大家好,又见面了,我是你们的朋友全栈君。
论文: Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition.
来源:ECCV 2014
1. Motivation
- R-CNN模型存在很多缺点和可改进的地方,其中的两个缺点如下:
- CNN网络后面接的FC层需要固定的输入大小,导致CNN也需要固定大小的输入,即要求候选区域在进入CNN前需要crop或warp等操作,这种操作可能会造成信息损失或信息改变。
- 重复使用同一个CNN对2000个候选区域进行特征提取,这个过程会存在大量的重复计算,既造成计算冗余,又影响目标检测速度。
- 针对R-CNN存在的第一个缺点,SPPNet提出了著名的空间金字塔池化(Spatial Pyramid Pooling,SPP),实现了将任意大小的输入转化成固定大小的输出。有了SPP,一来我们无需对任意大小的候选区域进行其他操作,二来我们可以使用多尺度训练和多尺度测试。
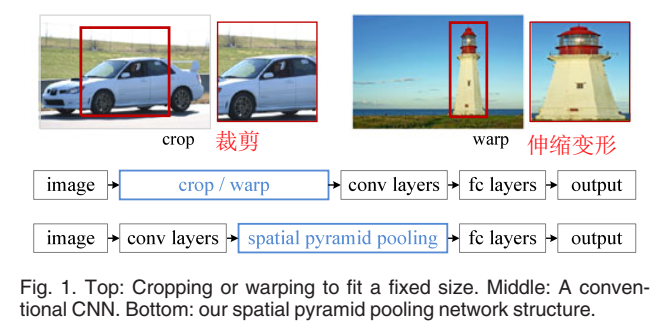

- 针对R-CNN存在的第二个缺点,SPPNet将候选区域的产生和利用CNN提取特征这两个步骤互换,即,仅使用一次CNN对整张图像进行特征提取,得到feature map,然后将候选区域映射到特征图上(候选区域是由Selective Search得到的相对于原图像的区域,将其映射到特征图上的某一区域),然后将基于特征图的候选区域输入SPP层,得到固定大小的特征,后续采用和R-CNN一样的分类和回归方法。
- 以上两处改进都会带来相对应的难点:
- SPP层是怎么实现接收任意大小的输入,输出固定向量的?
- SPPNet怎么实现将基于全图的候选区域映射成基于feature map的区域?
2. SPPnet
2.1 SPP层的原理
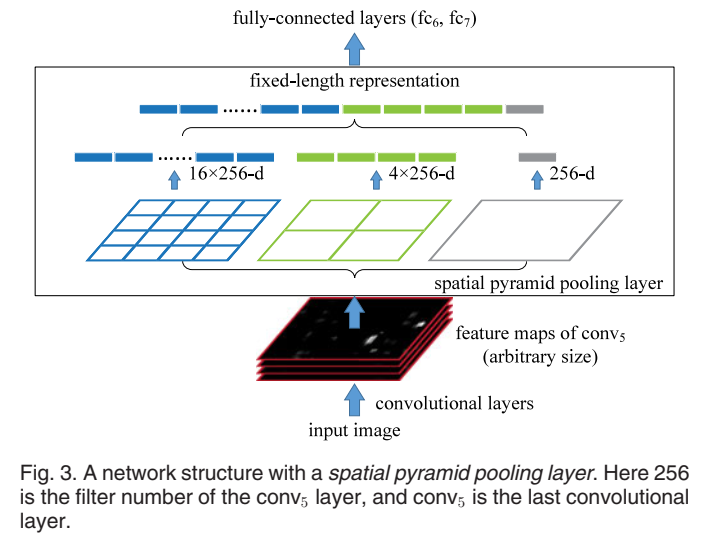
- 对于最后一层卷积层conv5(通道数为256),先把conv5分割成多个不同尺寸的网格(论文中的bin),比如 4 × 4 4\times4 4×4 、 2 × 2 2\times2 2×2、 1 × 1 1\times1 1×1,然后每个网格做全局max pooling,这样就得到了 16 × 256 16\times256 16×256、 4 × 256 4\times256 4×256、 1 × 256 1\times256 1×256的新特征图(这些图一起构成了特征金字塔),将这些特征图分别展平并连起来就形成了一个固定长度的特征向量,将这个向量输入到后面的全连接层。
- 其实严格来说,上面的说法是不太准确的,只是帮助你理解。实际上,从原论文可以看出,根本不存在网格划分这一步骤,网格的尺寸实际上是最后要得到的各个新的特征图的尺寸。在实际做pooling时,对于每一个不同大小的conv5,池化核的尺寸和池化步长都是经过特定计算而得到的。比如为了得到 16 × 256 16\times256 16×256这个特征图,对于输入为某一大小的conv5,就使用相对应的提前计算好的池化核的尺寸和池化步长,对于输入为另一大小的conv5,就使用另一套提前计算好的池化核的尺寸和池化步长。
如何计算池化核的尺寸和卷积步长呢?
- 对于标准的池化来说,假设输入特征尺寸为 a × a a\times a a×a,池化核大小为 f × f f\times f f×f,池化步长为 s s s,padding大小为 p p p,输出特征的尺寸为 n × n n\times n n×n,则有:
n = ⌊ a − f + 2 p s ⌋ + 1 n=\lfloor \frac{a-f+2p}{s} \rfloor+1 n=⌊sa−f+2p⌋+1在不考虑padding的情况下,为了得到尺寸为 n n n的输出特征, f f f和 s s s应满足:
f = ⌈ a n ⌉ , s = ⌊ a n ⌋ f=\lceil \frac{a}{n} \rceil , s=\lfloor \frac{a}{n} \rfloor f=⌈na⌉,s=⌊na⌋在计算 f f f时向上取整的目的是:保证整数,使池化核尺寸稍大于或等于网格bin的尺寸,否则会丢失信息。在计算 s s s时向下取整的目的是:保证整数,使卷积步长稍小于或等于池化核尺寸,否则信息会重叠。
举一个例子:假设 a = 13 a=13 a=13,则
- n = 3 n=3 n=3时, f = 5 f=5 f=5, s = 4 s=4 s=4;
- n = 2 n=2 n=2时, f = 7 f=7 f=7, s = 6 s=6 s=6;
- n = 1 n=1 n=1时, f = 13 f=13 f=13, s = 13 s=13 s=13;
SPP层的作用:
- 使得网络可以接受任意大小的输入(任意尺寸,任意宽高比),产生固定长度的特征向量;
- 聚合不同范围的空间信息,提供不同大小的感受野,不同感受野捕捉不同尺度的特征;
- 可以用于多尺度训练(论文指出多尺度训练可以提高准确率)
2.2 SPPnet的区域映射原理
- 为什么可以将基于原图的候选区域映射成基于feature map的区域?由于卷积具有平移不变性,不会改变空间位置信息。特征可视化的结果也表明,图像中的目标区域会在特征图的相应位置表现得比较活跃。
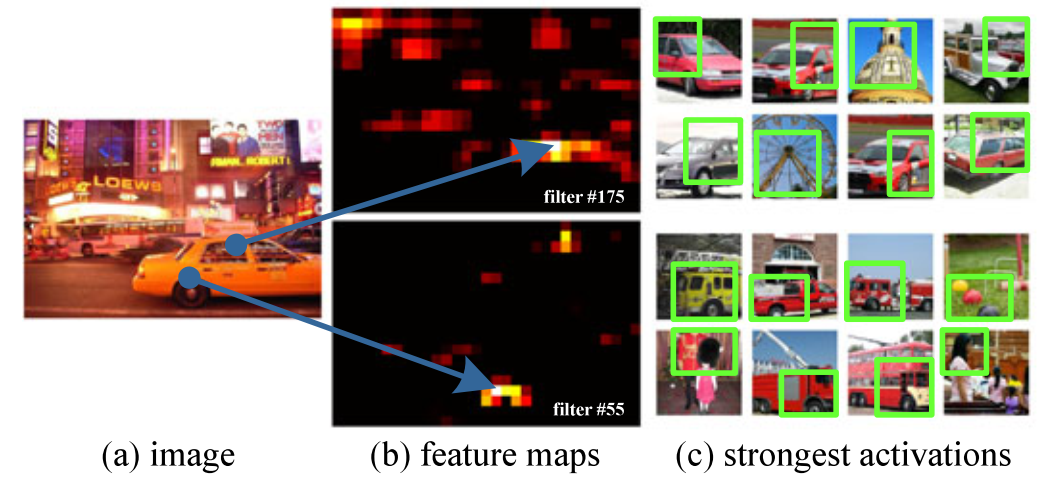
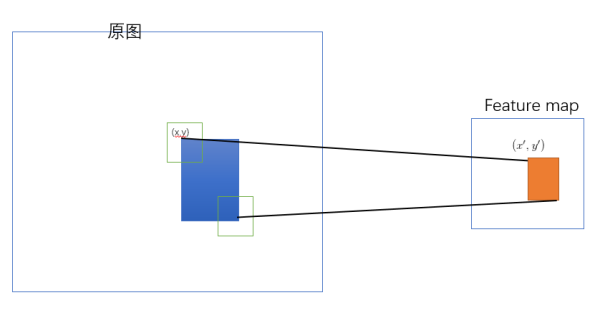
- 如何将基于原图的候选区域映射成基于feature map的区域。SPPNet 是把候选区域的左上角和右下角分别映射到feature map上的两个对应点。 有了feature map上的两对角点就确定了对应的feature map区域(下图中橙色)。
- 映射的准则为:映射后对应点在原图中的感受野的中心尽可能与原象接近。如,原图候选区域(蓝色)的左上角为 ( x , y ) (x,y) (x,y),其映射后在feature map上的坐标为 ( x ′ , y ′ ) (x’,y’) (x′,y′),那么应使得 ( x ′ , y ′ ) (x’,y’) (x′,y′) 在原图上的感受野(绿色框)的中心点与 ( x , y ) (x,y) (x,y)尽量接近。
- 由于卷积具有平移不变性, ( x , y ) (x,y) (x,y)和 ( x ′ , y ′ ) (x’,y’) (x′,y′)的关系式为:
( x , y ) = ( S x ′ , S y ′ ) (x,y)=(Sx’,Sy’) (x,y)=(Sx′,Sy′)其中,S是总下采样率。显然这种映射是一种等比例缩放映射。
论文中的最后做法为:
- 左上角取: x ′ = ⌊ x / S ⌋ + 1 x’=\lfloor x/S \rfloor+1 x′=⌊x/S⌋+1, y ′ = ⌊ y / S ⌋ + 1 y’=\lfloor y/S \rfloor+1 y′=⌊y/S⌋+1
- 右下角取: x ′ = ⌈ x / S ⌉ − 1 x’=\lceil x/S \rceil-1 x′=⌈x/S⌉−1, y ′ = ⌈ y / S ⌉ − 1 y’=\lceil y/S \rceil-1 y′=⌈y/S⌉−1
具体原理可参考这篇文章
3. 总结
| R-CNN | SPPNet |
|---|---|
| R-CNN是让每个候选区域经过crop/wrap等操作变换成固定大小的图像 | SPPNet把全图塞给CNN得到全图的feature map,让候选区域与feature map直接映射,得到候选区域的映射特征向量(这是映射来的,不需要过CNN) |
| 固定大小的图像塞给CNN,CNN输出固定大小的特征向量,这些特征向量将后续的分类和回归 | 映射过来的特征向量大小不固定,所以这些特征向量塞给SPP层,SPP层接收任何大小的输入,输出固定大小的特征向量,再塞给FC层 |
| 这里每个候选区域是需要单独过一下CNN,2000个候选区域过2000次CNN,耗费时间啊 | 经过映射+SPP转换,简化了计算,速度/精确度也上去了 |
-
SPPnet对R-CNN最大的改进就是特征提取步骤做了修改,其他模块仍然和R-CNN一样。特征提取不再需要每个候选区域都经过CNN,只需要将整张图片输入到CNN就可以了,ROI特征直接从特征图获取。和R-CNN相比,速度提高了百倍。
-
SPPnet缺点也很明显,CNN中的conv层在微调时是不能继续训练的。它仍然是R-CNN的框架,离我们需要的端到端的检测还差很多。既然端到端如此困难,那就先统一后面的几个模块吧,把SVM和边框回归去掉,由CNN直接得到类别和边框可不可以?于是就有了Fast R-CNN。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/130072.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
