大家好,又见面了,我是你们的朋友全栈君。
写在前面:博主是一只经过实战开发历练后投身培训事业的“小山猪”,昵称取自动画片《狮子王》中的“彭彭”,总是以乐观、积极的心态对待周边的事物。本人的技术路线从Java全栈工程师一路奔向大数据开发、数据挖掘领域,如今终有小成,愿将昔日所获与大家交流一二,希望对学习路上的你有所助益。同时,博主也想通过此次尝试打造一个完善的技术图书馆,任何与文章技术点有关的异常、错误、注意事项均会在末尾列出,欢迎大家通过各种方式提供素材。
- 对于文章中出现的任何错误请大家批评指出,一定及时修改。
- 有任何想要讨论和学习的问题可联系我:zhuyc@vip.163.com。
- 发布文章的风格因专栏而异,均自成体系,不足之处请大家指正。
如何用开源组件“攒”出一个大数据建模平台?
本文关键字:开源组件、大数据建模、项目架构、技术栈
一、食用须知
终于又可以名正言顺的发一篇聊天吹水。。。哦不是,是技术杂谈类的文章了,官方有活动?那必须跟上啊!咳~那么闲言少叙,下面是食用须知:
- 本文并非标题党,将介绍构建一个基于Web界面可操作的大数据建模平台相关的技术,以及各组件之间的关系。这是一个企业中真实存在的项目,并已实现商用,本人作为核心开发者之一,也是见证了整个平台的成长。
- 由于篇幅有限,不会涉及到特别具体的代码,但会尽量说明各组件与业务场景、数据处理流程的关系,其中也会穿插大数据领域相关的知识。
- 由于在培训领域深耕多年,如有废话和浅陋之处还请多多包涵。如果你还是一个学习者或者是一位刚刚踏入大数据领域的开发者,那么这篇文章很值得你收藏。
二、项目背景
项目的诞生可以追溯到三四年以前,在阿里巴巴的数加平台还在免费试用的时候,我们所做的大数据建模平台就已经实现商用并成单,并且曾经与华为、联通达成合作并进入联通沃创空间,先来一张图感受一下:

那么,此时应有路人甲站出来说一句:你们能实现商用完全是因为大厂还没有打造好能碾压你们的产品而已~对此我只能说:emmm,你。。。说的对!
但是其实一款产品是否能够实现商用有多方面的原因,大厂在各方面的优势十分明显,但是这并不代表其他产品没有机会,除了技术实力、团队规模、项目资金外,产品定位、市场环境等同样重要。
我在接手项目的时候已经是一个半成品了,所谓大数据建模平台其实是一个通用型的产品定位,更多的是功能的整合,可以说是标准的大数据开发,团队的主要构成都是开发者,当然也会包含数据分析师。
整个产品的核心功能就是为了实现:数据采集、数据源管理、数据清洗、统计分析、机器学习、数据可视化的完整流程,难点在于形成数据流,流程可控,易被管理。即使是在多年以后,我也依然觉得这个项目虽然没有涉及到复杂的场景和各种数据分析优化解决方案,但是对我的帮助绝对是最大的,它让我真实了解并操作了数据分析的每一个流程,也可以说打通了任督二脉,以后做的任何东西其实只不过是其中某个环节的优化或者是在某一特定场景下固定的数据流程,毕竟通用的东西都做出来了,某个固定指标的指标计算或是模型训练还会是问题吗?
以后每次谈起这段项目去面试,对方都会说:这个小伙子赶上了好项目。当然,项目本身是一方面,自己的总结归纳同时重要,借着当时临近毕业,也是逼着自己去彻底的吃透这个项目,不仅仅是技术方面,同时还有产品、设计等等方面,于是乎我把他变成了我的硕士论文,当然是获得了软件著作权之后(后来发现只是毕业论文的话好像并没有什么相关)。
背景介绍到此为止,下面正片开始,如果你确定这就是你想要的,请在阅读完成之后点赞、关注,略表支持,也欢迎收藏和在评论区说出你的想法。
三、遇见技术栈
为了方便场景介绍和相关技术的处理,将会按照不同的功能模块来进行划分,首先给出完整的项目架构图。
现在看这张图,架构不免有些陈旧,但是我想历史就应该被真实的还原,当时大前端相关技术才刚刚起爆,而且这个项目在我接手之前就已经被开发了一段时间了,所以这就是它当时应有的样子,也代表了那一段艰辛打拼的岁月。
回想起那个时候大数据方面的资料和落地的项目案例真的少之又少,大部分都是拿着PPT吹牛皮,大厂中的一些和大数据相关的核心技术又不是我等草民可以接触到的,所以也算是在摸索中前进。
1. 功能模块框架
由于文章篇幅有限,只会介绍大数据建模平台的部分功能,如果你对某些环节的处理技术感兴趣,可以扫描文章底部的二维码加入微信群(CSDN官方为内容合伙人提供的正经微信群),会定期面向粉丝直播互动。
在真实的项目中,由于是企业级应用,必然会存在部门、员工等一系列的权限管理功能,本文只是侧重介绍大数据处理相关流程,所以删去了部分不太重要的部分。
2. 数据源管理
对于数据源的管理部分,要分析的数据全部存储在HDFS上,同时由于主要是进行统计分析,所以处理的数据全部是结构化的离线数据:可以从关系数据库中拉取、也可以用户自行上传,在上传完成后都是以Hive表的形式存在,在平台中只记录数据源的名称、所属、以及对应的Hive表的信息,而且后续的数据流程不会对原始数据做修改,所以同一份数据有可能被应用在多个数据流程中,所以已存在的Hive表可以声明为多个数据源,其实就是建立了多个关联关系,在建模平台中展现给用户的都是一个一个的数据源节点。
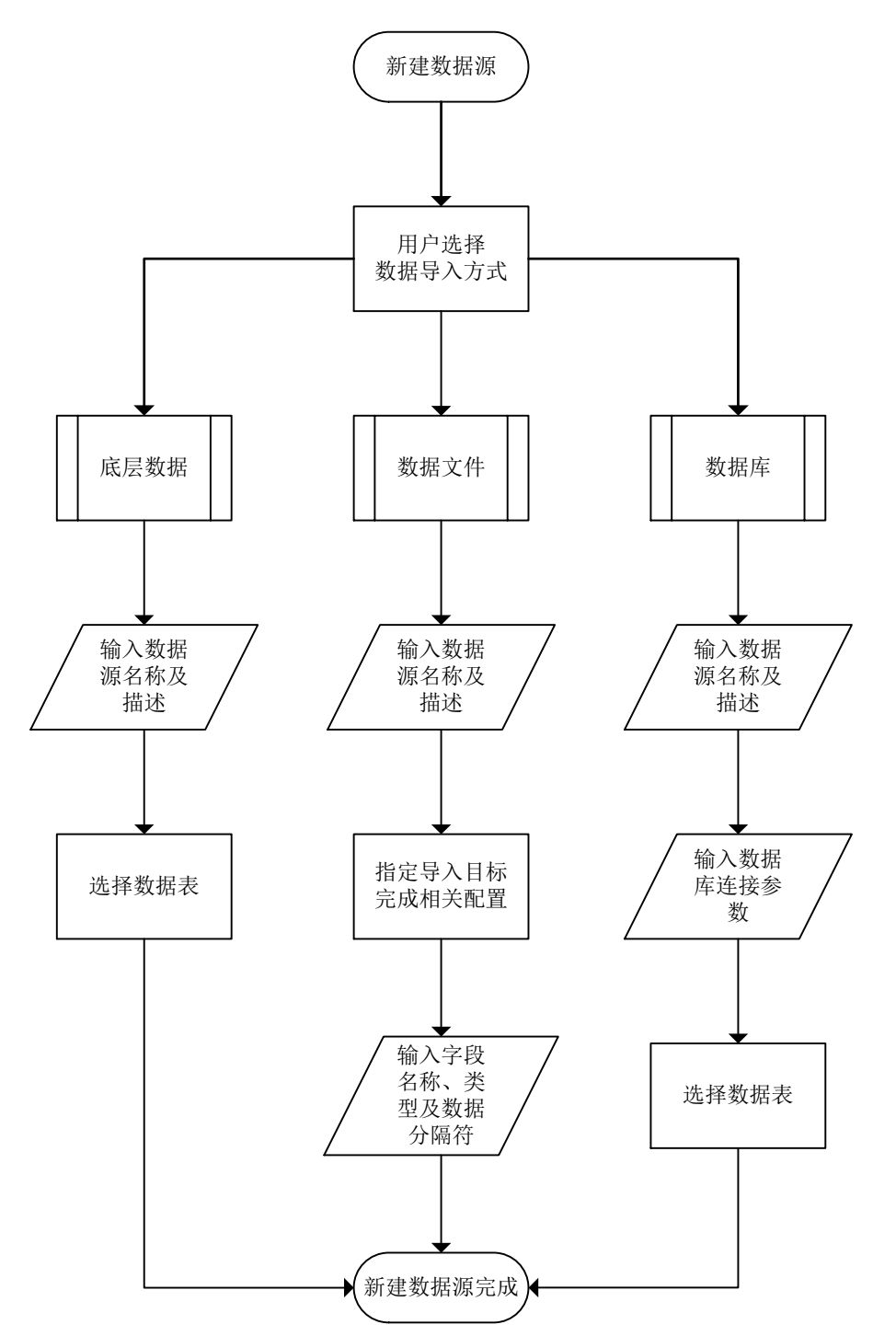
在进行关系型数据库拉取时使用了Sqoop组件,根据用户填写的数据库连接参数拼接为一个完整的命令,在服务器上执行。对于用户上传的数据文件,需要指定列名、列的类型、列与行的分隔符,根据信息自动建立对应结构的Hive表,这样导入数据以后才能够保证数据能够被正常识别。
3. 数据处理流程
对于建模平台,一个最基本的功能就是能够让用户自定义数据流程,可以应用在企业或者高校教学。我们采取的办法是将常见的一些统计分析功能和完善的机器学习库进行封装,变成一个一个的功能节点(主要通过Hive QL、Spark的Mllib,RHive实现),每一个节点都会有对应的配置参数,用户需要做的就是拖拽、组合,配置,运行。
对于前端的流程设计UI组件,我们选用的是GooFlow,数据流程可以进行保存和修改,体现在数据库中其实就是一个大JSON,里面记录了线的指向,节点的配置等等,再次打开流程的时候画布将得以还原,同时要保存整个流程各个节点的配置信息等等。
在项目流程开始以后,每一步都会生成一个结果表,作为下一步操作的数据源,最终的运行结果会生成一个结果表,可以直接以表格显示,下载结果数据,也可以拖拽一个可视化组件,配置后显示。
这里需要注意的是,GooFlow是一个需要授权使用的组件,大家也可以选择其他的组件来替代,目前网络上公开的只是试用版,要么就是带有挖矿程序的防盗版,所以大家想使用的话还是联系作者大大吧。
4. 其他功能模块
对于一些其他的功能,都是比较常规的Web应用开发。比如可视化展示的部分,就是基于对Echarts的option配置的封装,让用户可以通过界面的方式来配置图表的效果。要展示的数据从Hive当中查询,比较简单的方式就是HiveJDBC。
前后端的数据交互,使用的是基于JSP标签和Ajax结合的方式,比较古老了。持久层使用的是Hibernate,虽然我个人更偏爱MyBatis,但是凭我一己之力也不可能实现重构,踏踏实实干活儿就好。
因为是介绍技术栈的文章,我没有用过多的文字,觉得用架构图、流程图来展现会更加的清晰和直接。大家有想要继续讨论的内容,可以在评论区留言~
扫描下方二维码,加入官方粉丝微信群,可以与我直接交流,还有更多福利哦~

发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/130046.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
