以达到每秒几十万的吞吐速率;
- 支持服务器间的消息分区,支持分布式消费,同时保证了每个分区内的消息顺序;
- 轻量级,支持实时数据处理和离线数据处理两种方式。
1.1. 主要功能
根据官网的介绍,ApacheKafka®是一个分布式流媒体平台,它主要有3种功能:
1:发布和订阅消息流,这个功能类似于消息队列,这也是kafka归类为消息队列框架的原因
2:以容错的方式记录消息流,kafka以文件的方式来存储消息流
3:可以再消息发布的时候进行处理
1.2. 使用场景
1:在系统或应用程序之间构建可靠的用于传输实时数据的管道,消息队列功能
2:构建实时的流数据处理程序来变换或处理数据流,数据处理功能
kafka生产者
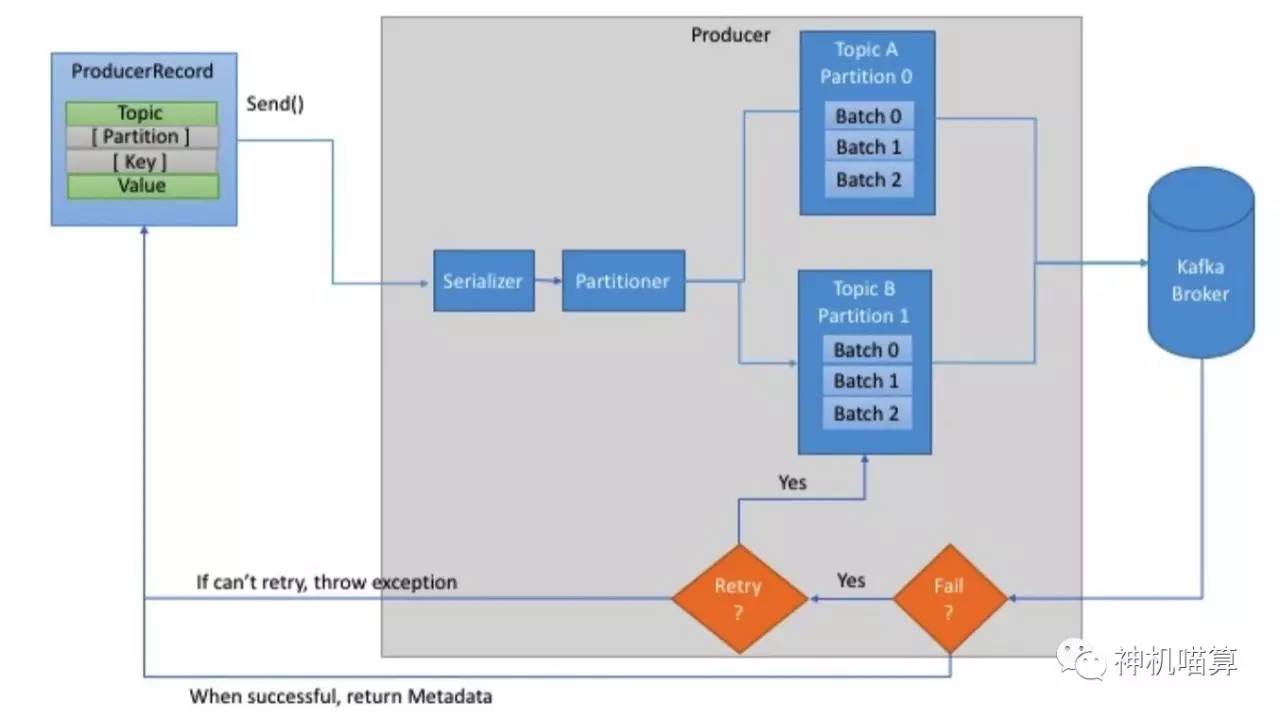

首先,创建ProducerRecord必须包含Topic和Value,key和partition可选。然后,序列化key和value对象为ByteArray,并发送到网络。
接下来,消息发送到partitioner。如果创建ProducerRecord时指定了partition,此时partitioner啥也不用做,简单的返回指定的partition即可。如果未指定partition,partitioner会基于ProducerRecord的key生成partition。producer选择好partition后,增加record到对应topic和partition的batch record。最后,专有线程负责发送batch record到合适的Kafka broker。
当broker收到消息时,它会返回一个应答(response)。如果消息成功写入Kafka,broker将返回RecordMetadata对象(包含topic,partition和offset);相反,broker将返回error。这时producer收到error会尝试重试发送消息几次,直到producer返回error。
实例化producer后,接着发送消息。这里主要有3种发送消息的方法:
-
立即发送:只管发送消息到server端,不care消息是否成功发送。大部分情况下,这种发送方式会成功,因为Kafka自身具有高可用性,producer会自动重试;但有时也会丢失消息;
-
同步发送:通过send()方法发送消息,并返回Future对象。get()方法会等待Future对象,看send()方法是否成功;
-
异步发送:通过带有回调函数的send()方法发送消息,当producer收到Kafka broker的response会触发回调函数
以上所有情况,一定要时刻考虑发送消息可能会失败,想清楚如何去处理异常。
通常我们是一个producer起一个线程开始发送消息。为了优化producer的性能,一般会有下面几种方式:单个producer起多个线程发送消息;使用多个producer。
kafka消费者
kafka的消费模式总共有3种:最多一次,最少一次,正好一次。为什么会有这3种模式,是因为客户端处理消息,提交反馈(commit)这两个动作不是原子性。
1.最多一次:客户端收到消息后,在处理消息前自动提交,这样kafka就认为consumer已经消费过了,偏移量增加。
2.最少一次:客户端收到消息,处理消息,再提交反馈。这样就可能出现消息处理完了,在提交反馈前,网络中断或者程序挂了,那么kafka认为这个消息还没有被consumer消费,产生重复消息推送。
3.正好一次:保证消息处理和提交反馈在同一个事务中,即有原子性。
本文从这几个点出发,详细阐述了如何实现以上三种方式。
At-most-once(最多一次)
设置enable.auto.commit为ture
设置 auto.commit.interval.ms为一个较小的时间间隔.
client不要调用commitSync(),kafka在特定的时间间隔内自动提交。
At-least-once(最少一次)
方法一
设置enable.auto.commit为false
client调用commitSync(),增加消息偏移;
方法二
设置enable.auto.commit为ture
设置 auto.commit.interval.ms为一个较大的时间间隔.
client调用commitSync(),增加消息偏移;
Exactly-once(正好一次)
3.1 思路
如果要实现这种方式,必须自己控制消息的offset,自己记录一下当前的offset,对消息的处理和offset的移动必须保持在同一个事务中,例如在同一个事务中,把消息处理的结果存到mysql数据库同时更新此时的消息的偏移。
3.2 实现
设置enable.auto.commit为false
保存ConsumerRecord中的offset到数据库
当partition分区发生变化的时候需要rebalance,有以下几个事件会触发分区变化
1 consumer订阅的topic中的分区大小发生变化
2 topic被创建或者被删除
3 consuer所在group中有个成员挂了
4 新的consumer通过调用join加入了group
此时 consumer通过实现ConsumerRebalanceListener接口,捕捉这些事件,对偏移量进行处理。
consumer通过调用seek(TopicPartition, long)方法,移动到指定的分区的偏移位置。
参考:https://blog.csdn.net/laojiaqi/article/details/79034798
Broker
Kafka是一个高吞吐量分布式消息系统,采用Scala和Java语言编写,它提供了快速、可扩展的、分布式、分区的和可复制的日志订阅服务。它由Producer、Broker、Consumer三部分构成.
Producer向某个Topic发布消息,而Consumer订阅某个Topic的消息。 一旦有某个Topic新产生的消息,Broker会传递给订阅它的所有Consumer,每个Topic分为多个分区,这样的设计有利于管理数据和负载均衡。
- Broker:消息中间件处理结点,一个Kafka节点就是一个broker,多个broker可以组成一个Kafka集群。
- Controller:中央控制器Control,负责管理分区和副本状态并执行管理着这些分区的重新分配。(里面涉及到partition leader 选举)
- ISR:同步副本组
Topic
在Kafka中,消息是按Topic组织的.
- Partition:topic物理上的分组,一个topic可以分为多个partition,每个partition是一个有序的队列。
- Segment:partition物理上由多个segment组成
- offset:每个partition都由一系列有序的、不可变的消息组成,这些消息被连续的追加到partition中. partition中的每个消息都有一个连续的序列号叫做offset,用于partition唯一标识一条消息.
topic中partition存储分布
在Kafka文件存储中,同一个topic下有多个不同partition,每个partition为一个目录,partiton命名规则为topic名称+有序序号,第一个partiton序号从0开始,序号最大值为partitions数量减1。
├── data0
│ ├── cleaner-offset-checkpoint
│ ├── client_mblogduration-35
│ │ ├── 00000000000004909731.index
│ │ ├── 00000000000004909731.log // 1G文件--Segment
│ │ ├── 00000000000005048975.index // 数字是Offset
│ │ ├── 00000000000005048975.log
│ ├── client_mblogduration-37
│ │ ├── 00000000000004955629.index
│ │ ├── 00000000000004955629.log
│ │ ├── 00000000000005098290.index
│ │ ├── 00000000000005098290.log
│ ├── __consumer_offsets-33
│ │ ├── 00000000000000105157.index
│ │ └── 00000000000000105157.log
│ ├── meta.properties
│ ├── recovery-point-offset-checkpoint
│ └── replication-offset-checkpoint
- cleaner-offset-checkpoint:存了每个log的最后清理offset
- meta.properties: broker.id 信息
- recovery-point-offset-checkpoint:表示已经刷写到磁盘的记录。recoveryPoint以下的数据都是已经刷 到磁盘上的了。
- replication-offset-checkpoint: 用来存储每个replica的HighWatermark的(high watermark (HW),表示已经被commited的message,HW以下的数据都是各个replicas间同步的,一致的。)
partiton中文件存储方式
每个partion(目录)由多个大小相等segment(段)数据文件中。但每个段segment file消息数量不一定相等,这种特性方便old segment file快速被删除。
每个partiton只需要支持顺序读写就行了,segment文件生命周期由服务端配置参数决定。
partiton中segment文件存储结构
partion中segment file组成和物理结构。
segment file组成:由2大部分组成,分别为index file和data file,此2个文件一一对应,成对出现,后缀”.index”和“.log”分别表示为segment索引文件、数据文件.
segment文件命名规则:partion全局的第一个segment从0开始,后续每个segment文件名为上一个segment文件最后一条消息的offset值。数值最大为64位long大小,19位数字字符长度,没有数字用0填充。
以一对segment file文件为例,说明segment中index<—->data file对应关系物理结构如下
- Index文件存储大量元数据,指向对应log文件中message的物理偏移地址。
- log数据文件存储大量消息
其中以Index文件中元数据3,497为例,依次在数据文件中表示第3个message(在全局partiton表示第368772个message)、以及该消息的物理偏移地址为497。
下面看看segment data file的内部
segment data file由许多message组成,下面详细说明message物理结构如下:
| 关键字 | 解释说明 |
|---|---|
| 8 byte offset | 该message在partition的offset |
| 4 byte message size | message大小 |
| 4 byte CRC32 | 用crc32校验message |
| 1 byte “magic” | 表示本次发布Kafka服务程序协议版本号 |
| 1 byte “attributes” | 表示为独立版本、或标识压缩类型、或编码类型。 |
| 4 byte key length | 表示key的长度,当key为-1时,K byte key字段不填 |
| K byte key | 可选 |
| value bytes payload | 表示实际消息数据。 |
2.4 在partition中如何通过offset查找message
例如读取offset=368776的message,需要通过下面2个步骤查找。
- 第一步查找segment file
- 上述图2为例,其中00000000000000000000.index表示最开始的文件,起始偏移量(offset)为0.第二个文件00000000000000368769.index的消息量起始偏移量为368770 = 368769 + 1.同样,第三个文件00000000000000737337.index的起始偏移量为737338=737337 + 1,其他后续文件依次类推,以起始偏移量命名并排序这些文件,只要根据offset 二分查找文件列表,就可以快速定位到具体文件。
当offset=368776时定位到00000000000000368769.index|log
- 第二步通过segment file查找message
- 通过第一步定位到segment file,当
offset=368776时,依次定位到00000000000000368769.index的元数据物理位置(这个较小,可以放在内存中,直接操作)和00000000000000368769.log的物理偏移地址,然后再通过00000000000000368769.log 顺序查找 直到offset=368776为止。
从上述图2.3节可知这样做的优点,segment index file采取稀疏索引存储方式,它减少索引文件大小,通过map可以直接内存操作,稀疏索引为数据文件的每个对应message设置一个元数据指针,它比稠密索引节省了更多的存储空间,但查找起来需要消耗更多的时间。
2.5 读写message总结
写message
- 消息从java堆转入page cache(即物理内存)。
- 由异步线程刷盘,消息从page cache刷入磁盘。
读message
- 消息直接从page cache转入socket发送出去。
- 当从page cache没有找到相应数据时,此时会产生磁盘IO,从磁
盘Load消息到page cache,然后直接从socket发出去
Kafka高效文件存储设计特点
- topic中一个parition大文件分成多个小文件段,通过多个小文件段,就容易定期清除或删除已经消费完文件,减少磁盘占用。
- 通过索引信息可以快速定位message和确定response的最大大小。
- 通过index元数据全部映射到memory,可以避免segment file的IO磁盘操作。
- 通过索引文件稀疏存储,可以大幅降低index文件元数据占用空间大小。
参考:https://www.cnblogs.com/byrhuangqiang/p/6364088.html
Kafka消费者
消费组与分区重平衡
可以看到,当新的消费者加入消费组,它会消费一个或多个分区,而这些分区之前是由其他消费者负责的;另外,当消费者离开消费组(比如重启、宕机等)时,它所消费的分区会分配给其他分区。这种现象称为重平衡(rebalance)。重平衡是Kafka一个很重要的性质,这个性质保证了高可用和水平扩展。不过也需要注意到,在重平衡期间,所有消费者都不能消费消息,因此会造成整个消费组短暂的不可用。而且,将分区进行重平衡也会导致原来的消费者状态过期,从而导致消费者需要重新更新状态,这段期间也会降低消费性能。后面我们会讨论如何安全的进行重平衡以及如何尽可能避免。
消费者通过定期发送心跳(hearbeat)到一个作为组协调者(group coordinator)的broker来保持在消费组内存活。这个broker不是固定的,每个消费组都可能不同。当消费者拉取消息或者提交时,便会发送心跳。
如果消费者超过一定时间没有发送心跳,那么它的会话(session)就会过期,组协调者会认为该消费者已经宕机,然后触发重平衡。可以看到,从消费者宕机到会话过期是有一定时间的,这段时间内该消费者的分区都不能进行消息消费;通常情况下,我们可以进行优雅关闭,这样消费者会发送离开的消息到组协调者,这样组协调者可以立即进行重平衡而不需要等待会话过期。
在0.10.1版本,Kafka对心跳机制进行了修改,将发送心跳与拉取消息进行分离,这样使得发送心跳的频率不受拉取的频率影响。另外更高版本的Kafka支持配置一个消费者多长时间不拉取消息但仍然保持存活,这个配置可以避免活锁(livelock)。活锁,是指应用没有故障但是由于某些原因不能进一步消费。
1.3. 详细介绍
Kafka目前主要作为一个分布式的发布订阅式的消息系统使用,下面简单介绍一下kafka的基本机制
1.3.1 消息传输流程
Producer即生产者,向Kafka集群发送消息,在发送消息之前,会对消息进行分类,即Topic,上图展示了两个producer发送了分类为topic1的消息,另外一个发送了topic2的消息。
Topic即主题,通过对消息指定主题可以将消息分类,消费者可以只关注自己需要的Topic中的消息
Consumer即消费者,消费者通过与kafka集群建立长连接的方式,不断地从集群中拉取消息,然后可以对这些消息进行处理。
从上图中就可以看出同一个Topic下的消费者和生产者的数量并不是对应的。
1.3.2 kafka服务器消息存储策略
谈到kafka的存储,就不得不提到分区,即partitions,创建一个topic时,同时可以指定分区数目,分区数越多,其吞吐量也越大,但是需要的资源也越多,同时也会导致更高的不可用性,kafka在接收到生产者发送的消息之后,会根据均衡策略将消息存储到不同的分区中。
在每个分区中,消息以顺序存储,最晚接收的的消息会最后被消费。
kafka中的message以topic的形式存在,topic在物理上又分为很多的partition,partition物理上由很多segment组成,segment是存放message的真正载体。
下面具体介绍下segment文件:
(1) 每个partition(目录)相当于一个巨型文件被平均分配到多个大小相等segment(段)数据文件中。但每个段segment file消息数量不一定相等,这种特性方便old segment file快速被删除。
(2) 每个partiton只需要支持顺序读写就行了,segment文件生命周期由服务端配置参数决定。
(3) segment file组成:由2大部分组成,分别为index file和data file,此2个文件一一对应,成对出现,后缀”.index”和“.log”分别表示为segment索引文件、数据文件.
(4) segment文件命名规则:partion全局的第一个segment从0开始,后续每个segment文件名为上一个segment文件最后一条消息的offset值。数值最大为64位long大小,19位数字字符长度,没有数字用0填充。
segment中index<—->data file对应关系物理结构如下:
index与log映射关系

.index文件存放的是message逻辑相对偏移量(相对offset=绝对offset-base offset)与在相应的.log文件中的物理位置(position)。但.index并不是为每条message都指定到物理位置的映射,而是以entry为单位,每条entry可以指定连续n条消息的物理位置映射(例如:假设有20000~20009共10条消息,.index文件可配置为每条entry
指定连续10条消息的物理位置映射,该例中,index entry会记录偏移量为20000的消息到其物理文件位置,一旦该条消息被定位,20001~20009可以很快查到。)。每个entry大小8字节,前4个字节是这个message相对于该log segment第一个消息offset(base offset)的相对偏移量,后4个字节是这个消息在log文件中的物理位置。
1.3.3 与生产者的交互
生产者在向kafka集群发送消息的时候,可以通过指定分区来发送到指定的分区中
也可以通过指定均衡策略来将消息发送到不同的分区中
如果不指定,就会采用默认的随机均衡策略,将消息随机的存储到不同的分区中
1.3.4 与消费者的交互
在消费者消费消息时,kafka使用offset来记录当前消费的位置
在kafka的设计中,可以有多个不同的group来同时消费同一个topic下的消息,如图,我们有两个不同的group同时消费,他们的的消费的记录位置offset各不项目,不互相干扰。
对于一个group而言,消费者的数量不应该多余分区的数量,因为在一个group中,每个分区至多只能绑定到一个消费者上,即一个消费者可以消费多个分区,一个分区只能给一个消费者消费
因此,若一个group中的消费者数量大于分区数量的话,多余的消费者将不会收到任何消息。
Kafka安装与使用
2.1. 下载
你可以在kafka官网: http://kafka.apache.org/downloads
下载到最新的kafka安装包,选择下载二进制版本的tgz文件,根据网络状态可能需要fq,这里我们选择的版本是kafka_2.11-1.1.0,目前的最新版
2.2. 安装
Kafka是使用scala编写的运行与jvm虚拟机上的程序,虽然也可以在windows上使用,但是kafka基本上是运行在linux服务器上,因此我们这里也使用linux来开始今天的实战。
首先确保你的机器上安装了jdk,kafka需要java运行环境,以前的kafka还需要zookeeper,新版的kafka已经内置了一个zookeeper环境,所以我们可以直接使用
说是安装,如果只需要进行最简单的尝试的话我们只需要解压到任意目录即可,这里我们将kafka压缩包解压到/home目录
2.3. 配置
在kafka解压目录下下有一个config的文件夹,里面放置的是我们的配置文件
consumer.properites 消费者配置,这个配置文件用于配置于2.5节中开启的消费者,此处我们使用默认的即可
producer.properties 生产者配置,这个配置文件用于配置于2.5节中开启的生产者,此处我们使用默认的即可
server.properties kafka服务器的配置,此配置文件用来配置kafka服务器,目前仅介绍几个最基础的配置
broker.id 申明当前kafka服务器在集群中的唯一ID,需配置为integer,并且集群中的每一个kafka服务器的id都应是唯一的,我们这里采用默认配置即可
listeners 申明此kafka服务器需要监听的端口号,如果是在本机上跑虚拟机运行可以不用配置本项,默认会使用localhost的地址,如果是在远程服务器上运行则必须配置,例如:listeners=PLAINTEXT://192.168.180.128:9092。并确保服务器的9092端口能够访问
zookeeper.connect 申明kafka所连接的zookeeper的地址 ,需配置为zookeeper的地址,由于本次使用的是kafka高版本中自带zookeeper,使用默认配置即可
zookeeper.connect=localhost:2181
当我们有多个应用,在不同的应用中都使用zookeer,都使用默认的zk端口的话就会2181端口冲突,我们可以设置自己的端口号,在config文件夹下zookeeper.properties文件中修改为
clientPort=2185
也就是zk开放接口为2185.
同时修改kafka的接入端口,server.properties文件中修改为
zookeeper.connect=localhost:2185
这样我们就成功修改了kafka里面的端口号
2.4. 运行
启动zookeeper
cd进入kafka解压目录,输入
bin/zookeeper-server-start.sh config/zookeeper.properties
启动zookeeper成功后会看到如下的输出
2.启动kafka
cd进入kafka解压目录,输入
bin/kafka-server-start.sh config/server.properties
启动kafka成功后会看到如下的输出
2.5. 第一个消息
2.5.1 创建一个topic
Kafka通过topic对同一类的数据进行管理,同一类的数据使用同一个topic可以在处理数据时更加的便捷
在kafka解压目录打开终端,输入
bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 1 --topic test
创建一个名为test的topic
在创建topic后可以通过输入
bin/kafka-topics.sh --list --zookeeper localhost:2181
来查看已经创建的topic
2.5.2 创建一个消息消费者
在kafka解压目录打开终端,输入
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic test --from-beginning
可以创建一个用于消费topic为test的消费者
消费者创建完成之后,因为还没有发送任何数据,因此这里在执行后没有打印出任何数据
不过别着急,不要关闭这个终端,打开一个新的终端,接下来我们创建第一个消息生产者
2.5.3 创建一个消息生产者
在kafka解压目录打开一个新的终端,输入
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
在执行完毕后会进入的编辑器页面
在发送完消息之后,可以回到我们的消息消费者终端中,可以看到,终端中已经打印出了我们刚才发送的消息
kafka清理数据和topic
1、删除kafka存储目录(server.properties文件log.dirs配置,默认为”/tmp/kafka-logs”)相关topic目录
2、Kafka 删除topic的命令是:
./bin/kafka-topics --delete --zookeeper 【zookeeper server】 --topic 【topic name】
如果kafaka启动时加载的配置文件中server.properties没有配置delete.topic.enable=true,那么此时的删除并不是真正的删除,而是把topic标记为:marked for deletion
你可以通过命令:
./bin/kafka-topics --zookeeper 【zookeeper server】 --list 来查看所有topic
此时你若想真正删除它,可以如下操作:
(1)登录zookeeper客户端:命令:./bin/zookeeper-client
(2)找到topic所在的目录:ls /brokers/topics
(3)找到要删除的topic,执行命令:rmr /brokers/topics/【topic name】即可,此时topic被彻底删除。
另外被标记为marked for deletion的topic你可以在zookeeper客户端中通过命令获得:ls /admin/delete_topics/【topic name】,
如果你删除了此处的topic,那么marked for deletion 标记消失
zookeeper 的config中也有有关topic的信息: ls /config/topics/【topic name】暂时不知道有什么用
总结:
彻底删除topic:
1、删除kafka存储目录(server.properties文件log.dirs配置,默认为”/tmp/kafka-logs”)相关topic目录
2、如果配置了delete.topic.enable=true直接通过命令删除,如果命令删除不掉,直接通过zookeeper-client 删除掉broker下的topic即可。
python操作kafka
我们已经知道了kafka是一个消息队列,下面我们来学习怎么向kafka中传递数据和如何从kafka中获取数据
首先安装python的kafka库
pip install kafka
按照官网的样例,先跑一个应用
1、生产者demo:
from kafka import KafkaProducer
from kafka.errors import KafkaError
producer = KafkaProducer(bootstrap_servers=['broker1:1234'])
# Asynchronous by default
future = producer.send('my-topic', b'raw_bytes')
# Block for 'synchronous' sends
try:
record_metadata = future.get(timeout=10)
except KafkaError:
# Decide what to do if produce request failed...
log.exception()
pass
# Successful result returns assigned partition and offset
print (record_metadata.topic)
print (record_metadata.partition)
print (record_metadata.offset)
# produce keyed messages to enable hashed partitioning
producer.send('my-topic', key=b'foo', value=b'bar')
# encode objects via msgpack
producer = KafkaProducer(value_serializer=msgpack.dumps)
producer.send('msgpack-topic', {'key': 'value'})
# produce json messages
producer = KafkaProducer(value_serializer=lambda m: json.dumps(m).encode('ascii'))
producer.send('json-topic', {'key': 'value'})
# produce asynchronously
for _ in range(100):
producer.send('my-topic', b'msg')
def on_send_success(record_metadata):
print(record_metadata.topic)
print(record_metadata.partition)
print(record_metadata.offset)
def on_send_error(excp):
log.error('I am an errback', exc_info=excp)
# handle exception
# produce asynchronously with callbacks
producer.send('my-topic', b'raw_bytes').add_callback(on_send_success).add_errback(on_send_error)
# block until all async messages are sent
producer.flush()
# configure multiple retries
producer = KafkaProducer(retries=5)
启动后生产者便可以将字节流发送到kafka服务器.
2、消费者(简单demo):
from kafka import KafkaConsumer
consumer = KafkaConsumer('test',bootstrap_servers=['127.0.0.1:9092']) #参数为接收主题和kafka服务器地址
# 这是一个永久堵塞的过程,生产者消息会缓存在消息队列中,并且不删除,所以每个消息在消息队列中都有偏移
for message in consumer: # consumer是一个消息队列,当后台有消息时,这个消息队列就会自动增加.所以遍历也总是会有数据,当消息队列中没有数据时,就会堵塞等待消息带来
print("%s:%d:%d: key=%s value=%s" % (message.topic, message.partition,message.offset, message.key,message.value))
启动后消费者可以从kafka服务器获取数据.
3、消费者(消费群组)
from kafka import KafkaConsumer
# 使用group,对于同一个group的成员只有一个消费者实例可以读取数据
consumer = KafkaConsumer('test',group_id='my-group',bootstrap_servers=['127.0.0.1:9092'])
for message in consumer:
print("%s:%d:%d: key=%s value=%s" % (message.topic, message.partition,message.offset, message.key,message.value))
启动多个消费者,只有其中某一个成员可以消费到,满足要求,消费组可以横向扩展提高处理能力
4、消费者(读取目前最早可读的消息)
from kafka import KafkaConsumer
consumer = KafkaConsumer('test',auto_offset_reset='earliest',bootstrap_servers=['127.0.0.1:9092'])
for message in consumer:
print("%s:%d:%d: key=%s value=%s" % (message.topic, message.partition,message.offset, message.key,message.value))
auto_offset_reset:重置偏移量,earliest移到最早的可用消息,latest最新的消息,默认为latest
源码定义:{‘smallest’: ‘earliest’, ‘largest’: ‘latest’}
5、消费者(手动设置偏移量)
# ==========读取指定位置消息===============
from kafka import KafkaConsumer
from kafka.structs import TopicPartition
consumer = KafkaConsumer('test',bootstrap_servers=['127.0.0.1:9092'])
print(consumer.partitions_for_topic("test")) #获取test主题的分区信息
print(consumer.topics()) #获取主题列表
print(consumer.subscription()) #获取当前消费者订阅的主题
print(consumer.assignment()) #获取当前消费者topic、分区信息
print(consumer.beginning_offsets(consumer.assignment())) #获取当前消费者可消费的偏移量
consumer.seek(TopicPartition(topic='test', partition=0), 5) #重置偏移量,从第5个偏移量消费
for message in consumer:
print ("%s:%d:%d: key=%s value=%s" % (message.topic, message.partition,message.offset, message.key,message.value))
6、消费者(订阅多个主题)
# =======订阅多个消费者==========
from kafka import KafkaConsumer
from kafka.structs import TopicPartition
consumer = KafkaConsumer(bootstrap_servers=['127.0.0.1:9092'])
consumer.subscribe(topics=('test','test0')) #订阅要消费的主题
print(consumer.topics())
print(consumer.position(TopicPartition(topic='test', partition=0))) #获取当前主题的最新偏移量
for message in consumer:
print ("%s:%d:%d: key=%s value=%s" % (message.topic, message.partition,message.offset, message.key,message.value))
7、消费者(手动拉取消息)
from kafka import KafkaConsumer
import time
consumer = KafkaConsumer(bootstrap_servers=['127.0.0.1:9092'])
consumer.subscribe(topics=('test','test0'))
while True:
msg = consumer.poll(timeout_ms=5) #从kafka获取消息
print(msg)
time.sleep(2)
8、消费者(消息挂起与恢复)
# ==============消息恢复和挂起===========
from kafka import KafkaConsumer
from kafka.structs import TopicPartition
import time
consumer = KafkaConsumer(bootstrap_servers=['127.0.0.1:9092'])
consumer.subscribe(topics=('test'))
consumer.topics()
consumer.pause(TopicPartition(topic=u'test', partition=0)) # pause执行后,consumer不能读取,直到调用resume后恢复。
num = 0
while True:
print(num)
print(consumer.paused()) #获取当前挂起的消费者
msg = consumer.poll(timeout_ms=5)
print(msg)
time.sleep(2)
num = num + 1
if num == 10:
print("resume...")
consumer.resume(TopicPartition(topic='test', partition=0))
print("resume......")
pause执行后,consumer不能读取,直到调用resume后恢复。
下面是一个完整的demo
from kafka import KafkaConsumer
# To consume latest messages and auto-commit offsets
consumer = KafkaConsumer('my-topic',
group_id='my-group',
bootstrap_servers=['localhost:9092'])
for message in consumer:
# message value and key are raw bytes -- decode if necessary!
# e.g., for unicode: `message.value.decode('utf-8')`
print ("%s:%d:%d: key=%s value=%s" % (message.topic, message.partition,
message.offset, message.key,
message.value))
# consume earliest available messages, don't commit offsets
KafkaConsumer(auto_offset_reset='earliest', enable_auto_commit=False)
# consume json messages
KafkaConsumer(value_deserializer=lambda m: json.loads(m.decode('ascii')))
# consume msgpack
KafkaConsumer(value_deserializer=msgpack.unpackb)
# StopIteration if no message after 1sec
KafkaConsumer(consumer_timeout_ms=1000)
# Subscribe to a regex topic pattern
consumer = KafkaConsumer()
consumer.subscribe(pattern='^awesome.*')
# Use multiple consumers in parallel w/ 0.9 kafka brokers
# typically you would run each on a different server / process / CPU
consumer1 = KafkaConsumer('my-topic',
group_id='my-group',
bootstrap_servers='my.server.com')
consumer2 = KafkaConsumer('my-topic',
group_id='my-group',
bootstrap_servers='my.server.com')
Python创建自定义的Kafka Topic
client = KafkaClient(bootstrap_servers=brokers)
if topic not in client.cluster.topics(exclude_internal_topics=True): # Topic不存在
request = admin.CreateTopicsRequest_v0(
create_topic_requests=[(
topic,
num_partitions,
-1, # replication unset.
[], # Partition assignment.
[(key, value) for key, value in configs.items()], # Configs
)],
timeout=timeout_ms
)
future = client.send(2, request) # 2是Controller,发送给其他Node都创建失败。
client.poll(timeout_ms=timeout_ms, future=future, sleep=False) # 这里
result = future.value
# error_code = result.topic_error_codes[0][1]
print("CREATE TOPIC RESPONSE: ", result) # 0 success, 41 NOT_CONTROLLER, 36 ALREADY_EXISTS
client.close()
else: # Topic已经存在
print("Topic already exists!")
return
kafka的配置
在kafka/config/目录下面有3个配置文件:
producer.properties
consumer.properties
server.properties
kafka的配置分为 broker(server.properties)、producter(producer.properties)、consumer(consumer.properties)三个不同的配置
一 BROKER 的全局配置
最为核心的三个配置 broker.id、log.dir、zookeeper.connect 。
------------------------------------------- 系统 相关 -------------------------------------------
##每一个broker在集群中的唯一标示,要求是正数。在改变IP地址,不改变broker.id的话不会影响consumers
broker.id =1
##kafka数据的存放地址,多个地址的话用逗号分割 /tmp/kafka-logs-1,/tmp/kafka-logs-2
log.dirs = /tmp/kafka-logs
##提供给客户端响应的端口
port =6667
##消息体的最大大小,单位是字节
message.max.bytes =1000000
## broker 处理消息的最大线程数,一般情况下不需要去修改
num.network.threads =3
## broker处理磁盘IO 的线程数 ,数值应该大于你的硬盘数
num.io.threads =8
## 一些后台任务处理的线程数,例如过期消息文件的删除等,一般情况下不需要去做修改
background.threads =4
## 等待IO线程处理的请求队列最大数,若是等待IO的请求超过这个数值,那么会停止接受外部消息,算是一种自我保护机制
queued.max.requests =500
##broker的主机地址,若是设置了,那么会绑定到这个地址上,若是没有,会绑定到所有的接口上,并将其中之一发送到ZK,一般不设置
host.name
## 打广告的地址,若是设置的话,会提供给producers, consumers,其他broker连接,具体如何使用还未深究
advertised.host.name
## 广告地址端口,必须不同于port中的设置
advertised.port
## socket的发送缓冲区,socket的调优参数SO_SNDBUFF
socket.send.buffer.bytes =100*1024
## socket的接受缓冲区,socket的调优参数SO_RCVBUFF
socket.receive.buffer.bytes =100*1024
## socket请求的最大数值,防止serverOOM,message.max.bytes必然要小于socket.request.max.bytes,会被topic创建时的指定参数覆盖
socket.request.max.bytes =100*1024*1024
------------------------------------------- LOG 相关 -------------------------------------------
## topic的分区是以一堆segment文件存储的,这个控制每个segment的大小,会被topic创建时的指定参数覆盖
log.segment.bytes =1024*1024*1024
## 这个参数会在日志segment没有达到log.segment.bytes设置的大小,也会强制新建一个segment 会被 topic创建时的指定参数覆盖
log.roll.hours =24*7
## 日志清理策略 选择有:delete和compact 主要针对过期数据的处理,或是日志文件达到限制的额度,会被 topic创建时的指定参数覆盖
log.cleanup.policy = delete
## 数据存储的最大时间 超过这个时间 会根据log.cleanup.policy设置的策略处理数据,也就是消费端能够多久去消费数据
## log.retention.bytes和log.retention.minutes任意一个达到要求,都会执行删除,会被topic创建时的指定参数覆盖
log.retention.minutes=7days
指定日志每隔多久检查看是否可以被删除,默认1分钟
log.cleanup.interval.mins=1
## topic每个分区的最大文件大小,一个topic的大小限制 = 分区数*log.retention.bytes 。-1没有大小限制
## log.retention.bytes和log.retention.minutes任意一个达到要求,都会执行删除,会被topic创建时的指定参数覆盖
log.retention.bytes=-1
## 文件大小检查的周期时间,是否处罚 log.cleanup.policy中设置的策略
log.retention.check.interval.ms=5minutes
## 是否开启日志压缩
log.cleaner.enable=false
## 日志压缩运行的线程数
log.cleaner.threads =1
## 日志压缩时候处理的最大大小
log.cleaner.io.max.bytes.per.second=None
## 日志压缩去重时候的缓存空间 ,在空间允许的情况下,越大越好
log.cleaner.dedupe.buffer.size=500*1024*1024
## 日志清理时候用到的IO块大小 一般不需要修改
log.cleaner.io.buffer.size=512*1024
## 日志清理中hash表的扩大因子 一般不需要修改
log.cleaner.io.buffer.load.factor =0.9
## 检查是否处罚日志清理的间隔
log.cleaner.backoff.ms =15000
## 日志清理的频率控制,越大意味着更高效的清理,同时会存在一些空间上的浪费,会被topic创建时的指定参数覆盖
log.cleaner.min.cleanable.ratio=0.5
## 对于压缩的日志保留的最长时间,也是客户端消费消息的最长时间,同log.retention.minutes的区别在于一个控制未压缩数据,一个控制压缩后的数据。会被topic创建时的指定参数覆盖
log.cleaner.delete.retention.ms =1day
## 对于segment日志的索引文件大小限制,会被topic创建时的指定参数覆盖
log.index.size.max.bytes =10*1024*1024
## 当执行一个fetch操作后,需要一定的空间来扫描最近的offset大小,设置越大,代表扫描速度越快,但是也更好内存,一般情况下不需要搭理这个参数
log.index.interval.bytes =4096
## log文件"sync"到磁盘之前累积的消息条数
## 因为磁盘IO操作是一个慢操作,但又是一个"数据可靠性"的必要手段
## 所以此参数的设置,需要在"数据可靠性"与"性能"之间做必要的权衡.
## 如果此值过大,将会导致每次"fsync"的时间较长(IO阻塞)
## 如果此值过小,将会导致"fsync"的次数较多,这也意味着整体的client请求有一定的延迟.
## 物理server故障,将会导致没有fsync的消息丢失.
log.flush.interval.messages=None
## 检查是否需要固化到硬盘的时间间隔
log.flush.scheduler.interval.ms =3000
## 仅仅通过interval来控制消息的磁盘写入时机,是不足的.
## 此参数用于控制"fsync"的时间间隔,如果消息量始终没有达到阀值,但是离上一次磁盘同步的时间间隔
## 达到阀值,也将触发.
log.flush.interval.ms = None
## 文件在索引中清除后保留的时间 一般不需要去修改
log.delete.delay.ms =60000
## 控制上次固化硬盘的时间点,以便于数据恢复 一般不需要去修改
log.flush.offset.checkpoint.interval.ms =60000
------------------------------------------- TOPIC 相关 -------------------------------------------
## 是否允许自动创建topic ,若是false,就需要通过命令创建topic
auto.create.topics.enable =true
## 一个topic ,默认分区的replication个数 ,不得大于集群中broker的个数
default.replication.factor =1
## 每个topic的分区个数,若是在topic创建时候没有指定的话 会被topic创建时的指定参数覆盖
num.partitions =1
实例 --replication-factor3--partitions1--topic replicated-topic :名称replicated-topic有一个分区,分区被复制到三个broker上。
----------------------------------复制(Leader、replicas) 相关 ----------------------------------
## partition leader与replicas之间通讯时,socket的超时时间
controller.socket.timeout.ms =30000
## partition leader与replicas数据同步时,消息的队列尺寸
controller.message.queue.size=10
## replicas响应partition leader的最长等待时间,若是超过这个时间,就将replicas列入ISR(in-sync replicas),并认为它是死的,不会再加入管理中
replica.lag.time.max.ms =10000
## 如果follower落后与leader太多,将会认为此follower[或者说partition relicas]已经失效
## 通常,在follower与leader通讯时,因为网络延迟或者链接断开,总会导致replicas中消息同步滞后
## 如果消息之后太多,leader将认为此follower网络延迟较大或者消息吞吐能力有限,将会把此replicas迁移
## 到其他follower中.
## 在broker数量较少,或者网络不足的环境中,建议提高此值.
replica.lag.max.messages =4000
##follower与leader之间的socket超时时间
replica.socket.timeout.ms=30*1000
## leader复制时候的socket缓存大小
replica.socket.receive.buffer.bytes=64*1024
## replicas每次获取数据的最大大小
replica.fetch.max.bytes =1024*1024
## replicas同leader之间通信的最大等待时间,失败了会重试
replica.fetch.wait.max.ms =500
## fetch的最小数据尺寸,如果leader中尚未同步的数据不足此值,将会阻塞,直到满足条件
replica.fetch.min.bytes =1
## leader 进行复制的线程数,增大这个数值会增加follower的IO
num.replica.fetchers=1
## 每个replica检查是否将最高水位进行固化的频率
replica.high.watermark.checkpoint.interval.ms =5000
## 是否允许控制器关闭broker ,若是设置为true,会关闭所有在这个broker上的leader,并转移到其他broker
controlled.shutdown.enable =false
## 控制器关闭的尝试次数
controlled.shutdown.max.retries =3
## 每次关闭尝试的时间间隔
controlled.shutdown.retry.backoff.ms =5000
## 是否自动平衡broker之间的分配策略
auto.leader.rebalance.enable =false
## leader的不平衡比例,若是超过这个数值,会对分区进行重新的平衡
leader.imbalance.per.broker.percentage =10
## 检查leader是否不平衡的时间间隔
leader.imbalance.check.interval.seconds =300
## 客户端保留offset信息的最大空间大小
offset.metadata.max.bytes
----------------------------------ZooKeeper 相关----------------------------------
##zookeeper集群的地址,可以是多个,多个之间用逗号分割 hostname1:port1,hostname2:port2,hostname3:port3
zookeeper.connect = localhost:2181
## ZooKeeper的最大超时时间,就是心跳的间隔,若是没有反映,那么认为已经死了,不易过大
zookeeper.session.timeout.ms=6000
## ZooKeeper的连接超时时间
zookeeper.connection.timeout.ms =6000
## ZooKeeper集群中leader和follower之间的同步实际那
zookeeper.sync.time.ms =2000
配置的修改
其中一部分配置是可以被每个topic自身的配置所代替,例如
新增配置
bin/kafka-topics.sh --zookeeper localhost:2181--create --topic my-topic --partitions1--replication-factor1--config max.message.bytes=64000--config flush.messages=1
修改配置
bin/kafka-topics.sh --zookeeper localhost:2181--alter --topic my-topic --config max.message.bytes=128000
删除配置 :
bin/kafka-topics.sh --zookeeper localhost:2181--alter --topic my-topic --deleteConfig max.message.bytes
二 CONSUMER 配置
最为核心的配置是group.id、zookeeper.connect
## Consumer归属的组ID,broker是根据group.id来判断是队列模式还是发布订阅模式,非常重要
group.id
## 消费者的ID,若是没有设置的话,会自增
consumer.id
## 一个用于跟踪调查的ID ,最好同group.id相同
client.id = group id value
## 对于zookeeper集群的指定,可以是多个 hostname1:port1,hostname2:port2,hostname3:port3 必须和broker使用同样的zk配置
zookeeper.connect=localhost:2182
## zookeeper的心跳超时时间,超过这个时间就认为是dead消费者
zookeeper.session.timeout.ms =6000
## zookeeper的等待连接时间
zookeeper.connection.timeout.ms =6000
## zookeeper的follower同leader的同步时间
zookeeper.sync.time.ms =2000
## 当zookeeper中没有初始的offset时候的处理方式 。smallest :重置为最小值 largest:重置为最大值 anythingelse:抛出异常
auto.offset.reset = largest
## socket的超时时间,实际的超时时间是:max.fetch.wait + socket.timeout.ms.
socket.timeout.ms=30*1000
## socket的接受缓存空间大小
socket.receive.buffer.bytes=64*1024
##从每个分区获取的消息大小限制
fetch.message.max.bytes =1024*1024
## 是否在消费消息后将offset同步到zookeeper,当Consumer失败后就能从zookeeper获取最新的offset
auto.commit.enable =true
## 自动提交的时间间隔
auto.commit.interval.ms =60*1000
## 用来处理消费消息的块,每个块可以等同于fetch.message.max.bytes中数值
queued.max.message.chunks =10
## 当有新的consumer加入到group时,将会reblance,此后将会有partitions的消费端迁移到新
## 的consumer上,如果一个consumer获得了某个partition的消费权限,那么它将会向zk注册
##"Partition Owner registry"节点信息,但是有可能此时旧的consumer尚没有释放此节点,
## 此值用于控制,注册节点的重试次数.
rebalance.max.retries =4
## 每次再平衡的时间间隔
rebalance.backoff.ms =2000
## 每次重新选举leader的时间
refresh.leader.backoff.ms
## server发送到消费端的最小数据,若是不满足这个数值则会等待,知道满足数值要求
fetch.min.bytes =1
## 若是不满足最小大小(fetch.min.bytes)的话,等待消费端请求的最长等待时间
fetch.wait.max.ms =100
## 指定时间内没有消息到达就抛出异常,一般不需要改
consumer.timeout.ms = -1
三 PRODUCER 的配置
比较核心的配置:metadata.broker.list、request.required.acks、producer.type、serializer.class
## 消费者获取消息元信息(topics, partitions and replicas)的地址,配置格式是:host1:port1,host2:port2,也可以在外面设置一个vip
metadata.broker.list
##消息的确认模式
##0:不保证消息的到达确认,只管发送,低延迟但是会出现消息的丢失,在某个server失败的情况下,有点像TCP
##1:发送消息,并会等待leader 收到确认后,一定的可靠性
## -1:发送消息,等待leader收到确认,并进行复制操作后,才返回,最高的可靠性
request.required.acks =0
## 消息发送的最长等待时间
request.timeout.ms =10000
## socket的缓存大小
send.buffer.bytes=100*1024
## key的序列化方式,若是没有设置,同serializer.class
key.serializer.class
## 分区的策略,默认是取模
partitioner.class=kafka.producer.DefaultPartitioner
## 消息的压缩模式,默认是none,可以有gzip和snappy
compression.codec = none
## 可以针对默写特定的topic进行压缩
compressed.topics=null
## 消息发送失败后的重试次数
message.send.max.retries =3
## 每次失败后的间隔时间
retry.backoff.ms =100
## 生产者定时更新topic元信息的时间间隔 ,若是设置为0,那么会在每个消息发送后都去更新数据
topic.metadata.refresh.interval.ms =600*1000
## 用户随意指定,但是不能重复,主要用于跟踪记录消息
client.id=""
------------------------------------------- 消息模式 相关 -------------------------------------------
## 生产者的类型 async:异步执行消息的发送 sync:同步执行消息的发送
producer.type=sync
## 异步模式下,那么就会在设置的时间缓存消息,并一次性发送
queue.buffering.max.ms =5000
## 异步的模式下 最长等待的消息数
queue.buffering.max.messages =10000
## 异步模式下,进入队列的等待时间 若是设置为0,那么要么进入队列,要么直接抛弃
queue.enqueue.timeout.ms = -1
## 异步模式下,每次发送的最大消息数,前提是触发了queue.buffering.max.messages或是queue.buffering.max.ms的限制
batch.num.messages=200
## 消息体的系列化处理类 ,转化为字节流进行传输
serializer.class= kafka.serializer.DefaultEncoder
参考:
https://www.cnblogs.com/hei12138/p/7805475.html
https://blog.csdn.net/zt3032/article/details/78756293
https://kafka-python.readthedocs.io/en/master/index.html
购买文章,更多优惠,免费送视频课
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/131654.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...