大家好,又见面了,我是你们的朋友全栈君。
一:新建CUDA项目流程(VS2013下)
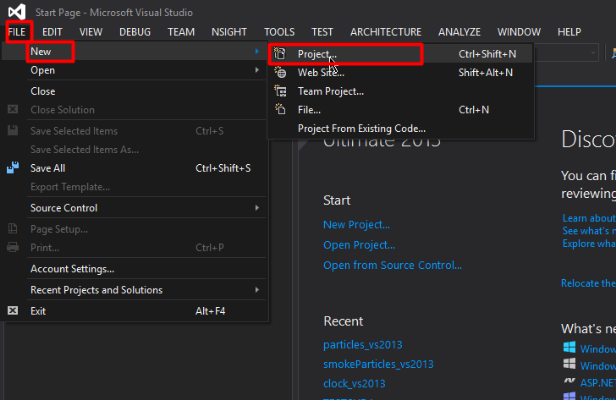
1.新建项目(file->New->Project)

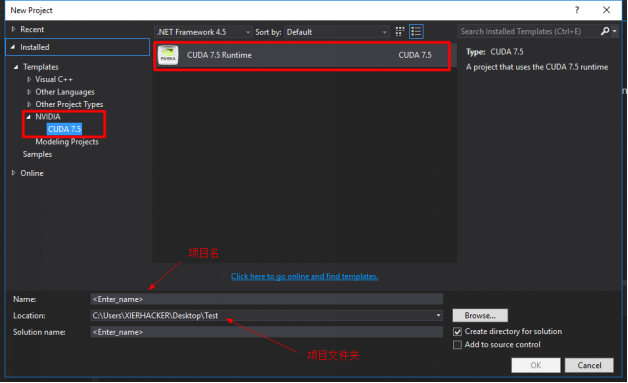
2.在项目列表中可以看见NVIDIA的CUDA项目(前提是你安装了CUDA)
选择项目,添加一些必要的信息,自己定义就行
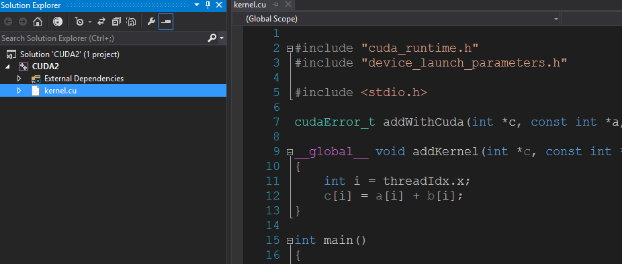
3.项目生生成成功
.cu文件就是跑在GPU上面的文件。文件夹里面是自动生成的一些要依赖的库文件你可以不用管
二:第一个程序:HelloWorld
我们通过最基本最经典的HelloWorld的程序来讲解在CUDA编程中的一些最基本的概念.消化这个程序的流程是非常重要的,因为很多基础都在这里.(这里贴代码采用的是截图的方式,便于知道哪里更加重要)
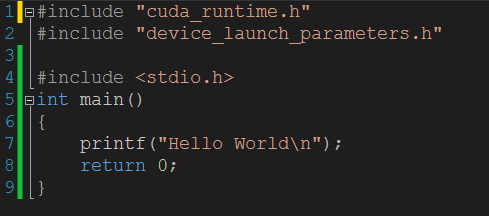
第一阶段:普通(C程序)
代码:
结果:
其实这就是一个C语言程序,但是其中载入了一些GPU编程的头文件(实际上这些文件并没有用到).后面会在这个源文件上面添加一些代码来慢慢扩充整个GPU编程入门源程序.
这里我们要搞清楚两个常用的概念:主机(host)和设备(device).
主机:CPU及系统的内存
设备:GPU及其内存
所以,在这里我们认为他是和纯C语言代码差不多是因为这个程序并没有考虑除了主机之外的设备.
第二阶段(引入核函数)
代码:
结果:
这里确实用到了GPU,但是设备函数(也叫核函数)本身并没有做什么事情,仅仅是调用了一下而已.
1.这个程序两个地方需要注意
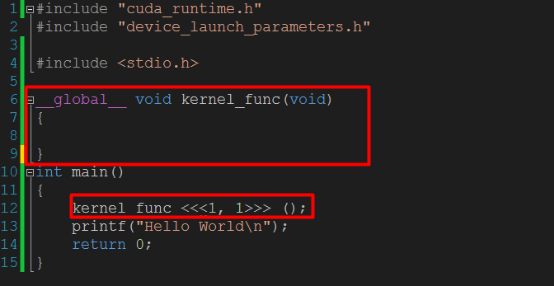
1.一个空的函数kernel_func(),且前面是__global__来修饰
2.对于这个函数的调用,注意其特殊的调用格式.2.__global__告诉系统,这个函数应该交给编译设备代码的编译器来编译.而main函数依然是交给主机的编译器.
3.这段代码看上去就像是CUDA编译器在运行时负责实现从主机代码中调用设备代码.
4.核函数调用时候的尖括号<<<x,x>>>是传递给runtime系统而不是传递给设备代码的参数.这个参数告诉runtime如何启动代码.(这里你并需要知道这是什么意思,在后面会讲到)
5.核函数后面的圆括号(),就和普通的函数一样,就是传递普通参数的.
第三阶段(对核函数传递参数)
代码:
结果:
显而易见,上面那段代码是完成的两个整数相加的操作.但是两个整数相加是在GPU上面完成的.这里也开始真正进入了比较烧脑的阶段了.(下面的描述请结合代码来看)
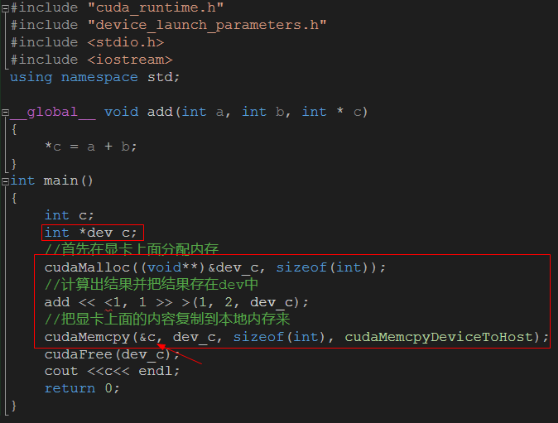
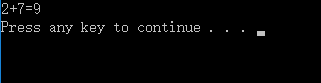
1.可以像c函数那样使用参数,核函数除了一个尖括号以外,其他的都跟普通的函数是差不多的.具体运行由rumtime系统负责.
2.当设备执行任何有用的操作的时候,都需要分配内存(例如将计算值返回给主机)
3.关于cudaMalloc():
cudaMalloc()这个函数的作用是在设备(GPU)上面分配内存,而不是在主机上面.所以一定要区分好和标准malloc的关系.
标准malloc函数:
首先复习一下标准的malloc函数
原型:extern void *malloc(unsigned int num_bytes);
malloc 向系统申请分配指定size个字节的内存空间。返回类型是 void* 类型。void* 表示未确定类型的指针。我们都已经知道,void* 类型可以强制转换为任何其它类型的指针。cudaMalloc():
然后就是新的cudaMalloc函数.
原型:__host____device__cudaError_t cudaMalloc(void**devPtr, size_t size)
参数:
devPtr:主机一个指针变量的地址,到时候某个设备内存的地址就存放在这里
Size:需要分配的空间的大小
返回值:
cudaSuccess, cudaErrorMemoryAllocation
描述:Allocates size bytes of linear memory on the device and returns in *devPtr a pointer to the allocated memory. The allocated memory is suitably aligned for any kind of variable. The memory is not cleared. cudaMalloc() returns cudaErrorMemoryAllocation in case of failure.
The device version of cudaFree cannot be used with a *devPtr allocated using the host API, and vice versa.其实这里是让很多人都非常非常疑惑的地方,主要就是因为cudaMalloc这个函数中的形参.写成了void **的样式.而在给出的例子里面,写成了(void **)&dev_c.很多人就会很疑惑了.刚开始我也是很疑惑的.
首先来看上面的例子,其中那句话int *dev_c还是很好懂的,就是声明了一个指针变量(与其说指针变量,本质上说是存放地址的变量更贴切).这里要注意的是,声明的这个变量还是在主机上面声明的,这个变量也是存储在主机内存上面的,这时候还没有和设备相联系.
那为什么这里需要定义一个地址(指针)变量呢?是为了之后将设备(显存)上面的开辟内存的地址(首地址)赋给主机我们刚刚定义的地址(指针)变量.(千万别绕晕了.)
然后像这个申请显存的函数,第一个参数传递的是dev_c这个指针的地址(&dev_c),然后改变这个地址的内容就会带给实参真正的改变。
总结这个函数的操作过程就是:cudaMalloc的第一个参数传递的是存储在cpu内存中的指针变量的地址,cudaMalloc在执行完成后,向这个地址中写入了一个地址值(此地址值是GPU显存里的)。
4.关于cudaMemcpy():
访问设备内存的必备函数,类似于C中的memcpy,但是C中的memcpy只适用于主机到主机中间的内存拷贝.
标准memcpy()函数
和上面一样,复习一下标准的memcpy()函数
所需头文件:#include <string.h>
原型:void *memcpy(void *dest, const void *src, size_t n);
从源src所指的内存地址的起始位置开始拷贝n个字节到目标dest所指的内存地址的起始位置中cudaMemecpy函数:
原型:__host__cudaError_t cudaMemcpy (void *dst, const void *src, size_t count, cudaMemcpyKind kind)
参数:
dst:被拷贝的内存地址(就是拷贝的东西会放到这里来)
src:拷贝的源地址(就是从这里拷贝)
count:拷贝的数量(单位是字节bytes哦)
kind:拷贝的方式,有下面几种
cudaMemcpyHostToHost
cudaMemcpyHostToDevice
cudaMemcpyDeviceToHost
cudaMemcpyDeviceToDevice
返回值:
cudaSuccess, cudaErrorInvalidValue, cudaErrorInvalidDevicePointer,
cudaErrorInvalidMemcpyDirection 5.cudaMalloc开辟出来的内存必须要用cudaFree来释放,不能够在主机里面随便释放.(主机指针只能够在访问主机代码中的内存,设备指针只能够访问设备代码中的内存).不能够在主机代码中对于设备指针解引用.也就是说,因为dev_c中现在存放的是设备上面的地址,所以*dev_c或者直接释放dev_c的操作都是不行的.
6.设备指针的使用限制:
1.可以将cudaMalloc分配的指针传递给在设备上面执行的函数,也可以传递给在主机上面执行的函数.(这点很重要)
2.可以在设备代码中使用cudaMalloc分配的指针进行内存读写操作(其实是废话.)不能够在主机代码中使用cudamalloc分配的指针进行内存读写操作(本质就是设备指针读写设备内存,主机指针读写主机内存)
3.总结起来就是:传递地址可以,但是访问读写(解引用)不行7.cudaMalloc()和cudaFree函数是关于怎么分配和释放内存的函数.
8.访问设备内存的两种最常用方法:
1.在设备代码中使用设备指针(这是废话)
2.在主机代码中使用cudaMemcpy()函数:连接主机内存和设备内存的桥梁.(很重要) 有了上面的基础,那么再来从头到尾看下那个示例.首先int c;显而易见c是以后用来接收结果的变量,且定义在主机内存上面.
然后就是之前提到过的int *dev_c,同样也是定义在主机内存上面,它的作用就是用来保存之后在显存上面分配的内存的地址.
cudaMalloc((void **)&dev_c,sizeof(int));就是在显存上面分配指定大小的存储空间,并且把地址赋给了dev_c.也就是说,dev_c虽然是主机内存上面的地址变量,但是他存储的是在显存上面开辟的地址.(dev_c存个地址总行了吧...)
然后就是调用自己定义的核函数(设备函数)add来求和,这里要注意核函数的定义方式.在核函数add的函数体中,c能够解引用*c是因为c本身传入的就是一个设备指针.设备指针能够在设备代码中读写解引用.函数的作用也就是得到的结果放入设备地址开辟的内存中.
然后把显存上面的内容复制到本地来,所以,第一个参数是主机接受变量(c)的地址,第二个参数就是源地址(设备地址,由dev_c保存),第三个就是内容大小,第四个表示是从设备复制到主机.
然后c中的内容就是得到的结果了.只是这个结果有点曲折.(先开辟显存,计算出结果放在显存里面,把结果从显存复制到主机内存)
用cudaFree()函数释放设备的地址.至此,已经讲完了建立一个非常基础简单的cuda项目需要的步骤以及其中注意的问题.
三:查询你的设备信息
因为我们最终会涉及到在设备上分配内存和执行代码,因此,了解自己设备的信息一般是很重要的.
Ⅰ.基本的结构和函数
首先是结构,显卡的信息是能够通过一个叫cudaDeviceProb结构体得到的。这个结构体记录了显卡的信息。所以,我们之后得到信息的工作都是访问结构体的信息得到的。下面直接贴了API中的结构体的详细信息(不用记下来,知道一些常用的,然后用得到的时候查就行)




2.cudaGetDeviceCount()函数
作用:找出来这台主机中的所有的显卡数量
用法:

3.cudaGetDeviceProperties()函数
作用:返回第i个显卡的配置结构体.
用法:

Ⅱ.实战
只列出了几个基本的,其他的可以根据需要在表中找到.然后自己写出来.
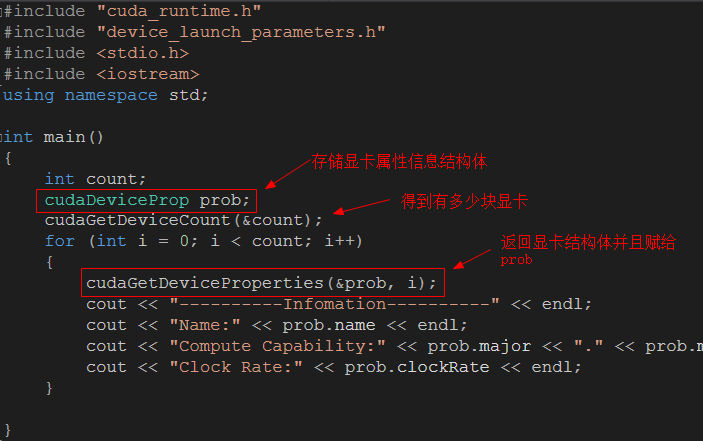
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/128439.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
