大家好,又见面了,我是你们的朋友全栈君。
1. 集群
#192.168.1.128 [root local]# cd /home/gilbert/app/rar/ [root rar]# tar zxvf kafka_2.10-0.10.2.0.tgz [root rar]# mv kafka_2.10-0.10.2.0 /home/gilbert/app/kafka
配置文件路径:kafka/config/server.properties


修改配置文件
[root@master config]# more server.properties # Licensed to the Apache Software Foundation (ASF) under one or more # contributor license agreements. See the NOTICE file distributed with # this work for additional information regarding copyright ownership. # The ASF licenses this file to You under the Apache License, Version 2.0 # (the "License"); you may not use this file except in compliance with # the License. You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # see kafka.server.KafkaConfig for additional details and defaults ############################# Server Basics ############################# # The id of the broker. This must be set to a unique integer for each broker. ##每一个broker在集群中的唯一标示,要求是正数。在改变IP地址,不改变broker.id的话不会影响consumers broker.id=0 # Switch to enable topic deletion or not, default value is false ## 是否允许自动创建topic ,若是false,就需要通过命令创建topic delete.topic.enable=true ############################# Socket Server Settings ############################# # The address the socket server listens on. It will get the value returned from # java.net.InetAddress.getCanonicalHostName() if not configured. # FORMAT: # listeners = listener_name://host_name:port # EXAMPLE: # listeners = PLAINTEXT://your.host.name:9092 #listeners=PLAINTEXT://:9092 ##提供给客户端响应的端口 port=9092 host.name=192.168.1.128 # Hostname and port the broker will advertise to producers and consumers. If not set, # it uses the value for "listeners" if configured. Otherwise, it will use the value # returned from java.net.InetAddress.getCanonicalHostName(). #advertised.listeners=PLAINTEXT://your.host.name:9092 # Maps listener names to security protocols, the default is for them to be the same. See the config documentation for more details #listener.security.protocol.map=PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL # The number of threads handling network requests ## broker 处理消息的最大线程数,一般情况下不需要去修改 num.network.threads=3 # The number of threads doing disk I/O ## broker处理磁盘IO 的线程数 ,数值应该大于你的硬盘数 num.io.threads=8 # The send buffer (SO_SNDBUF) used by the socket server ## socket的发送缓冲区,socket的调优参数SO_SNDBUFF socket.send.buffer.bytes=102400 # The receive buffer (SO_RCVBUF) used by the socket server ## socket的接受缓冲区,socket的调优参数SO_RCVBUFF socket.receive.buffer.bytes=102400 # The maximum size of a request that the socket server will accept (protection against OOM) ## socket请求的最大数值,防止serverOOM,message.max.bytes必然要小于socket.request.max.bytes,会被topic创建时的指定参数覆盖 socket.request.max.bytes=104857600 ############################# Log Basics ############################# # A comma seperated list of directories under which to store log files ##kafka数据的存放地址,多个地址的话用逗号分割/data/kafka-logs-1,/data/kafka-logs-2 log.dirs=/tmp/kafka-logs # The default number of log partitions per topic. More partitions allow greater # parallelism for consumption, but this will also result in more files across # the brokers. ##每个topic的分区个数,若是在topic创建时候没有指定的话会被topic创建时的指定参数覆盖 num.partitions=1 # The number of threads per data directory to be used for log recovery at startup and flushing at shutdown. # This value is recommended to be increased for installations with data dirs located in RAID array. ##我们知道segment文件默认会被保留7天的时间,超时的话就 ##会被清理,那么清理这件事情就需要有一些线程来做。这里就是 ##用来设置恢复和清理data下数据的线程数量 num.recovery.threads.per.data.dir=1 ############################# Log Flush Policy ############################# # Messages are immediately written to the filesystem but by default we only fsync() to sync # the OS cache lazily. The following configurations control the flush of data to disk. # There are a few important trade-offs here: # 1. Durability: Unflushed data may be lost if you are not using replication. # 2. Latency: Very large flush intervals may lead to latency spikes when the flush does occur as there will be a lot of data to flush. # 3. Throughput: The flush is generally the most expensive operation, and a small flush interval may lead to exceessive seeks. # The settings below allow one to configure the flush policy to flush data after a period of time or # every N messages (or both). This can be done globally and overridden on a per-topic basis. # The number of messages to accept before forcing a flush of data to disk #log.flush.interval.messages=10000 # The maximum amount of time a message can sit in a log before we force a flush #log.flush.interval.ms=1000 ############################# Log Retention Policy ############################# # The following configurations control the disposal of log segments. The policy can # be set to delete segments after a period of time, or after a given size has accumulated. # A segment will be deleted whenever *either* of these criteria are met. Deletion always happens # from the end of the log. # The minimum age of a log file to be eligible for deletion due to age ##segment文件保留的最长时间,默认保留7天(168小时), ##超时将被删除,也就是说7天之前的数据将被清理掉。 log.retention.hours=168 # A size-based retention policy for logs. Segments are pruned from the log as long as the remaining # segments don't drop below log.retention.bytes. Functions independently of log.retention.hours. #log.retention.bytes=1073741824 # The maximum size of a log segment file. When this size is reached a new log segment will be created. ###日志文件中每个segment的大小,默认为1G log.segment.bytes=1073741824 # The interval at which log segments are checked to see if they can be deleted according # to the retention policies ##上面的参数设置了每一个segment文件的大小是1G,那么 ##就需要有一个东西去定期检查segment文件有没有达到1G, ##多长时间去检查一次,就需要设置一个周期性检查文件大小 ##的时间(单位是毫秒)。 log.retention.check.interval.ms=300000 ############################# Zookeeper ############################# # Zookeeper connection string (see zookeeper docs for details). # This is a comma separated host:port pairs, each corresponding to a zk # server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002". # You can also append an optional chroot string to the urls to specify the # root directory for all kafka znodes. #zookeeper.connect=localhost:2181 ##消费者集群通过连接Zookeeper来找到broker。 ##zookeeper连接服务器地址 zookeeper.connect=master:2181,worker1:2181,worker2:2181 # Timeout in ms for connecting to zookeeper zookeeper.connection.timeout.ms=6000
启动kafka
[root kafka]# ./bin/kafka-server-start.sh config/server.properties & [2018-06-25 02:31:21,931] INFO KafkaConfig values: advertised.host.name = null advertised.listeners = null advertised.port = null authorizer.class.name = auto.create.topics.enable = true auto.leader.rebalance.enable = true background.threads = 10 broker.id = 0 broker.id.generation.enable = true broker.rack = null compression.type = producer connections.max.idle.ms = 600000 controlled.shutdown.enable = true controlled.shutdown.max.retries = 3 controlled.shutdown.retry.backoff.ms = 5000 controller.socket.timeout.ms = 30000
创建topic
#创建topic topic名字为gilbert [root kafka]# ./bin/kafka-topics.sh --create --zookeeper master:2181,worker1:2181,worker2:2181 --replication-factor 3 --partitions 3 --topic gilbert Created topic "gilbert".
查看topic
[root kafka]# ./bin/kafka-topics.sh --describe --zookeeper master:2181,worker1:2181,worker2:2181 --topic gilbert Topic:gilbert PartitionCount:3 ReplicationFactor:3 Configs: Topic: gilbert Partition: 0 Leader: 2 Replicas: 2,0,1 Isr: 2,0,1 Topic: gilbert Partition: 1 Leader: 0 Replicas: 0,1,2 Isr: 0,1,2 Topic: gilbert Partition: 2 Leader: 1 Replicas: 1,2,0 Isr: 1,2,0 [root kafka]# ./bin/kafka-topics.sh --list --zookeeper master:2181,worker1:2181,worker2:2181 gilbert test
创建producer
./bin/kafka-console-producer.sh --broker-list master:9092 -topic gilbert
创建consumer,分别在3台服务器上执行创建消费者
#192.168.1.128服务器 [root kafka]# ./bin/kafka-console-consumer.sh --zookeeper master:2181,worker1:2181,worker2:2181 -topic gilbert --from-beginning Using the ConsoleConsumer with old consumer is deprecated and will be removed in a future major release. Consider using the new consumer by passing [bootstrap-server] instead of [zookeeper]. #192.168.1.129服务器 [root kafka_2.10-0.10.2.0]# ./bin/kafka-console-consumer.sh --zookeeper master:2181,worker1:2181,worker2:2181 -topic gilbert --from-beginning Using the ConsoleConsumer with old consumer is deprecated and will be removed in a future major release. Consider using the new consumer by passing [bootstrap-server] instead of [zookeeper]. #192.168.1.130服务器 [root kafka_2.10-0.10.2.0]# ./bin/kafka-console-consumer.sh --zookeeper master:2181,worker1:2181,worker2:2181 -topic gilbert --from-beginning Using the ConsoleConsumer with old consumer is deprecated and will be removed in a future major release. Consider using the new consumer by passing [bootstrap-server] instead of [zookeeper].
在#192.168.1.128服务器上生产者控制台输入:hello kafka进行测试
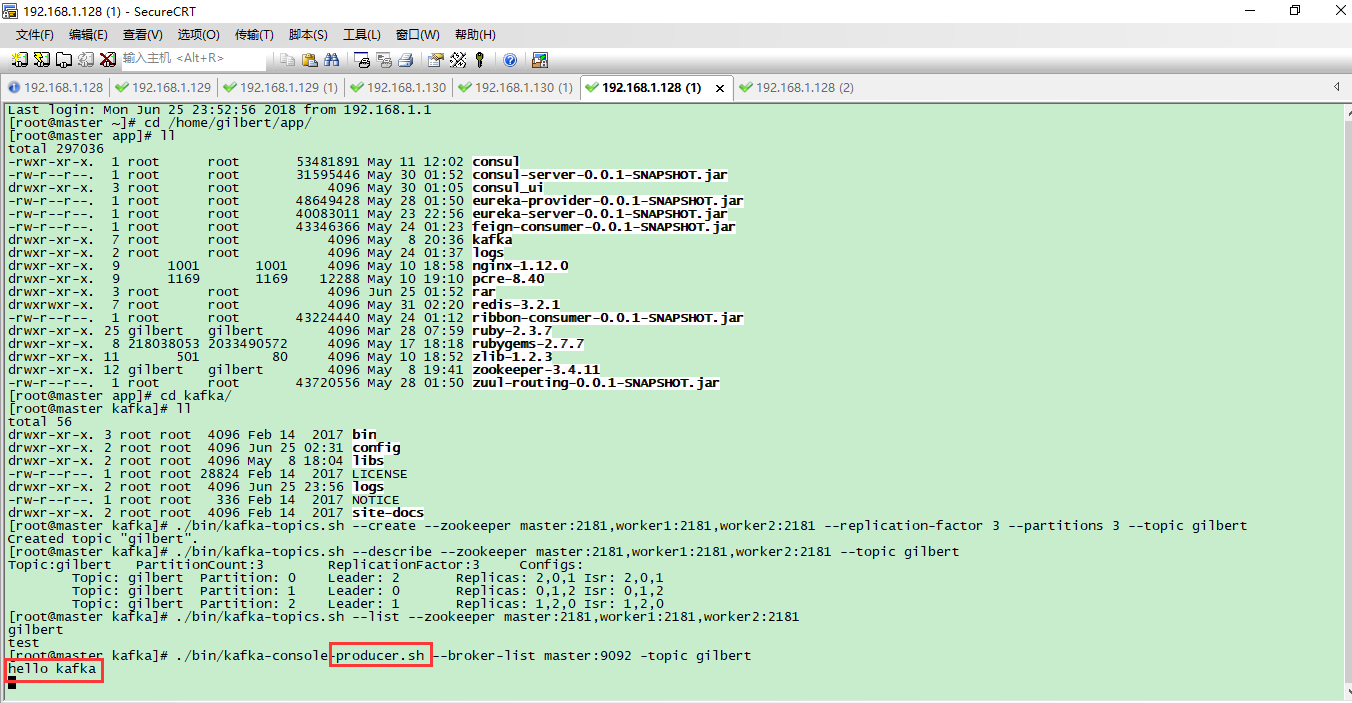
在3台服务器上的消费者都正常接收到消息
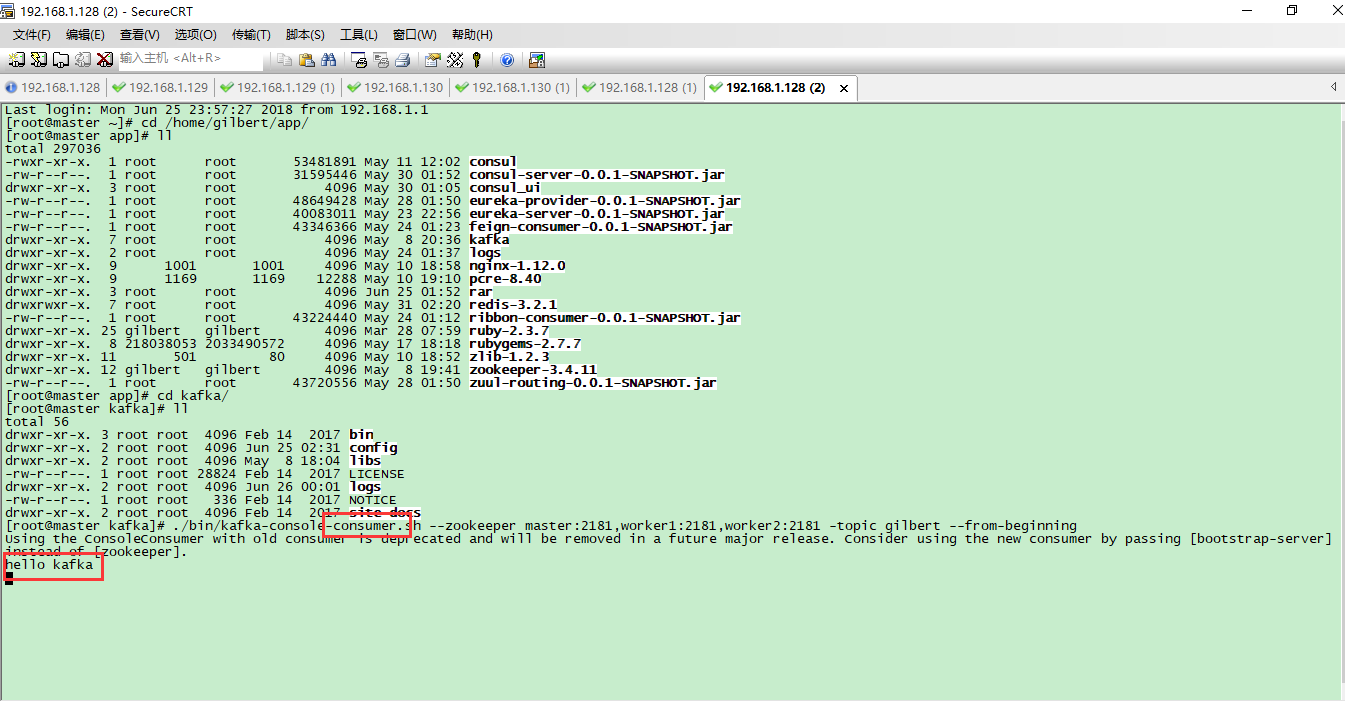
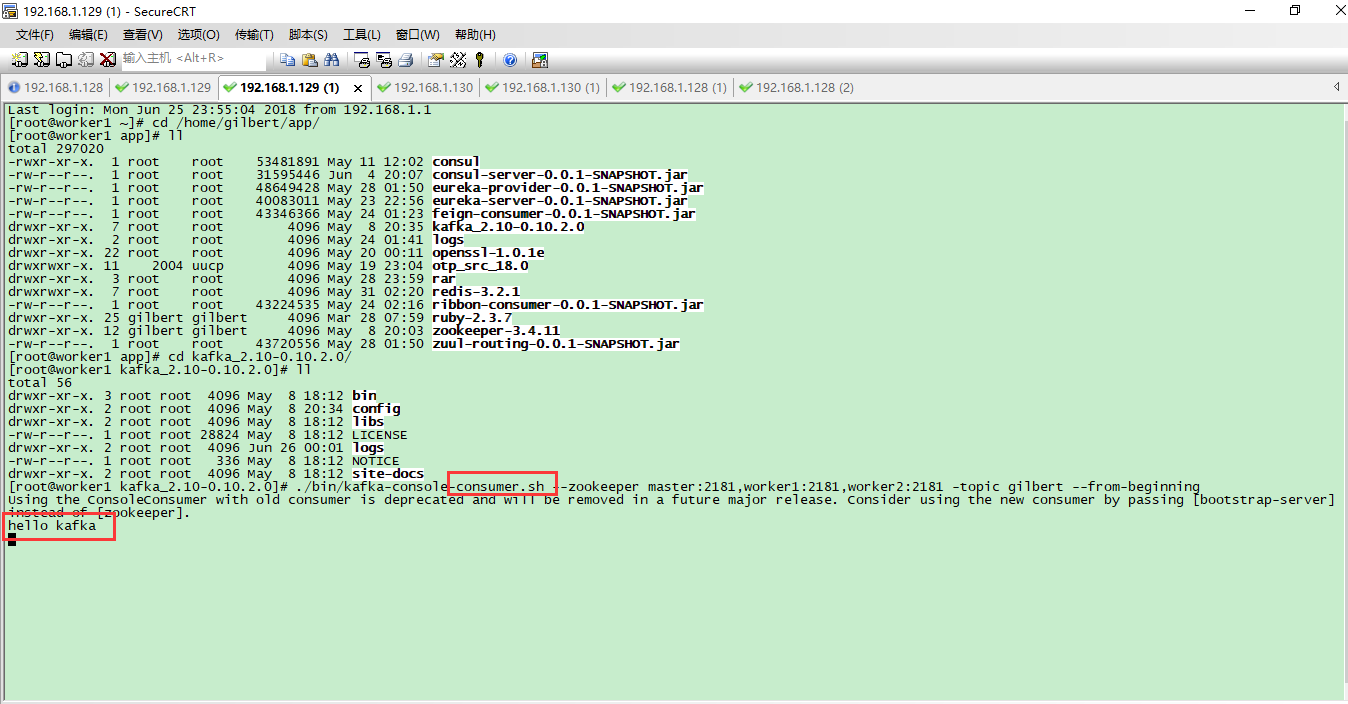
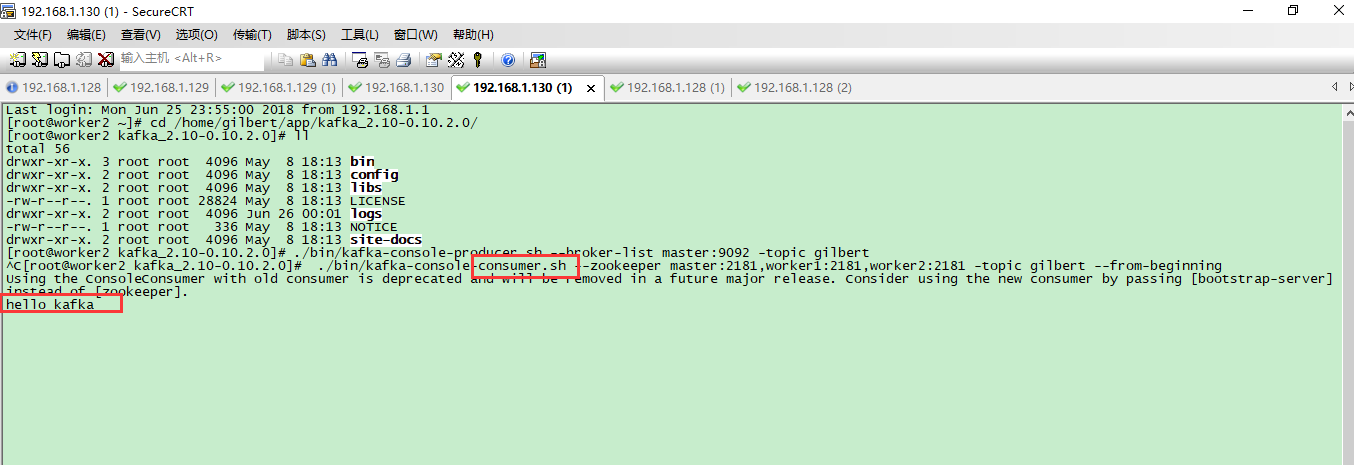
删除topic
[root kafka]# ./bin/kafka-topics.sh --delete --zookeeper master:2181,worker1:2181,worker2:2181 --topic test Topic test is marked for deletion. Note: This will have no impact if delete.topic.enable is not set to true
1.生产者kafka-producer
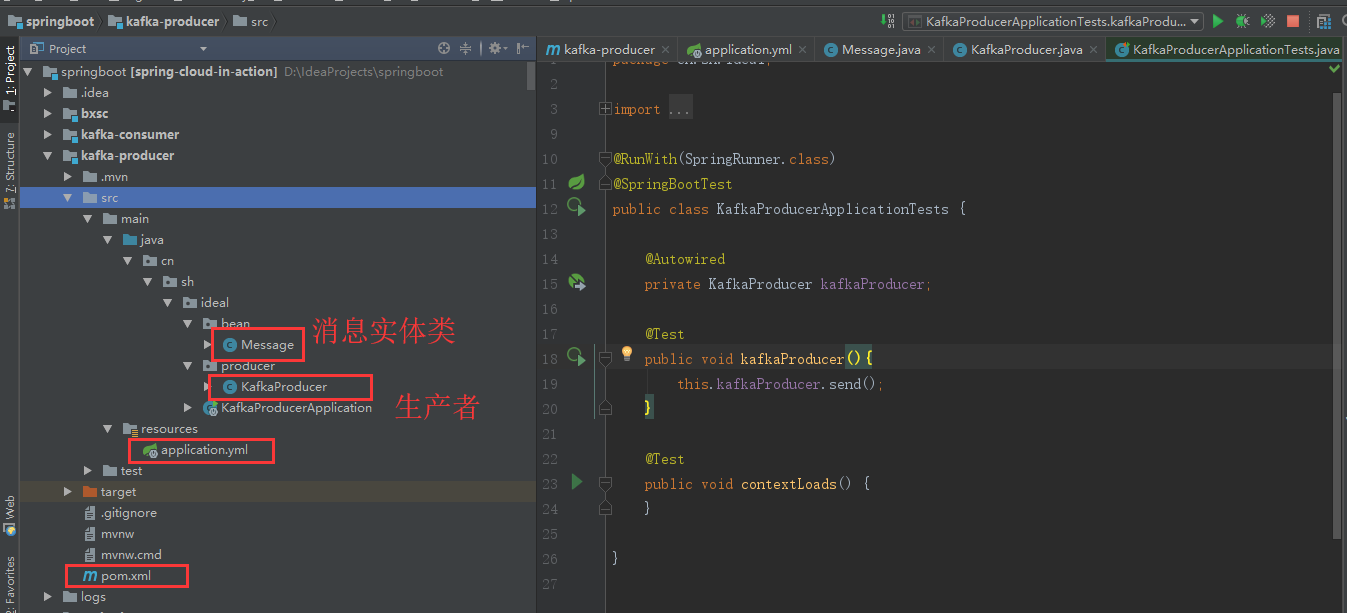
a) pom文件
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
b) yml配置文件,本例为kafka3节点集群
spring:
kafka:
bootstrap-servers: http://master:9092,http://worker1:9092,http://worker2:9092
producer:
retries: 0
batch-size: 16384
buffer-memory: 33554432
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
c) message消息实体类
public class Message { private Long id; //id private String msg; //消息 private Date sendTime; //时间戳 }
d) 生产者
public class KafkaProducer { private KafkaTemplate<String, String> kafkaTemplate; private Gson gson = new GsonBuilder().create(); //发送消息方法 public void send() { Message message = new Message(); message.setId(System.currentTimeMillis()); message.setMsg(UUID.randomUUID().toString()); message.setSendTime(new Date()); log.info("+++++++++++++++++++++ message = {}", gson.toJson(message)); //topic-ideal为主题 kafkaTemplate.send("topic-ideal", gson.toJson(message)); } }
e) 测试类,运行kafkaProducer方法即可
(SpringRunner.class) public class KafkaProducerApplicationTests { private KafkaProducer kafkaProducer; public void kafkaProducer(){ this.kafkaProducer.send(); } public void contextLoads() { } }
2. 消费者kafka-consumer
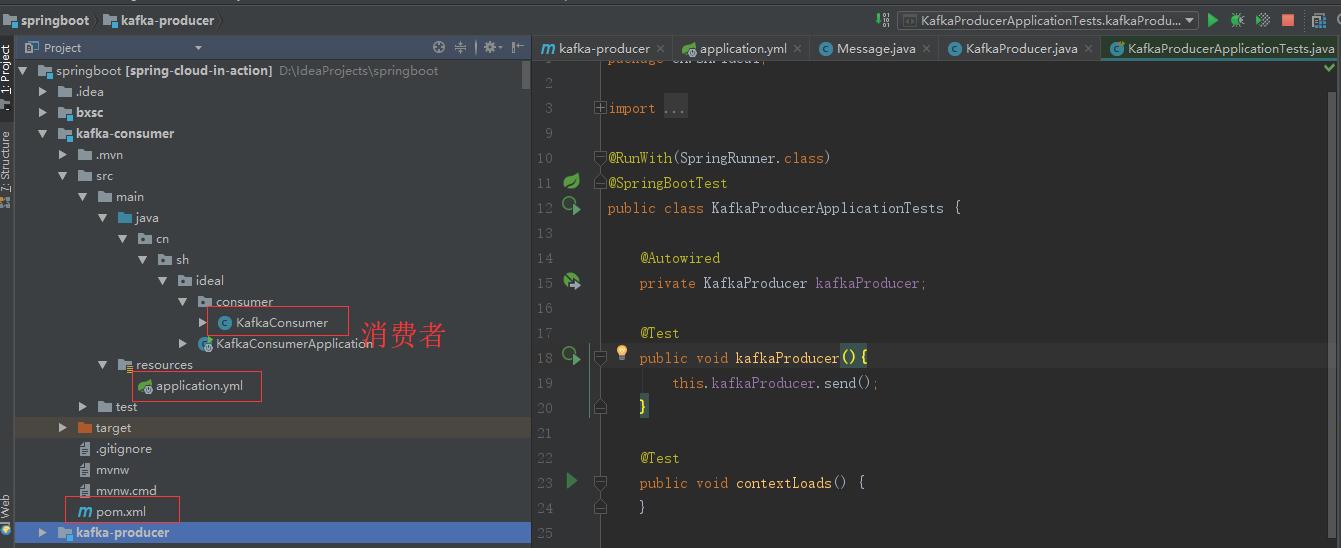
a) pom文件
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.8.2</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
b) yml配置文件
server:
port: 9999
spring:
kafka:
bootstrap-servers: http://master:9092,http://worker1:9092,http://worker2:9092
consumer:
group-id: ideal-consumer-group
auto-offset-reset: earliest
enable-auto-commit: true
auto-commit-interval: 20000
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
c) 消费者类
public class KafkaConsumer { (topics = { "topic-ideal"}) public void consumer(ConsumerRecord<?, ?> record){ Optional<?> kafkaMessage = Optional.ofNullable(record.value()); if (kafkaMessage.isPresent()) { Object message = kafkaMessage.get(); log.info("----------------- record =" + record); log.info("------------------ message =" + message); } } }
运行消费者kafka-consumer,再运行kafka-producer工程测试类KafkaProducerApplicationTests中kafkaProducer()方法,可以看到消费者后台正常接收消息
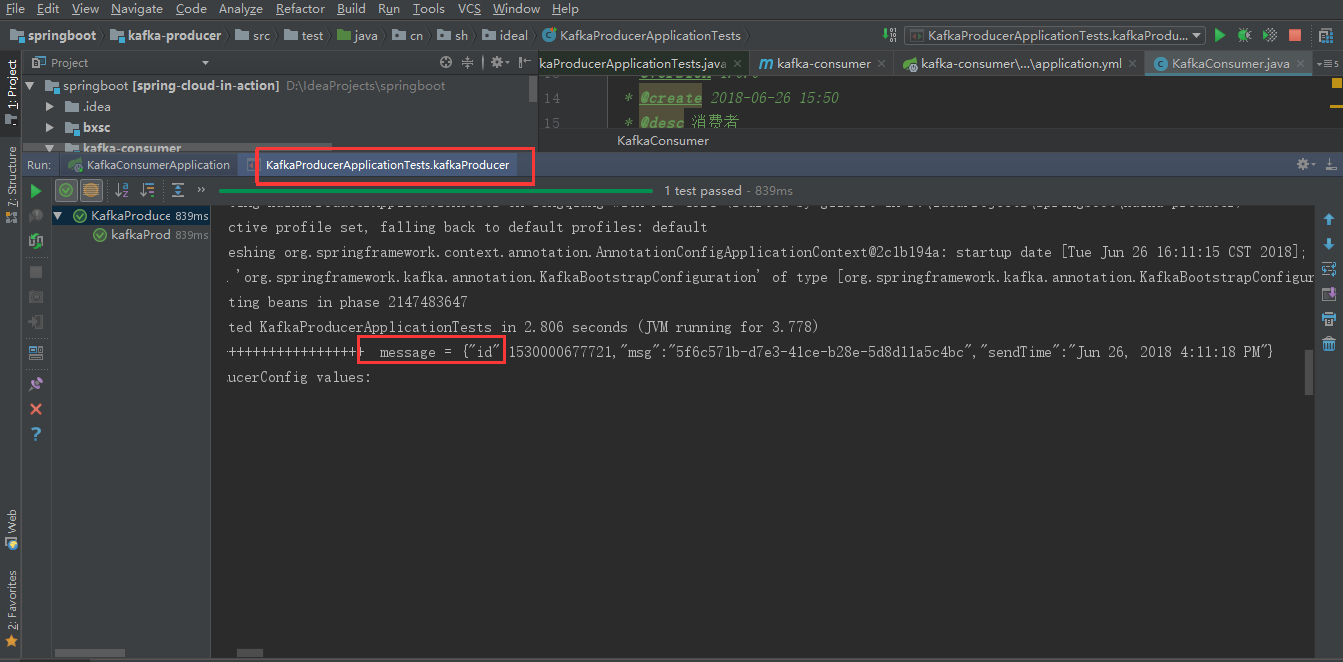
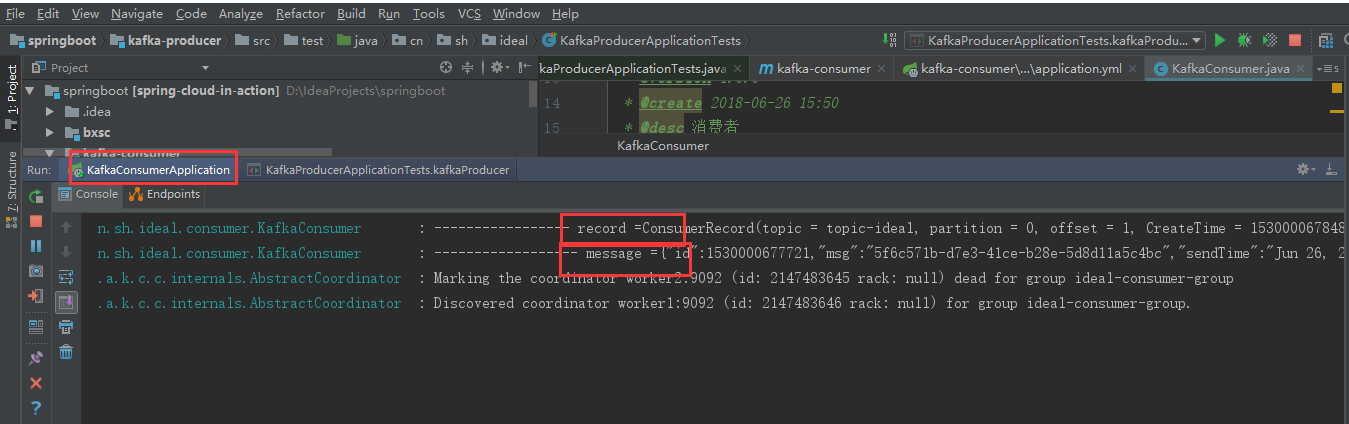
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/129939.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
