大家好,又见面了,我是你们的朋友全栈君。
目录
1-1-1 process_request – 正常请求调用
1-1-2 process_response – 正常返回调用
1-1-3 process_exception – 捕获错误调用
四、IPProxyPool – IP 池 Python 脚本
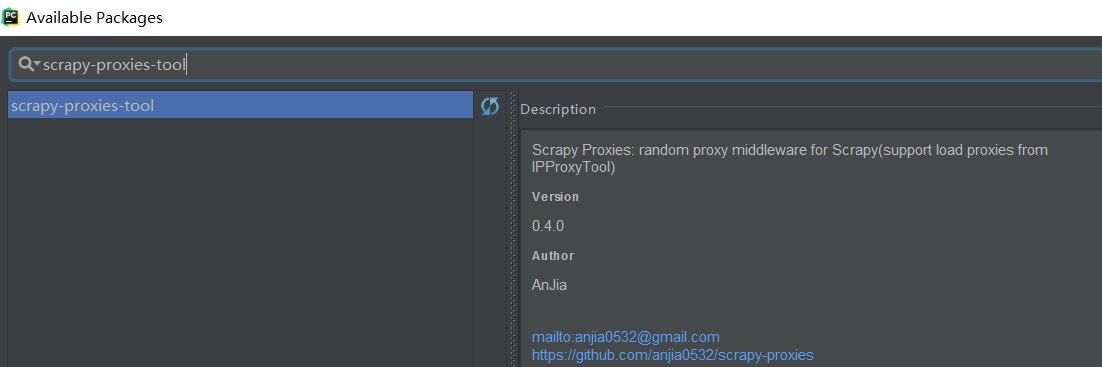
五、scrapy-proxies-tool – Scrapy 的 IP池 Python库
python爬虫scrapy之downloader_middleware设置proxy代理
一、中间件的使用
from scrapy import signals class MyscrapyDownloaderMiddleware(object): # Not all methods need to be defined. If a method is not defined, # scrapy acts as if the downloader middleware does not modify the # passed objects. @classmethod def from_crawler(cls, crawler): # This method is used by Scrapy to create your spiders. s = cls() crawler.signals.connect(s.spider_opened, signal=signals.spider_opened) return s def process_request(self, request, spider): # Called for each request that goes through the downloader # middleware. # Must either: # - return None: continue processing this request # - or return a Response object # - or return a Request object # - or raise IgnoreRequest: process_exception() methods of # installed downloader middleware will be called return None def process_response(self, request, response, spider): # Called with the response returned from the downloader. # Must either; # - return a Response object # - return a Request object # - or raise IgnoreRequest return response def process_exception(self, request, exception, spider): # Called when a download handler or a process_request() # (from other downloader middleware) raises an exception. # Must either: # - return None: continue processing this exception # - return a Response object: stops process_exception() chain # - return a Request object: stops process_exception() chain pass def spider_opened(self, spider): spider.logger.info('Spider opened: %s' % spider.name)1-1 具体方法详解
1-1-1 process_request – 正常请求调用
1-1-2 process_response – 正常返回调用
1-1-3 process_exception – 捕获错误调用




二、Proxy 相关官方中间件
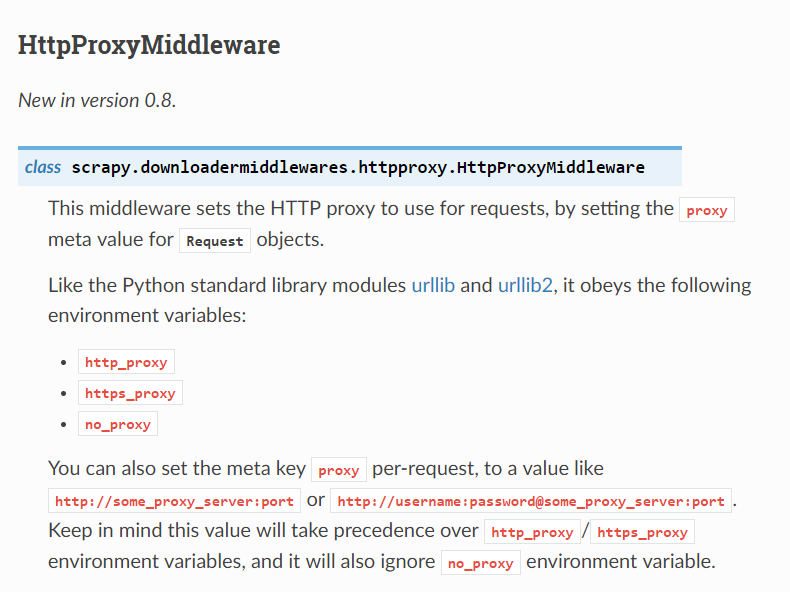
2-1 HttpProxyMiddleware
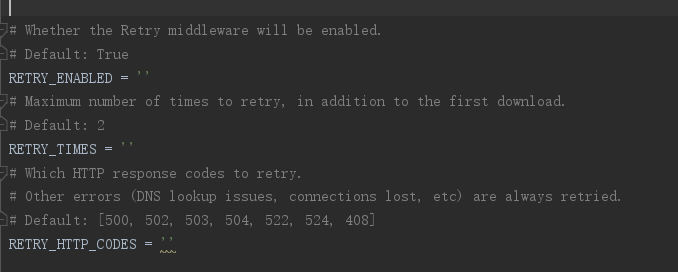
2-2 RetryMiddleware
注意!!不支持使用空来进行配置,只能使用 ‘1/0’和‘true/flase’进行配置
2-2-1 源码分析
import logging from twisted.internet import defer from twisted.internet.error import TimeoutError, DNSLookupError, \ ConnectionRefusedError, ConnectionDone, ConnectError, \ ConnectionLost, TCPTimedOutError from twisted.web.client import ResponseFailed from scrapy.exceptions import NotConfigured from scrapy.utils.response import response_status_message from scrapy.core.downloader.handlers.http11 import TunnelError from scrapy.utils.python import global_object_name logger = logging.getLogger(__name__) class RetryMiddleware(object): # IOError is raised by the HttpCompression middleware when trying to # decompress an empty response EXCEPTIONS_TO_RETRY = (defer.TimeoutError, TimeoutError, DNSLookupError, ConnectionRefusedError, ConnectionDone, ConnectError, ConnectionLost, TCPTimedOutError, ResponseFailed, IOError, TunnelError) def __init__(self, settings): if not settings.getbool('RETRY_ENABLED'): raise NotConfigured self.max_retry_times = settings.getint('RETRY_TIMES') self.retry_http_codes = set(int(x) for x in settings.getlist('RETRY_HTTP_CODES')) self.priority_adjust = settings.getint('RETRY_PRIORITY_ADJUST') @classmethod def from_crawler(cls, crawler): return cls(crawler.settings) def process_response(self, request, response, spider): if request.meta.get('dont_retry', False): return response if response.status in self.retry_http_codes: reason = response_status_message(response.status) return self._retry(request, reason, spider) or response return response # 捕获错误信息触发执行 def process_exception(self, request, exception, spider): # 如果错误属于捕获列表内的错误,并且,请求元信息内设置的配置为设置重启 - 处理错误请求 if isinstance(exception, self.EXCEPTIONS_TO_RETRY) \ and not request.meta.get('dont_retry', False): return self._retry(request, exception, spider) def _retry(self, request, reason, spider): # 重试次数获取 retries = request.meta.get('retry_times', 0) + 1 # 最多重试次数 retry_times = self.max_retry_times if 'max_retry_times' in request.meta: retry_times = request.meta['max_retry_times'] stats = spider.crawler.stats # 若重试次数未达到最多重试次数 if retries <= retry_times: logger.debug("Retrying %(request)s (failed %(retries)d times): %(reason)s", {'request': request, 'retries': retries, 'reason': reason}, extra={'spider': spider}) retryreq = request.copy() retryreq.meta['retry_times'] = retries retryreq.dont_filter = True retryreq.priority = request.priority + self.priority_adjust if isinstance(reason, Exception): reason = global_object_name(reason.__class__) stats.inc_value('retry/count') stats.inc_value('retry/reason_count/%s' % reason) # 返回request对象 (属于 process_exception 返回) return retryreq # 否则不进行重试 else: stats.inc_value('retry/max_reached') logger.debug("Gave up retrying %(request)s (failed %(retries)d times): %(reason)s", {'request': request, 'retries': retries, 'reason': reason}, extra={'spider': spider})



三、实现代理 IP池
3-1 代理 IP 设置
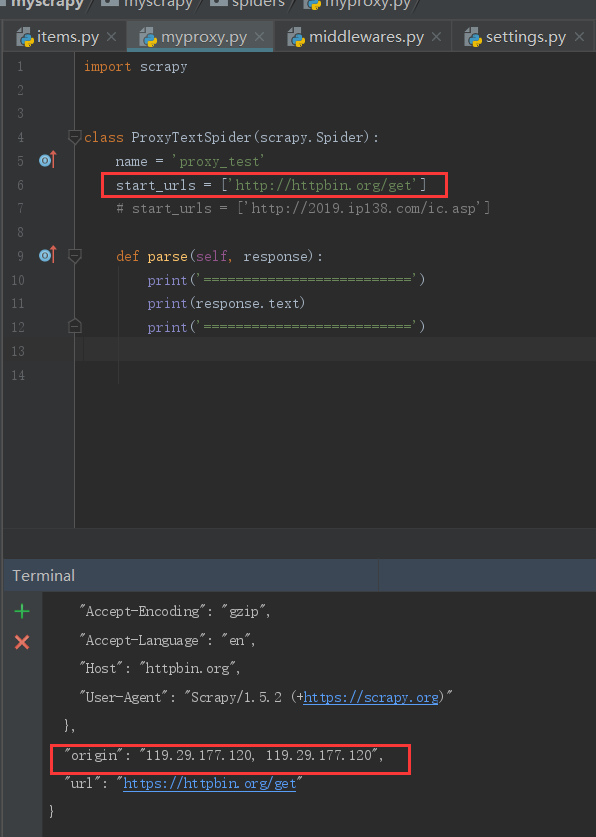
在 process_request 方法内,每次经过该中间件的该方法,就会自动包裹代理ip
验证代理是否有效
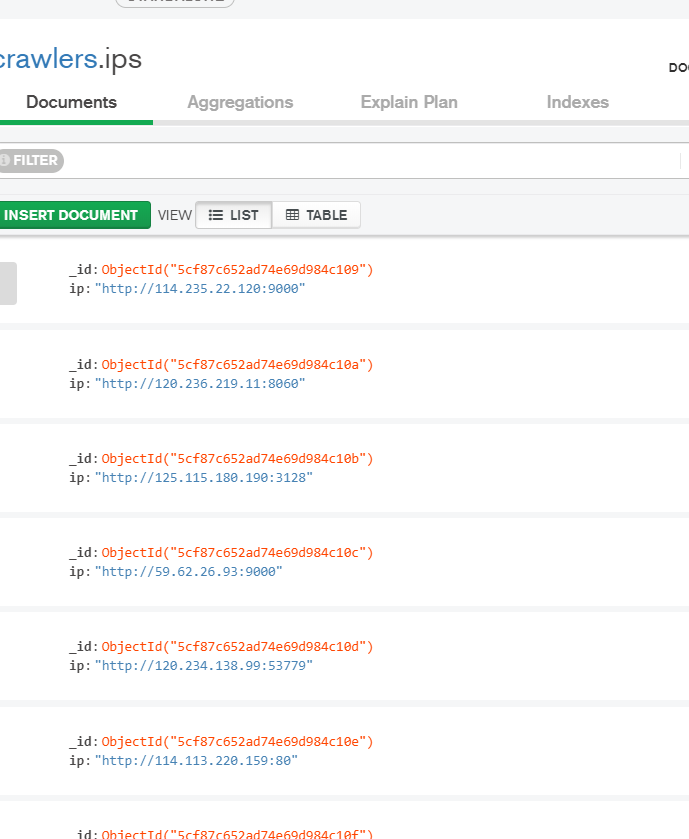
3-2 代理 ip 爬取 + mongodb 存储
https://www.kuaidaili.com/free/inha/1/ – 代理ip获取页
import scrapy from bs4 import BeautifulSoup from myscrapy.items import IpSpiderItem class IpSpider(scrapy.Spider): name = 'ipspider' # 替代start_urls def start_requests(self): # dont_filter=False 开启去重功能(爬过的url不再爬取),需要 setting 内的配置 # 根据爬取页规则,指定爬取页数 for page in range(1, 5): yield scrapy.Request('https://www.kuaidaili.com/free/inha/%s/' % page, self.parse, dont_filter=True, ) def parse(self, response): body = str(response.body, encoding='utf-8') ippool = BeautifulSoup(body, 'lxml') iptable = ippool.find('table', class_='table table-bordered table-striped') ip_trs = iptable.tbody.find_all('tr') for tr in ip_trs: ip = tr.find('td', attrs={'data-title': 'IP'}).text port = tr.find('td', attrs={'data-title': 'PORT'}).text print('http://%s:%s' % (ip, port)) item = IpSpiderItem() item['ip'] = 'http://%s:%s' % (ip, port) yield item
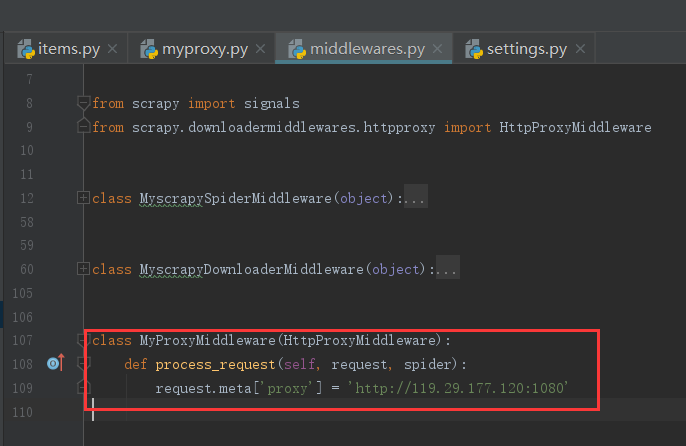
3-3 代理池的随机代理设置
import pymongo import random from scrapy.downloadermiddlewares.httpproxy import HttpProxyMiddleware class MyProxyMiddleware(HttpProxyMiddleware): def process_request(self, request, spider): conn = pymongo.MongoClient(spider.settings.get('MONGO_URI')) db = conn[spider.settings.get('MONGO_DATABASE')] collection = db['ips'] ip = random.choice([obj for obj in collection.find()]) request.meta['proxy'] = ip['ip']3-4 Rertry 更换代理并删除无效 ip
更换代理思路总结
由于,代理配置 process_request 方法内,所以每次请求都会是新的 ip 包裹,则使用 process_exception 或 process_response 方法,业务处理后(删除库中IP等),返回 request 对象,重新发送请求。(详情参考 1-1 方法返回值解释)
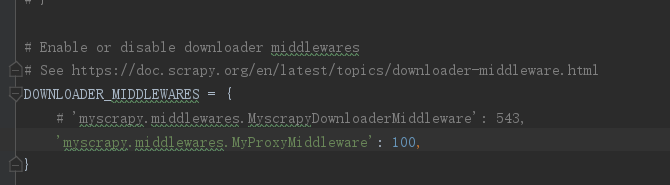
注意! 不要忘记在 settings 内开启 DOWNLOADER_MIDDLEWARES 配置
class MyProxyMiddleware(object): # 中间件权值小于默认543,优先原有的retry def mongo_conn(self, spider): conn = pymongo.MongoClient(spider.settings.get('MONGO_URI')) db = conn[spider.settings.get('MONGO_DATABASE')] collection = db['ips'] # ip = random.choice([obj for obj in collection.find()]) # print(ip['ip']) return collection # 每次访问页面都会通过该方法进行代理包裹 def process_request(self, request, spider): collection = self.mongo_conn(spider) ip = random.choice([obj for obj in collection.find()]) request.meta['proxy'] = ip['ip'] print('=========', request.meta['proxy']) # 非错误情况下的状态码处理 def process_response(self, request, response, spider): if response.status == 503: request.replace(url='http://2019.ip138.com/ic.asp') return request return response def process_exception(self, request, exception, spider): # 出现异常时(超时)使用代理 print("error retry ……") # 在库中删除无效ip collection = self.mongo_conn(spider) del_ip = {"ip": request.meta['proxy']} collection.delete_one(del_ip) # 返回request,重新发送请求 return request

四、IPProxyPool – IP 池 Python 脚本
五、scrapy-proxies-tool – Scrapy 的 IP池 Python库
Random proxy middleware for Scrapy
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/128445.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
