大家好,又见面了,我是你们的朋友全栈君。
一、内连接查询 inner join
关键字:inner join on
语句:select * from a_table a inner join b_table b on a.a_id = b.b_id;
说明:组合两个表中的记录,返回关联字段相符的记录,也就是返回两个表的交集(阴影)部分。

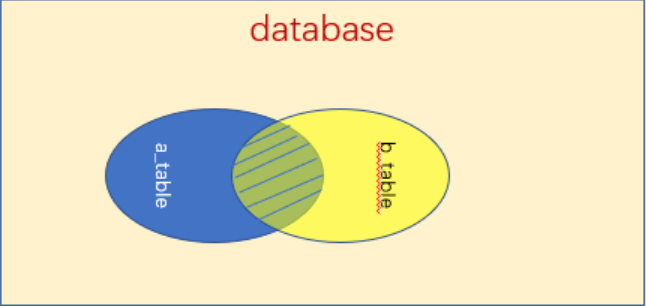
案例解释:在boy表和girl 表中查出两表 hid 字段一致的姓名(gname,bname),boy表和girl 表如下:
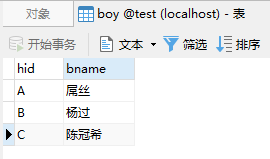
采用内连接查询方式:
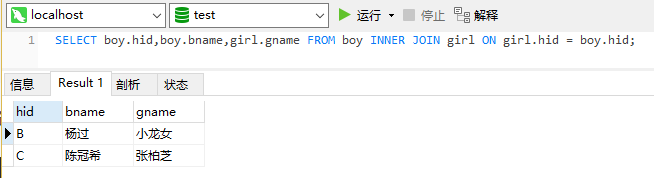
SELECT boy.hid,boy.bname,girl.gname FROM boy INNER JOIN girl ON girl.hid = boy.hid;查询结果如下:
二、左连接查询 left join
关键字:left join on / left outer join on
语句:SELECT * FROM a_table a left join b_table b ON a.a_id = b.b_id;
说明: left join 是left outer join的简写,它的全称是左外连接,是外连接中的一种。 左(外)连接,左表(a_table)的记录将会全部表示出来,而右表(b_table)只会显示符合搜索条件的记录。右表记录不足的地方均为NULL。
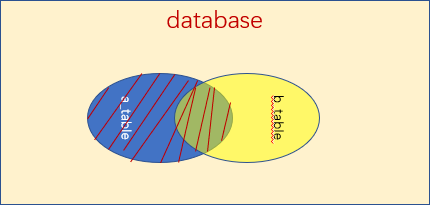
案例解释:在boy表和girl 表中左连接查询,boy表和girl 表如下:
采用内连接查询方式:
SELECT boy.hid,boy.bname,girl.gname FROM boy LEFT JOIN girl ON girl.hid = boy.hid;查询结果如下:
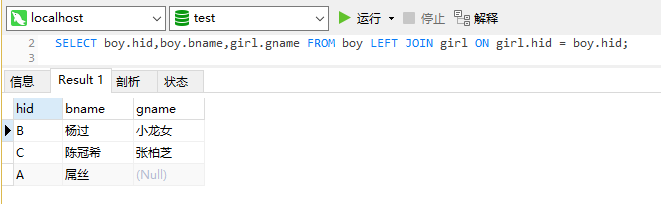
三、右连接 right join
关键字:right join on / right outer join on
语句:SELECT * FROM a_table a right outer join b_table b on a.a_id = b.b_id;
说明:right join是right outer join的简写,它的全称是右外连接,是外连接中的一种。与左(外)连接相反,右(外)连接,左表(a_table)只会显示符合搜索条件的记录,而右表(b_table)的记录将会全部表示出来。左表记录不足的地方均为NULL。
案例解释:在boy表和girl 表中右连接查询,boy表和girl 表如下:
采用内连接查询方式:
SELECT boy.hid,boy.bname,girl.gname FROM boy RIGHT JOIN girl ON girl.hid = boy.hid;查询结果如下:
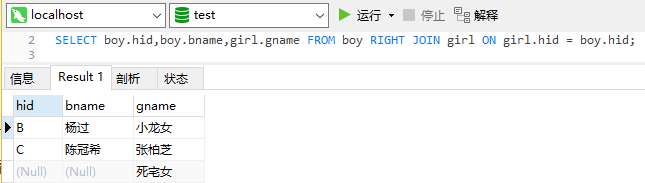
四、全连接 union
关键字:union /union all
语句:(select colum1,colum2…columN from tableA ) union (select colum1,colum2…columN from tableB )
或 (select colum1,colum2…columN from tableA ) union all (select colum1,colum2…columN from tableB );
union语句注意事项:
1.通过union连接的SQL它们分别单独取出的列数必须相同;
2.不要求合并的表列名称相同时,以第一个sql 表列名为准;
3.使用union 时,完全相等的行,将会被合并,由于合并比较耗时,一般不直接使用 union 进行合并,而是通常采用union all 进行合并;
4.被union 连接的sql 子句,单个子句中不用写order by ,因为不会有排序的效果。但可以对最终的结果集进行排序;
(select id,name from A order by id) union all (select id,name from B order by id); //没有排序效果
(select id,name from A ) union all (select id,name from B ) order by id; //有排序效果
案例解释:将a表和b表合并,表结构如下:
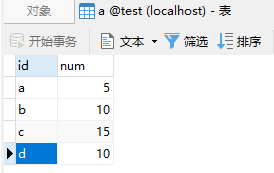
采用 union 全连接:
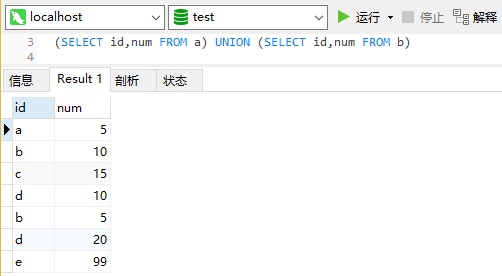
union会自动将完全重复的数据去除掉,a、b表中”c”的值都为15,所以只显示一行。
采用 union all 全连接:
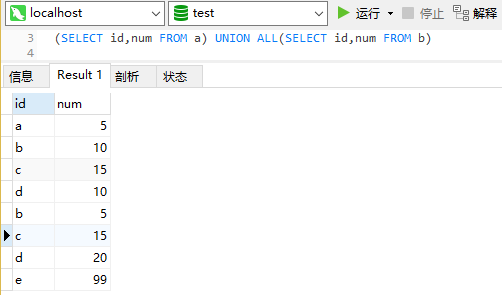
union all会保留那些重复的数据;
左右连接练习题:
根据给出的表结构按要求写出SQL语句。t 表(即Team表)和 m 表(即Match表) 的结构如下:
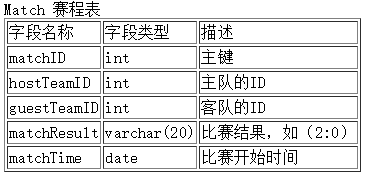
t 表(即Team表)和 m 表(即Match表) 的内容如下:
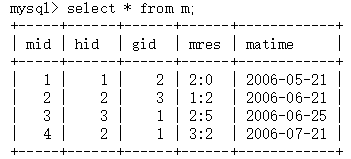
m 表(即Match表) 的 hostTeamID 与 guestTeamID 都与 t 表(即Team表) 中的 teamID 关联。请查出 2006-6-1 到2006-7-1之间举行的所有比赛,并且用以下形式列出: 拜仁 2:0 不来梅 2006-6-21
===============================================================================
解决方案:
第一步:先以 m 表左连接 t 表,查出 m 表中 hid 这列对应的比赛信息:
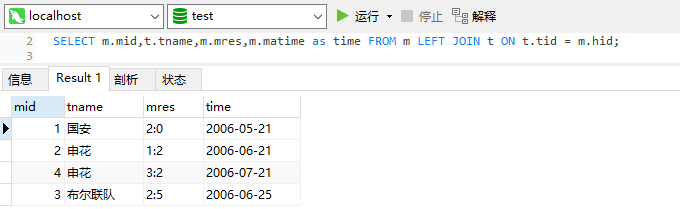
SELECT m.mid,t.tname,m.mres,m.matime as time FROM m LEFT JOIN t ON t.tid = m.hid;查询结果记为结果集 t1 ,t1 表如下:
第二步:先以 m 表左连接 t 表,查出 m 表中 gid 这列对应的比赛信息:
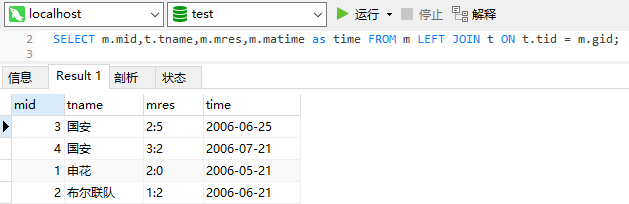
SELECT m.mid,t.tname,m.mres,m.matime FROM m LEFT JOIN t ON t.tid = m.gid;查询结果记为结果集 t2 ,t2 表如下:
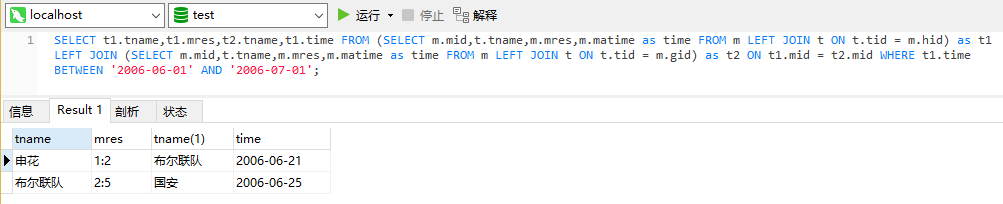
第三步:以结果集 t1 为基础左连接查询结果集 t2,查询条件为两者比赛序号(mid)相同。
SELECT t1.tname,t1.mres,t2.tname,t1.time FROM
(SELECT m.mid,t.tname,m.mres,m.matime as time FROM m LEFT JOIN t ON t.tid = m.hid)
as t1
LEFT JOIN
(SELECT m.mid,t.tname,m.mres,m.matime as time FROM m LEFT JOIN t ON t.tid = m.gid)
as t2
ON t1.mid = t2.mid WHERE t1.time BETWEEN '2006-06-01' AND '2006-07-01';查询结果如下:
全连接练习题:
A表和B表结构如下,请将两表合并:

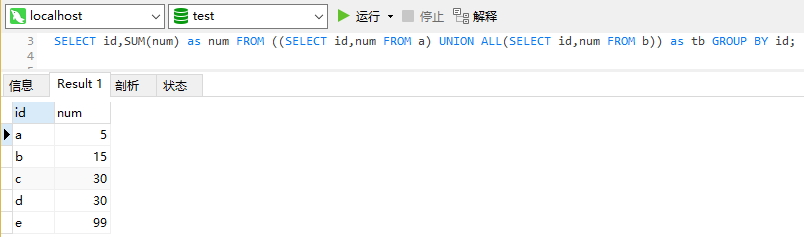
合并要求:A表中a:5,B表中a:5,因此合并后表中a对应的值为10;要求查出的结果样本如下:

采用 union all 全连接,然后使用from 子查询:
SELECT id,SUM(num) as num FROM ((SELECT id,num FROM a) UNION ALL(SELECT id,num FROM b)) as tb GROUP BY id;
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/128270.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
