大家好,又见面了,我是你们的朋友全栈君。
目录
图像翻译,指从一副图像到另一副图像的转换。可以类比机器翻译,一种语言转换为另一种语言。下图就是一些典型的图像翻译任务:比如语义分割图转换为真实街景图,灰色图转换为彩色图,白天转换为黑夜……


本文主要介绍图像翻译经典的模型pix2pix,pix2pixHD,
- pix2pix提出了一个统一的框架解决了各类图像翻译问题,
- pix2pixHD则在pix2pix的基础上,较好的解决了高分辨率图像转换(翻译)的问题,
学习GAN的关键就是理解生成器、判别器和损失函数这三部分
pix2pix与pix2pixHD的生成器
生成器的结构是U-net。有的GAN使用的是encoder-decoder模型作为生成器,但是相比之下,U-net效果会更好。因为上采样时加入了底层的特征信息。假设总共有n层,那么第i层和第n-i层之间有跳跃连接。注意:U-Net的跳跃连接和ResNet的不同,和DenseNet相同,是按通道拼接的。(作者问题:是否可以认为ResNet总是不如DenseNet呢?是不是可以使用ResNet的地方都可以使用DenseNet呢?)
判别器 PatchGAN(马尔科夫判别器)
不同于直接判断图片是否是真实的,PatchGAN会分别判断N x N个patch是否为真,然后求平均值输出。L1损失可以使模型学到低频的特征,PatchGAN的结构可以使模型学到高频的特征(因为它关注的是局部的信息)。而且,当N比原图的尺寸小得多时依然有效。
1、pix2pix
本文最大的贡献在于提出了一个统一的框架解决了图像翻译问题。
相比以往算法的大量专家知识,手工复杂的loss。这篇paper非常粗暴,使用CGAN处理了一系列的转换问题。
上面展示了许多有趣的结果,比如分割图 –> 街景图,边缘图 –> 真实图。对于第一次看到的时候还是很惊艳的,那么这个是怎么做到的呢?我们可以设想一下,如果是我们,我们自己会如何设计这个网络。
简单粗暴的办法
最直接的想法就是,设计一个CNN网络,直接建立输入-输出的映射,就像图像去噪问题一样。可是对于上面的问题,这样做会带来一个问题。生成图像质量不清晰。
拿下图第二排的分割图 –> 街景图为例,语义分割图的每个标签比如“汽车”可能对应不同样式,颜色的汽车。那么模型学习到的会是所有不同汽车的平均,这样会造成模糊。下图第三列就是直接用L1 Loss来学习得到的结果,相比于Ground truth,模糊很严重

如何解决模糊呢?
这里作者想了一个办法,即加入GAN的Loss去惩罚模型。GAN相比于传统生成式模型可以较好的生成高分辨率图片。思路也很简单,在上述直观想法的基础上加入一个判别器,判断输入图片是否是真实样本。模型示意图如下:
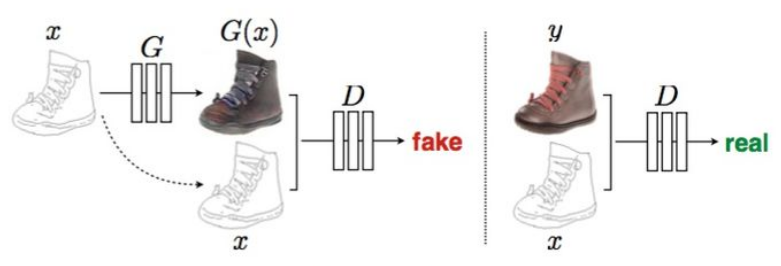
上图模型和CGAN有所不同,但它是一个CGAN,只不过输入只有一个,这个输入就是条件信息。原始的CGAN需要输入随机噪声,以及条件。这里之所有没有输入噪声信息,是因为在实际实验中,如果输入噪声和条件,噪声往往被淹没在条件C当中,所以这里直接省去了。
其他tricks
从上面两点可以得到最终的Loss由两部分构成:
- 输出和标签信息的L1 Loss。
- GAN Loss – 测试也使用Dropout,以使输出多样化
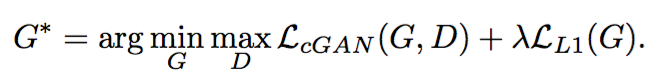
采用L1 Loss而不是L2 Loss的理由很简单,L1 Loss相比于L2 Loss保边缘:即L1生成的图片更清晰, 注:L2 Loss基于高斯先验,L1 Loss基于拉普拉斯先验
GAN Loss为LSGAN的最小二乘Loss,并使用PatchGAN(进一步保证生成图像的清晰度)。PatchGAN将图像换分成很多个Patch,并对每一个Patch使用判别器进行判别(实际代码实现有更取巧的办法,实际是这样实现的:假设输入一张256×256的图像到判别器,输出的是一个4×4的confidence map,每一个像素值代表当前patch是真实图像的置信度。感受野就是当前的图像patch),将所有Patch的Loss求平均作为最终的Loss。
2、pix2pixHD
这篇paper作为pix2pix的改进版本,如其名字一样,主要是可以产生高分辨率的图像。具体来说,作者的贡献主要在以下两个方面:
- 使用多尺度的生成器以及判别器等方式从而生成高分辨率图像。
- 使用了一种非常巧妙的方式,实现了对于同一个输入,产生不同的输出。并且实现了交互式的语义编辑方式,这一点不同于pix2pix中使用dropout保证输出的多样性。
高分辨率图像生成
为了生成高分辨率图像,作者主要从三个层面做了改进:
- 模型结构
- Loss设计
- 使用Instance-map的图像进行训练。
模型结构
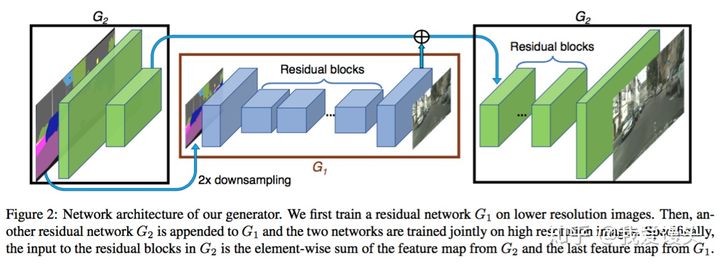
生成器由两部分组成,G1和G2,其中G2又被割裂成两个部分。G1和pix2pix的生成器没有差别,就是一个end2end的U-Net结构。G2的左半部分提取特征,并和G1的输出层的前一层特征进行相加融合信息,把融合后的信息送入G2的后半部分输出高分辨率图像。
判别器使用多尺度判别器,在三个不同的尺度上进行判别并对结果取平均。判别的三个尺度为:原图,原图的1/2降采样,原图的1/4降采样(实际做法为在不同尺度的特征图上进行判别,而非对原图进行降采样)。显然,越粗糙的尺度感受野越大,越关注全局一致性。
生成器和判别器均使用多尺度结构实现高分辨率重建,思路和PGGAN类似,但实际做法差别比较大。
Loss设计
这里的Loss由三部分组成:
- GAN loss:和pix2pix一样,使用PatchGAN。
- Feature matching loss:将生成的样本和Ground truth分别送入判别器提取特征,然后对特征做Element-wise loss
- Content loss:将生成的样本和Ground truth分别送入VGG16提取特征,然后对特征做Element-wise loss
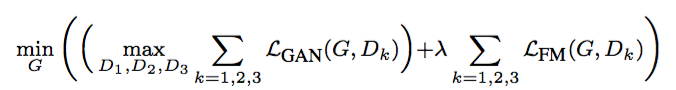
使用Feature matching loss和Content loss计算特征的loss,而不是计算生成样本和Ground truth的MSE,主要在于MSE会造成生成的图像过度平滑,缺乏细节。
Feature matching loss和Content loss只保证内容一致,细节则由GAN去学习。
使用Instance-map的图像进行训练
pix2pix采用语义分割的结果进行训练,可是语义分割结果没有对同类物体进行区分,导致多个同一类物体排列在一起的时候出现模糊,这在街景图中尤为常见。在这里,作者使用个体分割(Instance-level segmention)的结果来进行训练,因为个体分割的结果提供了同一类物体的边界信息。具体做法如下:
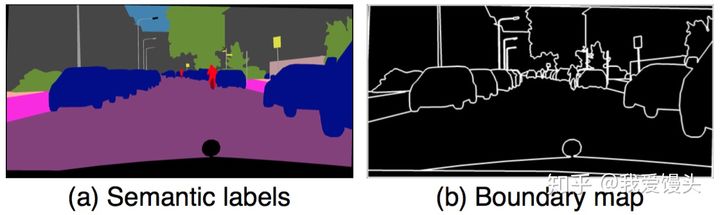
- 根据个体分割的结果求出Boundary map
- 将Boundary map与输入的语义标签concatnate到一起作为输入 Boundary map求法很简单,直接遍历每一个像素,判断其4邻域像素所属语义类别信息,如果有不同,则置为1。下面是一个示例:
语义编辑
不同于pix2pix实现生成多样性的方法(使用Dropout),这里采用了一个非常巧妙的办法,即学习一个条件(Condition)作为条件GAN的输入,不同的输入条件就得到了不同的输出,从而实现了多样化的输出,而且还是可编辑的。具体做法如下:
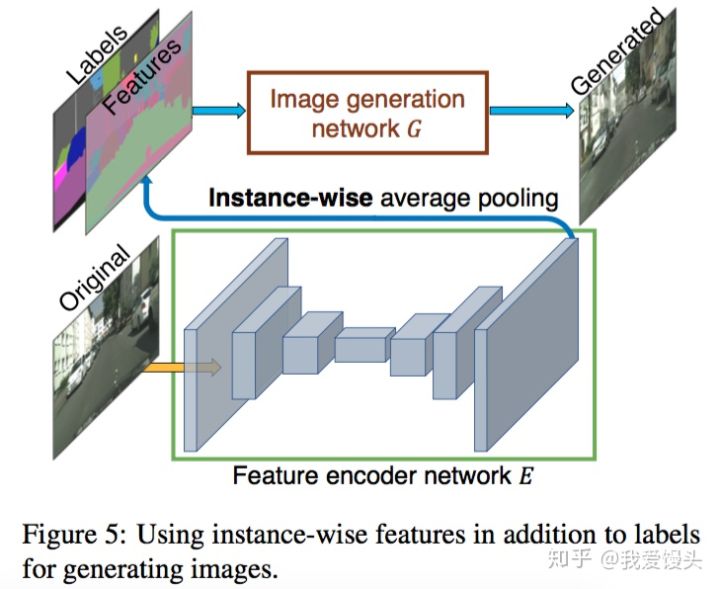
- 首先训练一个编码器
- 利用编码器提取原始图片的特征,然后根据Labels信息进行Average pooling,得到特征(上图的Features)。这个Features的每一类像素的值都代表了这类标签的信息。
- 如果输入图像有足够的多,那么Features的每一类像素的值就代表了这类物体的先验分布。 对所有输入的训练图像通过编码器提取特征,然后进行K-means聚类,得到K个聚类中心,以K个聚类中心代表不同的颜色,纹理等信息。
- 实际生成图像时,除了输入语义标签信息,还要从K个聚类中心随机选择一个,即选择一个颜色/纹理风格
这个方法总的来说非常巧妙,通过学习数据的隐变量达到控制图像颜色纹理风格信息。
总结
作者主要的贡献在于:
- 提出了生成高分辨率图像的多尺度网络结构,包括生成器,判别器
- 提出了Feature loss和VGG loss提升图像的分辨率 – 通过学习隐变量达到控制图像颜色,纹理风格信息
- 通过Boundary map提升重叠物体的清晰度
可以看出,这篇paper除了第三点,都是针对性的解决高分辨率图像生成的问题的。
pix2pixHD笔记_jacke121的专栏-CSDN博客_pix2pixhd
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/127633.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
