大家好,又见面了,我是你们的朋友全栈君。
全球计算机视觉顶会 CVPR 2018 (Conference on Computer Vision and Pattern Recognition,即IEEE国际计算机视觉与模式识别会议)将于6月18日至22日在美国盐湖城举行。作为大会钻石赞助商,旷视科技Face++研究院也将在孙剑博士的带领下重磅出席此次盛会。而在盛会召开之前,旷视将针对 CVPR 2018 收录论文集中进行系列解读。


论文名称:DocUNet: Document Image Unwarping via A Stacked U-Net
论文链接:https://www3.cs.stonybrook.edu/~cvl/content/papers/2018/Ma_CVPR18.pdf
目录
- 导语
- 设计思想
- 数据集
- 2D 扭曲图像合成
- DocUNet
- 网络架构
- 损失函数
- 实验
- 基准
- 结果
- 结论
- 参考文献
导语
由于移动摄像头数量剧增,随手拍照已成为一种对物理文档进行数字化记录的普遍方式,并可据此展开后续操作,比如文字识别。但是,由于物理文档时常存在扭曲或变形,以及光线条件差等情况,文字识别难以达到理想效果。针对这一问题,旷视科技Face++首次提出一种基于学习的堆叠式 U-Net,称之为 DocUNet,可以平整和复原扭曲变形的文档图像。DocUNet 填补了深度学习领域的一项技术空白。由于平整变形文档图像的有效和效率,DocUNet 可大幅降低文字识别的难度,优化 OCR 技术发展,进而推动真实、网络等不同场景下的文本识别和检索能力,从底层技术的维度为办公自动化、智慧零售、无人超市甚至是自动驾驶的革新添砖加瓦、铺平道路。
设计思想
文档数字化是保存现有打印文档的一种重要方式,可以随时随地访问。传统方法借助平板式扫描仪数字化文档,但是不易携带,成本高昂。最近,随着移动摄像头日益增多,拍摄物理文档成为最便捷的一种文档扫描方式。一旦拍摄,图像可由文本检测和识别技术进一步处理,实现内容分析和信息提取。
拍摄文档图像常见的一个实际问题是文档页的扫描条件不理想:它们可能弯曲、折叠、弄皱,或者放在非常复杂的背景上。试想一张从钱包取出的褶皱收据。所有这些因素都可能为文档图像的自动分析流程带来严重问题,如图 1 所示。因此存在数字化平整拍摄图像中扭曲文档的需求。

图 1:文档图像的平整化及其用途。(a) 展示了本文工作的一些成果。上面是输入图像,下面是输出图像。(b) 本文网络显著提升了当前最优文本检测系统的效能:相较于上面的扭曲图像,下面的复原文档图像可以检测出更多单词(绿色)。
文档图像的平整化不是一个新问题,已有多种解决方案。一些视觉系统依赖于精心设计和校准的硬件,比如立体摄像头,或者结构光投影仪以测量文档的 3D 扭曲;它们表现很好,但额外的硬件限制了其应用;其他工作吸取这一教训,通过多视角图像重建扭曲文档图像的 3D 形状。一些人则致力于通过各种低层的手工特征(比如明暗度,文本行等)分析单一图像而复原文档图像。
本文给出一种基于学习的全新方法,来复原任意弯曲和折叠的文档拍摄图像。不同于先前方法,本文提出首个端到端学习方法,可以直接预测文档扭曲。先前方法只使用学习提取特征,而最后的图像复原仍基于传统的优化技术;本文方法则借助卷积神经网络(CNNs)端到端复原图像。相较于优化方法,前馈网络的测试表现非常抢眼。此外,如果具备合适的训练数据,这一数据驱动的方法还可以更好地泛化至其他文档类型(文本、数字、手写体等)。
该方法把这一问题转化为寻找合适的 2D 映射,以复原失真图像文档。它预测一个映射域,把扭曲的源图像 S(u, v) 中的像素移动到结果图像 D 中的 (x, y) 。
由此本文发现该任务与语义分割有一些共性;对于后者而言,网络为每个像素分配一类标签。相似地,本文网络则为每个像素分配一个 2D 向量。这启发作者在网络结构中使用语义分割领域家喻户晓的 U-Net 解决本文的回归问题,并定义一个全新的损失函数以驱动网络为 S 中的每个像素回归 D 中的坐标 (x, y)。
获取带有标签的海量数据是深度监督学习面临的首个挑战。为训练网络,作者需要扭曲程度不同的大量文档图像及相应的变形图像作为输入以实现完美复原。可惜目前这样的数据集不存在。获取真实的变形标签图像非常难,所以本文最后选择合成数据。通过随机扭曲平整的文档图像,本文合成了 100K 张图像,以便把扰动图像作为输入,而本文用来扭曲图像的网络则是旨在复原的逆变形。
同样也没有评估文档平整化的可用公共基准。先前方法要么在少量图像上进行评估,要么数据集只包含若干个扭曲类型。作者创作了一个包含 130 张图像的基准填补了这一空白,在文档类型、扭曲程度及类型以及拍摄条件方面差异巨大。
数据集
本文方法基于 CNN,需要大量训练数据。在该任务中,文档变形可以表征为 3D 网格、曲面法线、2D 流动等,在现实世界中以任意形式精确地拍摄它非常困难,需要诸如深度摄像头(range camera)或者标定立体视觉系统等额外硬件,同时预估变形的精确度通常依赖于硬件成本。此外,通过手动扭曲/变形文档文件以涵盖全部实际情形是很不现实的。
本文考虑使用合成数据进行训练,这在最近的深度学习中很常见,并允许完全掌控数据集的变化。
一个直观的想法是在 3D 渲染文档中直接渲染扭曲的文档,但由于下述原因这是不切实际的。首先,通过物理模拟生成物理上正确的 3D 网格非常难且慢。第二,通过路径追踪渲染同样非常费时。渲染 100K 图像耗时将超过两月。
2D 扭曲图像合成
本文直接合成 2D 训练图像。尽管已忽略基础的物理建模,但操纵 2D 网格相当简单,且生成图像也很快。由于本文目的是把扭曲纸张映射到复原纸张,因此数据合成是反向过程,即,把复原图像进行多种类型的扭曲。
当创建扭曲图时,本文遵循以下实证原则:i)一张真实的纸张是局部刚性的,不会延展或压缩。一点上的扭曲将带来空间上的改变。ii)存在两类扭曲:折叠和弯曲,分别产生纸张的折痕和卷曲。实际情形通常是这两类扭曲的结合。
本文首先搜集大量平整的数字文档,包括论文、书籍和杂志页面等;接着扭曲这些图像,如图 2 所示。
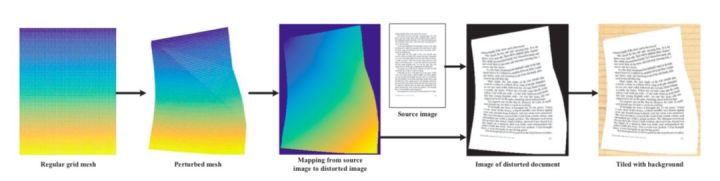
图 2:2D 合成扭曲文档图像。
扰动网格生成:给定图像 I,本文在其上放置一个 m x n 网格 M 以为扭曲提供控制点。在 M 上选择一个随机顶点 p 作为初始变形点。变形的方向和强度标记为 v,且也随机生成。最后,基于 i),v 通过权重 w 传播至其他顶点。扭曲网格上的顶点被计算为 p_i + wv, ∀i。
扰动图像生成:扰动网格提供一个稀疏的变形域。本文以线性方式对其进行插值,以从像素层面构建密集的扭曲图,接着把扭曲图应用到原始图像以生成扰动图像。作者通过这种方式在单块 CPU 上合成了 100K 张图像。每张图像最多包含 19 种合成变形(30% 是弯曲,70% 是折叠)。弯曲需要保证高斯曲率在任意位置都应为 0,折叠则随意。样本如图 5 所示。

图 5:合成数据中的样本图像。
DocUNet
网络架构
类似于语义分割,本文自行设计网络以强化逐像素的监督。出于其在语义分割任务上的简洁性和有效性,本文选择 U-Net 作为基础模型,它基本上是一个全卷积网络,包含一系列的下采样层和随后的上采样层,特征映射在上、下采样层之间连接。
但是,单一 U-Net 的输出并不令人满意,应该进行优化,因此在第一个 U-Net 的输出上堆叠另外一个 U-Net 作为 refiner。如图 3 所示。
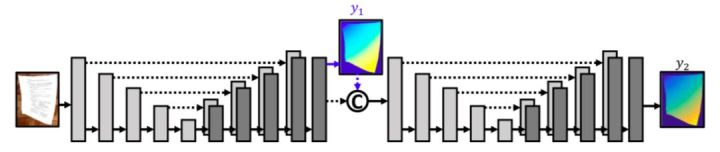
图 3:网络架构。该网络由两个 U-Net 堆叠而成。该网络从第一个 U-Net 的输出中分割和输出一个前向映射 y_1。应用在 y_2 的同一损失也应用在 y_1。接着 y_1 连接到第一个 U-Net 的输出特征映射,并作为第二个U-Net 的输入。y_2 可直接用于生成复原图像。
本文有一个层负责把去卷积特征转化为最后的输出 (x, y)。第一个 U-Net 在最后一个去卷积层之后分叉为两支。把第一个 U-Net 的去卷积特征和中间预测 y_1 连接起来作为第二个 U-Net 的输入。第二个 U-Net 最后给出一个优化的预测 y_2 ,作者将其用作网络的最后输出。本文在训练时把同一损失函数应用于 y_1 和 y_2。但是在测试时,只把 y_2 用作网络的输出。
不同于语义分割本质上是一个像素分类问题,该网络输出(为映射 F)的计算是一个回归的过程。语音分割的输出通常有 C 个通道,其中 C 是语义类别的数量。该网络只为 (x, y) 坐标输出 2 个通道。
损失函数
损失函数包含两个部分:1. 输出的映射 y 和其对应的 groundtruth 映射 y^star 之间的绝对误差(element-wise loss)。2. 输出的不同点的映射的相对位置 y_1 – y_2 和它们对应的 groundtruth 映射相对位置 y_1^star – y_2^star 之间的相对误差(shift invarient loss)。
其中绝对误差本文表示为:
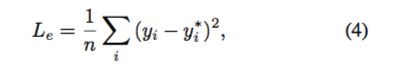
相对误差表示为:
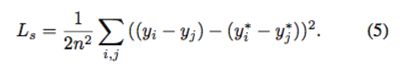
假设 d_i = y_i – y_i^star,Eq. 5 可表示为:
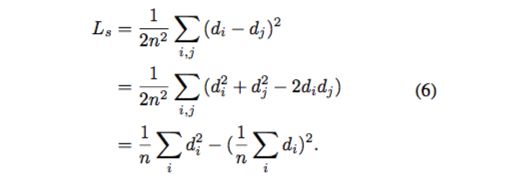
本文同时发现 L1 (Eq. 7)优于 L2(Eq. 6),因此损失函数可重写为:
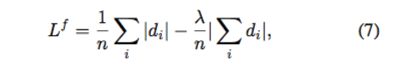
F 中与 S 的背景像素相对应的元素是常数 -1,因此 Eq. 7 中的部分损失来自背景。实际上网络没有必要把这些元素精确回归到 -1。任意负值都应该足够。因此本文把 hinge loss 用于背景像素:
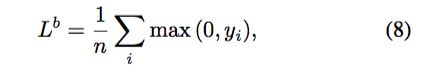
同时 Eq. 7 只用于前景像素。
实验
本文首先介绍评估单一图像上扭曲文档复原的基准;接着评估本文提出的基于学习的方法,并与先前非学习方法的结果作对比。
基准
图像:基准之中的图像是手机拍摄的物理纸张文档的图像。搜集 65 个各种内容/形式的纸张文档,其中每个文档拍照两张,共有 130 张图像。基准包含原始图像和剪裁框正的图像(document centered cropped images ),实验使用后者,因为本文的重点是平整化纸张而不是定位图像中的文档。基准的创建基于以下考量:
i)文档类型:选择的文档类型各不相同,有收据、信件、文件、杂志、论文、书籍等;
ii)扭曲:原始的平整纸张文档由不同的人进行物理扭曲;
iii)环境:图像由两个人用两部不同的手机在室内、室外不同的光照条件下拍摄。
Groundtruth:在折叠已选择的纸张文档之前,通过平板式扫描仪对其扫描。调整已获取图像的大小和整体颜色以尽可能地匹配原始的平整文档。图 6 是基准中的一些实例。

图 6:基准样本。
结果
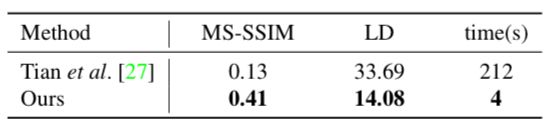
基准评估表明该方法优于先前的 Tian et al. [27]。具体而言,该方法的成绩在 MS-SSIM 和 LD 分别是 0.41 和 14.08,相比之下,[27] 的成绩分别为 0.13 和 33.69。这是因为 [27] 主要针对文本行文档而设计,严重依赖于文本行追踪的质量,因此无法处理更为复杂的文档,比如混合文本行和数字,或者文本行追踪失败的区域,如图 10 所示。

图 10:对比Tian et al. [27]。
在计算效率方面,[27] 借助 Matlab 实现在 1 块 CPU 处理 1 张图像耗时 3 到 4 分钟。相比之下,本文网络在 GTX 1080 Ti GPU 上的运行速度是 28 fps,虽然这种对比有点不公平。瓶颈在于从映射中生成复原图像。本文未优化的 Matlab 实现在 CPU 上大约耗时 3 到 4 秒。整体上该方法快 [27] 一个数量级,如下表所示:
更多对比结果请见图 8 和 图 9:

图 8:对比 You et al. [36]。尽管 [36] 使用 5 到 10 张图像,本文方法依然相当有竞争力。

图 9:对比 Das et al. [6]。[6] 的方法专门针对折叠两次的文档而设计。这种情况下本文方法同样表现良好。上图中的实例图像来自 [6]。
结论
本文展现了首个平整和复原扭曲文档图像的端到端神经网络。作者提出一个带有中间监督的堆叠式 U-Net,并对它进行端到端训练以直接预测可以移除图像扭曲的映射。作者还创建了合成训练数据,以及一个包含在各种条件下拍摄的真实图像的基准。实验结果证实了该方法的有效和效率。
在未来工作中,作者将应用 GAN 把这一网络更好地泛化至实际图像上,并希望加入亮度模型以移除复原图像上的高光或阴影。另一方面,作者还会优化从映射中生成复原图像的代码,并在移动端实现整个流程的实时部署。
参考文献
[6] S. Das, G. Mishra, A. Sudharshana, and R. Shilkrot. The Common Fold: Utilizing the Four-Fold to Dewarp Printed Documents from a Single Image. In Proceedings of the 2017 ACM Symposium on Document Engineering, DocEng ’17, pages 125–128. ACM, 2017.
[7] D. Eigen, C. Puhrsch, and R. Fergus. Depth map prediction from a single image using a multi-scale deep network. In Advances in Neural Information Processing Systems, 2014.
[21] G. Meng, Y. Wang, S. Qu, S. Xiang, and C. Pan. Active flattening of curved document images via two structured beams. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2014.
[25] O. Ronneberger, P. Fischer, and T. Brox. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer Assisted Intervention. Springer, 2015.
[27] Y. Tian and S. G. Narasimhan. Rectification and 3D recon- struction of curved document images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2011.
[28] Y.-C. Tsoi and M. S. Brown. Multi-view document rectification using boundary. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. IEEE, 2007.
[36] S.You,Y.Matsushita,S.Sinha,Y.Bou,andK.Ikeuchi.Multiview Rectification of Folded Documents. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2017.
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/127545.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
