大家好,又见面了,我是你们的朋友全栈君。
代价函数是学习模型优化时的目标函数或者准则,通过最小化代价函数来优化模型。到目前为止,接触了一些机器学习算法,但是他们使用的代价函数不一定是一样的,由于,在现实的使用中,通常代价函数都需要自己来确定,所以,这里总结一下,代价函数都有哪些形式,尽量揣测一下,这样使用的原因。
1. 均方差代价函数

这个是Andrew ng的机器学习课程里面看到的损失函数,在线性回归模型里面提出来的。表示模型所预测(假设)的输出,是真实的输出,即label。
个人猜测,均方差应该是
由于对给定的数据集来说,n是确定的值,因此,可以等同于式(1)。
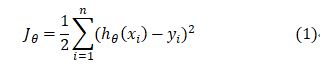
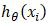
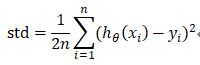
这个形式的代价函数计算Jacobian矩阵如下:
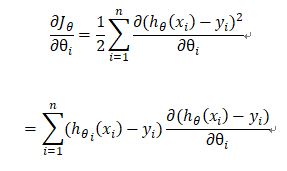
2. 对数损失函数
对数似然作为代价函数是在RNN中看到的,公式如下:
表示真实目标在数据集中的条件概率的负对数。其意义在于,在很多预测目标概率的模型中,将最大概率对应的类型作为输出类型,因此,真实目标的预测概率越高,分类越准确,学习的目标是真实目标的预测概率最大化。而概率是小于1的,其对数值小于0,且对数是单调递增的,因此,当负对数最小化,就等同于对数最大化,概率最大化。
逻辑回归中的代价函数实际上就是对数似然的特殊表示的方式:
二项逻辑回归的输入是预测目标为1的概率,的值为1或0.因此,目标为0的概率为,当真实的目标是1时,等式右边第二项为0,当真是目标为0时,等式右边第一项为0,因此,对于单个样本,L就是负对数似然。
同理,对于softmax回归的概率函数为
未添加权重惩罚项的代价函数为
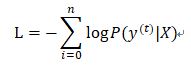
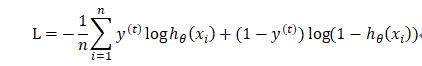
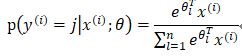
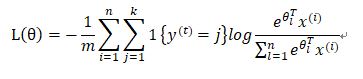
3.交叉熵
交叉熵在神经网络中基本都用交叉熵作为代价函数。
这和逻辑回归的代价函数很像,y作为真实的目标(label),不一定是二值的,且a不是预测目标的概率,而是神经网络的输出,
它的原理还不是很明白,据说在神经网络中用交叉熵而不用均方差代价函数的原因是早期的神经元的激活函数是sigmoid函数,而此函数在大部分取值范围的导数都很小,这样使得参数的迭代很慢。
而交叉熵的产生过程网友是这样推导的:
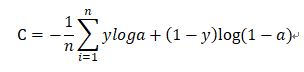

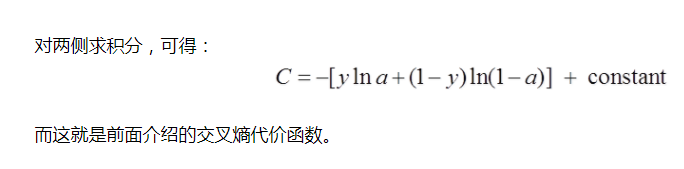
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/131300.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
