大家好,又见面了,我是你们的朋友全栈君。
随着电商企业的发展,为了更好的了解用户喜好以便于将更加适合的商品推荐给用户,不仅能得到用户好的评价,而且也有利于自身企业的利益,因此,随之诞生了很多推荐系统,最为常用的推荐算法就是协同过滤算法。
转载请标明原文链接原文地址
推荐算法的基础就是基于两个对象之间的相关性,常用的计算方法有欧几里得相似性,这是一种使用较多的相似性计算方法。除此之外还有曼哈顿相似性和余弦相似性的计算方法。
协同过滤算法又称“集体计算”方法,其主要思想是利用人性的相似性进行相似性的比较。协同过滤算法主要有两种具体形式。
- 基于用户的推荐算法
- 基于 物品的推荐算法
基于用户的推荐算法
基于用户的推荐算法可以用一个词语来描述,就是“志趣相投”,如果两个人有着相同的兴趣和品位,那么在一般情况下,你朋友喜欢的东西你也会喜欢,因此,协同过滤算法就是基于这种特性来向用户推荐产品的。
那么在电商项目中应用该算法呢?以购物为例,你在淘宝上买完一件东西之后,就需要你对该商品进行评分,因此,基于客户对于产品的评分就可以判断两个用户之间的相似度,其实生活中有很多例子,不仅仅是商品,还有电影,音乐推荐等等,其应用广泛。
在协同过滤算法的应用中,常常会有下面两个元素:
- Item:能够被推荐给用户的项目
-
User:用户,能够对Item进行评分
一般情况下会建立User-Item矩阵:

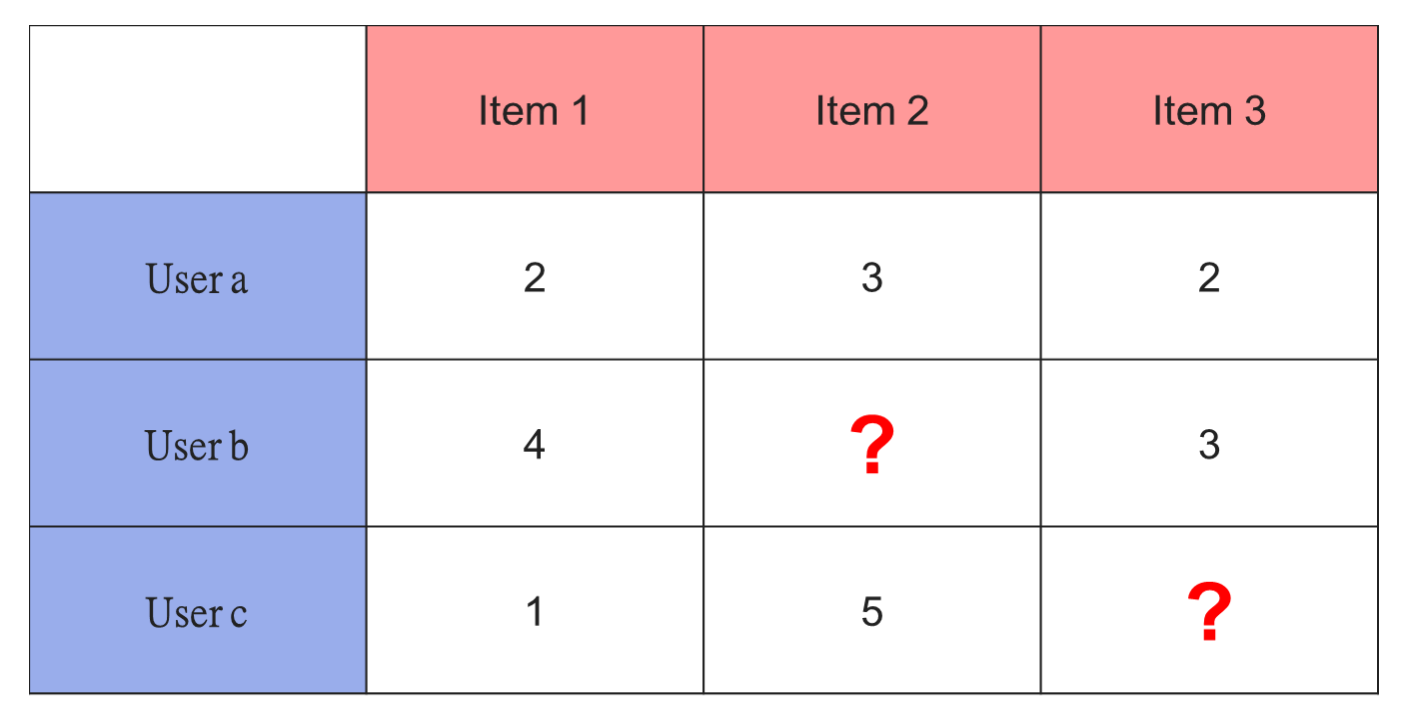
下面来看看基于用户推荐算法的步骤。
查找用户的相似度
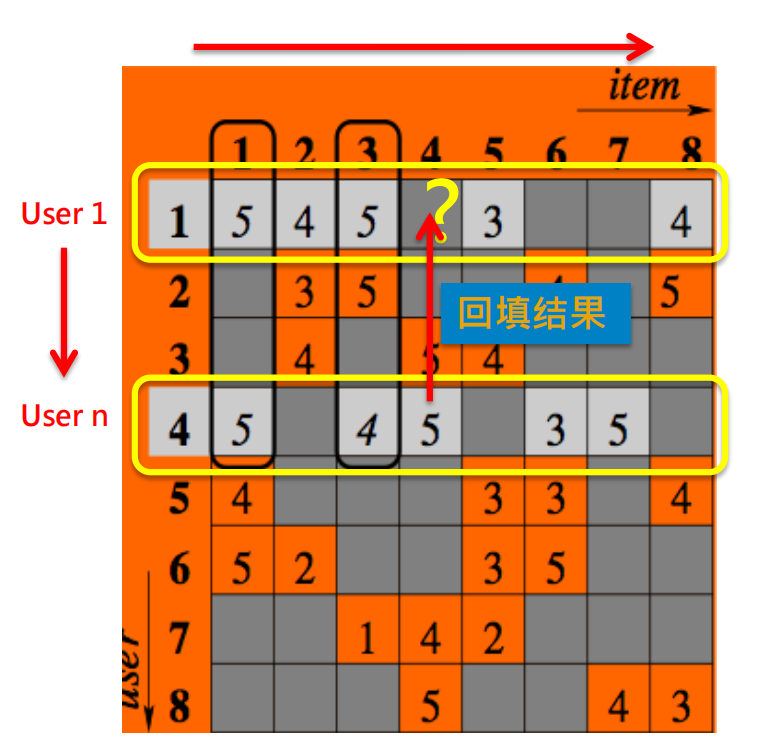
1.如何预测用户1对于商品4的喜好程度?
2.找到和用户1相似的用户且购买过商品4(基于购买记录)即为用户n。
3.根据用户n对商品4的评价,以相似度为权重回填结果 。
4.针对所有用户组合,重复1~3,直到所有空格都被填满
从上面的步骤中可以看出,该算法的实现难度不大,其核心在于找出相似的用户,这需要选择合适的相似度计算方法进行计算。基于用户的协同过滤算法做的推荐,用特定的扫描和指定目标相同已有用户,根据给定的相似度对用户进行相似度计算,选择得分最高的用户并根据其已有的信息作为推荐结果从而反馈给用户。这种推荐算法在计算结果上较为简单易懂,具有很高的实践应用价值。
基于物品的推荐
同样的,对于基于物品的推荐算法也可以使用一个词语来进行描述,即“物以类聚”,根据物品的相似性作为用户喜好的依据推荐给用户。顾名思义,基于物品的推荐算法是以已有的物品为线索去进行相似度计算从而给特定的目标用户。
基于物品的推荐算法步骤如下:
找出相似的Item

1.如何预测用户1对于商品4的喜好程度?
2.从用户1历史记录中,计算商品n和商品4的相似度(以其他用户的历史记录)。
3.将用户1对于商品n的评价,以商品相似度为权重回填。
4.针对所有商品组合,重复1~3直到所有空格都被填满。
协同过滤算法的优缺点
基于用户的和基于物品的推荐算法均是最常用的协同过滤算法,但是需要按照场合使用,在有些场合它们也存在着不足之处。
首先,基于用户的推荐算法,这种方式往往会将一些热度的物品排在推荐的首位,因此对用户的喜好预测不是很准确,并且这种推荐没有任何意义,更有热度的物品并不需要推荐,用户自己喜欢的话自己会去买,而根据二八定律,在现代互联网的销售中,有80%的销售额来自于20%的热门名牌,众所周知,互联网销售物品繁多,用户也许进入购物网站对于如此海量的商品在没有目的的购物时往往会比较头疼,但是如果我们能主动推荐一款产品,就可以解决用户的烦扰,也促进了商品的销售。而在这些繁多的商品中,“冷门”商品占绝大多数,我们称这些物品为“长尾商品”(出自美国《连线》杂志在2004年发表的“The Long Tail”一文,并且出版了《长尾理论》一书),我们要对这些长尾商品进行数据挖掘,提高其销售额,因此必须充分研究用户的兴趣,从而将长尾商品准确的推荐给需要它的用户,而不是对一些“热度”物品做反复的推荐。而且基于用户的推荐算法数据量较为庞大,计算费事。
基于物品的推荐算法,其数据量不大,可以较为容易的生成推荐值,但是它也存在着一个问题,同类物品的问题,例如,在你购买了一个商品之后,如果还推荐相同类型的商品,用户也许想下次购买时试试别的类型的商品,此时的推荐就不算成功,因此其准确率也不高。
因此,可以总结出基于用户的推荐算法推荐效果好,不过数据量较大,计算费事;基于物品的推荐算法推荐效果不是很显著,但是数据量不大,计算效率高。
参考资料:
《Spark MLlib机器学习实践》 王晓华 著 清华大学出版社《Mahout数据挖掘介绍》
《推荐系统实践》
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/127747.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
