大家好,又见面了,我是你们的朋友全栈君。
目录
1.简介
变异系数法(Coefficient of variation method)又称”标准差率”(标准差与平均数的比值)是直接利用各项指标所包含的信息,通过计算得到指标的权重。是一种客观赋权的方法。此方法的基本做法是:在评价指标体系中,指标取值差异越大的指标,也就是越难以实现的指标,这样的指标更能反映被评价单位的差距。例如,在评价各个国家的经济发展状况时,选择人均国民生产总值(人均GNP)作为评价的标准指标之一,是因为人均GNP不仅能反映各个国家的经济发展水平,还能反映一个国家的现代化程度。如果各个国家的人均GNP没有多大的差别,则这个指标用来衡量现代化程度、经济发展水平就失去了意义。
2.算法原理
2.1 指标正向化
和熵权法的指标正向化类似,正向指标越大越好,负向指标越小越好。把指标都转化成正向指标处理。此篇采用新的正向化形式,采用上一篇建模算法熵权法的处理形式也可,基本思想不变就行。这个数据集有正向指标(越大越优型指标)和负向指标(越小越优型指标)两种。
设有m个待评对象,n个评价指标,可以构成数据矩阵X=(xij)m*n,设数据矩阵内元素,经过指标正向化处理过后的元素为xij’
负向指标:并网点电压偏差越限次数D、有功控制能力F、功率因数越限G属于此类指标
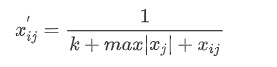

正向指标:其余所有指标属于此类,可以不用处理
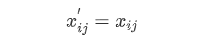
2.2 数据标准化
每个指标的数量级不一样,需要把它们化到同一个范围内比较。上一篇建模算法用到了最大最小值标准化方法。此篇可以用一个新的标准化方法,处理如下:
设标准化后的数据矩阵元素为rij,由上可得指标正向化后数据矩阵元素为xij’
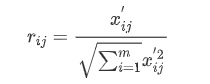
2.3 计算变异系数
处理过后可以构成数据矩阵R=(rij)m*n
- 计算指标的均值:
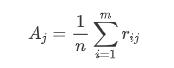
- 计算指标的标准差:
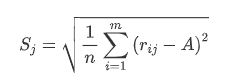
- 计算变异系数:
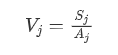
2.4 计算权重以及得分
- 权重为:
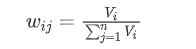
- 得分为:
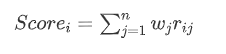
3.实例分析
| 风场名 | 风场1 | 风场2 | 风场3 |
| A(高频率穿越能力) | 0.743 | 0.7567 | 0.8104 |
| B(低频率穿越能力) | 0.8267 | 0.8033 | 0.7667 |
| C(低压穿越能力) | 0.8324 | 0.8736 | 0.8539 |
| D(并网点电压偏差越限次数 ) | 12 | 10 | 16 |
| E(SVC/SVG响应性能指标) | 0.8637 | 0.8538 | 0.9038 |
| F(有功控制能力) | 0.0743 | 0.0665 | 0.0881 |
| G(功率因素越限) | 0.0409 | 0.0716 | 0.0657 |
3.1 读取数据
读取表中全部数据
#导入数据
data=pd.read_excel('D:\桌面\变异系数.xlsx')
print(data)返回:
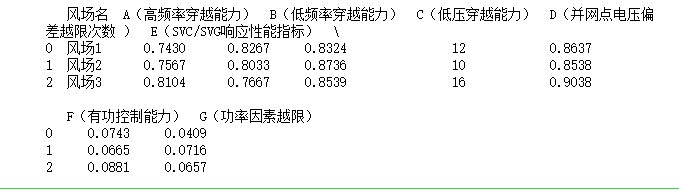
只读取表中数值
label_need=data.keys()[1:]
data1=data[label_need].values
print(data1)返回:

3.2 指标正向化
#数据正向化处理
data2=data1
index=[3,5,6] #越小越优指标位置,注意python是从0开始计数,对应位置也要相应减1
k=0.1
for i in range(0,len(index)):
data2[:,index[i]]=1/(k+max(abs(data1[:,index[i]]))+data1[:,index[i]])
print(data2)返回:

3.3 查看行数和列数
#行数和列数
[m,n]=data1.shape
print(m,n)返回:

3.4 数据标准化
#数据标准化
data3 = data2
for j in range(0,n):
data3[:,j]=data2[:,j]/np.sqrt(sum(np.square(data2[:,j])))
print(data3)返回:

3.5 计算变异系数
#计算变异系数
A=np.average(data3, axis=0) #计算均值
S=np.std(data3, axis=0) #计算标准差
V=S/A #计算变异系数
print('变异系数:',V)返回:
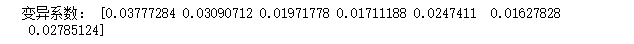
3.6 计算权重
# 计算权重
w=V/sum(V)
print('权重:',w)返回:
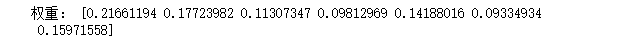
3.7 计算得分
#计算得分
s=np.dot(data3,w)
Score=100*s/max(s)
for i in range(0,len(Score)):
print(f"第{i+1}个风场百分制得分为:{Score[i]}")返回:
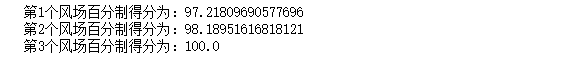
完整代码
#导入库
import pandas as pd
import numpy as np
#导入数据
data=pd.read_excel('D:\桌面\变异系数.xlsx')
# print(data)
label_need=data.keys()[1:]
data1=data[label_need].values
# print(data1)
#数据正向化处理
data2=data1
index=[3,5,6] #越小越优指标位置,注意python是从0开始计数,对应位置也要相应减1
k=0.1
for i in range(0,len(index)):
data2[:,index[i]]=1/(k+max(abs(data1[:,index[i]]))+data1[:,index[i]])
# print(data2)
#行数和列数
[m,n]=data1.shape
# print(m,n)
#数据标准化
data3 = data2
for j in range(0,n):
data3[:,j]=data2[:,j]/np.sqrt(sum(np.square(data2[:,j])))
# print(data3)
#计算变异系数
A=np.average(data3, axis=0) #计算均值
S=np.std(data3, axis=0) #计算标准差
V=S/A #计算变异系数
# print('变异系数:',V)
# 计算权重
w=V/sum(V)
# print('权重:',w)
#计算得分
s=np.dot(data3,w)
Score=100*s/max(s)
for i in range(0,len(Score)):
print(f"第{i+1}个风场百分制得分为:{Score[i]}")发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/131487.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
