大家好,又见面了,我是你们的朋友全栈君。
Python 2.7
IDE Pycharm 5.0.3
爬下来,解析,存储,分析,可视化--一气呵成,当然我还在学前面三个哈哈哈
直奔主题
1.自己写入txt
直接上核心代码:
with open("douban.txt","w") as f:
f.write("这是个测试!")这句话自带文件关闭功能,所以和那些先open再write再close的方式来说,更加pythontic!
结果就是这样:


2.将文件输入(print)的内容写入txt
我并不喜欢手写字符,更多时候用到的就是将程序跑出来的print写到txt中保存,比如说刚从豆瓣抓的内容,我想写进去,该怎么保存呢。这就用到了for循环啦。关于豆瓣的爬取请见我的前面那篇博客
我就是想把输出框的文字保存而已
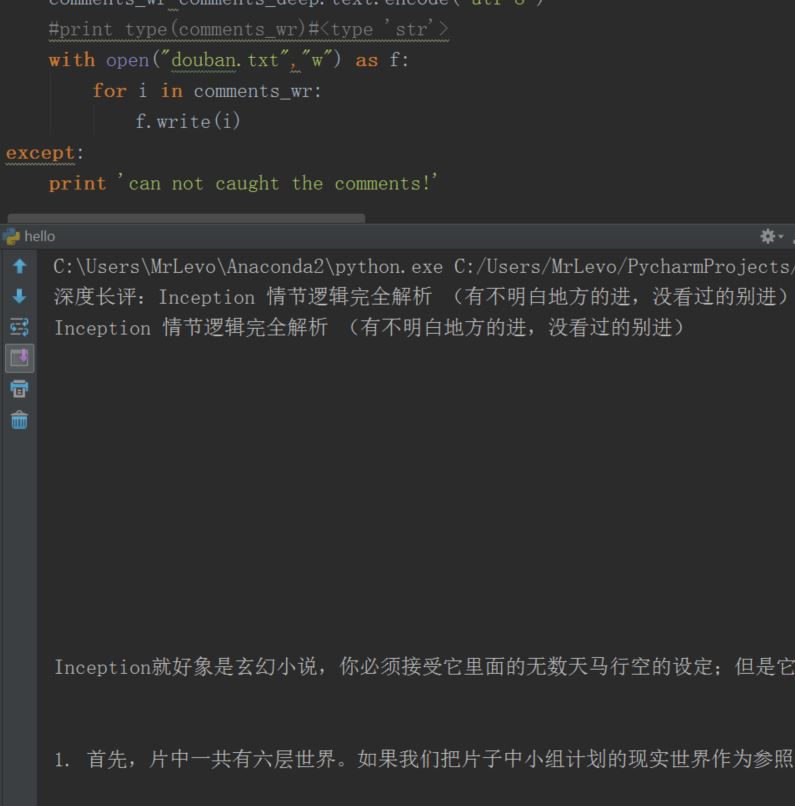
#分模块测试,txt写入测试
# -*- coding: utf-8 -*-
from selenium import webdriver
import selenium.webdriver.support.ui as ui
import time
#driver_item=webdriver.Firefox()
driver_item=webdriver.PhantomJS(executable_path="phantomjs.exe")
url="https://movie.douban.com/subject/3541415/?tag=%E7%A7%91%E5%B9%BB&from=gaia_video"
wait = ui.WebDriverWait(driver_item,10)
driver_item.get(url)
try:
driver_item.find_element_by_xpath("//img[@class='bn-arrow']").click()
#wait.until(lambda driver: driver.find_element_by_xpath("//div[@class='review-bd']/div[2]/div/div"))
time.sleep(1)
comments_deep = driver_item.find_element_by_xpath("//div[@class='review-bd']/div[2]/div")
print u"深度长评:"+comments_deep.text
#print type(comments_deep.text)#<type 'unicode'>
comments_wr=comments_deep.text.encode('utf-8')
#print type(comments_wr)#<type 'str'>
#title="盗梦空间"#中文命名文件名乱码,内容可用 title="Inception"
with open("%s.txt"%title,"w") as f:#格式化字符串还能这么用!
for i in comments_wr:
f.write(i)
except:
print 'can not caught the comments!'比较常用MODE

不清空连续写入
没有文件时候会自动创建的,但是!如果我重新对此进行写入,那么会先清空,然后再写,就是说以前写的没了,这样搞不好吧,我可是要记录很多东西的啊,万能的a出现了。。。
把核心代码改成这样就可以了,记得把w改成a,至于那个分割线问题,因为后续写入和前面已经有的会混在一块,所以我做分割用:
with open("%s.txt"%title,"a") as f:#格式化字符串还能这么用!
f.write("\n-------------------------------------我是分割线-----------------------------------------\n")
for i in comments_wr:
f.write(i)效果是这样的,不够好看自己再加细节,比如换行多几次

That’s all
用到啥学啥,学得快又学的牢

致谢
Python:文件的读取、创建、追加、删除、清空
@王志 –Python: 删除已安装的模块或包(modules or packages)
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/127568.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
