大家好,又见面了,我是你们的朋友全栈君。
基于卷积神经网络的人脸表情识别
前言
这篇文章记录一下我本科毕业设计的内容。我的课题是人脸表情识别,本来最开始按照历届学长的传统是采用MATLAB用传统的机器学习方法来实现分类的。但是鉴于我以前接触过一点点深度学习的内容,觉得用卷积神经来实现这个网络或许效果会好一点。于是我上网络上搜集了大量资料,照着做了一个基于Pytorch实现的卷积模型,加入了调用摄像头实时识别的程序。第一次接触机器视觉的东西,没有什么经验,还望指教。本次设计的参考来源于以下:
1.基于卷积神经网络的面部表情识别(Pytorch实现)–秋沐霖。链接:LINK
2.Pytorch基于卷积神经网络的人脸表情识别-marika。链接:LINK
3.Python神经网络编程-塔里克
毕业设计内容介绍
本文章使用Pytorch深度学习框架用卷积神经网络设计了人脸表情识别程序,将部分FER2013作为数据集进行训练,另一部分作为测试集。利用三层卷积层和四层全连接层对数据集进行模型训练,训练集精度能够达到99.4%,测试集精度最高达到60.5%。同时利用训练好的模型设计了实时人脸表情识别系统,能够调用摄像头对人脸表情进行实时分析,能够识别出基本的表情类别并通过标签显示在窗口上,同时展示系统判定的概率大小。
卷积神经网络的设计
卷积网络的模型
数据集选用的是FER2013{百度网盘链接:Link}
链接:https://pan.baidu.com/s/1MTQ12vq60vVOWIPTLlfOGw
提取码:xili
该数据为csv格式存储,0-6分别代表了:(0)生气、(1)厌恶、(2)恐惧、(3)高兴、(4)悲伤、(5)惊讶、(6)自然。这些数据需要进行处理转变为jpg格式输入网络训练。下图展示了处理好的数据集。将数据集


下图是本次系统所采用的卷积神经网络模型。数据集图像大小为48×48,模型由三层卷积和池化层组成,和四层全连接层组成。结构比较简单,因此最终训练出来的模型识别精度有限。
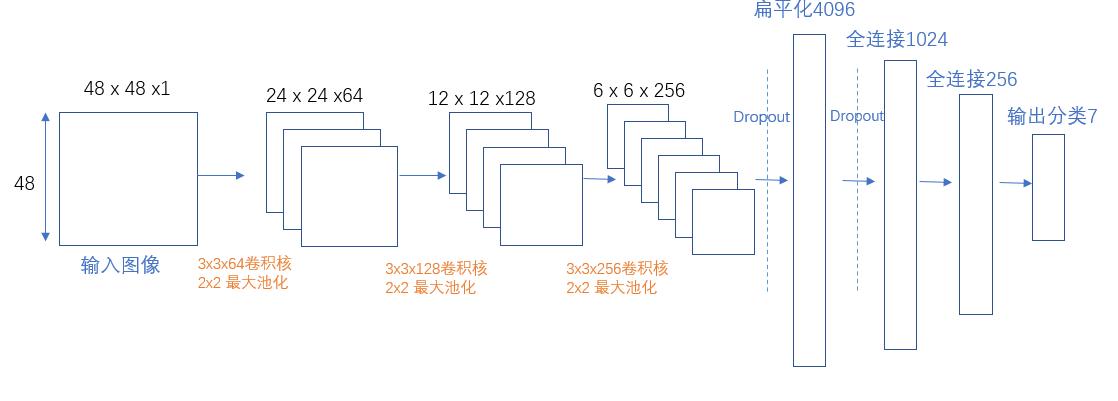

卷积池化过程详细说明
模型构建好了,那具体过程怎么实现呢,下面我会对每一次卷积和池化的过程进行详细说明。模型输入为1通道48×48的图像,输出为256通道的6×6的特征图。卷积过程中均采用3×3的卷积核,为了卷积后特征图尺寸不变,在卷积之前进行了一圈边缘填充。
填充意思是原本48×48的图像,padding为1时,会变成49×49的尺寸。
步长是指每次卷积核或者池化核移动的跨度大小。
第一层卷积池化过程
第一层卷积核池化过程:如下图所示,在第一层卷积层中,我们采用的是3×3的卷积核,输入图像大小为48×48,卷积后得到了64个通道的48×48的特征图。然后是经过ReLU函数运算,使特征图内像素值保持在合理的范围内。然后使用大小为2的池化核进行池化操作,步长为2,最后将得到64通道的24×24的特征图。
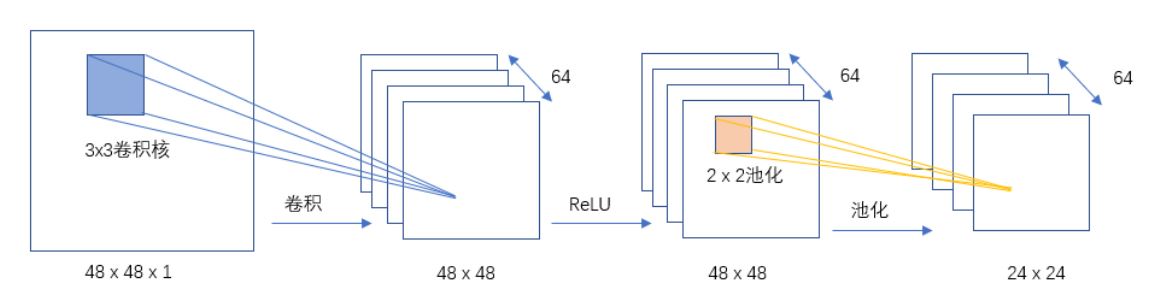
第二层卷积池化过程
第二层卷积和池化过程:如图所示,在第二层卷积层,采用的是128个3×3的卷积核,步长为1,边缘填充为1,进行卷积之后输出为一个128通道的24×24的特征图。再经过了ReLU函数后,使用2×2的核进行池化操作,得到了128张12×12的特征图。
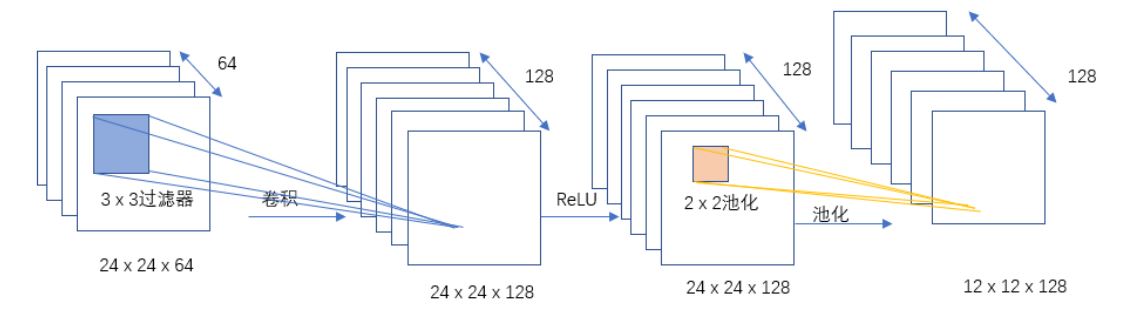
第三层卷积池化过程
第三层卷积和池化的过程:如下图所示,第三层卷积采用256个卷积核对128通道的上一层输出的特征图进行卷积操作,256个通道的12×12的特征图,然后再经过ReLU函数运算,对其进行2×2的池化操作,得到了256通道6×6的特征图。
全连接层过程
在经过三层卷积层操作后,在第四层中将第三层输出的256通道3×3的特征图进行一维化展开,然后将其全连接到4096个神经元节点上,经过ReLU激活层,再进行Dropout。在第五层中,将4096个节点连接到1024个神经元节点,经过ReLU层,再经过Dropout。在第六层中,将上一层的1024个神经元节点对下一层的256个节点进行全连接,然后连接到最后一层输出层的7个神经元节点上,经过Softmax函数就可以完成7种表情的分类,输出每一种表情的概率。
模型的训练过程
卷积与池化原理
模型构建好以后,网络的参数都还是随机的,没有任何意义,那怎么样才能让卷积神经网络完成分类的任务呢?下面我来谈谈卷积神经网络的实现过程。卷积实际上就是对图像的内容进行特征提取的一个过程,卷积核就像是一个小的窗口,去图像上逐一套,看每次所移动到的窗口位置上的“贴合度”,要是“贴合度”高,点积求和运算得到的数值就会比较高,反之就会较小。这样操作以后就会的到一个特征图。下图展示了对图像进行卷积的具体过程,卷积核共用一个偏置。在图像中,浅层的卷积层用来提取原始图像上的边缘轮廓信息,深层次的卷积层能从底层次的特征图中迭代提出复杂的图像抽象信息。
卷积过程

池化过程:池化层能够十分有效地减小图像的空间尺寸和参数量,从而减小计算量。因此,当输入图像比较大的时候,通常会导致网络运算参数量很大,在相邻的卷积层之间间隔性地引入池化操作,能够有效地解决训练参数过多的问题,能够在有效信息保留的同时压缩图像大小,提高计算速度。池化层可以选择进行平均池化或者是最大池化。平均池化是指对单元格内的所有元素指相加取平均值,最大池化是在所有对应单元格内的所有元素值中取最大值最为池化输出结果。下图展示了池化过程,采用的是最大池化。
池化过程动图

模型如何训练
表情特征训练就是用本次设计的模型对预先处理好的数据集进行提取表情特征的过程。训练过程大概分为:前向传播、反向传播、损失值计算、求权值梯度和权值更新几个过程。下图展示了神经网络训练过程。
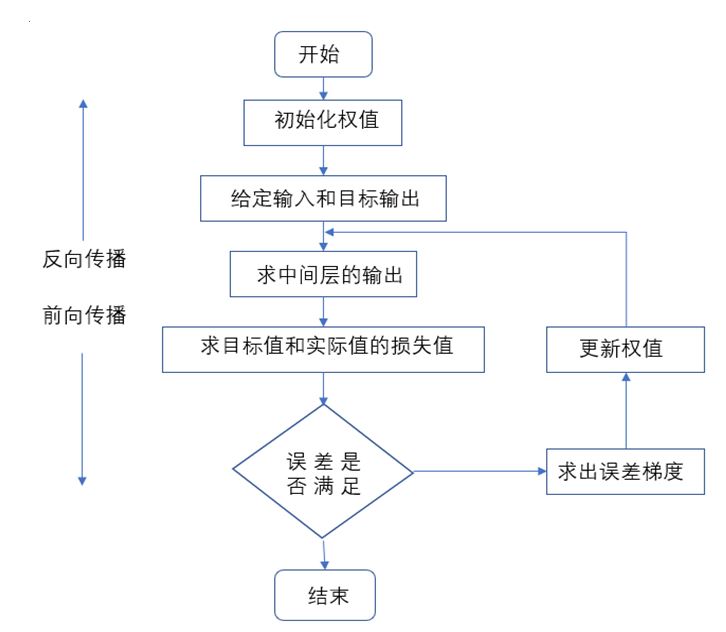
![]()
反向传播的实现过程:深度学习中学习方式一般都是反向传播方法,–反向传播本身是有梯度下降法发展而来,通过引入一个神经单元误差delta,该变量能将梯度下降法中比较繁琐的求解偏导过程变为数列的递推关系式。通俗的来说就是,通过链式法则,可以求解出全局的损失函数对于某一个权值或者偏置的偏导。然后乘以eta,也就是学习率来更新参数大小。下式为神经单元误差delta的定义。
δ j l = ∂ C ∂ z j l ( l = 2 , 3 , ⋯ ) \delta _{j}^{l}=\frac{\partial C}{\partial z_{j}^{l}}\left( l=2,3,\cdots \right) δjl=∂zjl∂C(l=2,3,⋯)
神经单元误差怎么求呢?根据链式法则推导,得到了第l层和第l+1层的关系式如下面公式所示。只要我们得知了最后一层的神经单元误差,就可以通过公式进行递推得到前面的神经单元误差,进而可以得到我们更新参数需要用到的参数梯度值。
δ i l = { δ 1 l + 1 w 1 i l + 1 + δ 2 l + 1 w 2 i l + 1 + ⋯ + δ m l + 1 w m i l + 1 } a ′ ( z i l ) \delta _{i}^{l}=\left\{ \delta _{1}^{l+1}w_{1i}^{l+1}+\delta _{2}^{l+1}w_{2i}^{l+1}+\cdots +\delta _{m}^{l+1}w_{mi}^{l+1} \right\} a’\left( z_{i}^{l} \right) δil={
δ1l+1w1il+1+δ2l+1w2il+1+⋯+δml+1wmil+1}a′(zil)
利用上式,我们可以通过递推关系逐一求出所有需要更新的参数的神经单元误差,求出这个delta以后,我们就可以通过神经单元误差与权值和权重之间的联系求的权值和偏置对于损失函数的偏导数。如下公式所示。
{ ∂ C ∂ w j i l = δ j l a j l − 1 ∂ C ∂ b j l = δ j l ( l = 2 , 3 ⋯ ) \begin{cases} \frac{\partial C}{\partial w_{ji}^{l}}=\delta _{j}^{l}a_{j}^{l-1}\\ \frac{\partial C}{\partial \mathrm{b}_{j}^{l}}=\delta _{j}^{l}\\ \end{cases}\left( l=2,3\cdots \right) ⎩⎨⎧∂wjil∂C=δjlajl−1∂bjl∂C=δjl(l=2,3⋯)
得到对于损失函数的偏置以后,我们的目的是为了更新网络的权重,使网络的误差进一步减小,通过以下公式进行权值更新。
模型的评估指标
在模型构建完毕后,需要对模型的效果好坏进行一些评估,然后以评估的效果来作为参考进而继续调整模型的权值和偏置量,以达到最佳的效果。根据不同选择的模型评估指标,就会有不同的评估结果,且没有什么模型能够保证在所有的评估中都是最优,因此模型的强弱能力还主要取决于要解决什么样的问题。例如自动化生成线中的水果好坏检测机器,其目的是将好的水果送到生产线前端去,坏的水果挑出来,即便仍然会有一些误判,但是影响不会太大。而对于刑事侦查中的犯罪调查就不同了,模型的建立目的是将罪犯识别出来,而不希望有太高的误判。
卷积神经网络通常使用的评估指标也就是损失函数是交叉熵损失函数。交叉熵能够衡量同一个随机变量中的两个不同概率分布的差异程度,在机器学习中就表示为真实概率分布与预测概率分布之间的差异。交叉熵的值越小,模型预测效果就越好。下式为交叉熵损失函数。
C = − 1 n ∑ i = 1 n [ y i ln ( σ ( z ) ) + ( 1 − y i ) ln ( 1 − σ ( z ) ) ] C=-\frac{1}{n}\sum_{i=1}^n{\left[ y_i\ln \left( \sigma \left( z \right) \right) +\left( 1-y_i \right) \ln \left( 1-\sigma \left( z \right) \right) \right]} C=−n1i=1∑n[yiln(σ(z))+(1−yi)ln(1−σ(z))]
训练结果分析
通过训练曲线分析
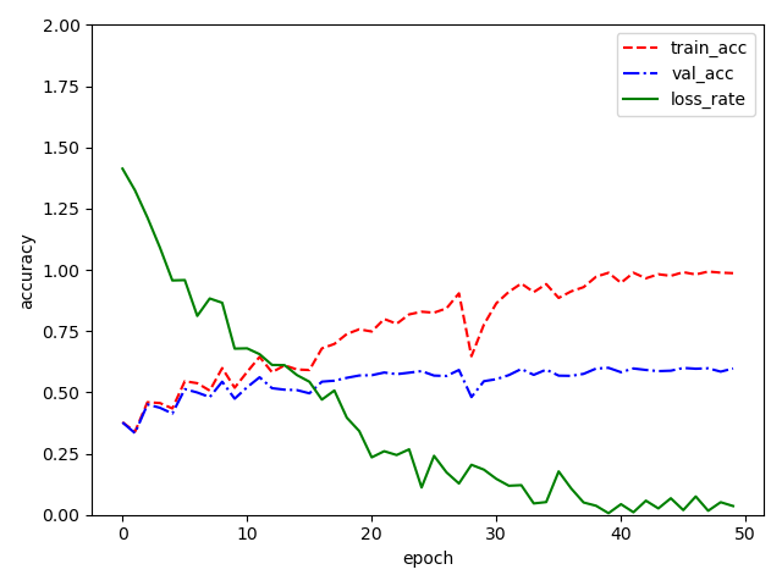
下图显示的是训练的每个时期的损失值和测试集精度以及测试集精度曲线。其中Batch Size大小为128,学习率为0.1,对模型训练50次。图中横轴数值表示迭代轮数,纵轴数值代表了模型损失率和训练精度。从图中可以看到,训练迭代到第35轮的时候训练集精度和测试集精度都基本趋于稳定,其中训练集测试精度能够达到99.4%,测试集精度最高达到60.5%。此时损失值稳定在一个较小的数值小幅度震荡,基本能够保持在一个稳定的趋势,这时候训练模型的性能较好。
输出曲线实现的代码:
def draw(train_acc, val_acc, epoch, loss):
epoch_list.append(epoch)
train_acc_list.append(train_acc)
val_acc_list.append(val_acc)
loss_list.append(loss)
x = torch.tensor(train_acc_list)
y = torch.tensor(val_acc_list)
l = torch.tensor(loss_list)
z = torch.tensor(epoch_list)
plt.cla()
plt.ylim((0, 2))
plt.xlabel('epoch')
plt.ylabel('accuracy')
# plt.scatter(z.numpy(), x.data.numpy(), c='r', marker='x')
# plt.scatter(z.numpy(), y.data.numpy(), c='b')
# plt.scatter(z.numpy(), l.data.numpy(), c='g', marker='o')
plt.plot(z.numpy(), x.data.numpy(), color='red', linestyle='--', label='train_acc')
plt.plot(z.numpy(), y.data.numpy(), color='blue',linestyle='-.', label='val_acc')
plt.plot(z.numpy(), l.data.numpy(), color='green', label='loss_rate')
plt.legend()
# plt.pause(0.005)
plt.show()
每次训练一轮就调用一次该函数,然后更新图像。
下面是训练过程中的动图效果。为了显示效果直观,在每一轮训练都标注了点。

![]()
通过混淆矩阵分析效果
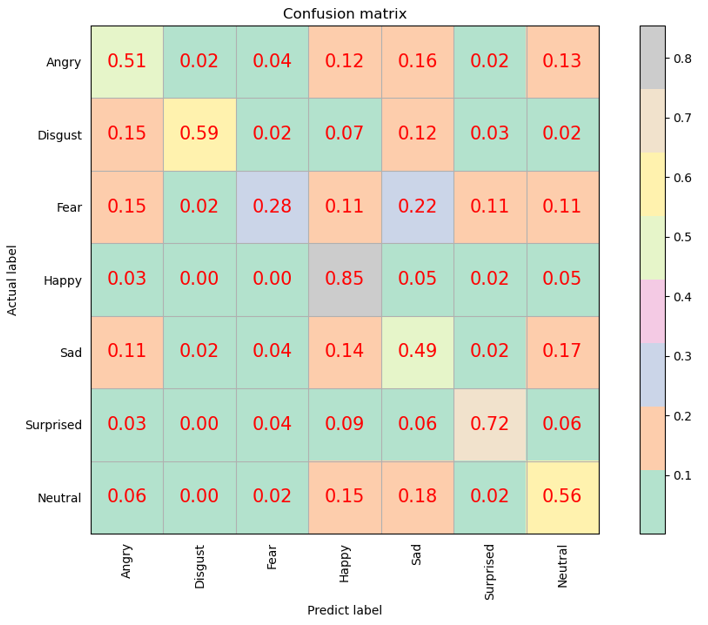
混淆矩阵也称误差矩阵,是表示精度评价的一种标准格式,用n行n列的矩阵形式来表示。如下图所示,表示的是7种表情的混淆矩阵,矩阵正对角线代表每一种表情的判断准确率。在该图中的横坐标代表对人脸表情的预测类型,纵坐标代表了人脸表情的正确类别。
![]()
从图中我们可以看出对于高兴的判别准确率能够达到85%,也就是说在训练集中对所有开心的表情进行判别中有85%能够正确识别的,开心的表情被错判为生气、悲伤、惊讶和自然的错误率分别是3%、5%、2%和5%。在7类表情判定中,对恐惧的识别精度最低,正确率只有28%,也就是在所有恐惧的数据集中,只有28%的图片被判定正确。可见,由于对应恐惧的训练集样本较少,导致最后判定的错误率较高。
混淆矩阵实现代码:
def plot_confusion_matrix(cm, savename, title='Confusion Matrix'):
plt.figure(figsize=(12, 8), dpi=100)
np.set_printoptions(precision=2) # 控制输出小数点个数为2
# 在混淆矩阵中每格的概率值
ind_array = np.arange(len(classes)) # 生成一个长度为*的列表[1,2,3....]
x, y = np.meshgrid(ind_array, ind_array) # 在网格上画一个正方形坐标
for x_val, y_val in zip(x.flatten(), y.flatten()):
c = cm[y_val][x_val]
if c > 0.001:
plt.text(x_val, y_val, "%0.2f" % (c,), color='red', fontsize=15, va='center', ha='center')
plt.imshow(cm, interpolation='nearest', cmap=plt.cm.Pastel2)
plt.title(title)
plt.colorbar()
xlocations = np.array(range(len(classes)))
plt.xticks(xlocations, classes, rotation=90)
plt.yticks(xlocations, classes)
plt.ylabel('Actual label')
plt.xlabel('Predict label')
# offset the tick
tick_marks = np.array(range(len(classes))) + 0.5
plt.gca().set_xticks(tick_marks, minor=True)
plt.gca().set_yticks(tick_marks, minor=True)
plt.gca().xaxis.set_ticks_position('none')
plt.gca().yaxis.set_ticks_position('none')
plt.grid(True, which='minor', linestyle='-')
plt.gcf().subplots_adjust(bottom=0.15)
# show confusion matrix
plt.savefig(savename, format='png')
plt.show()
通过摄像头识别表情
设计流程
根据上一节训练好的模型设计一个能够调用摄像头实时识别人脸表情的系统,系统要识别的表情分为7种,分别是:悲伤、高兴、恐惧、愤怒、中性、厌恶和惊讶。识别结果会将标签显示在识别界面,同时显示识别的概率大小。系统的识别过程有如下几个步骤:
(1)运行系统的程序,自动打开摄像头;
(2)摄像头打开后,自动捕获图片,检测到人脸,框出人脸;
(3)对框中的人脸进行裁剪,并送入系统进行处理灰度化,大小尺寸归一化,转变为TENSOR格式送入卷积神经网络;
(3)卷积神经网络进行前向传播得到对7类表情的预测概率数组
(4)将卷积神经的输出取最大值作为预测值,将结果标签和对应概率输出在系统界面。
效果演示
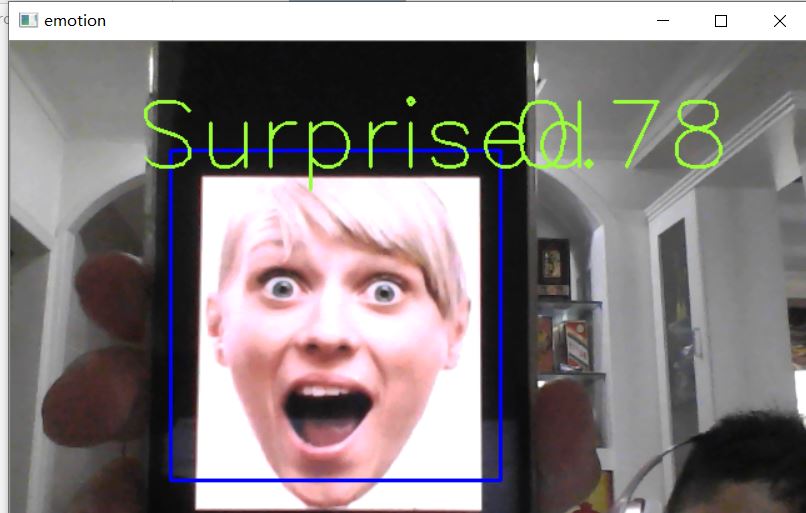
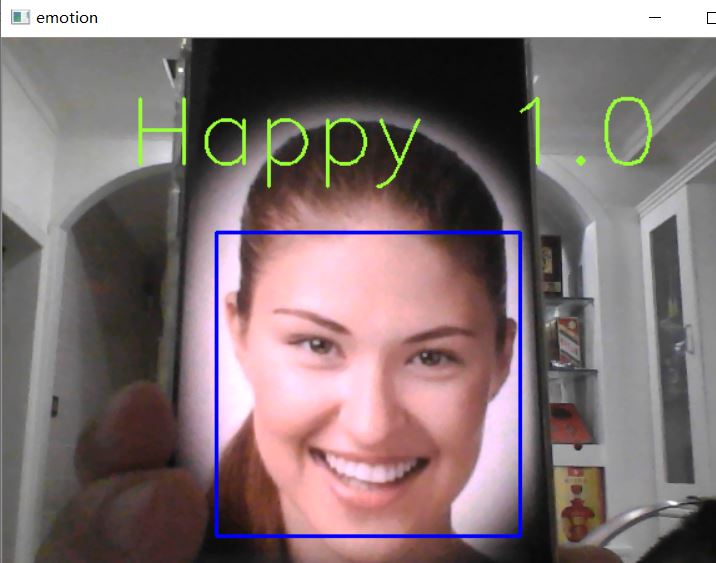
上图演示了表情识别的效果,数字代表的是卷积神经网络输出的概率矩阵中的最大值四舍五入以后的数值。表示系统判定该表情的正确概率。
部分代码展示
pre = model.forward(img)
pre = F.softmax(pre, dim=1) # dim = 0是对列操作,dim = 1是对行操作
pro = pre.cpu().data.numpy()
max_num = max(pro[0])
result = round(max_num, 2)
# print(max_num)
pred = np.argmax(pro, axis=1)
# pre = model(img).item()
# print(pre)
# pre = pre.max(1)[1]
frame = cv2.putText(frame, emotion[pred[0]], (100, 100), cv2.FONT_HERSHEY_SIMPLEX, 2.5, (55,255,155), 2)
#显示窗口第一个参数是窗口名,第二个参数是内容
frame = cv2.putText(frame, str(result), (400, 100), cv2.FONT_HERSHEY_SIMPLEX, 2.5, (55, 255, 155), 2)
cv2.imshow('emotion', frame)
if cv2.waitKey(1) == ord('q'):#按q退出
break
总结
博主写这篇博客是为了记录自己学习的一些历程,第一次写博客,所以很多地方可能会有些错误,希望多多包涵,还请大佬们日后多加指点。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/128396.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...