大家好,又见面了,我是你们的朋友全栈君。
近期读了一些关于LSTM的文章,但仍旧很难理解,关键就是不懂输入、输出是什么,相比于图像处理的CNN,RNN特别抽象。
昨晚花了很大的精力去理解“遗留状态”这个概念,现在终于明白了一些,关键在timestep这个概念。
一、深入理解timestep
我们看到的所有的RNN结构图,其实都是在一个timestep中的,而不是整个序列。(这句话很简单,但真的是花了很长时间才领悟到的)
以下引用自知乎回答:
我的RNN理解
用动图讲RCNN
对于常用的cnn模型,它只能单独处理每个输入,每个输入之间完全没有联系,但是现实中很多情况是需要考虑数据的前后之间的联系的,比如:视频的每一帧都是有联系的,一段话中每个词也都是离不开上下文的,那么可不可以在神经网络输入的时候把之前的信息加进去呢?因此提出了RNN模型。
在提到RNN时,总会遇到这个抽象的图:
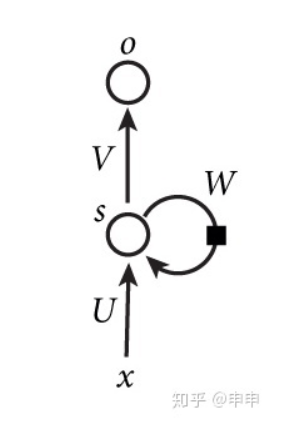

这个图总是让人一脸蒙蔽阿,说白了这就是rnn的一个抽象流程。x代表输入,o代表输出,s代表隐藏层。如果把W这个环去掉,就是最普通的网络结构,把这个环扩展开,如下图所示:
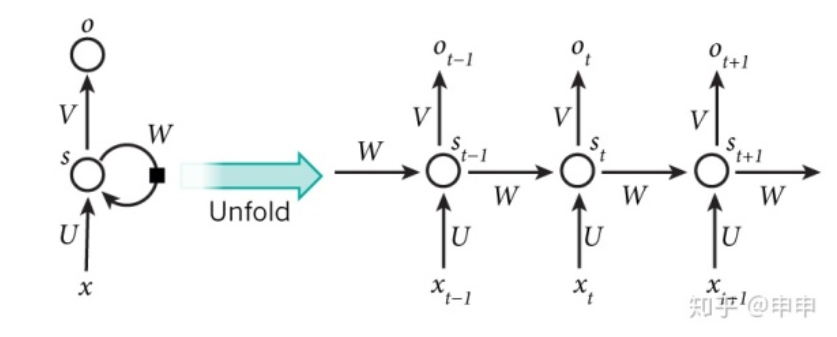
其实x向量并不是一下子全都输进去的,是每次输入一个Xt,并且每次输出一个Ot。具体公式如下:

其中,f、g都是激活函数,Ot由隐藏层决定,相当于是一个全连接。St是由当前的输入Xt以及上一个隐藏层共同决定的。这里介绍的比较简单,任何一个rnn教程都会对该过程做一个详细的说明。看到这里我就不太理解,我这个W的环到底要循环多少次?这是由timestep决定的。timestep的值决定了该rnn的结构,如果timestep为20,那么这个W的环要循环20次,每一步t都需要一个输入,同时也会有一个输出,共有20次输入和对应的20个输出。

所以说,造成我理解最大的困难就是没有懂上面的那句话:我们看到的所有的RNN结构,其实是对一个timestep内部来说的,而不是timestep之间。RNN所谓的t-1的遗留状态也是在一个timestep里面的事情,t多少取决于timestep的值。
二、timestep示例理解
这一个实战操作的解释会有助于理解这一过程:
简单粗暴LSTM:LSTM进行时间序列预测
LSTM进行预测需要的是时序数据 根据前timestep步预测后面的数据
假定给一个数据集
{
A,B,C->D
B,C,D->E
C,D,E->F
D,E,F->G
E,F,G->H
}
这时timestep为3,即根据前三个的数据预测后一个数据的值。我们所谓的隐藏状态是这样的:把A输入进去,得到隐藏状态h(1),然后h(1)与B一起输入,得到h(2),然后h(2)与C一起输入…
而不是过去以为的[ABC—D]训练完,得到h(1),再把[BCD—E]和h(1)训练得到h(2)…
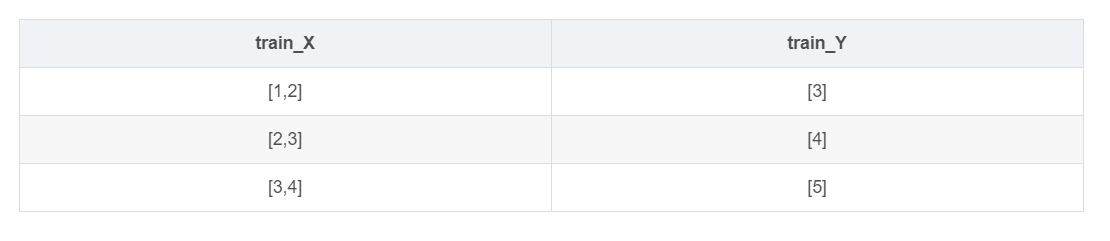
举一个简单的情况 假设一个list为[1,2,3,4,5],timestep = 2
我们转化之后要达到的效果是
这部分就需要自己编程实现,按照自己设定的timestep构建训练集:
def create_dataset(dataset, look_back):
#这里的look_back与timestep相同
dataX, dataY = [], []
for i in range(len(dataset)-look_back-1):
a = dataset[i:(i+look_back)]
dataX.append(a)
dataY.append(dataset[i + look_back])
return numpy.array(dataX),numpy.array(dataY)
#训练数据太少 look_back并不能过大
look_back = 1
trainX,trainY = create_dataset(trainlist,look_back)
testX,testY = create_dataset(testlist,look_back)
所以说,timestep的值为n,就意味着我们认为每一个值都和它前n个值有关系。拿来预测时也是如此,如果timestep=n,训练之后,为了预测第m个值,就要把m的前n个值做输入。
三、示例:timestep与Batchsize的区别
个人看法:给定一个长序列,序列中的每一个值,也都由一个很长的向量(或矩阵)表示。把序列从前往后理解为时间维度,那么timestep就是指的这个维度中的值,如果timestep=n,就是用序列内的n个向量(或矩阵)预测一个值。
而对于每一个向量来说,它本身有一个空间维度(如长度),那么Batchsize就是这个空间维度上的概念。
比如一共有5个字母ABCDE,它们分别如此表示:
A:1 1 1 1 1
B:2 2 2 2 2
C:3 3 3 3 3
D:4 4 4 4 4
E:5 5 5 5 5
如果timestep为2,那么在训练过程中就是:
| X | Y |
|---|---|
| AB | C |
| BC | D |
| CD | E |
下面我们只看第一对数据:AB-C
t=0,A进入训练,生成h(0)
t=1,B进入训练,生成h(1)
下面我们只看t=0,由于A的序列可能也很长(在本例子中是5),所以也不能一次全都带进去。这就需要分批次了(和过去的所有网络就一样了),所以设定Batchsize为2,则就是分成三批次:11、11、1
四、示例:timestep、batchsize、inputsize的区别
下面的例子来自动图看懂RNN
我们用碎纸做个比方。有一张A4纸,长宽分别为297*210 mm,现在要把纸塞进碎纸机里。

在这个例子中,
A4纸就是数据,总数据量为297*210,
碎纸机是神经网络
输出的结果是粉碎的纸,这里我们先不管输出是什么样,只关注输入。
每次塞纸时,都要正拿A4纸,把210的一边冲着碎纸机的口塞入。
现在开始考虑各个参数的意义。
下图代表input_size=1,batch=1,喂给碎纸机的是一个1*1的小纸片,训练1000次代表喂1000次纸;

下图代表数据维度input_size=210,batch=1,也就说,数据本身发生了变化——增加维度了;

下图代表input_size=1,批次batch=297,数据本身没变,每次训练时进的数据量多了

相应的,下图就代表input_size=210,batch=297,一共只需要1次就能训练完所有数据。

以上是我们之前学习的全连接神经网络。
现在引入RNN。RNN保留了之前所有参数,并增加了参数time_step(时间步),对于这个例子,我们应该怎么理解这个新参数呢?
此刻你手中的纸突然有了厚度(10297210),碎纸机还是那台,纸变厚了,就必须切片才能塞进去,在这个例子中,纸被切成了10层。
1、RNN要求你,每次塞纸时,不管纸是什么形状(不管batch等于多少),都必须把10层纸依次、先后、全塞进去,才算一次完整的喂纸,中间不许停(time_step=10)
2、同时,每层纸在进纸时,还需要跟上层产生的碎纸片一起塞进去(h_{t-1}+x_{t})
至此,我们看到,batch依然保留,与time_step分别代表不同意义。

其实,从另一个角度也可以区分,time_step是神经网络的参数,网络建好了便不会改变;batch是训练参数,在训练时可根据效果随时调整。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/128435.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
