大家好,又见面了,我是你们的朋友全栈君。
在OkHttp的源码中经常能看到Okio的身影,所以单独拿出来学习一下,作为OkHttp的低层IO库,Okio确实比传统的java输入输出流读写更加方便高效。Okio补充了java.io和java.nio的不足,使访问、存储和处理数据更加容易,它起初只是作为OKHttp的一个组件,现在你可以独立的使用它来解决一些IO问题。
ByteStrings and Buffers
Okio是围绕这两种类型构建的,它们将大量功能打包到一个简单的API中:
ByteString是不可变的字节序列。对于字符数据,最基本的就是String。而ByteString就像是String的兄弟一般,它使得将二进制数据作为一个变量值变得容易。这个类很聪明:它知道如何将自己编码和解码为十六进制、base64和utf-8。Buffer是一个可变的字节序列。像Arraylist一样,你不需要预先设置缓冲区的大小。你可以将缓冲区读写为一个队列:将数据写到队尾,然后从队头读取。
在内部,
ByteString和Buffer做了一些聪明的事情来节省CPU和内存。如果您将UTF-8字符串编码为ByteString,它会缓存对该字符串的引用,这样,如果您稍后对其进行解码,就不需要做任何工作。
Buffer是作为片段的链表实现的。当您将数据从一个缓冲区移动到另一个缓冲区时,它会重新分配片段的持有关系,而不是跨片段复制数据。这对多线程特别有用:与网络交互的子线程可以与工作线程交换数据,而无需任何复制或多余的操作。
Sources and Sinks
java.io设计的一个优雅部分是如何对流进行分层来处理加密和压缩等转换。Okio有自己的stream类型:Source和Sink,分别类似于java的Inputstream和Outputstream,但是有一些关键区别:
- 超时(Timeouts)。流提供了对底层I/O超时机制的访问。与
java.io的socket字流不同,read()和write()方法都给予超时机制。- 易于实施。
source只声明了三个方法:read()、close()和timeout()。没有像available()或单字节读取这样会导致正确性和性能意外的危险操作。- 使用方便。虽然
source和sink的实现只有三种方法可写,但是调用方可以实现Bufferedsource和Bufferedsink接口, 这两个接口提供了丰富API能够满足你所需的一切。- 字节流和字符流之间没有人为的区别。都是数据。你可以以字节、UTF-8字符串、big-endian的32位整数、little-endian的短整数等任何你想要的形式进行读写;不再有
InputStreamReader!- 易于测试。
Buffer类同时实现了BufferedSource和BufferedSink接口,因此测试代码简单明了。
Sources 和 Sinks分别与
InputStream和OutputStream交互操作。你可以将任何Source看做InputStream,也可以将任何InputStream当做Source。对于Sink和Outputstream也是如此。
读文本文件
public void readLines(File file) throws IOException {
Source fileSource = Okio.source(file);
BufferedSource bufferedSource = Okio.buffer(fileSource);
for (String line; (line = bufferedSource.readUtf8Line()) != null; ) {
System.out.println(line);
}
bufferedSource.close();
}
这个示例代码是用来读取文本文件的,Okio通过Okio.source(File) 的方式来读取文件流,它返回的是一个Source对象,但是Source对象的方法是比较少的(只有3个),因此Okio提供了一个装饰者对象接口BufferedSource,通过Okio.buffer(fileSource)来生成,这个方法内部实际会生成一个RealBufferedSource类对象,RealBufferedSource内部持有Buffer缓冲对象可使IO速度更快,该类实现了BufferedSource接口,而BufferedSource接口提供了大量丰富的接口方法:
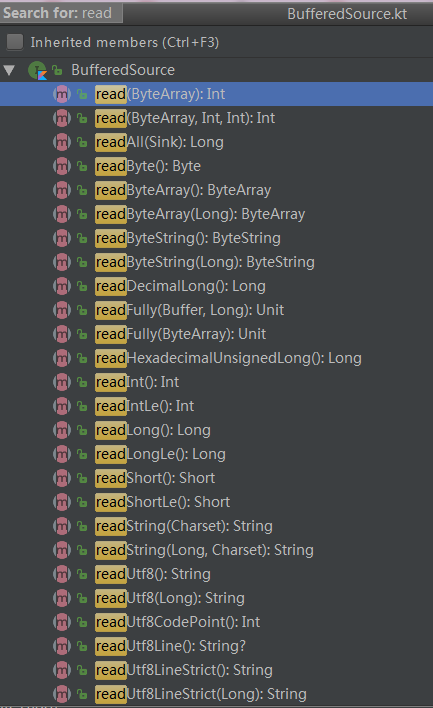

可以看到,几乎你想从输入流中读取任何的数据类型都可以,而不需要你自己去转换,可以说是非常强大而且人性化了,除了read方法以外,还有一些别的方法:

在上面的示例代码中,打开输入流对象的方法需要负责关闭对象资源,调用close方法,okio官方推荐使用java的try-with-source语法,上面示例代码可以写成下面这样:
public void readLines(File file) throws IOException {
try (BufferedSource bufferedSource = Okio.buffer(Okio.source(file))) {
for (String line; (line = bufferedSource.readUtf8Line()) != null; ) {
System.out.println(line);
}
}
}
try-with-source是jdk1.7开始提供的语法糖,在try语句()里面的资源对象,jdk最终会自动调用它的close方法去关闭它, 即便try里有多个资源对象也是可以的,这样就不用你手动去关闭资源了。但是在android里面使用的话,会提示你要求API level最低为19才可以。
readUtf8Line()方法适用于大多数文件。对于某些用例,还可以考虑使用readUtf8LineStrict()。类似readUtf8Line(),但它要求每一行都以\n或\r\n结尾。如果在这之前遇到文件结尾,它将抛出一个EOFException。它还允许设置一个字节限制来防止错误的输入。
public void readLines(File file) throws IOException {
try (BufferedSource source = Okio.buffer(Okio.source(file))) {
while (!source.exhausted()) {
String line = source.readUtf8LineStrict(1024L);
System.out.println(line);
}
}
}
写文本文件
public void writeEnv(File file) throws IOException {
Sink fileSink = Okio.sink(file);
BufferedSink bufferedSink = Okio.buffer(fileSink);
for (Map.Entry<String, String> entry : System.getenv().entrySet()) {
bufferedSink.writeUtf8(entry.getKey());
bufferedSink.writeUtf8("=");
bufferedSink.writeUtf8(entry.getValue());
bufferedSink.writeUtf8("\n");
}
bufferedSink.close();
}
类似于读文件使用Source和BufferedSource, 写文件的话,则是使用的Sink 和 BufferedSink,同样的在BufferedSink接口中也提供了丰富的接口方法:
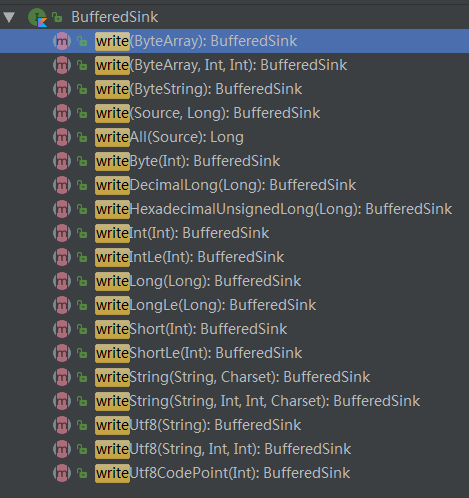
其中Okio.buffer(fileSink)内部返回的实现对象是一个RealBufferedSink类的对象, 跟RealBufferedSource一样它也是一个装饰者对象,具备Buffer缓冲功能。同样,以上代码可以使用jdk的try-with-source语法获得更加简便的写法:
public void writeEnv(File file) throws IOException {
try (BufferedSink sink = Okio.buffer(Okio.sink(file))) {
sink.writeUtf8("啊啊啊")
.writeUtf8("=")
.writeUtf8("aaa")
.writeUtf8("\n");
}
}
其中的换行符\n,Okio没有提供单独的api方法,而是要你手动写,因为这个跟操作系统有关,不过你可以使用System.lineSeparator()来代替\n,这个方法在Windows上返回的是"\r\n"在UNIX上返回的是"\n"。
在上面的代码中,对writeUtf8()进行了四次调用, 这样要比下面的代码更高效,因为虚拟机不必对临时字符串进行创建和垃圾回收。
sink.writeUtf8(entry.getKey() + "=" + entry.getValue() + "\n");
Gzip压缩和读取
//zip压缩
GzipSink gzipSink = new GzipSink(Okio.sink(file));
BufferedSink bufferedSink = Okio.buffer(gzipSink);
bufferedSink.writeUtf8("this is zip file");
bufferedSink.flush();
bufferedSink.close();
//读取zip
GzipSource gzipSource = new GzipSource(Okio.source(file));
BufferedSource bufferedSource = Okio.buffer(gzipSource);
String s = bufferedSource.readUtf8();
bufferedSource.close();
UTF-8
在上面的代码中,可以看到使用的基本都是带UTF-8的读写方法。Okio推荐优先使用UTF-8的方法,why UTF-8? 这是因为UTF-8在世界各地都已标准化,而在早期的计算机系统中有许多不兼容的字符编码如:ISO-8859-1、ShiftJIS、 ASCII、EBCDIC等,使用UTF-8可以避免这些问题。
如果你需要使用其他编码的字符集,可以使用readString() 和 writeString(),这两个方法可以指定字符编码参数,但在大多数情况下应该只使用带UTF-8的方法。
在编码字符串时,需要特别注意字符串的表达形式和编码方式。当字形有重音或其他装饰时,情况可能会有点复杂。尽管在I/O中读写字符串时使用的都是UTF-8,但是当在内存中,Java字符串使用的是已过时的UTF-16进行编码的。这是一种糟糕的编码格式,因为它对大多数字符使用 16-bit char,但有些字符不适合。特别是大多数的表情符号使用的是两个Java字符, 这时就会出现一个问题: String.length()返回的结果是utf-16字符的数量,而不是字体原本的字符数量。
| Café ? | Café ? | |
|---|---|---|
| Form | NFC | NFD |
| Code Points | c a f é ␣ ? |
c a f e ´ ␣ ? |
| UTF-8 bytes | 43 61 66 c3a9 20 f09f8da9 |
43 61 66 65 cc81 20 f09f8da9 |
| String.codePointCount | 6 | 7 |
| String.length | 7 | 8 |
| Utf8.size | 10 | 11 |
在大多数情况下,Okio无需你关心这些问题,从而可以将关注点放在数据本身的使用上。但是当你确实需要处理这些低级的UTF-8字符串问题时,也有一些方便的API来处理,如使用utf8.size()可以计算字符串按钮UTF-8形式编码的字节数(但是并不会实际编码),使用bufferedsource.readutf8codepoint()读取单个可变长度的Code Point,使用bufferedsink.writeutf8codepoint()写入一个Code Point。
public final class ExploreCharsets {
public void run() throws Exception {
dumpStringData("Café \uD83C\uDF69"); // NFC: é is one code point.
dumpStringData("Café \uD83C\uDF69"); // NFD: e is one code point, its accent is another.
}
public void dumpStringData(String s) throws IOException {
System.out.println(" " + s);
System.out.println(" String.length: " + s.length());
System.out.println("String.codePointCount: " + s.codePointCount(0, s.length()));
System.out.println(" Utf8.size: " + Utf8.size(s));
System.out.println(" UTF-8 bytes: " + ByteString.encodeUtf8(s).hex());
readUtf8CodePoint(s);
System.out.println();
}
private void readUtf8CodePoint(String s) throws IOException {
Buffer buffer = new Buffer();
buffer.writeString(s, Charset.forName("utf-8"));
Source source = Okio.source(buffer.inputStream());
BufferedSource bufferedSource = Okio.buffer(source);
int i = -1;
StringBuilder sb = new StringBuilder();
while (!bufferedSource.exhausted() && (i = bufferedSource.readUtf8CodePoint()) != -1) {
sb.append((char) i).append("---");
}
System.out.println(" readUtf8CodePoint: " + sb.toString());
bufferedSource.close();
}
public static void main(String... args) throws Exception {
new ExploreCharsets().run();
}
}
序列化和反序列化
将一个对象进行序列化并以ByteString的形式返回:
private ByteString serialize(Object o) throws IOException {
Buffer buffer = new Buffer();
try (ObjectOutputStream objectOut = new ObjectOutputStream(buffer.outputStream())) {
objectOut.writeObject(o);
}
return buffer.readByteString();
}
这里使用Buffer对象代替java的ByterrayOutputstream,然后从buffer中获得输出流对象,并通过ObjectOutputStream(来自java的Api)写入对象到buffer缓冲区当中,当你向Buffer中写数据时,总是会写到缓冲区的末尾。
最后,通过buffer对象的readByteString()从缓冲区读取一个ByteString对象,这会从缓冲区的头部开始读取,readByteString()方法可以指定要读取的字节数,如果不指定,则读取全部内容。
我们利用上面的方法将一个对象进行序列化,并得到的ByteString对象按照base64格式进行输出:
Point point = new Point(8.0, 15.0);
ByteString pointBytes = serialize(point);
System.out.println(pointBytes.base64());
这样我们会得到输出的一串字符串:
rO0ABXNyADVjb20uZXhhbXBsZS5hc3VzLm15YXBwbGljYXRpb24ub2tpby5Hb2xkZW5WYWx1ZSRQb2ludIRwF2M5CCK2AgACRAABeEQAAXl4cEAgAAAAAAAAQC4AAAAAAAA=
Okio将这个字符串称之为 Golden Value
接下来,我们尝试将这个字符串(Golden Value)反序列化为一个Point对象
首先转回ByteString对象:
ByteString goldenBytes = ByteString.decodeBase64("rO0ABXNyADVjb20uZXhhbXBsZS5hc3VzLm1"
+"5YXBwbGljYXRpb24ub2tpby5Hb2xkZW5WYWx1ZSRQb2ludIRwF2M5CCK2AgACRAABeEQAAXl4cEAgAAAAAAAAQC4AAAAAAAA=");
然后将ByteString对象反序列化:
private Object deserialize(ByteString byteString) throws IOException, ClassNotFoundException {
Buffer buffer = new Buffer();
buffer.write(byteString);
try (ObjectInputStream objectIn = new ObjectInputStream(buffer.inputStream())) {
Object result = objectIn.readObject();
if (objectIn.read() != -1) throw new IOException("Unconsumed bytes in stream");
return result;
}
}
public void run() throws Exception {
Point point = new Point(8.0, 15.0);
ByteString pointBytes = serialize(point);
System.out.println(pointBytes.base64());
ByteString goldenBytes = ByteString.decodeBase64("rO0ABXNyADVjb20uZXhhbXBsZS5hc3VzLm15YXBwbGljYXRpb24ub2tpby5Hb2xkZW5WYWx1ZSRQb2ludIRwF2M5CCK2AgACRAABeEQAAXl4cEAgAAAAAAAAQC4AAAAAAAA=");
Point decoded = (Point) deserialize(goldenBytes);
if (point.x == decoded.x || point.y == decoded.y) {
System.out.println("Equals");
}
}
输出:

这样我们可以在不破坏兼容性的情况下更改对象的序列化方式。
这个序列化与Java原生的序列化有一个明显的区别就是GodenValue可以在不同客户端之间兼容(只要序列化和反序列化的Class是相同的)。什么意思呢,比如我在PC端使用Okio序列化一个User对象生成的GodenValue字符串,这个字符串你拿到手机端照样可以反序列化出来User对象。
写二进制文件
编码二进制文件与编码文本文件没有什么不同,Okio使用相同的BufferedSink和BufferedSource字节。这对于同时包含字节和字符数据的二进制格式很方便。写二进制数据比写文本更容易出错,需要注意以下几点:
- 字段的宽度 ,即字节的数量。Okio没有释放部分字节的机制。如果你需要的话,需要自己在写操作之前对字节进行shift和mask运算。
- 字段的字节顺序 , 所有多字节的字段都具有结束符:字节的顺序是从最高位到最低位(大字节 big endian),还是从最低位到最高位(小字节 little endian)。Okio中针对小字节排序的方法都带有
Le的后缀;而没有后缀的方法默认是大字节排序的。 - 有符号和无符号,Java没有无符号的基础类型(除了char!)因此,在应用程序层经常会遇到这种情况。为方便使用,Okio的
writeByte()和writeShort()方法可以接受int类型。你可以直接传递一个“无符号”字节像255,Okio会做正确的处理。
| 方法 | 宽度 | 字节排序 | 值 | 编码后的值 |
|---|---|---|---|---|
| writeByte | 1 | 3 | 03 |
|
| writeShort | 2 | big | 3 | 00 03 |
| writeInt | 4 | big | 3 | 00 00 00 03 |
| writeLong | 8 | big | 3 | 00 00 00 00 00 00 00 03 |
| writeShortLe | 2 | little | 3 | 03 00 |
| writeIntLe | 4 | little | 3 | 03 00 00 00 |
| writeLongLe | 8 | little | 3 | 03 00 00 00 00 00 00 00 |
| writeByte | 1 | Byte.MAX_VALUE | 7f |
|
| writeShort | 2 | big | Short.MAX_VALUE | 7f ff |
| writeInt | 4 | big | Int.MAX_VALUE | 7f ff ff ff |
| writeLong | 8 | big | Long.MAX_VALUE | 7f ff ff ff ff ff ff ff |
| writeShortLe | 2 | little | Short.MAX_VALUE | ff 7f |
| writeIntLe | 4 | little | Int.MAX_VALUE | ff ff ff 7f |
| writeLongLe | 8 | little | Long.MAX_VALUE | ff ff ff ff ff ff ff 7f |
下面的示例代码是按照 BMP文件格式 对文件进行编码:
public final class BitmapEncoder {
static final class Bitmap {
private final int[][] pixels;
Bitmap(int[][] pixels) {
this.pixels = pixels;
}
int width() {
return pixels[0].length;
}
int height() {
return pixels.length;
}
int red(int x, int y) {
return (pixels[y][x] & 0xff0000) >> 16;
}
int green(int x, int y) {
return (pixels[y][x] & 0xff00) >> 8;
}
int blue(int x, int y) {
return (pixels[y][x] & 0xff);
}
}
/** * Returns a bitmap that lights up red subpixels at the bottom, green subpixels on the right, and * blue subpixels in bottom-right. */
Bitmap generateGradient() {
int[][] pixels = new int[1080][1920];
for (int y = 0; y < 1080; y++) {
for (int x = 0; x < 1920; x++) {
int r = (int) (y / 1080f * 255);
int g = (int) (x / 1920f * 255);
int b = (int) ((Math.hypot(x, y) / Math.hypot(1080, 1920)) * 255);
pixels[y][x] = r << 16 | g << 8 | b;
}
}
return new Bitmap(pixels);
}
void encode(Bitmap bitmap, File file) throws IOException {
try (BufferedSink sink = Okio.buffer(Okio.sink(file))) {
encode(bitmap, sink);
}
}
/** * https://en.wikipedia.org/wiki/BMP_file_format */
void encode(Bitmap bitmap, BufferedSink sink) throws IOException {
int height = bitmap.height();
int width = bitmap.width();
int bytesPerPixel = 3;
int rowByteCountWithoutPadding = (bytesPerPixel * width);
int rowByteCount = ((rowByteCountWithoutPadding + 3) / 4) * 4;
int pixelDataSize = rowByteCount * height;
int bmpHeaderSize = 14;
int dibHeaderSize = 40;
// BMP Header
sink.writeUtf8("BM"); // ID.
sink.writeIntLe(bmpHeaderSize + dibHeaderSize + pixelDataSize); // File size.
sink.writeShortLe(0); // Unused.
sink.writeShortLe(0); // Unused.
sink.writeIntLe(bmpHeaderSize + dibHeaderSize); // Offset of pixel data.
// DIB Header
sink.writeIntLe(dibHeaderSize);
sink.writeIntLe(width);
sink.writeIntLe(height);
sink.writeShortLe(1); // Color plane count.
sink.writeShortLe(bytesPerPixel * Byte.SIZE);
sink.writeIntLe(0); // No compression.
sink.writeIntLe(16); // Size of bitmap data including padding.
sink.writeIntLe(2835); // Horizontal print resolution in pixels/meter. (72 dpi).
sink.writeIntLe(2835); // Vertical print resolution in pixels/meter. (72 dpi).
sink.writeIntLe(0); // Palette color count.
sink.writeIntLe(0); // 0 important colors.
// Pixel data.
for (int y = height - 1; y >= 0; y--) {
for (int x = 0; x < width; x++) {
sink.writeByte(bitmap.blue(x, y));
sink.writeByte(bitmap.green(x, y));
sink.writeByte(bitmap.red(x, y));
}
// Padding for 4-byte alignment.
for (int p = rowByteCountWithoutPadding; p < rowByteCount; p++) {
sink.writeByte(0);
}
}
}
public static void main(String[] args) throws Exception {
BitmapEncoder encoder = new BitmapEncoder();
Bitmap bitmap = encoder.generateGradient();
encoder.encode(bitmap, new File("gradient.bmp"));
}
}
代码中对文件按照BMP的格式写入二进制数据,这会生成一个bmp格式的图片文件,BMP格式要求每行以4字节开始,所以代码中加了很多0来做字节对齐。
编码其他二进制的格式非常相似。一些值得注意的点:
- 使用Golden values编写测试,对于确认程序的预期结果可以使调试更容易。
- 使用
Utf8.size()方法计算编码字符串的字节长度。这对于length-prefixed格式必不可少。 - 使用
Float.floatToIntBits()和Double.doubleToLongBits()来编码浮点型的数值。
使用Socket进行通信
通过网络发送和接收数据有点像文件的读写。Okio使用BufferedSink对输出进行编码,使用BufferedSource对输入进行解码。与文件一样,网络协议可以是文本、二进制或两者的混合。但是网络和文件系统之间也有一些实质性的区别。
当你有一个文件对象,你只可以选择读或者写,但是网络与之不同的是可以同时进行读和写!在有一些协议中,处理这个问题的方式是轮流的进行:写入请求、读取响应、重复以上操作。你可以用一个单线程来实现这种协议。而在其他协议中,你可以同时进行读写。通常你需要一个专门的线程来读取数据。对于写入数据,你可以使用专门线程或者使用synchronized,以便多个线程可以共享一个Sink。Okio的流在并发情况下使用是不安全的。
对于Okio的Sinks缓冲区,必须手动调用flush()来传输数据,以最小化I/O操作。通常,面向消息的协议会在每条消息之后刷新。注意,当缓冲数据超过某个阈值时,Okio将自动刷新。但这只是为了节省内存,不能依赖它进行协议交互。
Okio是基于java.io.socket建立连接的,当你通过socket创建服务器或客户端后,可以使用Okio.source(Socket)进行读取,使用Okio.sink(Socket)进行写入。这些API也同样适用于SSLSocket。
在任意线程中想要取消socket连接可以调用Socket.close()方法,这将导致 sources 和 sinks 对象立即抛出IOException而失败。Okio中可以为所有的socket操作配置超时限制,但并不需要你去调用Socket的方法来设置超时:Source 和 Sink会提供超时的接口。即使流对象被装饰,这个API也能工作。
Okio官方Demo中编写了一个 简单的Socket代理服务 来示例完整的网络交互操作,下面是其中的部分代码截取:
private void handleSocket(final Socket fromSocket) {
try {
final BufferedSource fromSource = Okio.buffer(Okio.source(fromSocket));
final BufferedSink fromSink = Okio.buffer(Okio.sink(fromSocket));
//..............
//..................
} catch (IOException e) {
.....
}
}
可以看到通过Socket创建sources 和 sinks的方式与通过文件创建的方式一样,都是先通过Okio.source()拿到Socket对应的Source或Sink对象,然后通过Okio.buffer()获取对应的装饰者缓冲对象。在Okio中,一旦你为Socket对象创建了Source 或者 Sink,那么你就不能再使用InputStream 或 OutputStream 了。
Buffer buffer = new Buffer();
for (long byteCount; (byteCount = source.read(buffer, 8192L)) != -1; ) {
sink.write(buffer, byteCount);
sink.flush();
}
以上代码中,循环从source中读取数据写入到sink当中,并调用flush()进行刷新,如果你不需要每次写数据都进行flush(),那么for循环里的两句可以使用BufferedSink.writeAll(Source)一行代码来代替。
你会发现,在read()方法中传递了一个8192作为读取的字节数,其实这里可以传任何数字,但是Okio更喜欢用8 kib,因为这是Okio在单个系统调用中所能处理的最大值。大多数时候应用程序代码不需要处理这样的限制!
int addressType = fromSource.readByte() & 0xff;
int port = fromSource.readShort() & 0xffff;
Okio使用的是有符号类型,如byte和short,但通常协议需要的是无符号的值,而在Java中将有符号的值转换为无符号值的首选方式,就是通过是按位与&运算符。以下是字节、短整型和整型的转换清单:
| Type | Signed Range | Unsigned Range | Signed to Unsigned |
|---|---|---|---|
| byte | -128…127 | 0…255 | int u = s & 0xff; |
| short | -32,768…32,767 | 0…65,535 | int u = s & 0xffff; |
| int | -2,147,483,648…2,147,483,647 | 0…4,294,967,295 | long u = s & 0xffffffffL; |
Java中没有能够表示无符号的long型的基本类型。
Hashing
哈希散列函数应用广泛,如HTTPS证书、Git提交、BitTorrent完整性检查和区块链块等都使用到加密散列, 良好地使用哈希可以提高应用程序的性能、隐私性、安全性和简单性。每个加密哈希函数接受一个可变长度的字节输入流,并生成一个长度固定的字符串值,称之为“hash”值。哈希函数具有以下重要特性:
- 确定性:每个输入总是产生相同的输出。
- 统一:每个输出的字节字符串的可能性相同。很难找到或创建产生相同输出的不同输入对。即“碰撞”。
- 不可逆:知道输出并不能帮助你找到输入。
- 易于理解:哈希在很多环境中都已被实现并且被严格理解。
Okio支持一些常见的加密哈希函数:
- MD5:128位(16字节)加密哈希。它既不安全又是过时的,因为它的逆向成本很低!之所以提供此哈希,是因为它在安全性较低的系统中使用比较非常流行并且方便。
- SHA-1:160位(20字节)加密散列。最近的研究表明,创建SHA-1碰撞是可行的。考虑从sha-1升级到sha-256。
- SHA-256:256位(32字节)加密哈希。SHA-256被广泛理解,逆向操作成本较高。这是大多数系统应该使用的哈希。
- SHA-512:512位(64字节)加密哈希。逆向操作成本很高。
Okio可以从字节字符串生成加密哈希:
ByteString byteString = readByteString(new File("README.md"));
System.out.println(" md5: " + byteString.md5().hex());
System.out.println(" sha1: " + byteString.sha1().hex());
System.out.println("sha256: " + byteString.sha256().hex());
System.out.println("sha512: " + byteString.sha512().hex());
public ByteString readByteString(File file) throws IOException {
try (BufferedSource source = Okio.buffer(Okio.source(file))) {
return source.readByteString();
}
}
从Buffer中生成:
Buffer buffer = readBuffer(new File("README.md"));
System.out.println(" md5: " + buffer.md5().hex());
System.out.println(" sha1: " + buffer.sha1().hex());
System.out.println("sha256: " + buffer.sha256().hex());
System.out.println("sha512: " + buffer.sha512().hex());
public Buffer readBuffer(File file) throws IOException {
try (Source source = Okio.source(file)) {
Buffer buffer = new Buffer();
buffer.writeAll(source);
return buffer;
}
}
从source输入流中获取hash值:
try (HashingSource hashingSource = HashingSource.sha256(Okio.source(file));
BufferedSource source = Okio.buffer(hashingSource)) {
source.readAll(Okio.blackhole());
System.out.println(" sha256: " + hashingSource.hash().hex());
}
从sink输出流中获取hash值:
try (HashingSink hashingSink = HashingSink.sha256(Okio.blackhole());
BufferedSink sink = Okio.buffer(hashingSink);
Source source = Okio.source(file)) {
sink.writeAll(source);
sink.close(); // Emit anything buffered.
System.out.println(" sha256: " + hashingSink.hash().hex());
}
Okio还支持HMAC(哈希消息认证代码),它结合了一个秘钥值和一个hash值。应用程序可以使用HMAC进行数据完整性和身份验证。
ByteString secret = ByteString.decodeHex("7065616e7574627574746572");
System.out.println("hmacSha256: " + byteString.hmacSha256(secret).hex());
同样样,你可以从ByteString, Buffer, HashingSource, 和HashingSink生成HMAC。注意,Okio没有为MD5实现HMAC。Okio使用Java的java.security.MessageDigest用于加密散列和javax.crypto.Mac 生成HMAC。
以上,主要介绍了Okio的简单使用的一些API,其中的代码和说明主要是从Okio的GitHub的文档翻译过来的。总的来说,Okio这个库已经算是很强大很方便的了,几乎涵盖了所有你需要的东西。官方demo中还有一些代码,没有文档说明用途,暂时没有介绍。后面再单独来一篇简要分析学习一下OKio的源码组成结构和功能实现。目前的Okio版本源码已经是用Kotlin写的了。
参考:https://github.com/square/okio
Okio源码分析请参考下一篇博文:Okio源码学习分析
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/131629.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...