大家好,又见面了,我是你们的朋友全栈君。
RF、GBDT、XGboost都可以做特征选择,属于特征选择中的嵌入式方法。比如在sklearn中,可以用属性feature_importances_去查看特征的重要度, 比如:
from sklearn import ensemble
#grd = ensemble.GradientBoostingClassifier(n_estimators=30)
grd = ensemble.RandomForestClassifier(n_estimators=30)
grd.fit(X_train,y_train)
grd.feature_importances_但是这三个分类器是如何计算出特征的重要度呢?下面来分别的说明一下。
1. 随机森林(Random Forest)
用袋外数据 (OOB) 做预测。随机森林在每次重抽样建立决策树时,都会有一些样本没有被选中,那么就可以用这些样本去做交叉验证,这也是随机森林的优点之一。它可以不用做交叉验证,直接用oob _score_去对模型性能进行评估。
具体的方法就是:
1. 对于每一棵决策树,用OOB 计算袋外数据误差,记为 errOOB1;
2. 然后随机对OOB所有样本的特征i加入噪声干扰,再次计算袋外数据误差,记为errOOB2;
3. 假设有N棵树,特征i的重要性为sum(errOOB2-errOOB1)/N;
如果加入随机噪声后,袋外数据准确率大幅下降,说明这个特征对预测结果有很大的影响,进而说明它的重要程度比较高
2. 梯度提升树(GBDT)
主要是通过计算特征i在单棵树中重要度的平均值,计算公式如下:

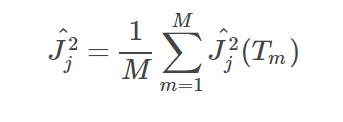
其中,M是树的数量。特征i在单棵树的重要度主要是通过计算按这个特征i分裂之后损失的减少值
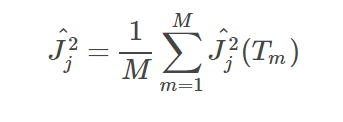
其中,L是叶子节点的数量,L-1就是非叶子结点的数量。
3. XGboost
XGboost是通过该特征每棵树中分裂次数的和去计算的,比如这个特征在第一棵树分裂1次,第二棵树2次……,那么这个特征的得分就是(1+2+…)。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/127541.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
