大家好,又见面了,我是你们的朋友全栈君。
转载请注明作者和出处: http://blog.csdn.net/c406495762
Github代码获取:https://github.com/Jack-Cherish/python-spider
Python版本: Python3.x
运行平台: Windows
IDE: Sublime text3
更多教程,请查看:https://cuijiahua.com/blog/spider/
一 前言
**强烈建议:**请在电脑的陪同下,阅读本文。本文以实战为主,阅读过程如稍有不适,还望多加练习。
本文的实战内容有:
- 网络小说下载(静态网站)
- 优美壁纸下载(动态网站)
- 视频下载
2020年,更多精彩内容,尽在微信公众号,欢迎您的关注:


二 网络爬虫简介
网络爬虫,也叫网络蜘蛛(Web Spider)。它根据网页地址(URL)爬取网页内容,而网页地址(URL)就是我们在浏览器中输入的网站链接。比如:https://www.baidu.com/,它就是一个URL。
在讲解爬虫内容之前,我们需要先学习一项写爬虫的必备技能:审查元素(如果已掌握,可跳过此部分内容)。
1 审查元素
在浏览器的地址栏输入URL地址,在网页处右键单击,找到检查。(不同浏览器的叫法不同,Chrome浏览器叫做检查,Firefox浏览器叫做查看元素,但是功能都是相同的)
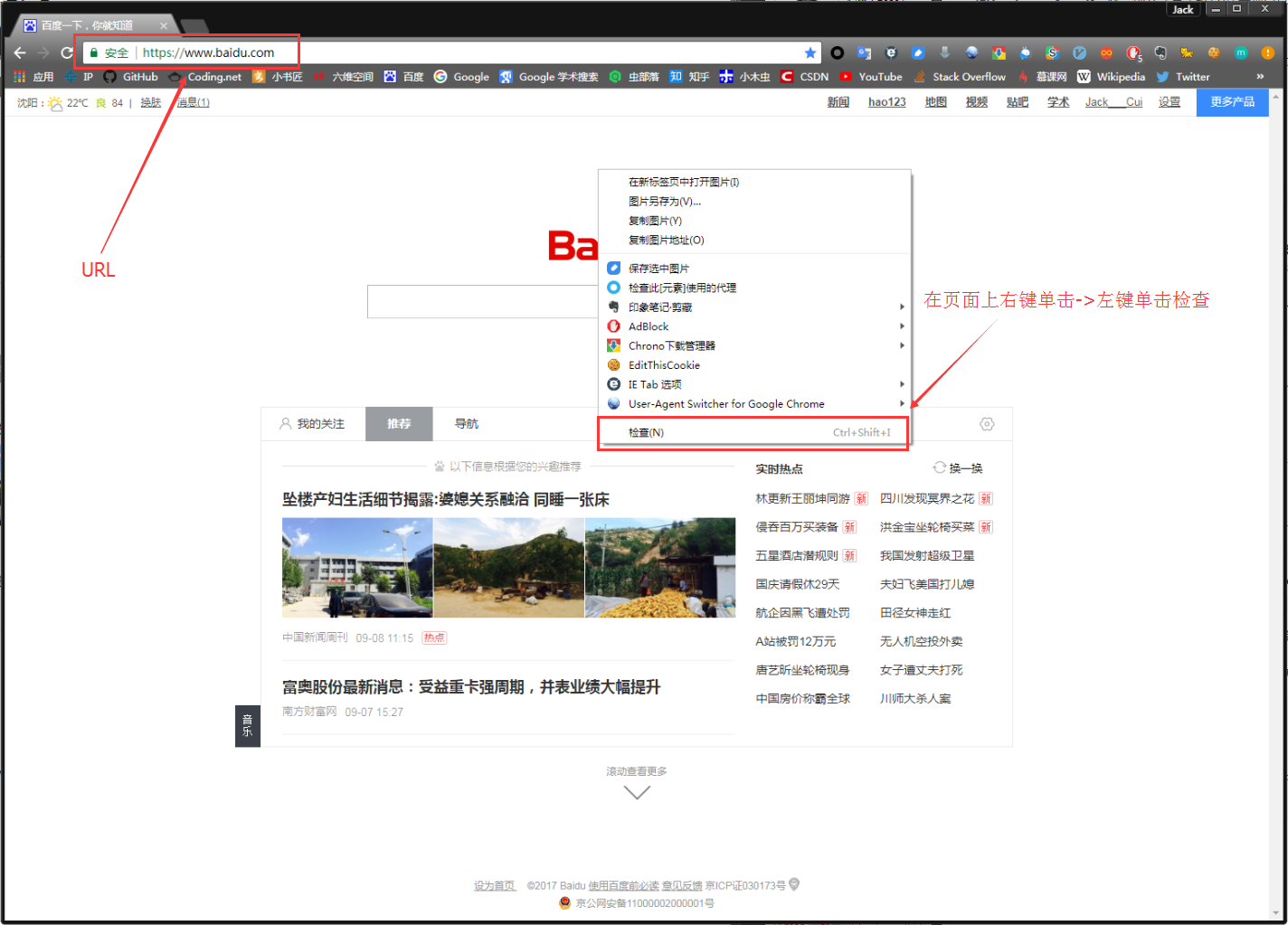
我们可以看到,右侧出现了一大推代码,这些代码就叫做HTML。什么是HTML?举个容易理解的例子:我们的基因决定了我们的原始容貌,服务器返回的HTML决定了网站的原始容貌。
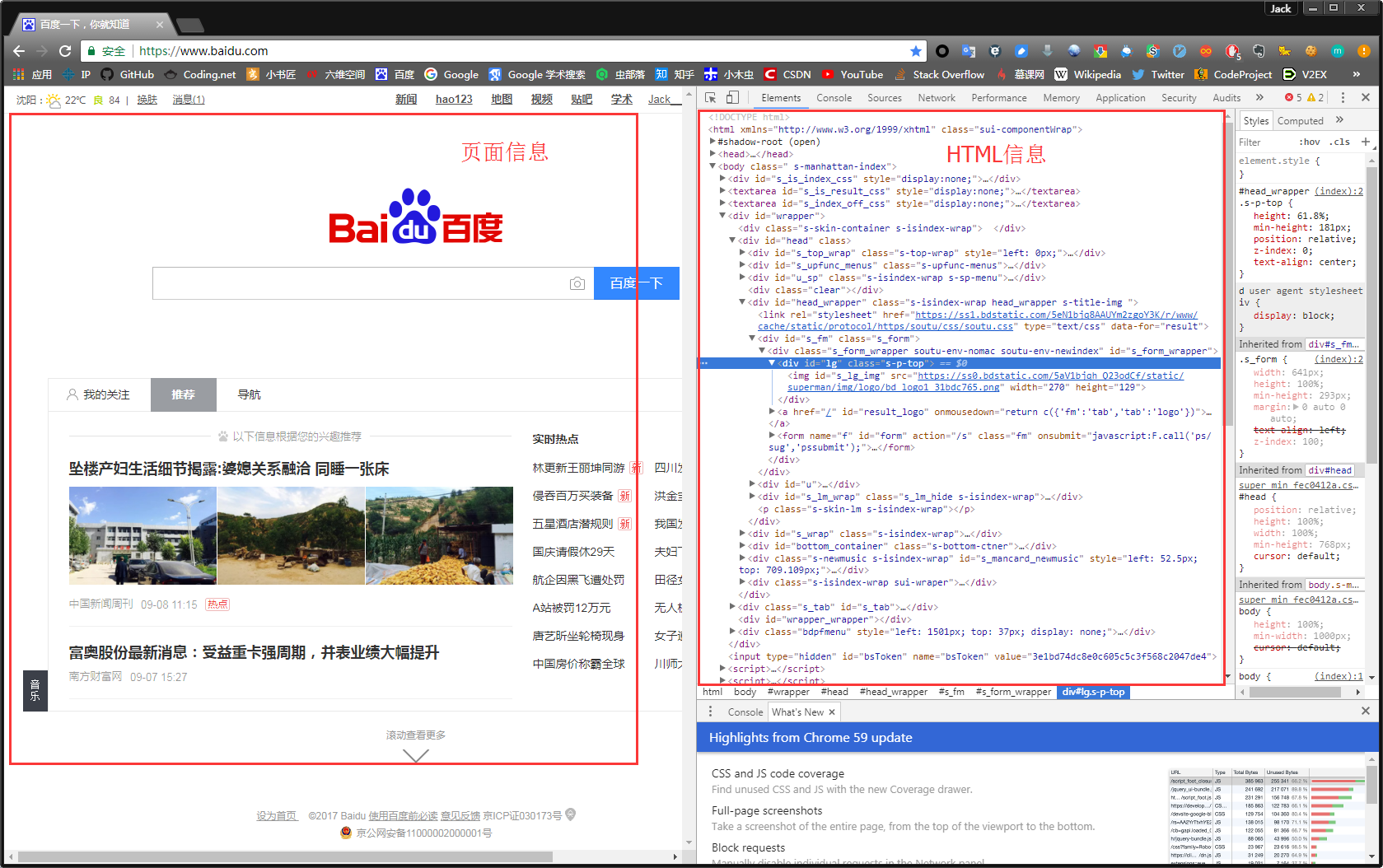
为啥说是原始容貌呢?因为人可以整容啊!扎心了,有木有?那网站也可以”整容”吗?可以!请看下图:
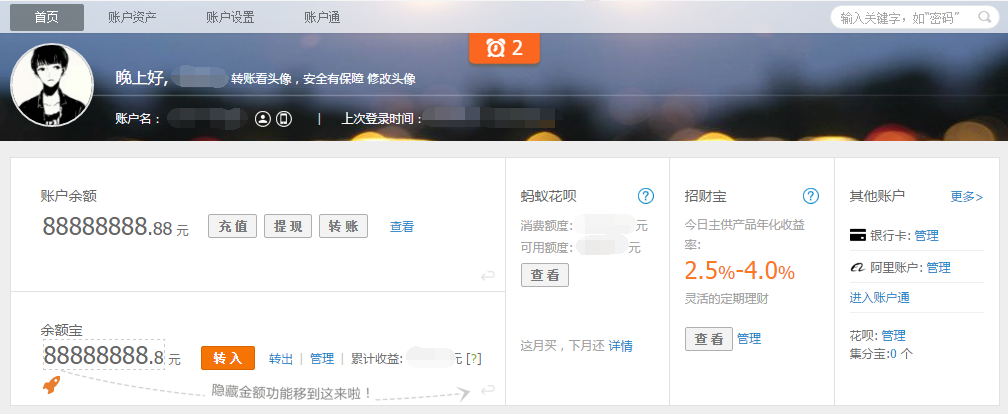
我能有这么多钱吗?显然不可能。我是怎么给网站”整容”的呢?就是通过修改服务器返回的HTML信息。我们每个人都是”整容大师”,可以修改页面信息。我们在页面的哪个位置点击审查元素,浏览器就会为我们定位到相应的HTML位置,进而就可以在本地更改HTML信息。
**再举个小例子:**我们都知道,使用浏览器”记住密码”的功能,密码会变成一堆小黑点,是不可见的。可以让密码显示出来吗?可以,只需给页面”动个小手术”!以淘宝为例,在输入密码框处右键,点击检查。
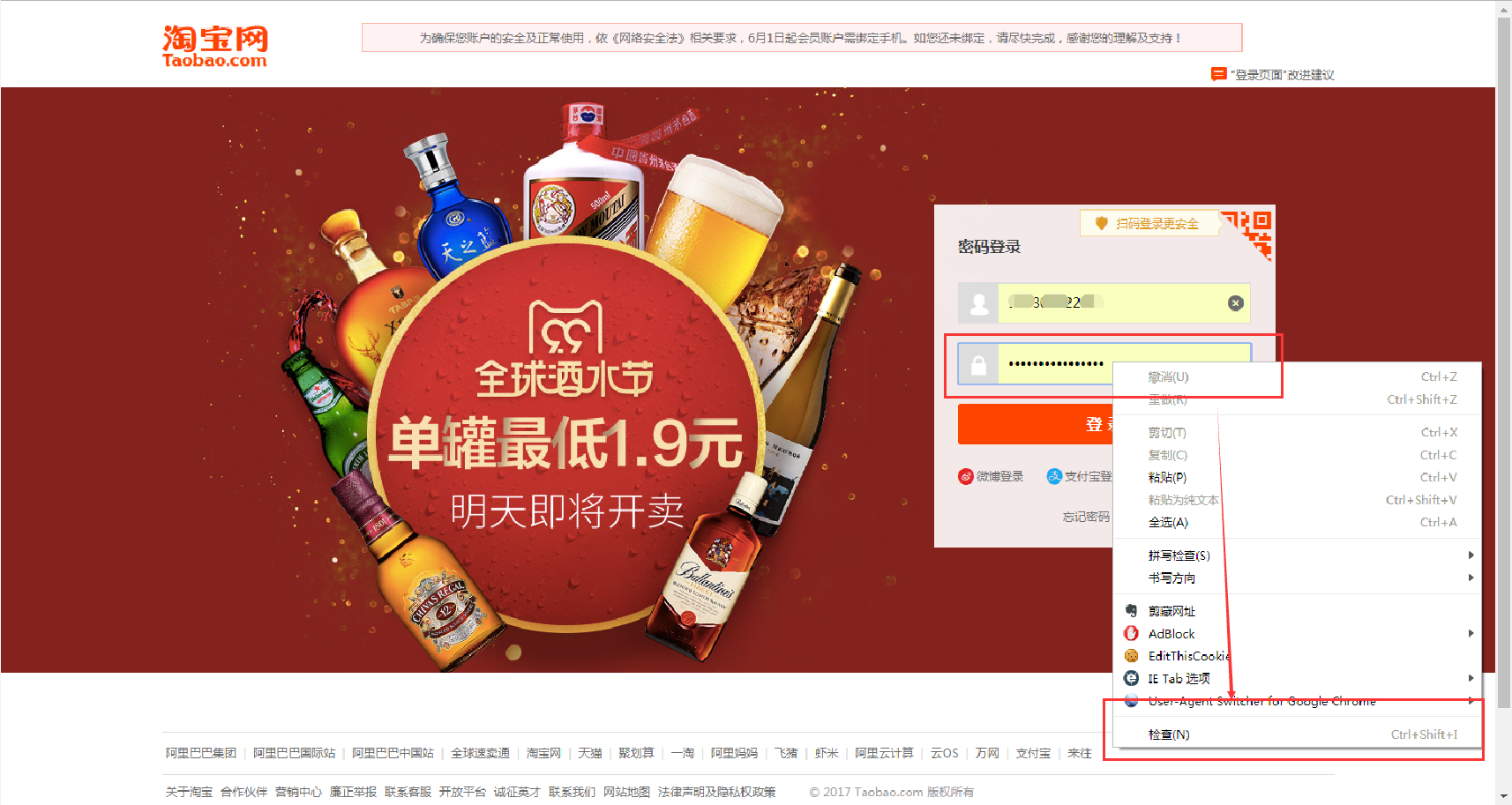
可以看到,浏览器为我们自动定位到了相应的HTML位置。将下图中的password属性值改为text属性值(直接在右侧代码处修改):
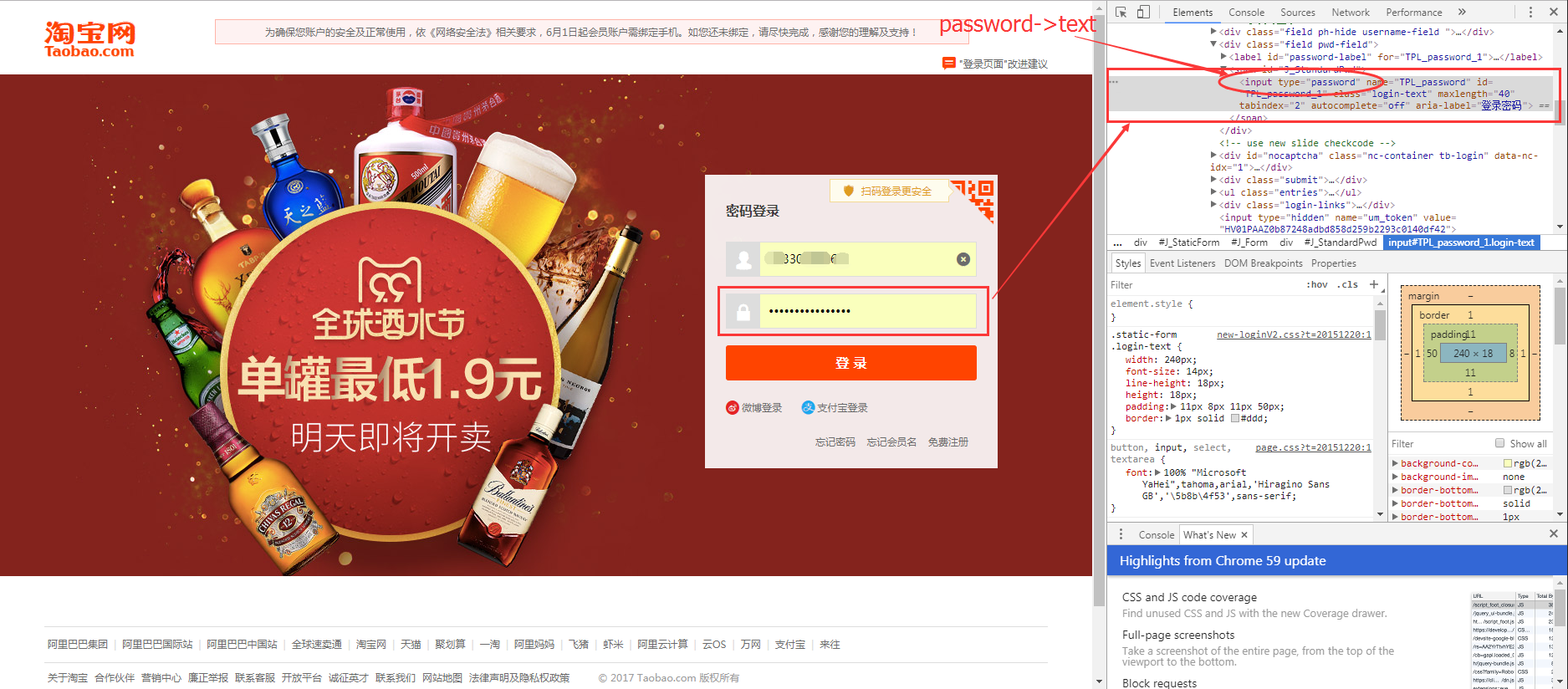
我们让浏览器记住的密码就这样显现出来了:
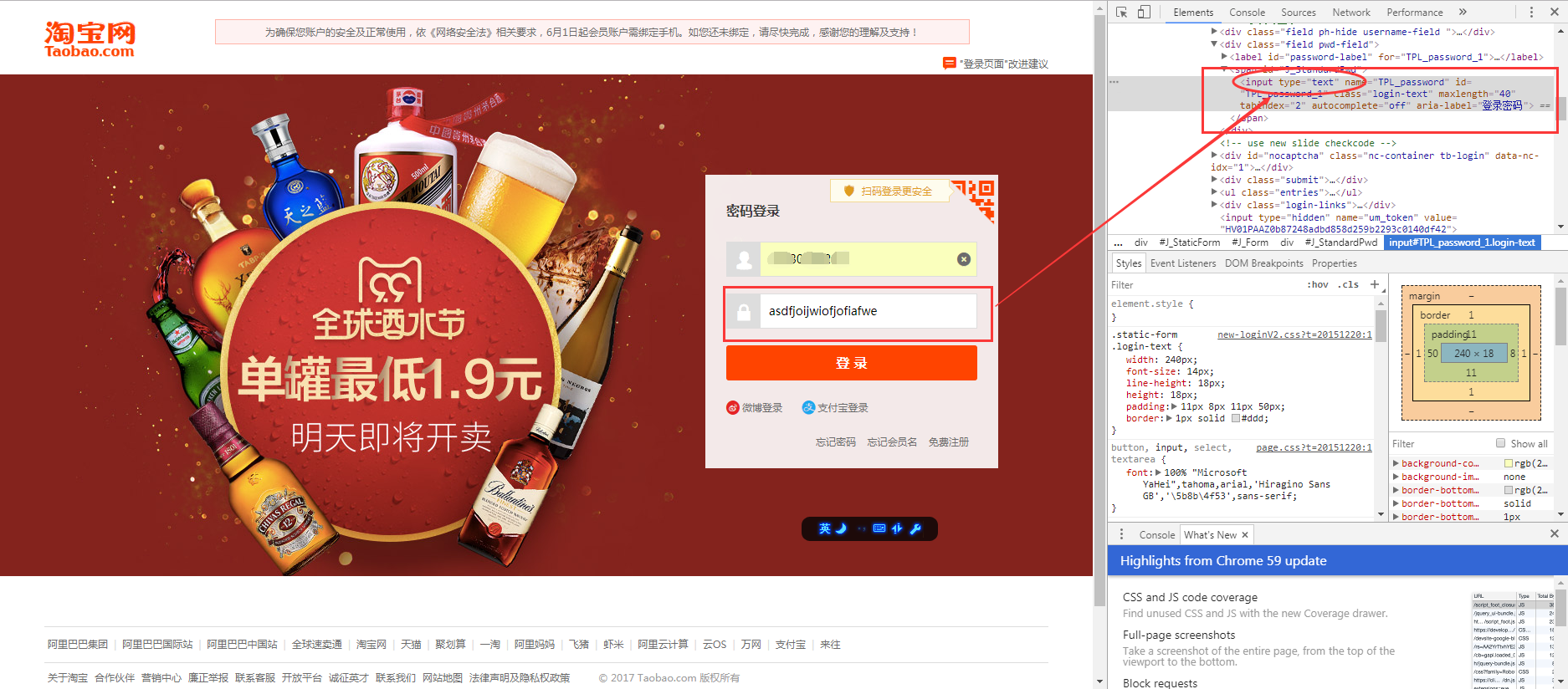
说这么多,什么意思呢?**浏览器就是作为客户端从服务器端获取信息,然后将信息解析,并展示给我们的。**我们可以在本地修改HTML信息,为网页”整容”,但是我们修改的信息不会回传到服务器,服务器存储的HTML信息不会改变。刷新一下界面,页面还会回到原本的样子。这就跟人整容一样,我们能改变一些表面的东西,但是不能改变我们的基因。
2 简单实例
网络爬虫的第一步就是根据URL,获取网页的HTML信息。在Python3中,可以使用urllib.request和requests进行网页爬取。
- urllib库是python内置的,无需我们额外安装,只要安装了Python就可以使用这个库。
- requests库是第三方库,需要我们自己安装。
requests库强大好用,所以本文使用requests库获取网页的HTML信息。requests库的github地址:https://github.com/requests/requests
(1) requests安装
在cmd中,使用如下指令安装requests:
pip install requests
或者:
easy_install requests
(2) 简单实例
requests库的基础方法如下:
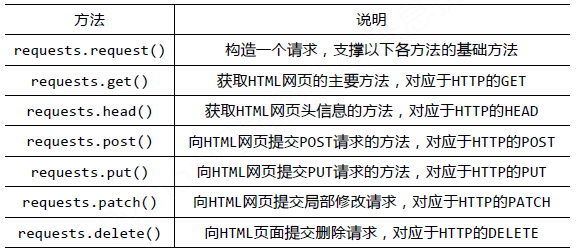
官方中文教程地址:http://docs.python-requests.org/zh_CN/latest/user/quickstart.html
requests库的开发者为我们提供了详细的中文教程,查询起来很方便。本文不会对其所有内容进行讲解,摘取其部分使用到的内容,进行实战说明。
首先,让我们看下requests.get()方法,它用于向服务器发起GET请求,不了解GET请求没有关系。我们可以这样理解:get的中文意思是得到、抓住,那这个requests.get()方法就是从服务器得到、抓住数据,也就是获取数据。让我们看一个例子(以 www.gitbook.cn为例)来加深理解:
# -*- coding:UTF-8 -*-
import requests
if __name__ == '__main__':
target = 'http://gitbook.cn/'
req = requests.get(url=target)
print(req.text)
requests.get()方法必须设置的一个参数就是url,因为我们得告诉GET请求,我们的目标是谁,我们要获取谁的信息。运行程序看下结果:
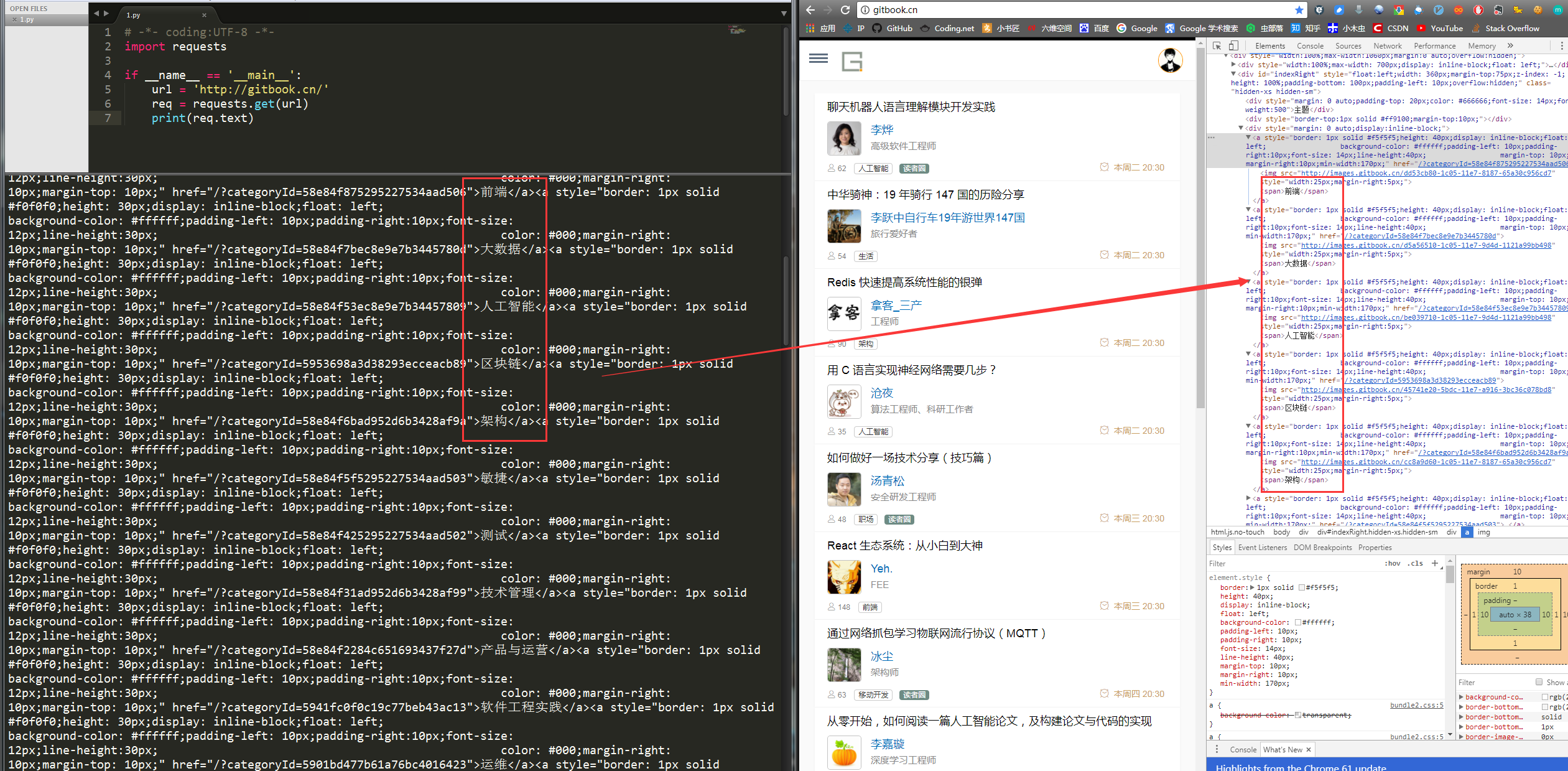
左侧是我们程序获得的结果,右侧是我们在www.gitbook.cn网站审查元素获得的信息。我们可以看到,我们已经顺利获得了该网页的HTML信息。这就是一个最简单的爬虫实例,可能你会问,我只是爬取了这个网页的HTML信息,有什么用呢?客官稍安勿躁,接下来进入我们的实战正文。
三 爬虫实战
1 小说下载
(1) 实战背景
小说网站-笔趣看:URL:http://www.biqukan.com/
本次实战就是从该网站爬取并保存一本名为《一念永恒》的小说。
(2) 小试牛刀
我们先看下《一念永恒》小说的第一章内容,URL:http://www.biqukan.com/1_1094/5403177.html
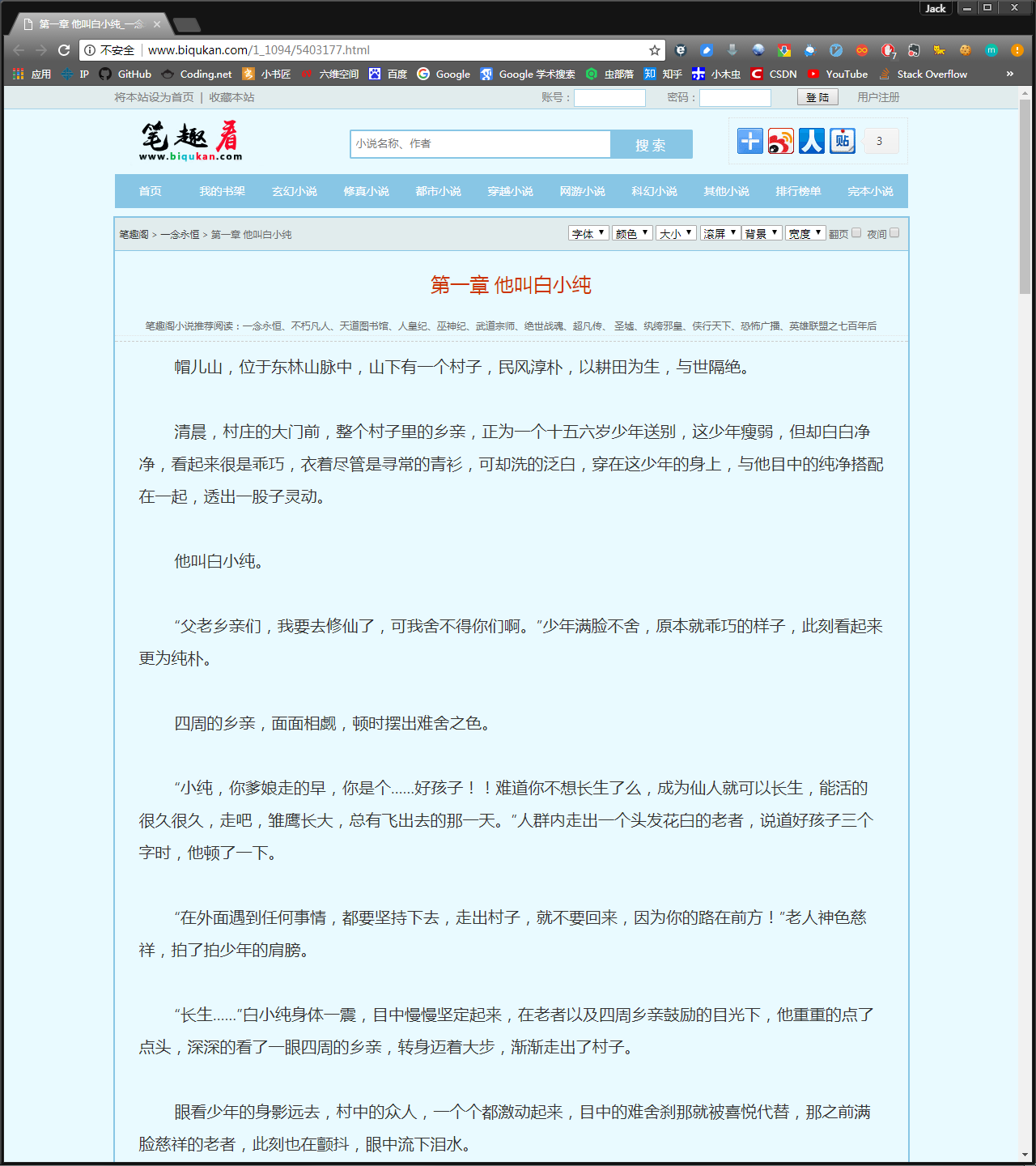
我们先用已经学到的知识获取HTML信息试一试,编写代码如下:
# -*- coding:UTF-8 -*-
import requests
if __name__ == '__main__':
target = 'http://www.biqukan.com/1_1094/5403177.html'
req = requests.get(url=target)
print(req.text)
运行代码,可以看到如下结果:
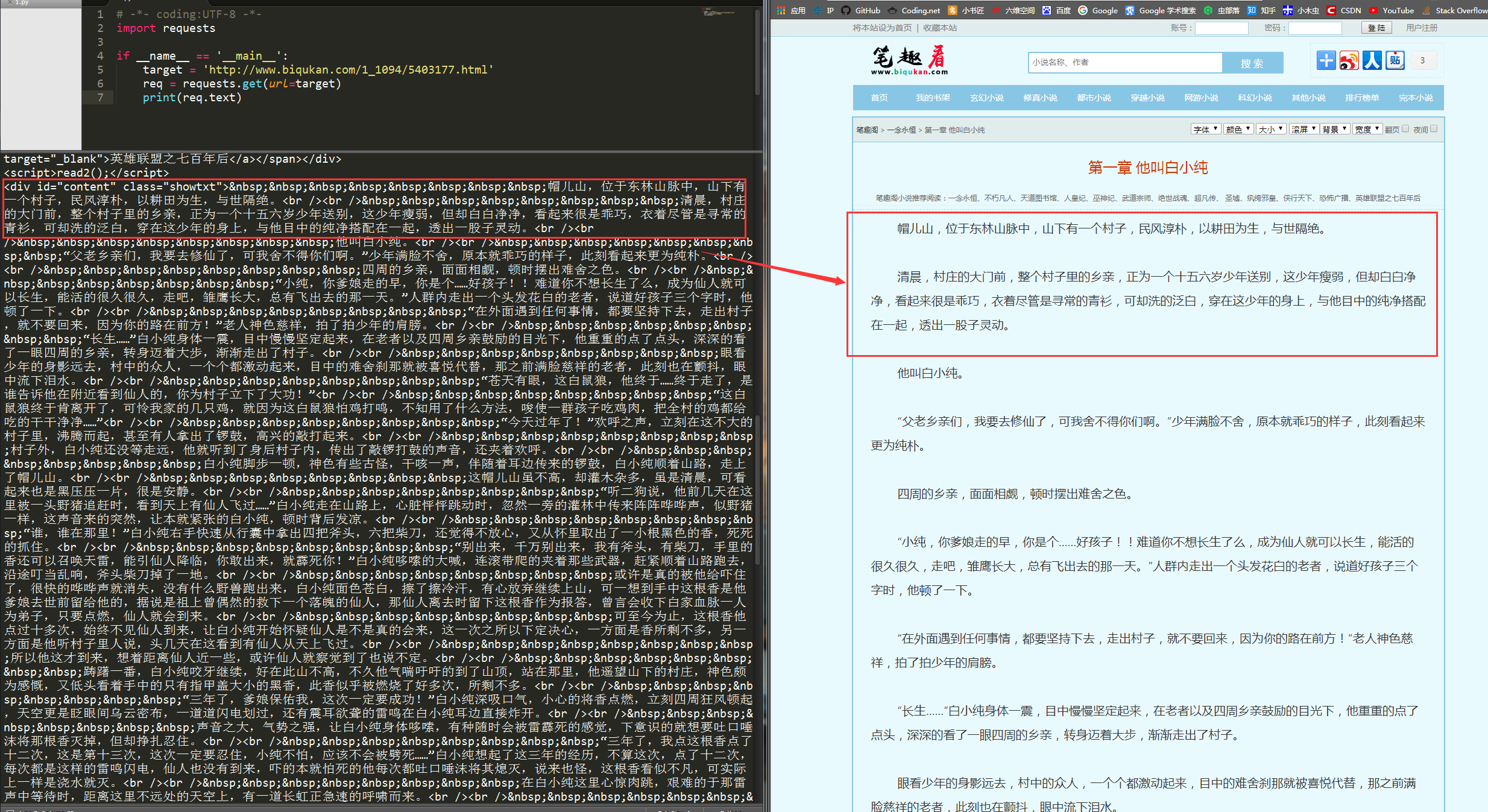
可以看到,我们很轻松地获取了HTML信息。但是,很显然,很多信息是我们不想看到的,我们只想获得如右侧所示的正文内容,我们不关心div、br这些html标签。如何把正文内容从这些众多的html标签中提取出来呢?这就是本次实战的主要内容。
###(3)Beautiful Soup
**爬虫的第一步,获取整个网页的HTML信息,我们已经完成。接下来就是爬虫的第二步,解析HTML信息,提取我们感兴趣的内容。**对于本小节的实战,我们感兴趣的内容就是文章的正文。提取的方法有很多,例如使用正则表达式、Xpath、Beautiful Soup等。对于初学者而言,最容易理解,并且使用简单的方法就是使用Beautiful Soup提取感兴趣内容。
Beautiful Soup的安装方法和requests一样,使用如下指令安装(也是二选一):
- pip install beautifulsoup4
- easy_install beautifulsoup4
一个强大的第三方库,都会有一个详细的官方文档。我们很幸运,Beautiful Soup也是有中文的官方文档。
URL:http://beautifulsoup.readthedocs.io/zh_CN/latest/
同理,我会根据实战需求,讲解Beautiful Soup库的部分使用方法,更详细的内容,请查看官方文档。
现在,我们使用已经掌握的审查元素方法,查看一下我们的目标页面,你会看到如下内容:
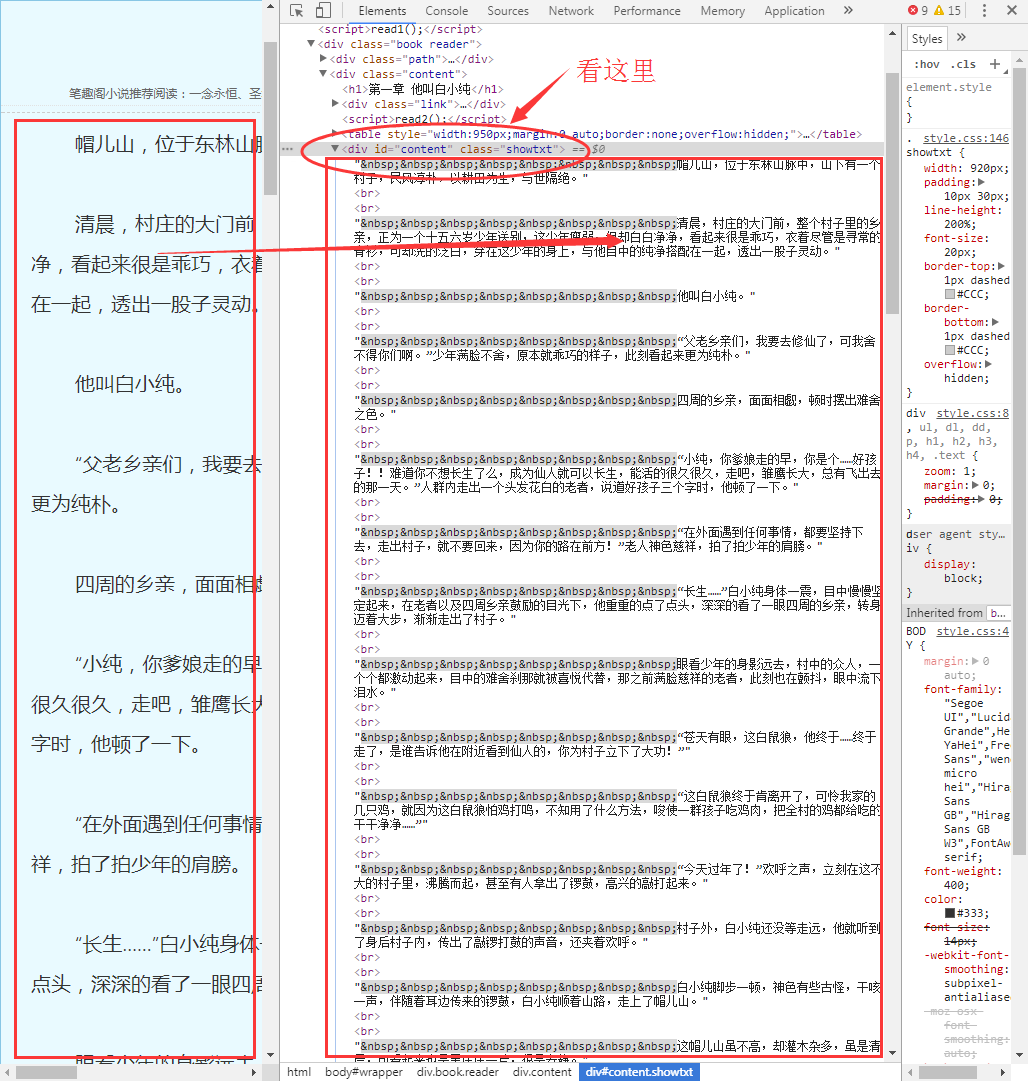
不难发现,文章的所有内容都放在了一个名为div的“东西下面”,这个”东西”就是html标签。HTML标签是HTML语言中最基本的单位,HTML标签是HTML最重要的组成部分。不理解,没关系,我们再举个简单的例子:
一个女人的包包里,会有很多东西,她们会根据自己的习惯将自己的东西进行分类放好。镜子和口红这些会经常用到的东西,会归放到容易拿到的外侧口袋里。那些不经常用到,需要注意安全存放的证件会放到不容易拿到的里侧口袋里。
html标签就像一个个“口袋”,每个“口袋”都有自己的特定功能,负责存放不同的内容。显然,上述例子中的div标签下存放了我们关心的正文内容。这个div标签是这样的:
<div id="content", class="showtxt">
细心的朋友可能已经发现,除了div字样外,还有id和class。id和class就是div标签的属性,content和showtxt是属性值,一个属性对应一个属性值。这东西有什么用?它是用来区分不同的div标签的,因为div标签可以有很多,我们怎么加以区分不同的div标签呢?就是通过不同的属性值。
仔细观察目标网站一番,我们会发现这样一个事实:class属性为showtxt的div标签,独一份!这个标签里面存放的内容,是我们关心的正文部分。
知道这个信息,我们就可以使用Beautiful Soup提取我们想要的内容了,编写代码如下:
# -*- coding:UTF-8 -*-
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
target = 'http://www.biqukan.com/1_1094/5403177.html'
req = requests.get(url = target)
html = req.text
bf = BeautifulSoup(html)
texts = bf.find_all('div', class_ = 'showtxt') print(texts)
在解析html之前,我们需要创建一个Beautiful Soup对象。BeautifulSoup函数里的参数就是我们已经获得的html信息。然后我们使用find_all方法,获得html信息中所有class属性为showtxt的div标签。find_all方法的第一个参数是获取的标签名,第二个参数class_是标签的属性,为什么不是class,而带了一个下划线呢?因为python中class是关键字,为了防止冲突,这里使用class_表示标签的class属性,class_后面跟着的showtxt就是属性值了。看下我们要匹配的标签格式:
<div id="content", class="showtxt">
这样对应的看一下,是不是就懂了?可能有人会问了,为什么不是find_all(‘div’, id = ‘content’, class_ = ‘showtxt’)?这样其实也是可以的,属性是作为查询时候的约束条件,添加一个class_=’showtxt’条件,我们就已经能够准确匹配到我们想要的标签了,所以我们就不必再添加id这个属性了。运行代码查看我们匹配的结果:
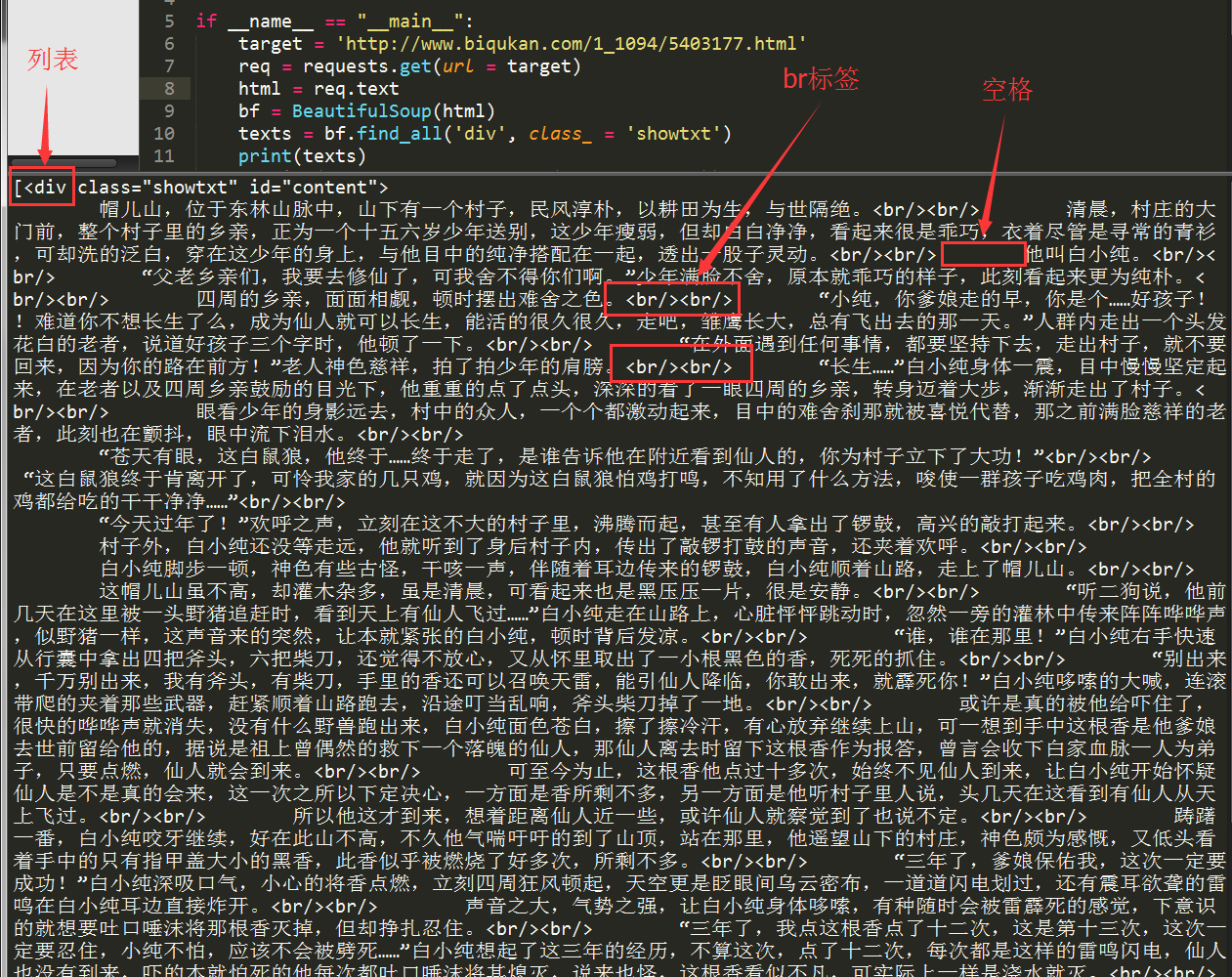
我们可以看到,我们已经顺利匹配到我们关心的正文内容,但是还有一些我们不想要的东西。比如div标签名,br标签,以及各种空格。怎么去除这些东西呢?我们继续编写代码:
# -*- coding:UTF-8 -*-
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
target = 'http://www.biqukan.com/1_1094/5403177.html'
req = requests.get(url = target) html = req.text
bf = BeautifulSoup(html)
texts = bf.find_all('div', class_ = 'showtxt')
print(texts[0].text.replace('\xa0'*8,'\n\n'))
find_all匹配的返回的结果是一个列表。提取匹配结果后,使用text属性,提取文本内容,滤除br标签。随后使用replace方法,剔除空格,替换为回车进行分段。 在html中是用来表示空格的。replace(’\xa0’*8,’\n\n’)就是去掉下图的八个空格符号,并用回车代替:
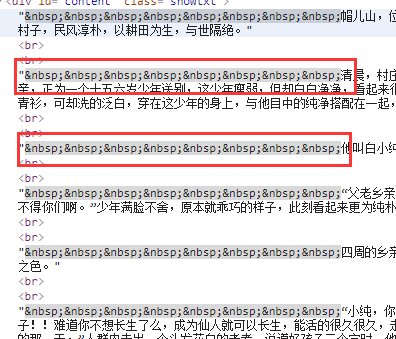
程序运行结果如下:
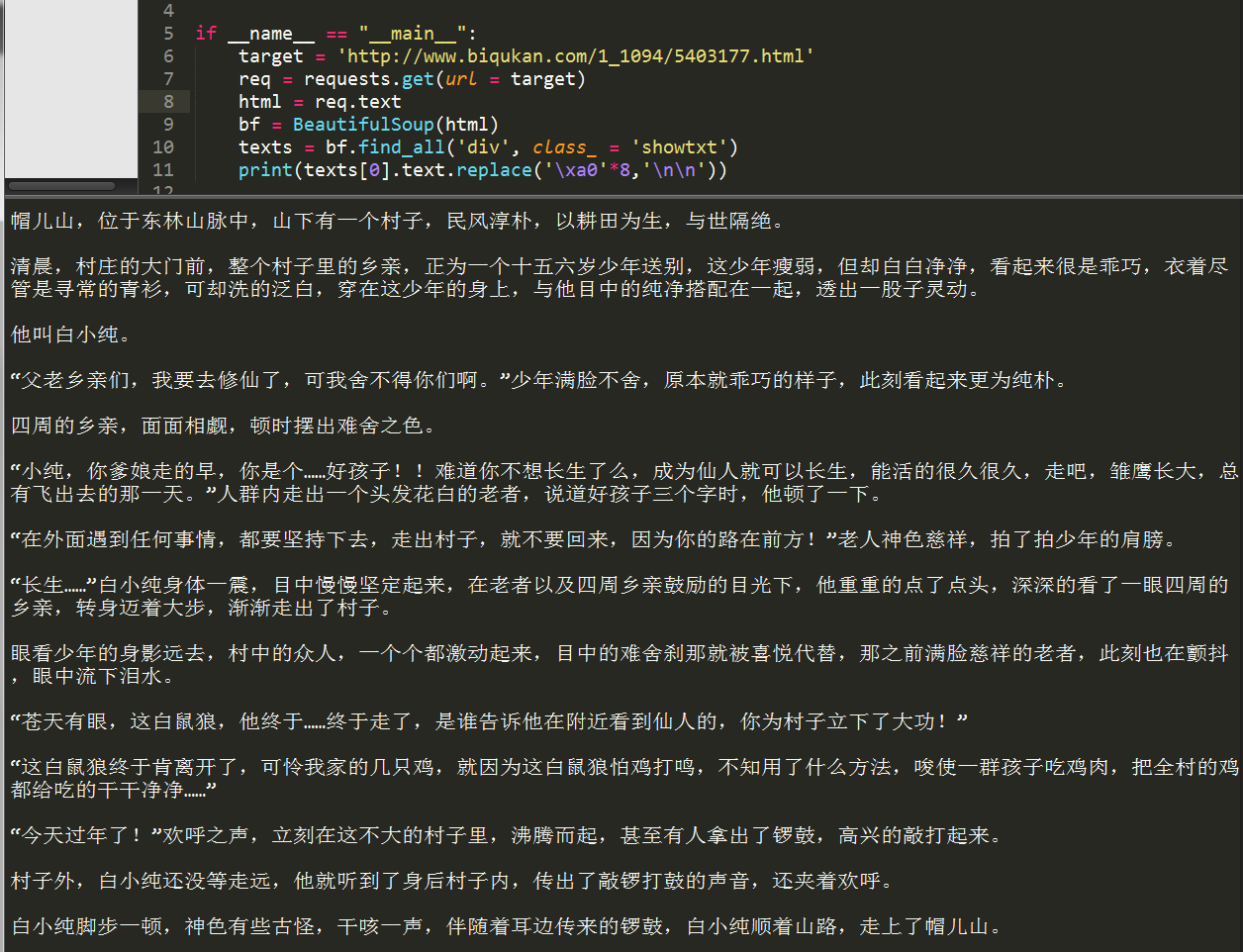
可以看到,我们很自然的匹配到了所有正文内容,并进行了分段。我们已经顺利获得了一个章节的内容,要想下载正本小说,我们就要获取每个章节的链接。我们先分析下小说目录:
URL:http://www.biqukan.com/1_1094/
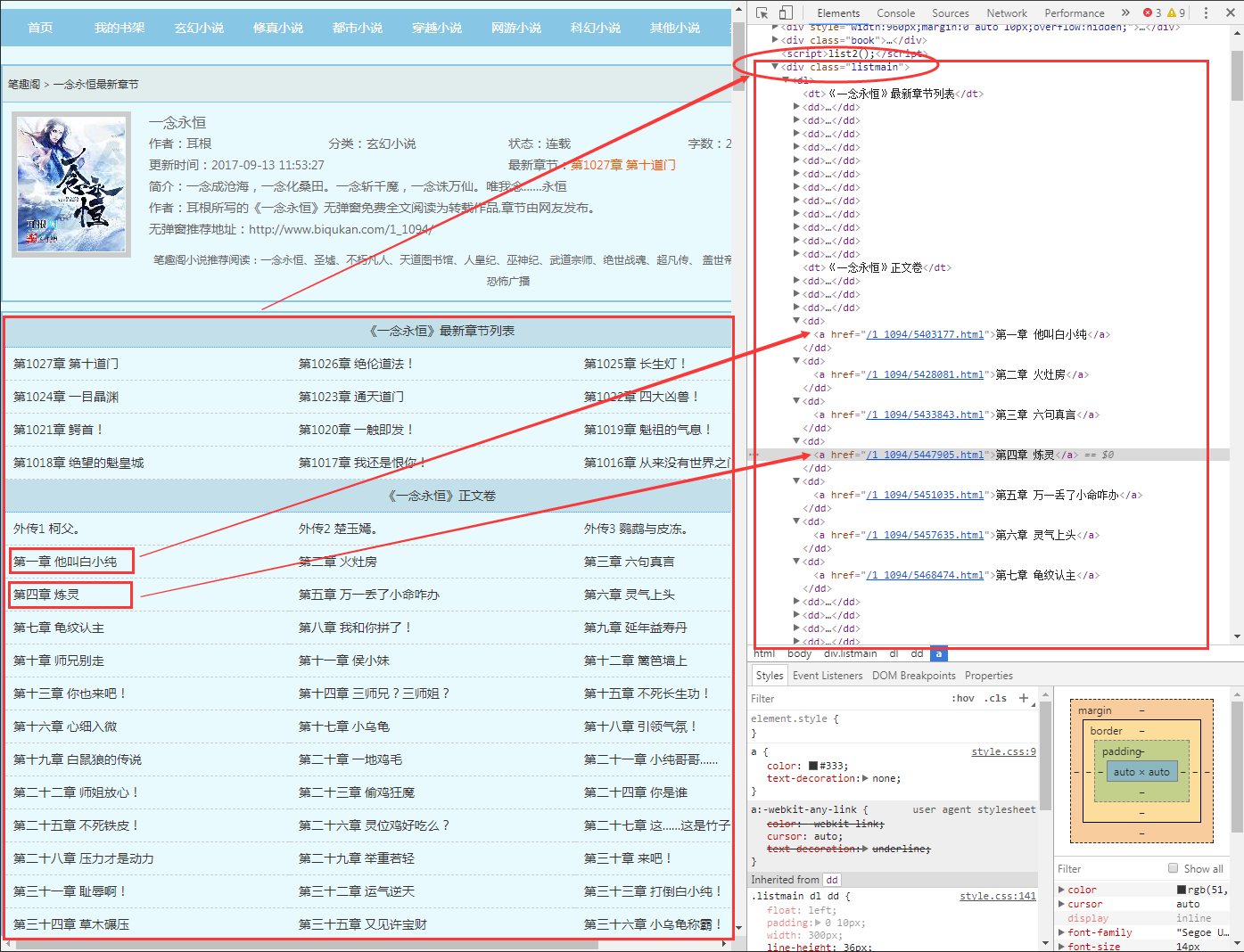
通过审查元素,我们发现可以发现,这些章节都存放在了class属性为listmain的div标签下,选取部分html代码如下:
<div class="listmain">
<dl>
<dt>《一念永恒》最新章节列表</dt>
<dd><a href="/1_1094/15932394.html">第1027章 第十道门</a></dd>
<dd><a href="/1_1094/15923072.html">第1026章 绝伦道法!</a></dd>
<dd><a href="/1_1094/15921862.html">第1025章 长生灯!</a></dd>
<dd><a href="/1_1094/15918591.html">第1024章 一目晶渊</a></dd>
<dd><a href="/1_1094/15906236.html">第1023章 通天道门</a></dd>
<dd><a href="/1_1094/15903775.html">第1022章 四大凶兽!</a></dd>
<dd><a href="/1_1094/15890427.html">第1021章 鳄首!</a></dd>
<dd><a href="/1_1094/15886627.html">第1020章 一触即发!</a></dd>
<dd><a href="/1_1094/15875306.html">第1019章 魁祖的气息!</a></dd>
<dd><a href="/1_1094/15871572.html">第1018章 绝望的魁皇城</a></dd>
<dd><a href="/1_1094/15859514.html">第1017章 我还是恨你!</a></dd>
<dd><a href="/1_1094/15856137.html">第1016章 从来没有世界之门!</a></dd>
<dt>《一念永恒》正文卷</dt> <dd><a href="/1_1094/5386269.html">外传1 柯父。</a></dd>
<dd><a href="/1_1094/5386270.html">外传2 楚玉嫣。</a></dd> <dd><a href="/1_1094/5386271.html">外传3 鹦鹉与皮冻。</a></dd>
<dd><a href="/1_1094/5403177.html">第一章 他叫白小纯</a></dd> <dd><a href="/1_1094/5428081.html">第二章 火灶房</a></dd>
<dd><a href="/1_1094/5433843.html">第三章 六句真言</a></dd> <dd><a href="/1_1094/5447905.html">第四章 炼灵</a></dd>
</dl>
</div>
在分析之前,让我们先介绍一个概念:父节点、子节点、孙节点。<div>和</div>限定了<div>标签的开始和结束的位置,他们是成对出现的,有开始位置,就有结束位置。我们可以看到,在<div>标签包含<dl>标签,那这个<dl>标签就是<div>标签的子节点,<dl>标签又包含<dt>标签和<dd>标签,那么<dt>标签和<dd>标签就是<div>标签的孙节点。有点绕?那你记住这句话:谁包含谁,谁就是谁儿子!
**他们之间的关系都是相对的。**比如对于<dd>标签,它的子节点是<a>标签,它的父节点是<dl>标签。这跟我们人是一样的,上有老下有小。
看到这里可能有人会问,这有好多<dd>标签和<a>标签啊!不同的<dd>标签,它们是什么关系啊?显然,兄弟姐妹喽!我们称它们为兄弟结点。
好了,概念明确清楚,接下来,让我们分析一下问题。我们看到每个章节的名字存放在了<a>标签里面。<a>标签还有一个href属性。这里就不得不提一下<a>标签的定义了,<a>标签定义了一个超链接,用于从一张页面链接到另一张页面。<a> 标签最重要的属性是 href 属性,它指示链接的目标。
我们将之前获得的第一章节的URL和<a> 标签对比看一下:
http://www.biqukan.com/1_1094/5403177.html
<a href="/1_1094/5403177.html">第一章 他叫白小纯</a>
不难发现,<a> 标签中href属性存放的属性值/1_1094/5403177.html是章节URLhttp://www.biqukan.com/1_1094/5403177.html的后半部分。其他章节也是如此!那这样,我们就可以根据<a>标签的href属性值获得每个章节的链接和名称了。
总结一下:小说每章的链接放在了class属性为listmain的<div>标签下的<a>标签中。链接具体位置放在html->body->div->dl->dd->a的href属性中。先匹配class属性为listmain的<div>标签,再匹配<a>标签。编写代码如下:
# -*- coding:UTF-8 -*-
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
target = 'http://www.biqukan.com/1_1094/'
req = requests.get(url = target)
html = req.text
div_bf = BeautifulSoup(html)
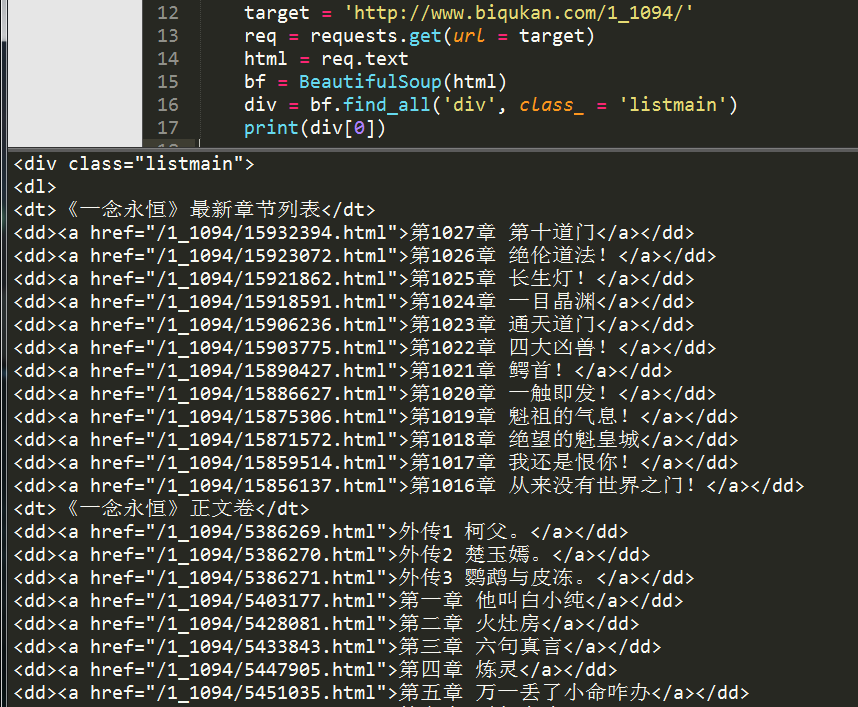
div = div_bf.find_all('div', class_ = 'listmain')
print(div[0])
还是使用find_all方法,运行结果如下:
很顺利,接下来再匹配每一个<a>标签,并提取章节名和章节文章。如果我们使用Beautiful Soup匹配到了下面这个<a>标签,如何提取它的href属性和<a>标签里存放的章节名呢?
<a href="/1_1094/5403177.html">第一章 他叫白小纯</a>
方法很简单,对Beautiful Soup返回的匹配结果a,使用a.get(‘href’)方法就能获取href的属性值,使用a.string就能获取章节名,编写代码如下:
# -*- coding:UTF-8 -*-
from bs4 import BeautifulSoup
import requests
if __name__ == "__main__":
server = 'http://www.biqukan.com/'
target = 'http://www.biqukan.com/1_1094/'
req = requests.get(url = target) html = req.text
div_bf = BeautifulSoup(html)
div = div_bf.find_all('div', class_ = 'listmain')
a_bf = BeautifulSoup(str(div[0]))
a = a_bf.find_all('a')
for each in a:
print(each.string, server + each.get('href'))
因为find_all返回的是一个列表,里边存放了很多的<a>标签,所以使用for循环遍历每个<a>标签并打印出来,运行结果如下。
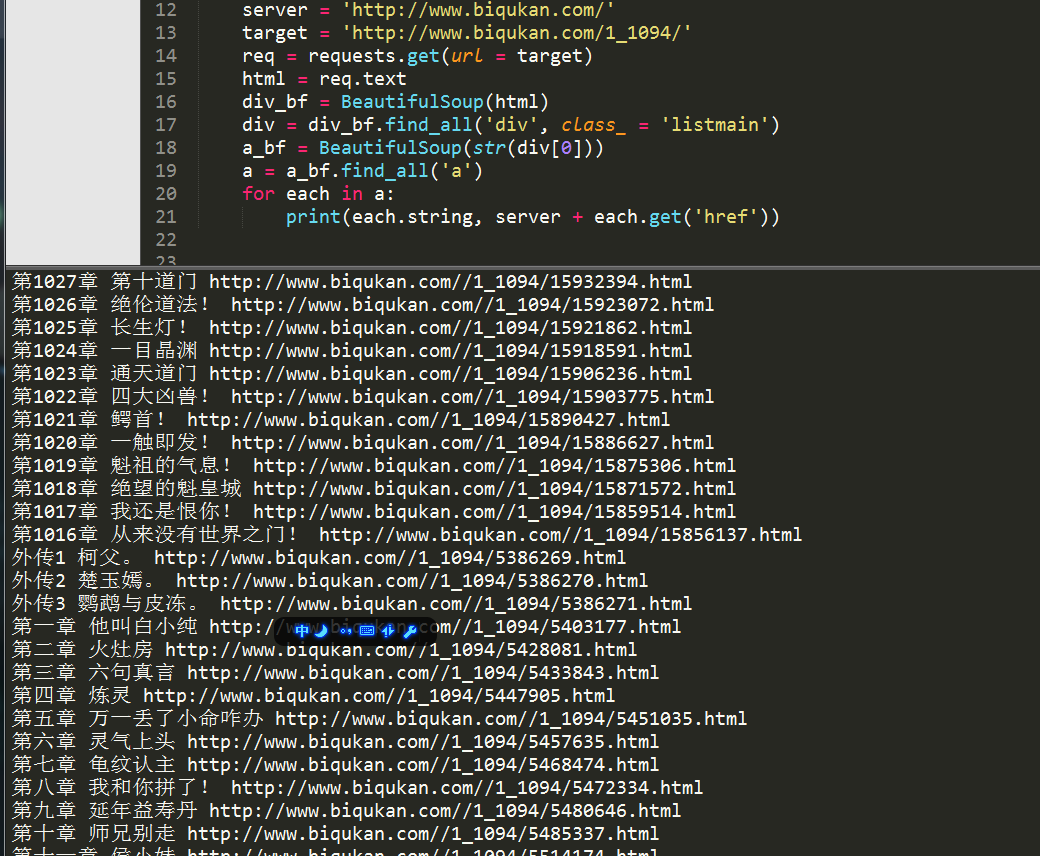
最上面匹配的一千多章的内容是最新更新的12章节的链接。这12章内容会和下面的重复,所以我们要滤除,除此之外,还有那3个外传,我们也不想要。这些都简单地剔除就好。
###(3)整合代码
每个章节的链接、章节名、章节内容都有了。接下来就是整合代码,将获得内容写入文本文件存储就好了。编写代码如下:
# -*- coding:UTF-8 -*-
from bs4 import BeautifulSoup
import requests, sys
"""
类说明:下载《笔趣看》网小说《一念永恒》
Parameters:
无
Returns:
无
Modify:
2017-09-13
"""
class downloader(object):
def __init__(self):
self.server = 'http://www.biqukan.com/'
self.target = 'http://www.biqukan.com/1_1094/'
self.names = [] #存放章节名
self.urls = [] #存放章节链接
self.nums = 0 #章节数
"""
函数说明:获取下载链接
Parameters:
无
Returns:
无
Modify:
2017-09-13
"""
def get_download_url(self):
req = requests.get(url = self.target)
html = req.text
div_bf = BeautifulSoup(html)
div = div_bf.find_all('div', class_ = 'listmain')
a_bf = BeautifulSoup(str(div[0]))
a = a_bf.find_all('a')
self.nums = len(a[15:]) #剔除不必要的章节,并统计章节数
for each in a[15:]:
self.names.append(each.string)
self.urls.append(self.server + each.get('href'))
"""
函数说明:获取章节内容
Parameters:
target - 下载连接(string)
Returns:
texts - 章节内容(string)
Modify:
2017-09-13
"""
def get_contents(self, target):
req = requests.get(url = target)
html = req.text
bf = BeautifulSoup(html)
texts = bf.find_all('div', class_ = 'showtxt')
texts = texts[0].text.replace('\xa0'*8,'\n\n')
return texts
"""
函数说明:将爬取的文章内容写入文件
Parameters:
name - 章节名称(string)
path - 当前路径下,小说保存名称(string)
text - 章节内容(string)
Returns:
无
Modify:
2017-09-13
"""
def writer(self, name, path, text):
write_flag = True
with open(path, 'a', encoding='utf-8') as f:
f.write(name + '\n')
f.writelines(text)
f.write('\n\n')
if __name__ == "__main__":
dl = downloader()
dl.get_download_url()
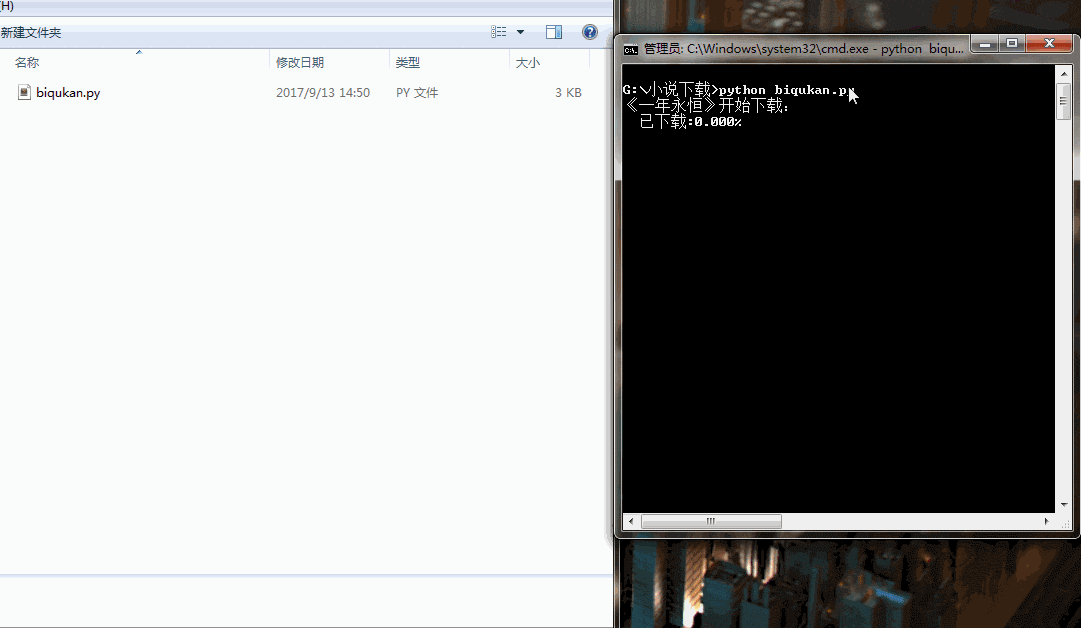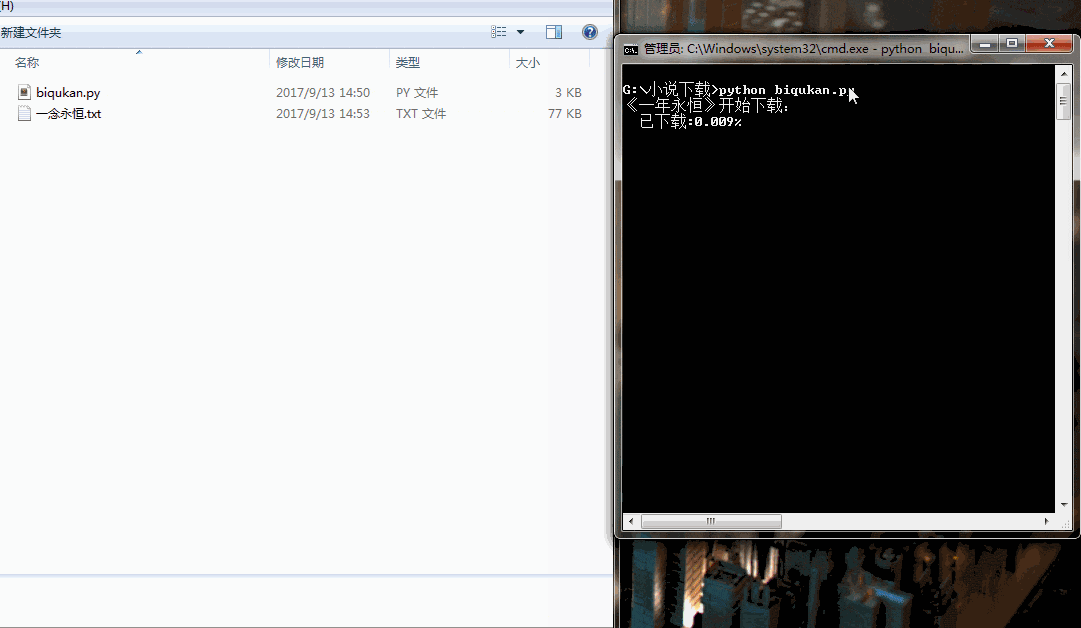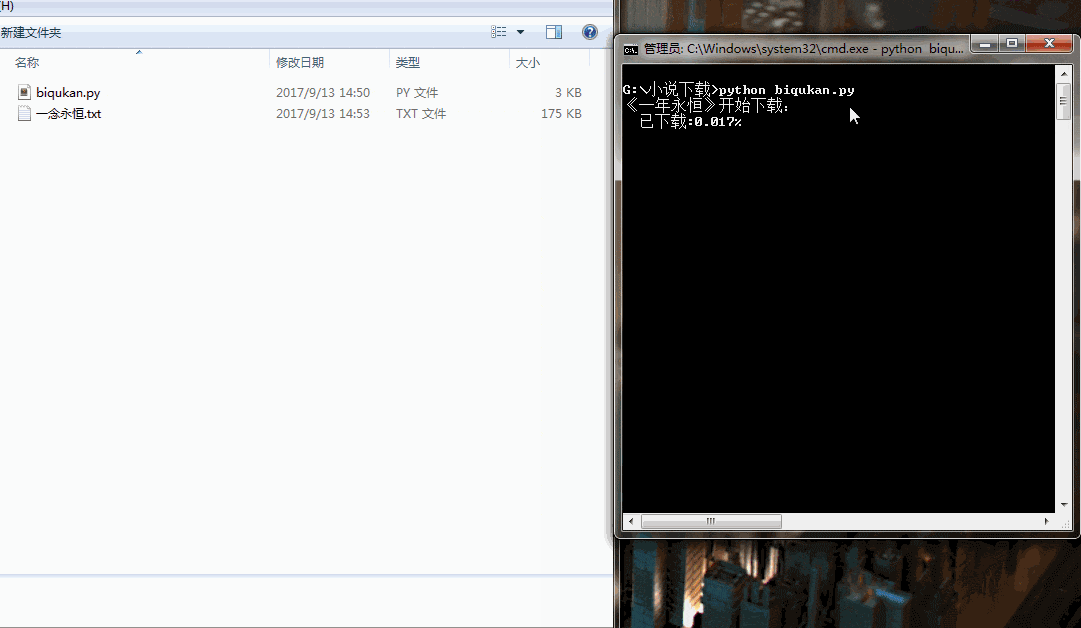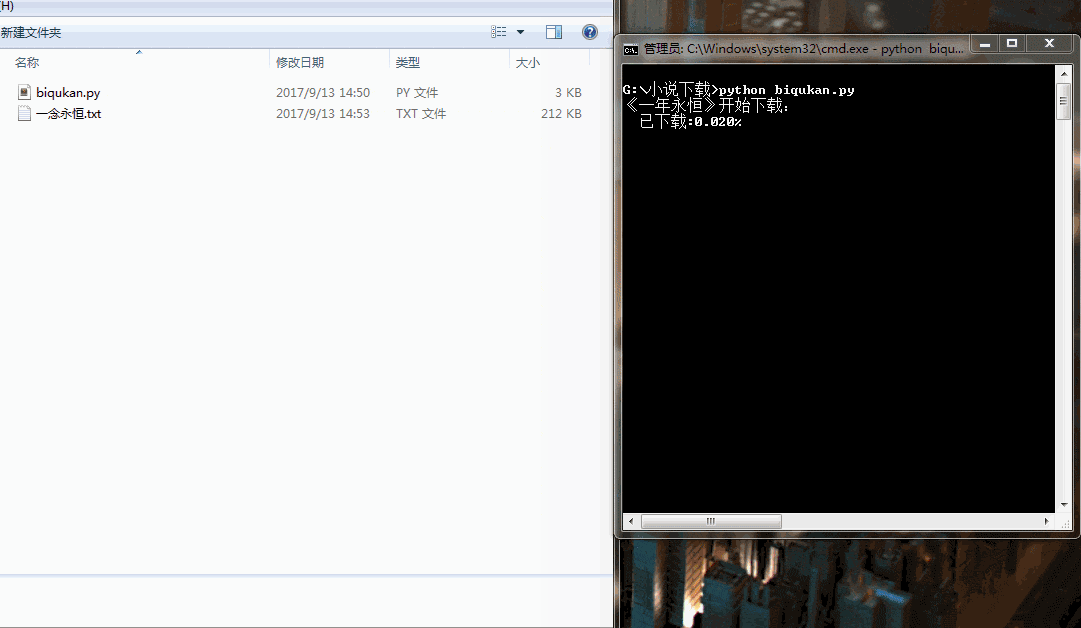
print('《一年永恒》开始下载:')
for i in range(dl.nums):
dl.writer(dl.names[i], '一念永恒.txt', dl.get_contents(dl.urls[i]))
sys.stdout.write(" 已下载:%.3f%%" % float(i/dl.nums) + '\r')
sys.stdout.flush()
print('《一年永恒》下载完成')
很简单的程序,单进程跑,没有开进程池。下载速度略慢,喝杯茶休息休息吧。代码运行效果如下图所示:
2 优美壁纸下载
###(1)实战背景
已经会爬取文字了,是不是感觉爬虫还是蛮好玩的呢?接下来,让我们进行一个进阶实战,了解一下反爬虫。
URL:https://unsplash.com/
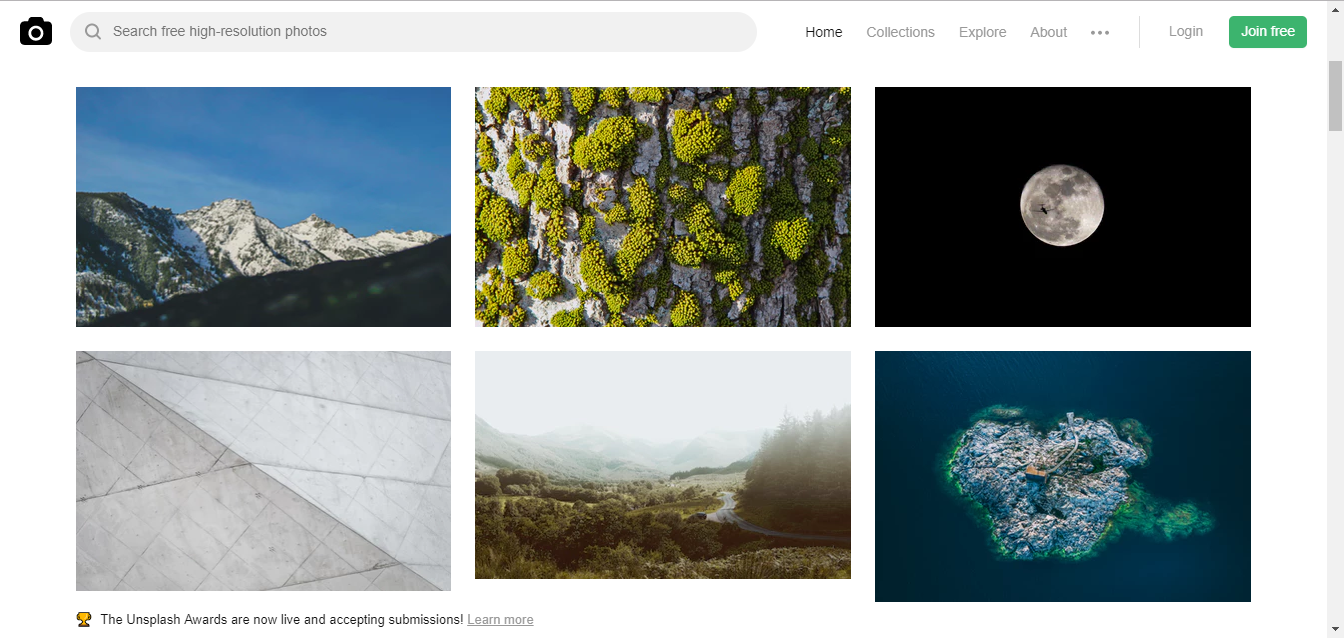
看一看这些优美的壁纸,这个网站的名字叫做Unsplash,免费高清壁纸分享网是一个坚持每天分享高清的摄影图片的站点,每天更新一张高质量的图片素材,全是生活中的景象作品,清新的生活气息图片可以作为桌面壁纸也可以应用于各种需要的环境。
看到这么优美的图片,我的第一反应就是想收藏一些,作为知乎文章的题图再好不过了。每张图片我都很喜欢,批量下载吧,不多爬,就下载50张好了。
###(2)实战进阶
我们已经知道了每个html标签都有各自的功能。<a>标签存放一下超链接,图片存放在哪个标签里呢?html规定,图片统统给我放到<img>标签中!既然这样,我们截取就Unsplash网站中的一个<img>标签,分析一下:
<img alt="Snow-capped mountain slopes under blue sky" src="https://images.unsplash.com/photo-1428509774491-cfac96e12253?dpr=1&auto=compress,format&fit=crop&w=360&h=240&q=80&cs=tinysrgb&crop=" class="cV68d" style="width: 220px; height: 147px;">
可以看到,<img>标签有很多属性,有alt、src、class、style属性,其中src属性存放的就是我们需要的图片保存地址,我们根据这个地址就可以进行图片的下载。
那么,让我们先捋一捋这个过程:
- 使用requeusts获取整个网页的HTML信息;
- 使用Beautiful Soup解析HTML信息,找到所有
<img>标签,提取src属性,获取图片存放地址; - 根据图片存放地址,下载图片。
我们信心满满地按照这个思路爬取Unsplash试一试,编写代码如下:
# -*- coding:UTF-8 -*-
import requests
if __name__ == '__main__':
target = 'https://unsplash.com/'
req = requests.get(url=target)
print(req.text)
按照我们的设想,我们应该能找到很多<img>标签。但是我们发现,除了一些<script>标签和一些看不懂的代码之外,我们一无所获,一个<img>标签都没有!跟我们在网站审查元素的结果完全不一样,这是为什么?
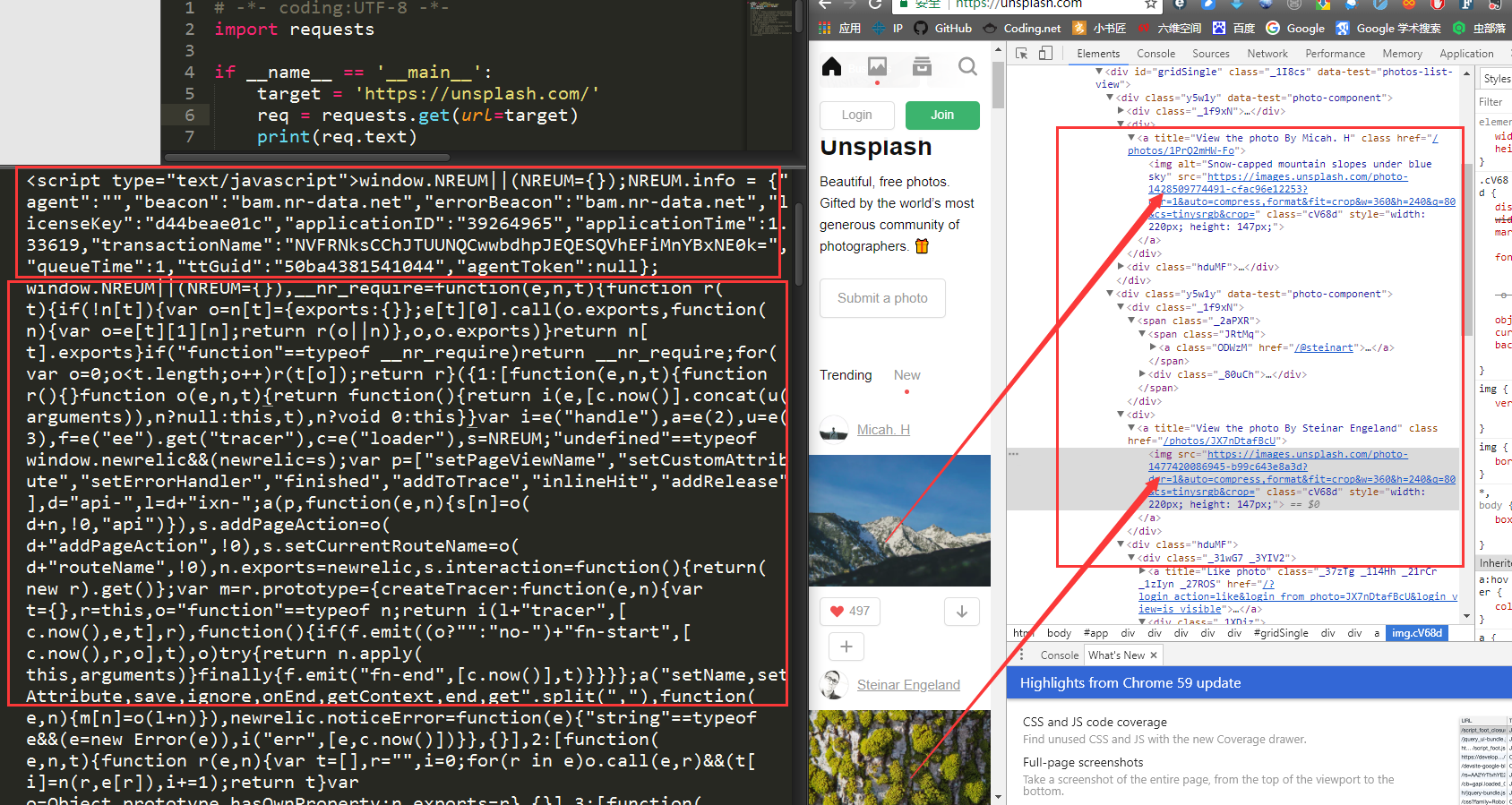
**答案就是,这个网站的所有图片都是动态加载的!**网站有静态网站和动态网站之分,上一个实战爬取的网站是静态网站,而这个网站是动态网站,动态加载有一部分的目的就是为了反爬虫。
对于什么是动态加载,你可以这样理解:我们知道化妆术学的好,贼厉害,可以改变一个人的容貌。相应的,动态加载用的好,也贼厉害,可以改变一个网站的容貌。
动态网站使用动态加载常用的手段就是通过调用JavaScript来实现的。怎么实现JavaScript动态加载,我们不必深究,我们只要知道,动态加载的JavaScript脚本,就像化妆术需要用的化妆品,五花八门。有粉底、口红、睫毛膏等等,它们都有各自的用途。动态加载的JavaScript脚本也一样,一个动态加载的网站可能使用很多JavaScript脚本,我们只要找到负责动态加载图片的JavaScript脚本,不就找到我们需要的链接了吗?
对于初学者,我们不必看懂JavaScript执行的内容是什么,做了哪些事情,因为我们有强大的抓包工具,它自然会帮我们分析。这个强大的抓包工具就是Fiddler:
URL:http://www.telerik.com/fiddler
PS:也可以使用浏览器自带的Networks,但是我更推荐这个软件,因为它操作起来更高效。
安装方法很简单,傻瓜式安装,一直下一步即可,对于经常使用电脑的人来说,应该没有任何难度。
这个软件的使用方法也很简单,打开软件,然后用浏览器打开我们的目标网站,以Unsplash为例,抓包结果如下:
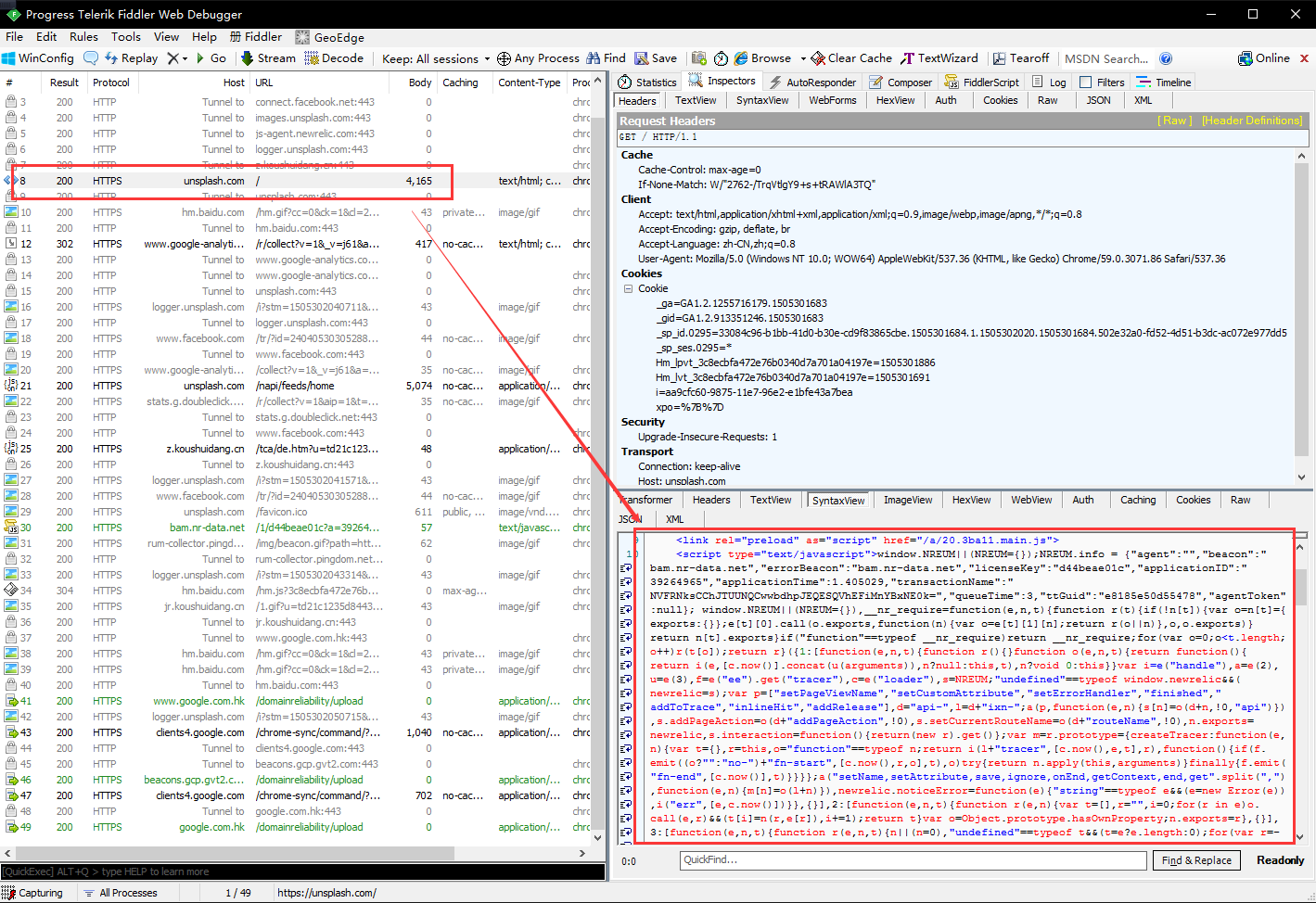
我们可以看到,上图左侧红框处是我们的GET请求的地址,就是网站的URL,右下角是服务器返回的信息,我们可以看到,这些信息也是我们上一个程序获得的信息。这个不是我们需要的链接,我们继续往下看。
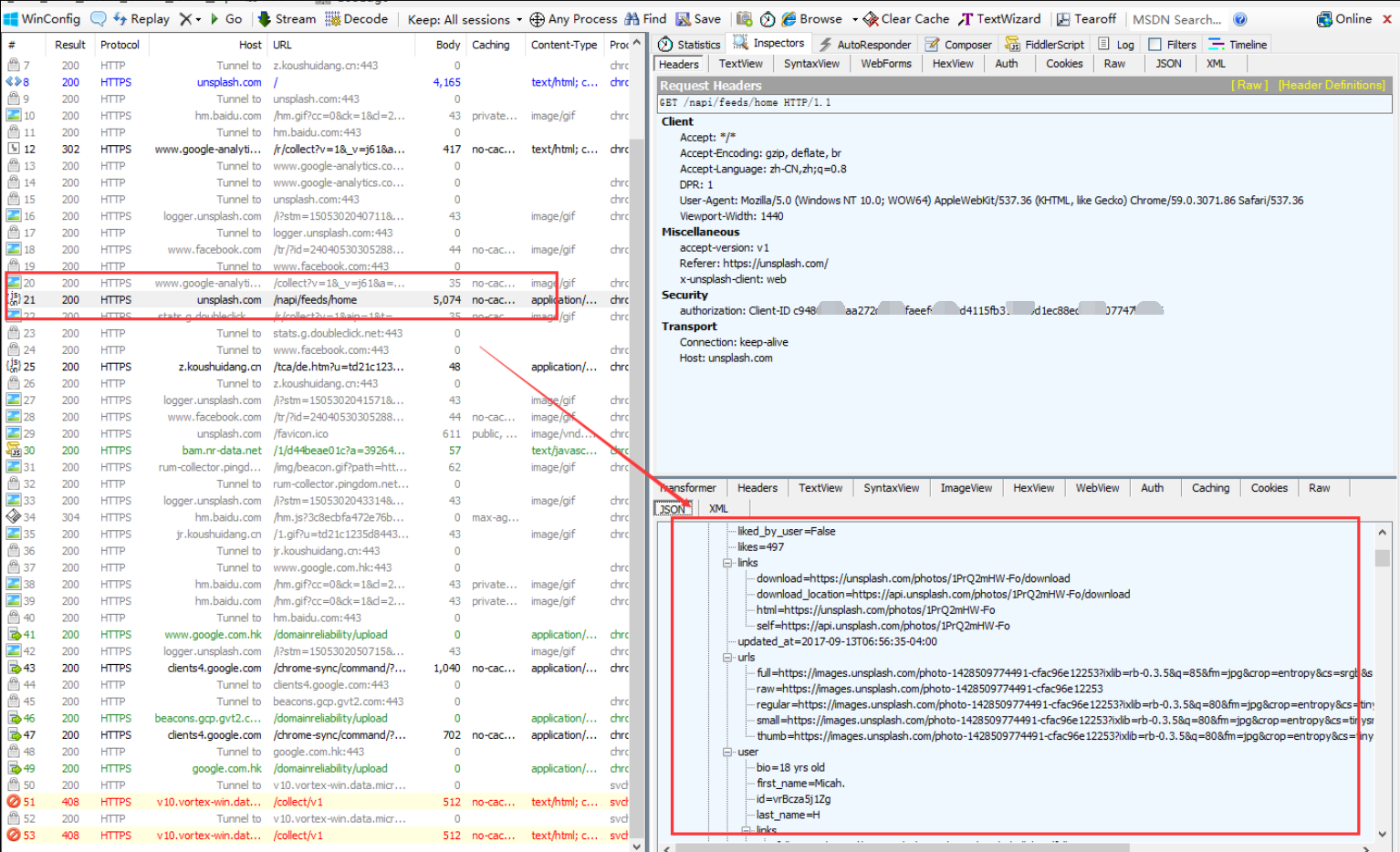
我们发现上图所示的就是一个JavaScript请求,看右下侧服务器返回的信息是一个json格式的数据。这里面,就有我们需要的内容。我们局部放大看一下:
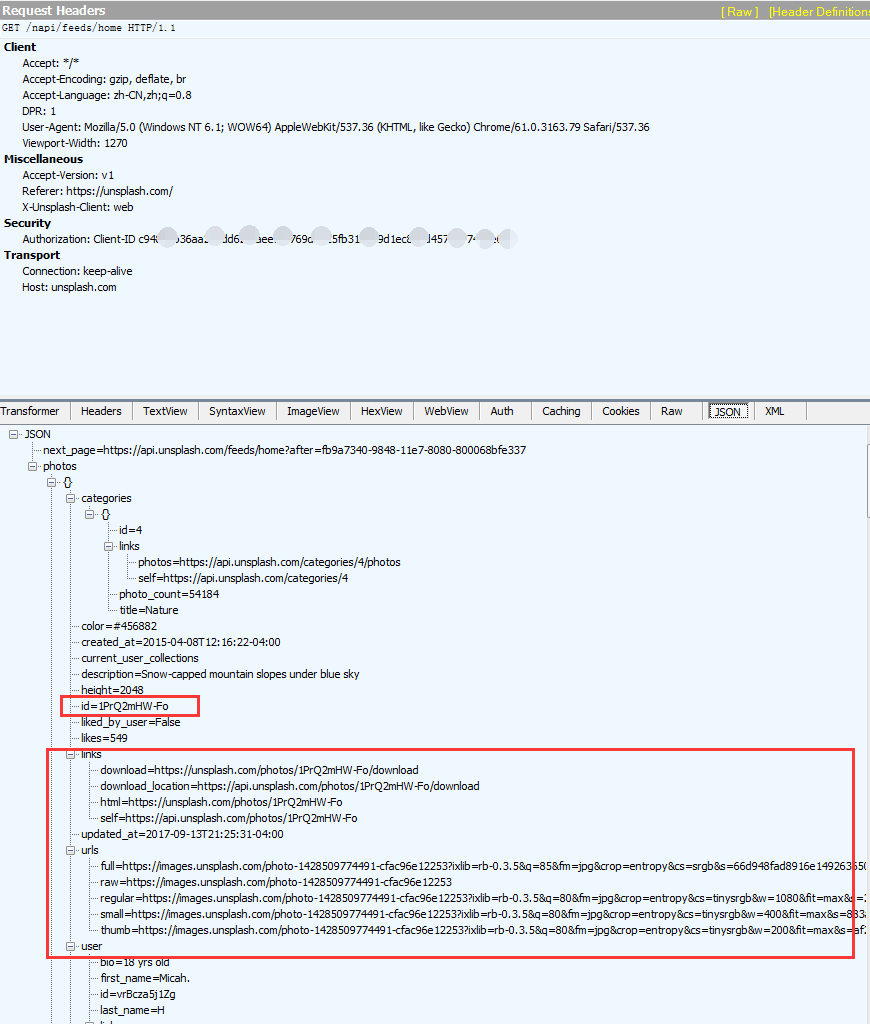
这是Fiddler右侧的信息,上面是请求的Headers信息,包括这个Javascript的请求地 址:http://unsplash.com/napi/feeds/home,其他信息我们先不管,我们看看下面的内容。里面有很多图片的信息,包括图片的id,图片的大小,图片的链接,还有下一页的地址。这个脚本以json格式存储传输的数据,json格式是一种轻量级的数据交换格式,起到封装数据的作用,易于人阅读和编写,同时也易于机器解析和生成。这么多链接,可以看到图片的链接有很多,根据哪个链接下载图片呢?先别急,让我们继续分析:
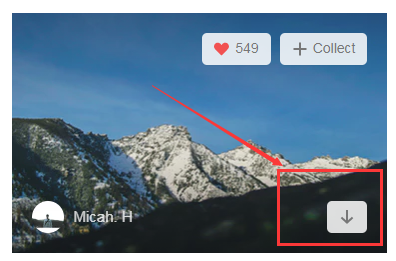
在这个网站,我们可以按这个按钮进行图片下载。我们抓包分下下这个动作,看看发送了哪些请求。
https://unsplash.com/photos/1PrQ2mHW-Fo/download?force=true
https://unsplash.com/photos/JX7nDtafBcU/download?force=true
https://unsplash.com/photos/HCVbP3zqX4k/download?force=true
通过Fiddler抓包,我们发现,点击不同图片的下载按钮,GET请求的地址都是不同的。但是它们很有规律,就是中间有一段代码是不一样的,其他地方都一样。中间那段代码是不是很熟悉?没错,它就是我们之前抓包分析得到json数据中的照片的id。我们只要解析出每个照片的id,就可以获得图片下载的请求地址,然后根据这个请求地址,我们就可以下载图片了。那么,现在的首要任务就是解析json数据了。
json格式的数据也是分层的。可以看到next_page里存放的是下一页的请求地址,很显然Unsplash下一页的内容,也是动态加载的。在photos下面的id里,存放着图片的id,这个就是我们需要获得的图片id号。
怎么编程提取这些json数据呢?我们也是分步完成:
- 获取整个json数据
- 解析json数据
编写代码,尝试获取json数据:
# -*- coding:UTF-8 -*-
import requests
if __name__ == '__main__':
target = 'http://unsplash.com/napi/feeds/home'
req = requests.get(url=target) print(req.text)
很遗憾,程序报错了,问题出在哪里?通过错误信息,我们可以看到SSL认证错误,SSL认证是指客户端到服务器端的认证。一个非常简单的解决这个认证错误的方法就是设置requests.get()方法的verify参数。这个参数默认设置为True,也就是执行认证。我们将其设置为False,绕过认证不就可以了?
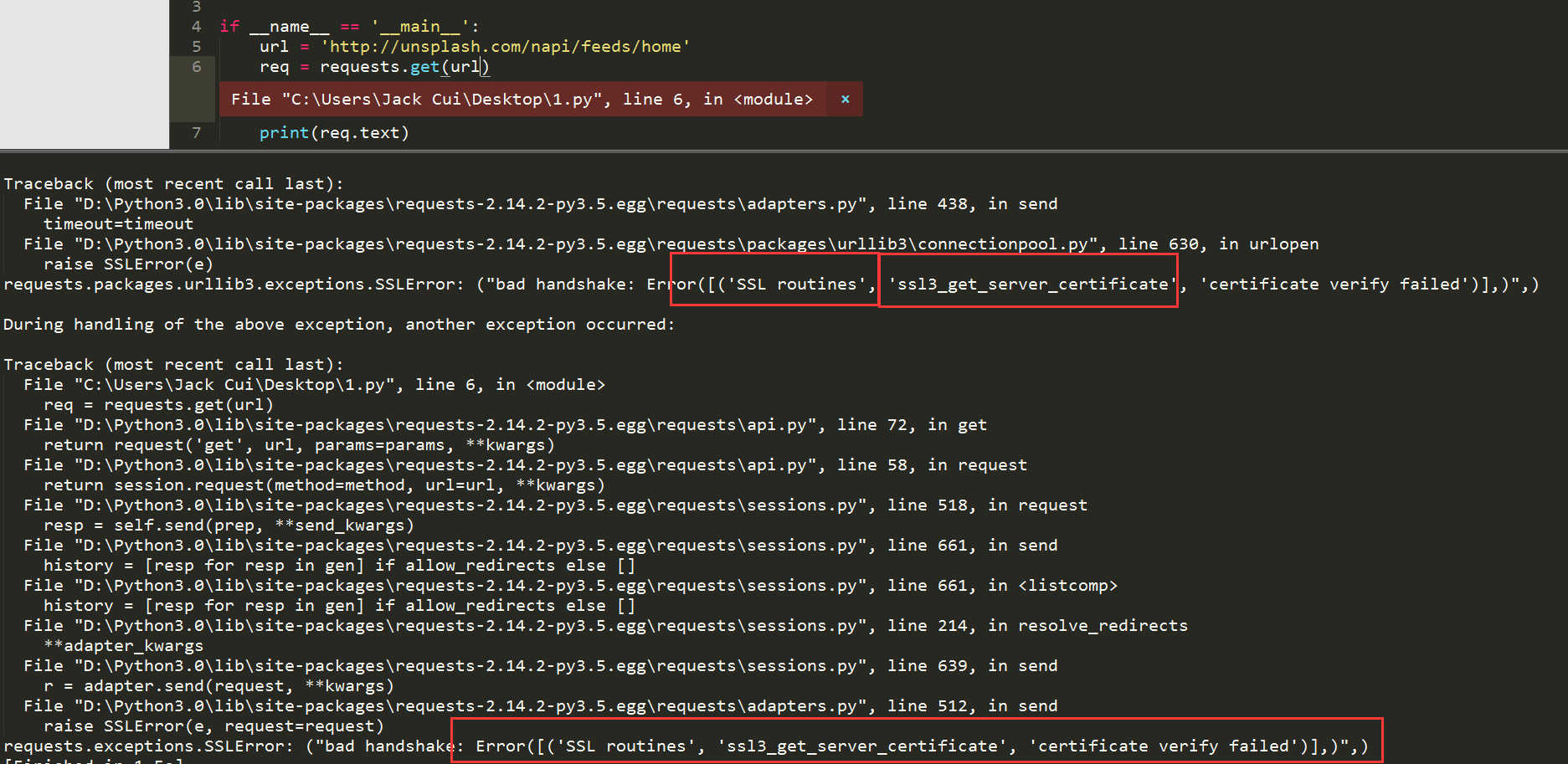
有想法就要尝试,编写代码如下:
# -*- coding:UTF-8 -*-
import requests
if __name__ == '__main__':
target = 'http://unsplash.com/napi/feeds/home'
req = requests.get(url=target, verify=False)
print(req.text)
认证问题解决了,又有新问题了:
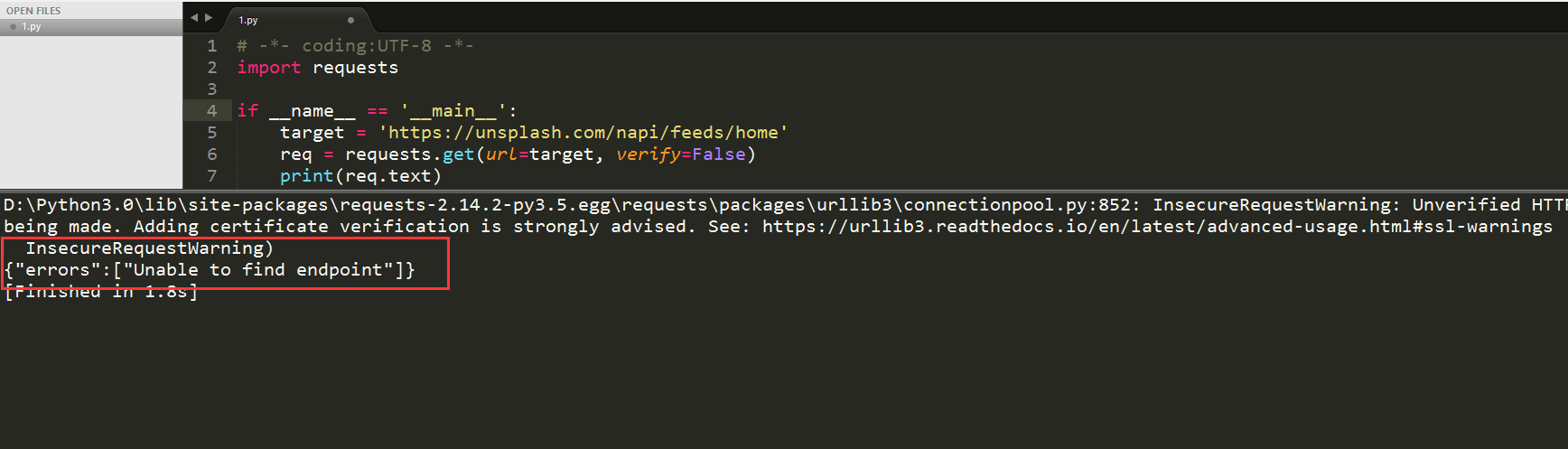
可以看到,我们GET请求又失败了,这是为什么?这个网站反爬虫的手段除了动态加载,还有一个反爬虫手段,那就是验证Request Headers。接下来,让我们分析下这个Requests Headers:
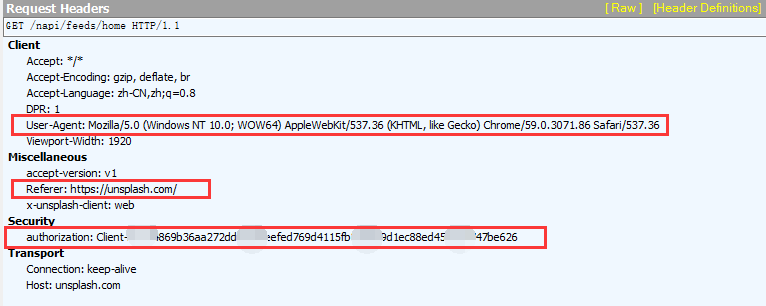
我截取了Fiddler的抓包信息,可以看到Requests Headers里又很多参数,有Accept、Accept-Encoding、Accept-Language、DPR、User-Agent、Viewport-Width、accept-version、Referer、x-unsplash-client、authorization、Connection、Host。它们都是什么意思呢?
专业的解释能说的太多,我挑重点:
-
User-Agent:这里面存放浏览器的信息。可以看到上图的参数值,它表示我是通过Windows的Chrome浏览器,访问的这个服务器。如果我们不设置这个参数,用Python程序直接发送GET请求,服务器接受到的User-Agent信息就会是一个包含python字样的User-Agent。如果后台设计者验证这个User-Agent参数是否合法,不让带Python字样的User-Agent访问,这样就起到了反爬虫的作用。这是一个最简单的,最常用的反爬虫手段。
-
Referer:这个参数也可以用于反爬虫,它表示这个请求是从哪发出的。可以看到我们通过浏览器访问网站,这个请求是从https://unsplash.com/,这个地址发出的。如果后台设计者,验证这个参数,对于不是从这个地址跳转过来的请求一律禁止访问,这样就也起到了反爬虫的作用。
-
authorization:这个参数是基于AAA模型中的身份验证信息允许访问一种资源的行为。在我们用浏览器访问的时候,服务器会为访问者分配这个用户ID。如果后台设计者,验证这个参数,对于没有用户ID的请求一律禁止访问,这样就又起到了反爬虫的作用。
Unsplash是根据哪个参数反爬虫的呢?根据我的测试,是authorization。我们只要通过程序手动添加这个参数,然后再发送GET请求,就可以顺利访问了。怎么什么设置呢?还是requests.get()方法,我们只需要添加headers参数即可。编写代码如下:
# -*- coding:UTF-8 -*-
import requests
if __name__ == '__main__':
target = 'http://unsplash.com/napi/feeds/home'
headers = {'authorization':'your Client-ID'}
req = requests.get(url=target, headers=headers, verify=False)
print(req.text)
headers参数值是通过字典传入的。记得将上述代码中your Client-ID换成诸位自己抓包获得的信息。代码运行结果如下:
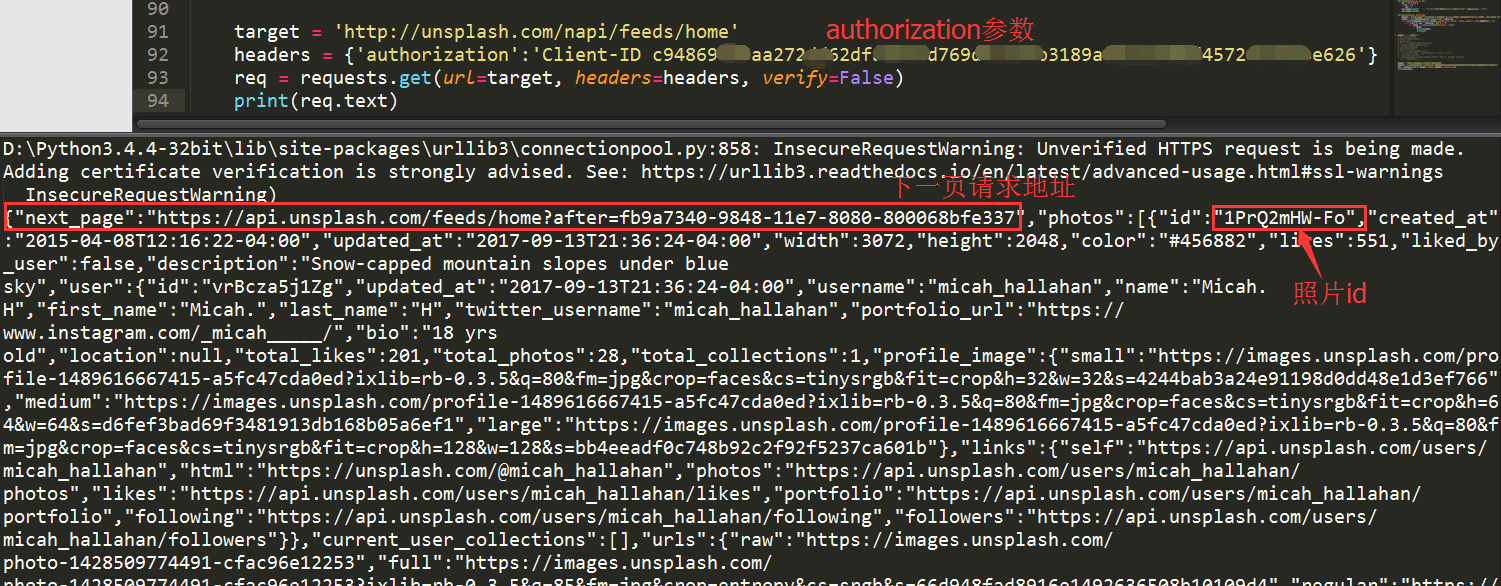
皇天不负有心人,可以看到我们已经顺利获得json数据了,里面有next_page和照片的id。接下来就是解析json数据。根据我们之前分析可知,next_page放在了json数据的最外侧,照片的id放在了photos->id里。我们使用json.load()方法解析数据,编写代码如下:
# -*- coding:UTF-8 -*-
import requests, json
if __name__ == '__main__':
target = 'http://unsplash.com/napi/feeds/home'
headers = {'authorization':'your Client-ID'}
req = requests.get(url=target, headers=headers, verify=False)
html = json.loads(req.text)
next_page = html['next_page']
print('下一页地址:',next_page)
for each in html['photos']:
print('图片ID:',each['id'])
解析json数据很简单,跟字典操作一样,就是字典套字典。json.load()里面的参数是原始的json格式的数据。程序运行结果如下:
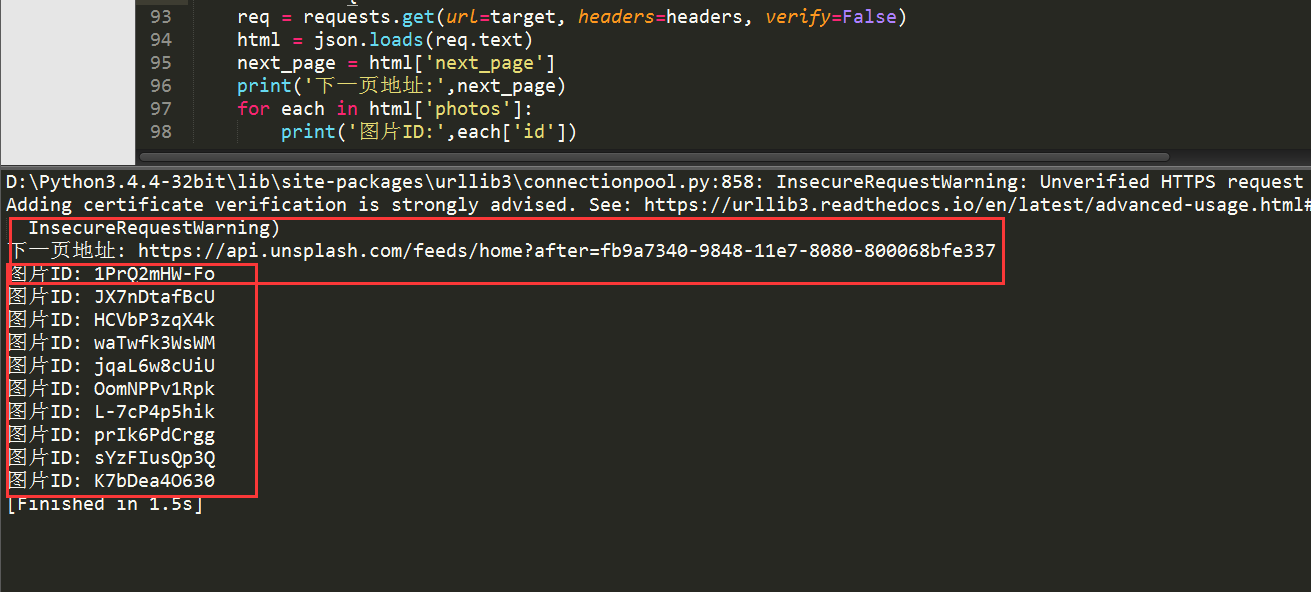
图片的ID已经获得了,再通过字符串处理一下,就生成了我们需要的图片下载请求地址。根据这个地址,我们就可以下载图片了。下载方式,使用直接写入文件的方法。
###(3)整合代码
每次获取链接加一个1s延时,因为人在浏览页面的时候,翻页的动作不可能太快。我们要让我们的爬虫尽量友好一些。
# -*- coding:UTF-8 -*-
import requests, json, time, sys
from contextlib import closing
class get_photos(object):
def __init__(self):
self.photos_id = []
self.download_server = 'https://unsplash.com/photos/xxx/download?force=trues'
self.target = 'http://unsplash.com/napi/feeds/home'
self.headers = {'authorization':'Client-ID c94869b36aa272dd62dfaeefed769d4115fb3189a9d1ec88ed457207747be626'}
"""
函数说明:获取图片ID
Parameters:
无
Returns:
无
Modify:
2017-09-13
"""
def get_ids(self):
req = requests.get(url=self.target, headers=self.headers, verify=False)
html = json.loads(req.text)
next_page = html['next_page']
for each in html['photos']:
self.photos_id.append(each['id'])
time.sleep(1)
for i in range(5):
req = requests.get(url=next_page, headers=self.headers, verify=False)
html = json.loads(req.text)
next_page = html['next_page']
for each in html['photos']:
self.photos_id.append(each['id'])
time.sleep(1)
"""
函数说明:图片下载
Parameters:
无
Returns:
无
Modify:
2017-09-13
"""
def download(self, photo_id, filename):
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.0.3163.79 Safari/537.36'}
target = self.download_server.replace('xxx', photo_id)
with closing(requests.get(url=target, stream=True, verify = False, headers = self.headers)) as r:
with open('%d.jpg' % filename, 'ab+') as f:
for chunk in r.iter_content(chunk_size = 1024):
if chunk:
f.write(chunk)
f.flush()
if __name__ == '__main__':
gp = get_photos()
print('获取图片连接中:')
gp.get_ids()
print('图片下载中:')
for i in range(len(gp.photos_id)):
print(' 正在下载第%d张图片' % (i+1))
gp.download(gp.photos_id[i], (i+1))
下载速度还行,有的图片下载慢是因为图片太大。可以看到右侧也打印了一些警报信息,这是因为我们没有进行SSL验证。
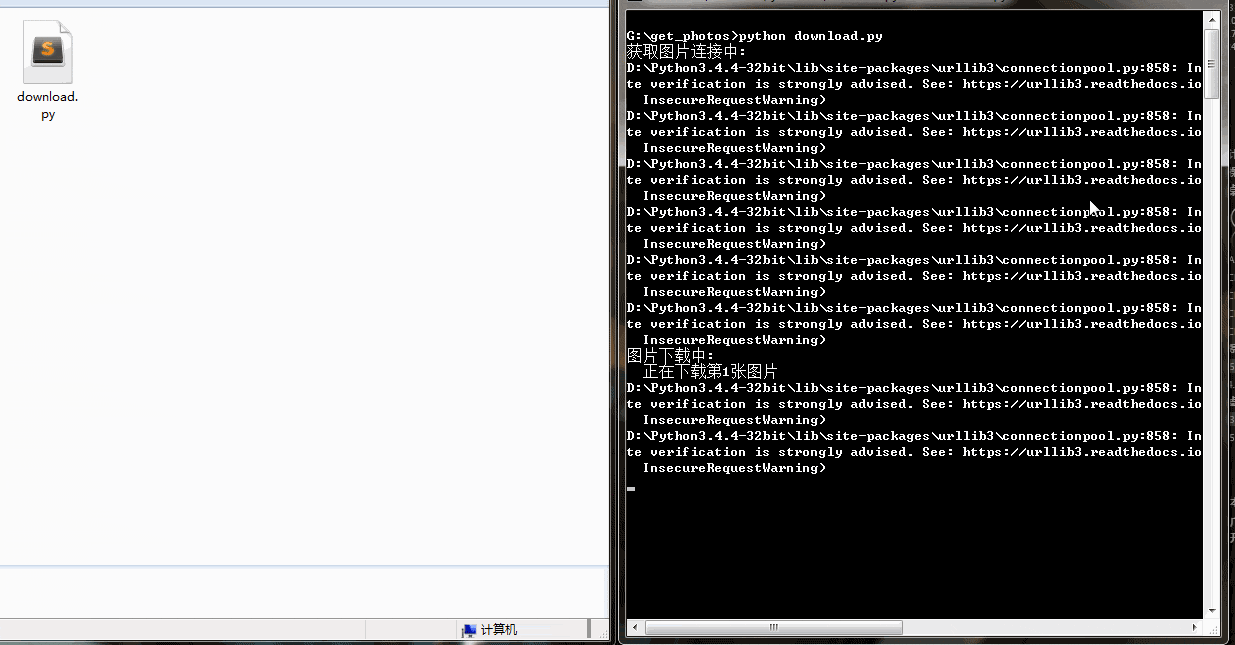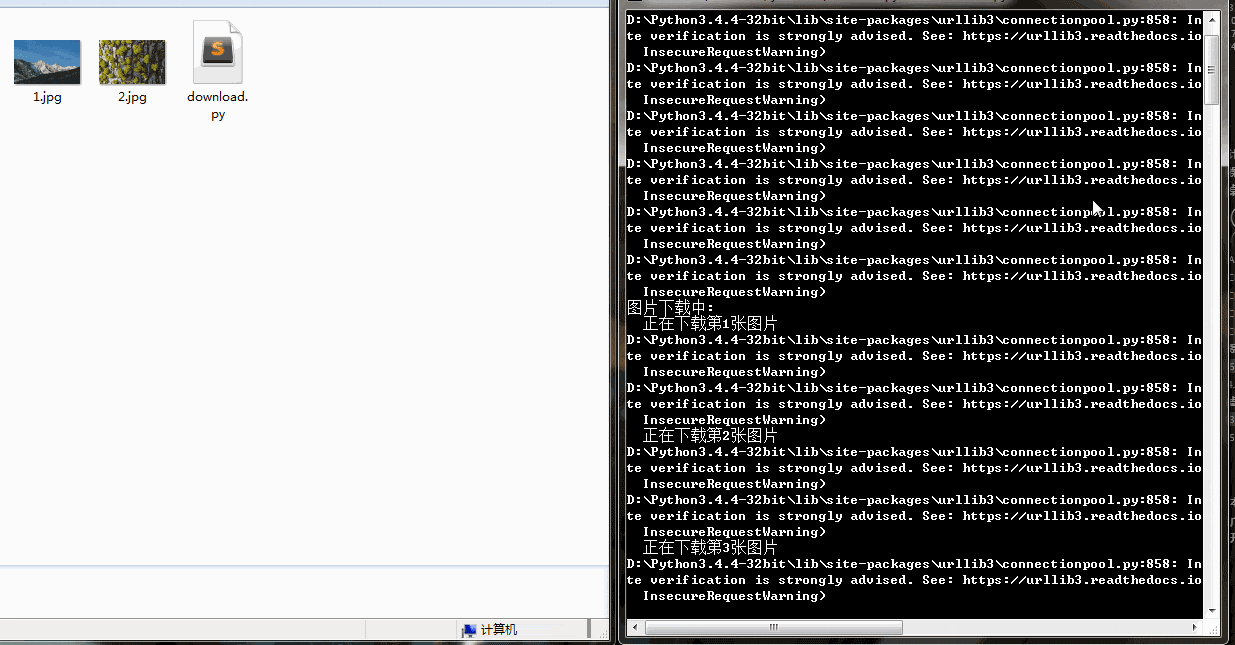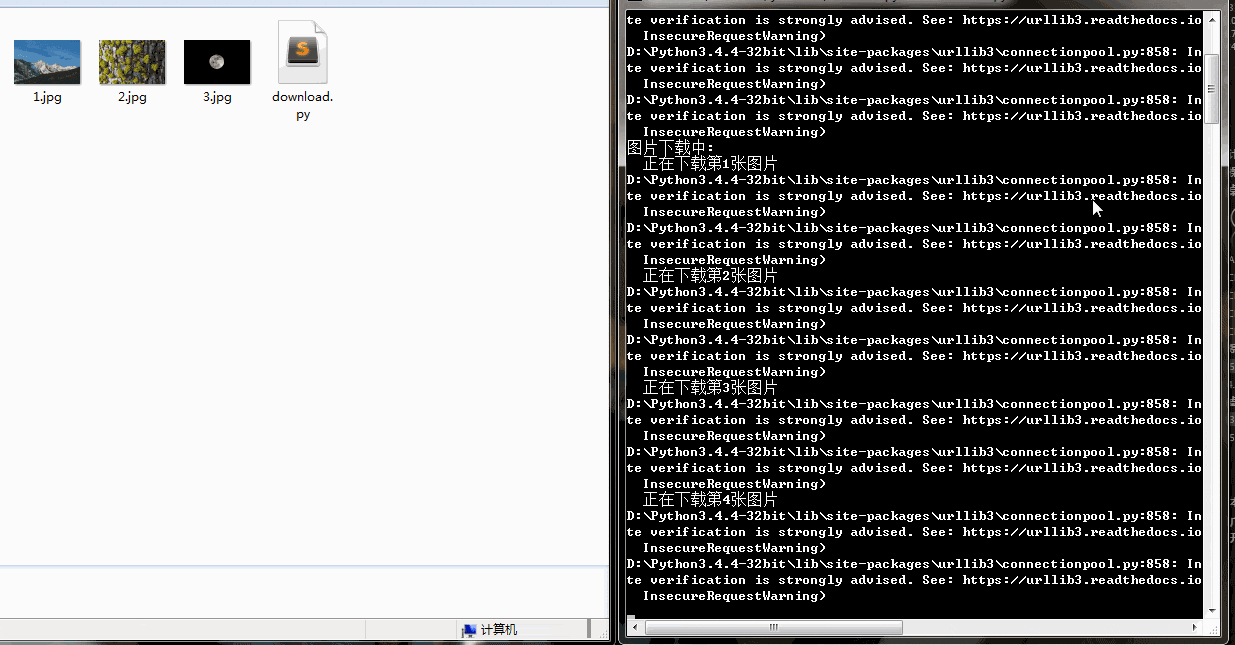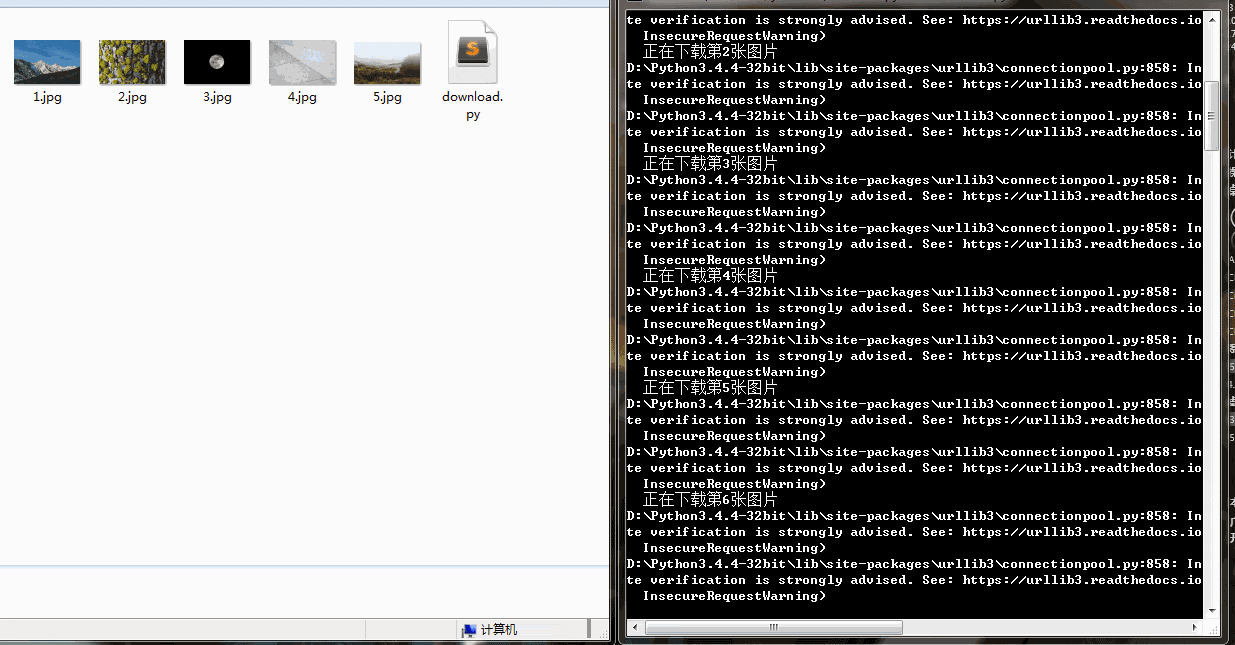
学会了爬取图片,简单的动态加载的网站也难不倒你了。赶快试试国内的一些图片网站吧!
3 视频下载
视频下载教程,请到这里查看:
https://cuijiahua.com/blog/2017/10/spider_tutorial_1.html
四 总结
- 本次Chat讲解的实战内容,均仅用于学习交流,请勿用于任何商业用途!
- 爬虫时效性低,同样的思路过了一个月,甚至一周可能无法使用,但是爬取思路都是如此,完全可以自行分析。
- 本次实战代码,均已上传我的Github,欢迎Follow、Star:https://github.com/Jack-Cherish/python-spider
- 如有问题,请留言。如有错误,还望指正,谢谢!
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/131532.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
