大家好,又见面了,我是你们的朋友全栈君。
多重比较LSD-t值的计算
问题的提出:
向学术期刊投稿时,“变态”的审稿人向你“索要”LSD-t值,可是SPSS的输出结果中没有这个值——是不是有点悲催?!另外,大家还会有一个常见的疑问:采用LSD-t法进行两两比较之后得出来的p值,需不需要调整显著性水平?
我们先把原始数据和答案给出来,然后再讲一讲其中的数理逻辑。
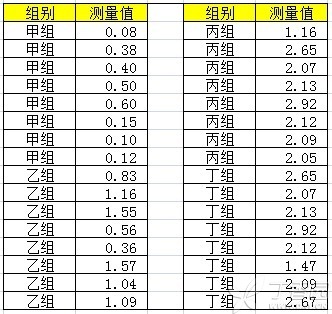
本例使用的原始数据如下图所示,有兴趣的读者可以用本数据进行对照学习(本例采用单因素方差分析,具体的步骤就不再列出了):

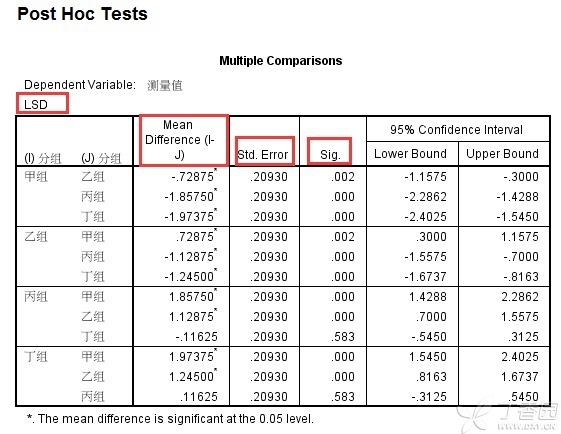
通过单因素方差分析并采用LSD-t法进行多重比较(即在“事后比较(Post Hoc)”次对话框中勾选“LSD”),在SPSS中得到的多重比较结果如下图:
现在,我们来回答前述两个问题的答案:
1、关于LSD-t值的计算:LSD-t=Mean Difference(I-J)/Std. Error(即LSD-t=均值差/标准误差)
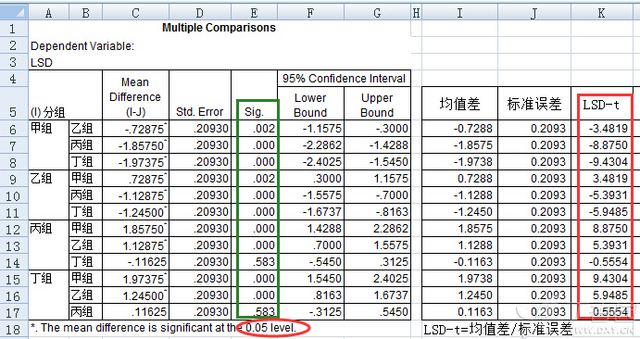
在实际操作中,为了求得具体的LSD-t值,我们可以将上表复制到EXCEL中,并且对均值差这一列进行数据整理(因为其中有些数据后面标着星号,其此时已经不是数值格式),然后再将均值差除以标准误差,即可得到各对两两比较之间的Lsd-t值,如下图最右侧红色框中所示:
2、关于显著性水平的问题:由LSD-t多重比较法得到的p值就是上表中绿框内Sig.值,此时,不需要再进行显著性水平的调整,以0.05作为显著性水平即可。
==============我是分割线,下面进入数理逻辑的讲解=====================
LSD-t法的基本思想:
我们知道,当只有两个独立样本时,可以采用独立样本t检验来进行两组的比较。当组别大于等于三时,应进行方差分析。如果方差分析的p值小于0.05,则说明组间存在显著性的差异,这时我们就需要通过多重比较(又称“两两比较”)来找出到底是哪两组或者哪几组之间存在显著性差异。如果再通过各组别间的独立样本t检验来做多重比较的话,首先是麻烦,它需要进行N多次的两两比较(显得有点“傻大笨”),更重要的是它会增大犯Ⅰ类错误的概率。
综上,统计学家们为了解决三组或三组以上数据之间两两比较的问题,发挥个人主观能动性,研究出了各种算法(SPSS中就集成了十几种算法),LSD就是其中之一。
LSD-t法是采用的是t检验的基本逻辑,其核心思想是在保持显著性水平不变的情况下,寻找新的统计量(即LSD-t值)代替t统计量(即t值)来进行t检验,所以其本质上依然是t检验,故而我们经常把它写成”LSD-t检验”。但是,与独立样本t检验相比,LSD-t法在统计量(LSD-t)、自由度(v)等方面做了调整,它充分利用了样本信息,故而相比之下更为精确和可靠。
下图是LSD-t值的公式:
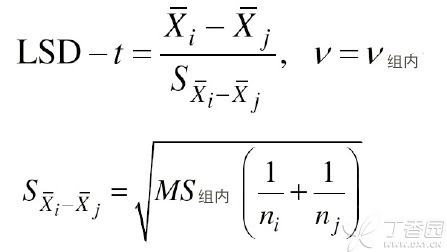


好了,原理大致说完了,下面我们根据上述数学原理来手动计算LSD-t值。
================我是分割线,下面进入LSD-t值的计算===================
首先,我们到SPSS输出的方差分析表中去寻找后续计算中会用到的数据,方差分析表如下:
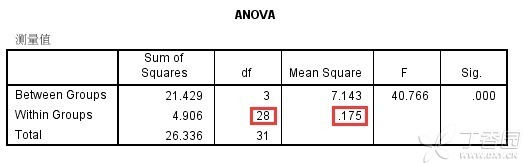
由上表可知:

此时,我们再来看一下SPSS输出的LSD-t多重比较表中的标准误差值:
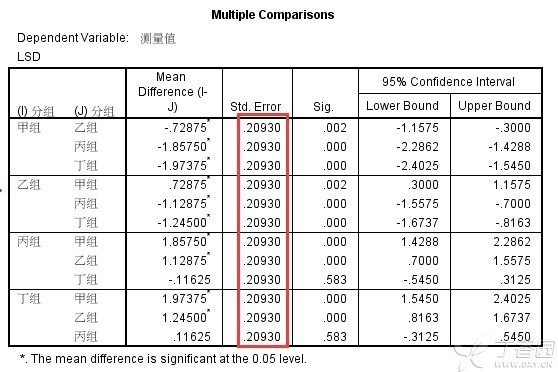
SPSS计算出来的标准误差是0.20930,而我们手工计算的是0.209165,略有差异。那么,问题出在哪儿呢?
在上面的方差分析表中(ANOVA表),组内均方值0.175是机显值,而并非真实值,如下图所示:
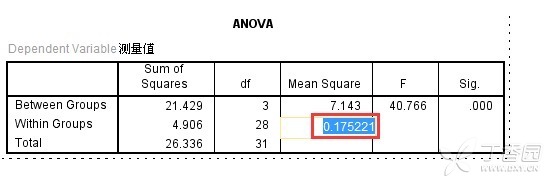
此时我们发现,组内均方值应为0.175221,我们以该值代入标准误差的公式再计算一遍:
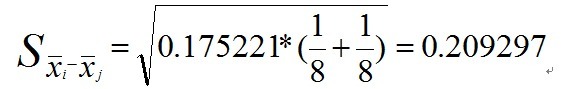
为了满足好奇心,我们以0.175220代入标准误差的公式再计算一遍:
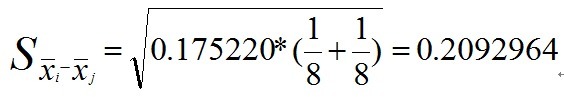
综合上述三次计算,整理后可得下表:
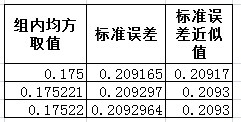
由上表可见,我们手动计算出来的p值与SPSS为我们计算的p值是一致的,我们看上去的不一致只是机显值和四舍五入等原因带来的,并不是我们计算有误。
由此,我们就可以确定一点:SPSS输出的LSD-t多重比较表(Multiple Comparisons)中的标准误差(Std. Error)就是根据LSD-t法的数学公式计算出来标准误差,我们可以直接把它拿过来用于参与LSD-t值的计算,而不需要手动计算标准误差了。
书接上文,咱们继续手动计算LSD-t值,这就很简单了:将数据复制到EXCEL中,根据LSD-t的计算公式,我们只需要将均值差除以标准误差(标准误差采用SPSS输出的值)就可以得到 LSD-t值了。
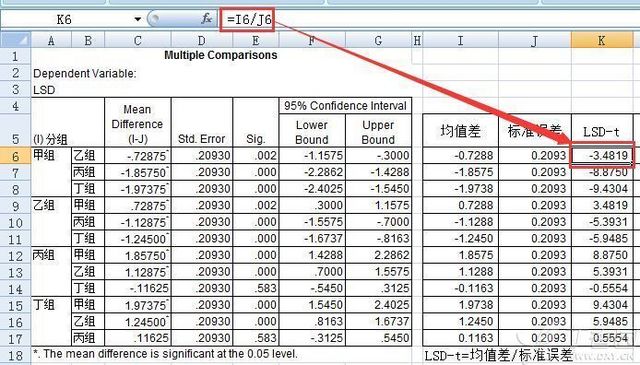
至此,我们就可以得出第一个重要的结论:LSD-t值等于LSD多重比较表格中的均值差除以该表中的标准误差。
================我是分割线,下面进入LSD-t检验p值的计算=================
我们再来温习一下关于是否需要调整显著性水平的问题,这就又一次回到LSD-t检验的数学思想——在保持显著性水平不变的前提下,弃用独立样本t检验,转而寻找新的统计量(即LSD-t)代替独立样本t检验的t统计量来进行组间的比较(依然使用t检验)。关于LSD-t检验与t检验的区别,前面已经讲了,LSD-t检验充分利用了样本信息来进行两两比较,如组内均方、组内自由度、组内观测值数量等等,不再过多叙述。
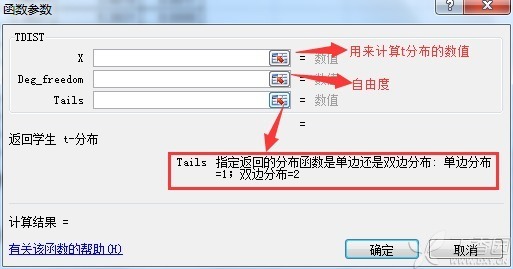
我们下面再进一步利用EXCEL来计算LSD-t检验的p值。具体方法是利用TDIST函数,其函数表达式如下:
f(x)=TDIST(X,Deg_freedom,Tails)
TDIST函数的对话框如下所示:
对于本案例中TDIST函数参数的说明:
1.使用LSD-t值来计算t分布的数值(即p值);同时,由于该函数要求X值必须是正值,所以需要先对LSD-t求绝对值,然后再用其绝对值参与计算。
2.本例中,自由度为32-4 =28。
3.使用双尾检验,故TDIST函数第三个参数值为2。
运算过程和运算结果如下图所示:
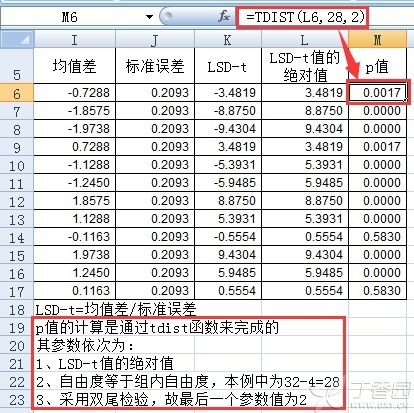
为了验证计算的正确性,我们将手动计算的p值与SPSS为我们算出来的p值进行对照,如下图所示:
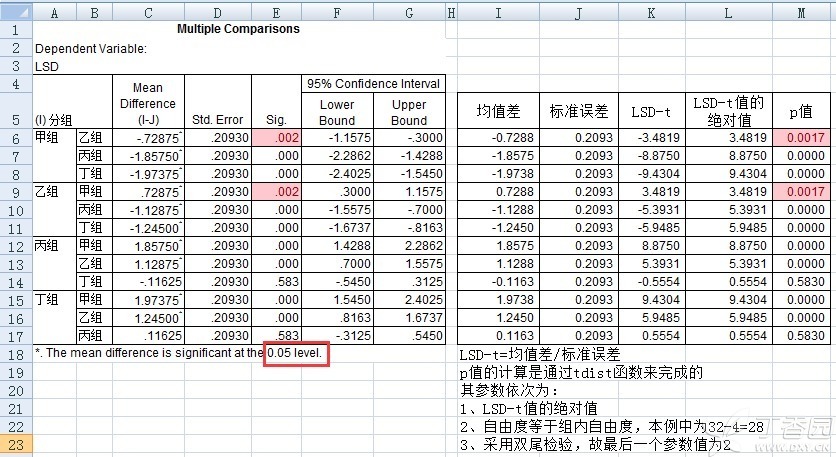
可以看到,甲组和乙组两两比较时手工计算出来的p值(0.0017)和SPSS计算出来的p值(0.002)不一致,其他的组别在两两比较时的p值都是一致的。关于这个问题的原因,也是机显值和四舍五入等原因造成的。我们可以再进行进一步的验证——如下图所示,p=0.002对应的实际p值为0.001652,其也可近似认为是0.017。
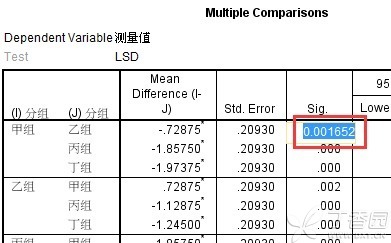
至此,我们可以得出第二个重要结论:LSD-t多重比较表中的p值,就是对于LSD-t统计量(即LSD-t值)进行双尾t检验的p值(只不过SPSS没有为我们输入LSD-t值),我们可以放心使用,并且无需调整显著性水平。
====================我是分割线,下面进入时间====================
最后,我们再总结一下:采用LSD-t法进行多重比较时,LSD-t值就是用多重比较表(Multiple Comparisons)中的均值差/标准误差;同时,不必调整显著性水平,因为LSD-t法的数学思想就是在不改变显著性水平的前提下,寻找新的t值(即LSD-t值)来进行t检验。
以上公式和计算过程只是为了向大家确认LSD-t值的计算和是否需要调整显著性水平而写的,只是为了让大家不再纠结,大家也不必记住公式和计算过程,只要记住最终的结论就好了。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/131565.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
