大家好,又见面了,我是你们的朋友全栈君。
Domain Adaptation
在经典的机器学习问题中,我们往往假设训练集和测试集分布一致,在训练集上训练模型,在测试集上测试。然而在实际问题中,测试场景往往非可控,测试集和训练集分布有很大差异,这时候就会出现所谓过拟合问题:模型在测试集上效果不理想。
以人脸识别为例,如果用东方人人脸数据训练,用于识别西方人,相比东方人识别性能会明显下降。
当训练集和测试集分布不一致的情况下,通过在训练数据上按经验误差最小准则训练的模型在测试上性能不好,因此出现了迁移学习技术。
领域自适应(Domain Adaptation)是迁移学习中的一种代表性方法,指的是利用信息丰富的源域样本来提升目标域模型的性能。
领域自适应问题中两个至关重要的概念:源域(source domain)表示与测试样本不同的领域,但是有丰富的监督信息;目标域(target domain)表示测试样本所在的领域,无标签或者只有少量标签。源域和目标域往往属于同一类任务,但是分布不同。
根据目标域和源域的不同类型,领域自适应问题有四类不同的场景:无监督的,有监督的,异构分布和多个源域问题。
通过在不同阶段进行领域自适应,研究者提出了三种不同的领域自适应方法:1)样本自适应,对源域样本进行加权重采样,从而逼近目标域的分布。2)特征层面自适应,将源域和目标域投影到公共特征子空间。3)模型层面自适应,对源域误差函数进行修改,考虑目标域的误差。
样本自适应:
其基本思想是对源域样本进行重采样,从而使得重采样后的源域样本和目标域样本分布基本一致,在重采样的样本集合上重新学习分类器。
样本迁移(Instance based TL)
在源域中找到与目标域相似的数据,把这个数据的权值进行调整,使得新的数据与目标域的数据进行匹配,然后加重该样本的权值,使得在预测目标域时的比重加大。优点是方法简单,实现容易。缺点在于权重的选择与相似度的度量依赖经验,且源域与目标域的数据分布往往不同。


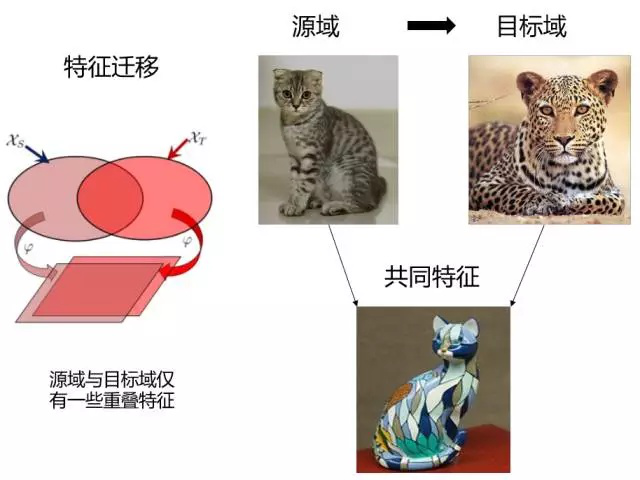
特征自适应:
其基本思想是学习公共的特征表示,在公共特征空间,源域和目标域的分布要尽可能相同。
特征迁移(Feature based TL)
假设源域和目标域含有一些共同的交叉特征,通过特征变换,将源域和目标域的特征变换到相同空间,使得该空间中源域数据与目标域数据具有相同分布的数据分布,然后进行传统的机器学习。优点是对大多数方法适用,效果较好。缺点在于难于求解,容易发生过适配。
链接:https://www.zhihu.com/question/41979241/answer/247421889
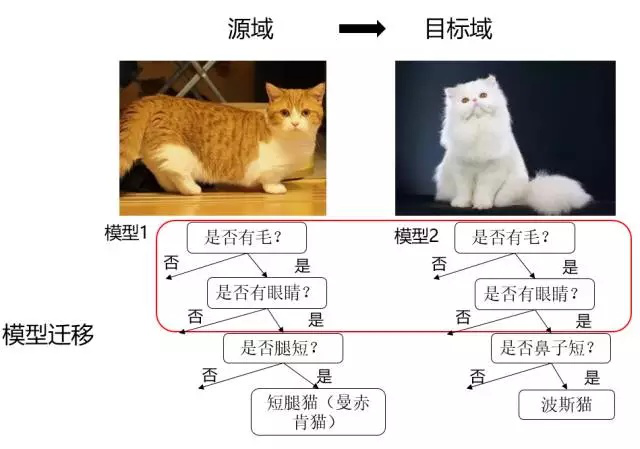
模型自适应:
其基本思想是直接在模型层面进行自适应。模型自适应的方法有两种思路,一是直接建模模型,但是在模型中加入“domain间距离近”的约束,二是采用迭代的方法,渐进的对目标域的样本进行分类,将信度高的样本加入训练集,并更新模型。
模型迁移(Parameter based TL)
假设源域和目标域共享模型参数,是指将之前在源域中通过大量数据训练好的模型应用到目标域上进行预测,比如利用上千万的图象来训练好一个图象识别的系统,当我们遇到一个新的图象领域问题的时候,就不用再去找几千万个图象来训练了,只需把原来训练好的模型迁移到新的领域,在新的领域往往只需几万张图片就够,同样可以得到很高的精度。优点是可以充分利用模型之间存在的相似性。缺点在于模型参数不易收敛。
注:博众家之所长,集群英之荟萃。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/127862.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
