大家好,又见面了,我是你们的朋友全栈君。
Java二维数组排序
Java二维数组排序
关于Java二维数组的排序方法之一是把二维数组放进一维数组然后试用版Arrays.sort();进行排序,排序结束后再把一维数组内容重新写入二维数组内,代码实现如下:
为了方便,我在这里使用了随机数生成方法Math.random()进行随机数生成,依次写入二维数组内:
import java.util.*;
public class P11{
public static void main(String[] args){
int[][] arr=new int[5][5];
for(int i=0;i<arr.length;i++){
for (int j=0;j<arr[i].length;j++){
//生成随机数【100-1000】
arr[i][j]=(int)(Math.random()*(1000-100+1)+100);
}
}
for(int i=0;i<arr.length;i++){
System.out.println(Arrays.toString(arr[i]));
}
System.out.println();
for(int i=0;i<arr.length;i++){
Arrays.sort(arr[i]);
}
for(int i=0;i<arr.length;i++){
System.out.println(Arrays.toString(arr[i]));
}
int[] temp=new int[25];
int k=0;
for(int i=0;i<arr.length;i++){
for(int j=0;j<arr[i].length;j++){
temp[k]=arr[i][j];
k++;
}
}
System.out.println();
for(int x:temp){
System.out.print(x+" ");
}
Arrays.sort(temp);
System.out.println();
for(int x:temp){
System.out.print(x+" ");
}
k=-1;
for(int i=0;i<arr.length;i++){
for(int j=0;j<arr[i].length;j++){
k++;
arr[i][j]=temp[k];
}
}
System.out.println();
System.out.println();
for(int i=0;i<arr.length;i++){
System.out.println(Arrays.toString(arr[i]));
}
}
}
因为使用了随机数生成的数组内容,所以每次运行数组内容都不尽相同,本次运行结果如下:
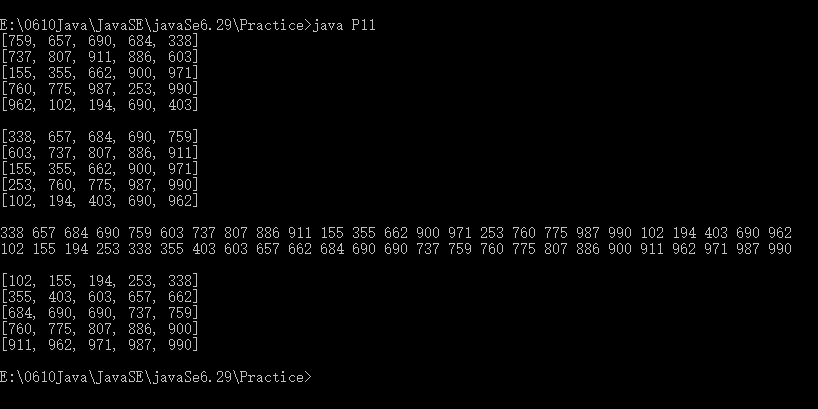

版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/131551.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
