大家好,又见面了,我是你们的朋友全栈君。
使用pandas之前要导入包:
import numpy as np
import pandas as pd
import random #其中有用到random函数,所以导入
一、dataframe创建
pandas.DataFrame(data=None, index=None, columns=None, dtype=None, copy=False)
data:numpy ndarray(结构化或同类),dict或DataFrame,Dict可以包含Series,数组,常量或类似列表的对象
index:dataframe的索引,如果没有自定义,则默认为RangeIndex(0,1,2,…,n)
columns:dataframe的列标签,如果没有自定义,则默认为RangeIndex(0,1,2,…,n)
dtype:默认None,要强制的数据类型。 只允许一个dtype
copy:boolean,默认为False
(1)利用randn函数用于创建随机数来快速生成一个dataframe,可以将下句这一部分np.random.randn(8,5)作为参数data,其他默认,可以看到索引和列名都为(0,1,2,,,n),可以看出dataframe最不能缺少的为data
df = pd.DataFrame(np.random.randn(8,5))
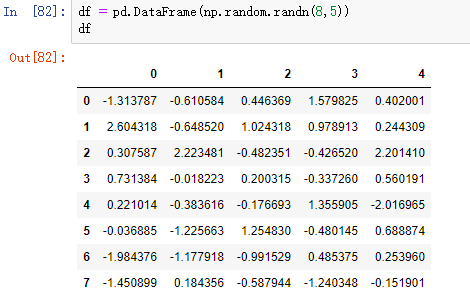
(2)用字典dict来生成一个dataframe
data = {'BoolCol': [1, 2, 3, 3, 4],
'attr': [22, 33, 22, 44, 66],
'BoolC': [1, 2, 3, 3, 4],
'att': [22, 33, 22, 44, 66],
'Bool': [1, 2, 3, 3, 4]
}
df = pd.DataFrame(data)
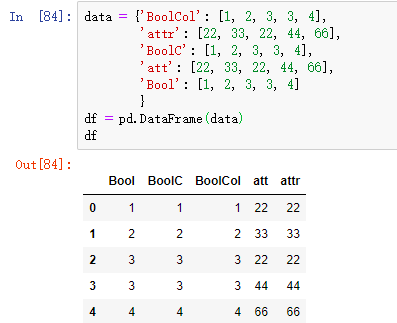
(2).1自定义索引的dataframe
data = {'BoolCol': [1, 2, 3, 3, 4],
'attr': [22, 33, 22, 44, 66],
'BoolC': [1, 2, 3, 3, 4],
'att': [22, 33, 22, 44, 66],
'Bool': [1, 2, 3, 3, 4]
}
df = pd.DataFrame(data,index=[10,20,30,40,50])
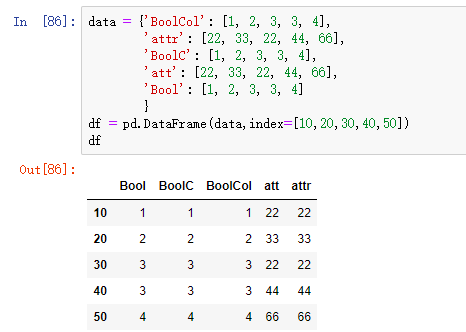
或者这样自定义索引
data = {'BoolCol': [1, 2, 3, 3, 4],
'attr': [22, 33, 22, 44, 66],
'BoolC': [1, 2, 3, 3, 4],
'att': [22, 33, 22, 44, 66],
'Bool': [1, 2, 3, 3, 4]
}
index = pd.Index(data=[10,20,30,40,50],name="self_index")
df = pd.DataFrame(data,index=index)
(3)可以看出像列名‘att’等对应的都是一个list的形式,为例填充这些列名对应的值,首先要把值的形式定义好,形成list
#随机生成3000个test号
#random.sample(range(0,10),6)从0-9这十位数中随机选出6位
test_list=[]
for i in range(3000):
test_list.append("123456"+"".join(str(s) for s in random.sample(range(0,10),6)))
#生成3000个1-200的随机浮点数,且保留两位小数
test_list2 = [round(random.uniform(1,200),2) for _ in range(3000)]
data = {
'date':pd.date_range("2000",freq= 'Y',periods=16).year,
'aa':test_list,
'test2':test_list2,
'label':[random.randint(0,1) for _ in range(3000)]
}
df = pd.DataFrame(data = data)二、dataframe插入列/多列
添加一列数据,,把dataframe如df1中的一列或若干列加入另一个dataframe,如df2
思路:先把数据按列分割,然后再把分出去的列重新插入
df1 = pd.read_csv(‘example.csv’)
(1)首先把df1中的要加入df2的一列的值读取出来,假如是’date’这一列
date = df1.pop(‘date’)
(2)将这一列插入到指定位置,假如插入到第一列
df2.insert(0,’date’,date)
(3)默认插入到最后一列
df2[‘date’] = date
2.2插入多列
假如dataframe1.shape=(5,4),dataframe2.shape=(5,6),运行代码:dataframe3=pd.concat([dataframe1,dataframe2], axis=1),则dataframe3.shape=(5,10)。关键点是axis=1,指明是列的拼接
三、dataframe插入行
插入行数据,前提是要插入的这一行的值的个数能与dataframe中的列数对应且列名相同,思路:先切割,再拼接。
假如要插入的dataframe如df3有5列,分别为[‘date’,’spring’,’summer’,’autumn’,’winter’],
(1)插入空白一行
方法一:利用append方法将它们拼接起来,注意参数中的ignore_index=True,如果不把这个参数设为True,新排的数据块索引不会重新排列。
insertRow = pd.DataFrame([[0.,0.,0.,0.,0.]],columns = ['date','spring','summer','autumne','winter'])
above = df3.loc[:2]
below = df3.loc[3:]
newData = above.append(insertRow,ignore_index=True).append(below,ignore_index=True) 方法二:用.concat()的方法来进行拼接,注意ignore_index=True
newData2 = pd.concat([above,insertRow,below],ignore_index = True)(2)假设df4中的列数和df3相同,取df4的行插入df3中
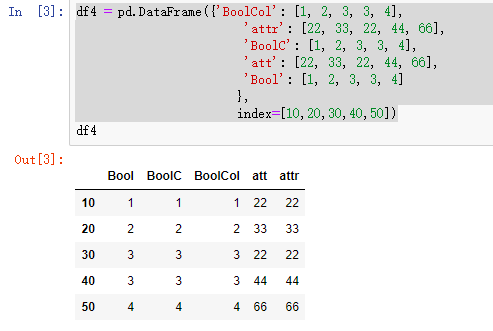
df4 = pd.DataFrame({'BoolCol': [1, 2, 3, 3, 4],
'attr': [22, 33, 22, 44, 66],
'BoolC': [1, 2, 3, 3, 4],
'att': [22, 33, 22, 44, 66],
'Bool': [1, 2, 3, 3, 4]
},
index=[10,20,30,40,50])
data = {
'date':pd.date_range("2000",freq= 'Y',periods=16).year,
'spring':[random.uniform(12,15) for _ in range(16)],
'summer':[random.uniform(16,18) for _ in range(16)],
'autumn':[random.uniform(12,19) for _ in range(16)],
'winter':[random.uniform(11,15) for _ in range(16)]
}
df3 = pd.DataFrame(data=data)
cols = ['date','spring','summer','autumn','winter']
#df3 = df3.ix[:,cols]
df3 = df3.loc[:,cols]
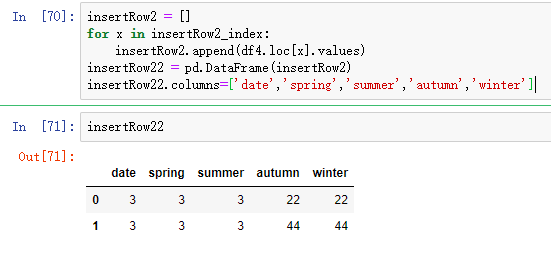
<1>.先获取取某一行的索引:
insertRow2_index = df4[df4.Bool == 3].index.tolist()

<2>.根据索引获取这两行的值:
insertRow2 = []
for x in insertRow2_index:
#注意.values的使用,只获取值,不带列名
insertRow2.append(df4.loc[x].values)
insertRow22 = pd.DataFrame(insertRow2)
#修改列名简单粗暴的方法,要改就全改,否则不成功
insertRow22.columns=['date','spring','summer','autumn','winter']
------------------------------------------------------------------------
#灵活修改列名方法,可以选择,默认列名为(1,2,,,n)
insertRow22.rename(columns={'1':'date', '2':'spring','3':'summer', '4':'autumn','5':'winter'}, inplace = True)根据索引取得这一行的值的不同用法
(1)#根据自定义的index取一行数据,即用于标签索引
1.1
#row = df4.loc[insertRow2_index]
1.2
row = df4.loc[insertRow2_index,:].values
-------------------------------------
(2)#根据系统默认的index取一行数据,即用于位置索引
row= df4.iloc[insertRow2_index,:].values
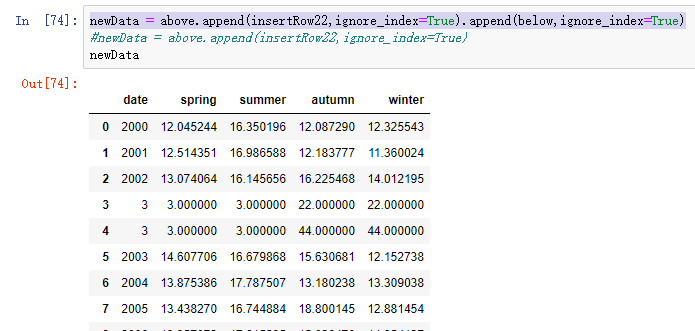
<3>.将insertRow22插入df3:
above = df3.loc[:2]
below = df3.loc[3:]
newData = above.append(insertRow22,ignore_index=True).append(below,ignore_index=True)
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/130125.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
