大家好,又见面了,我是你们的朋友全栈君。
一,hashmap数据结构。
数据结构中有数组和链表来实现对数据的存储,但是这两种方式的优点和缺点都很明显:
1,数组存储,它的存储区间是连续的,比较占内存,故空间复杂度高。但是利用二分法进行查找的话,效率高,时间复杂度为O(1)。其特点就是:存储区间连续,查找速度快,但是占内存严重,插入和删除就慢。
2,链表查询,它的存储区间离散,占内存比较宽松,故空间复杂度低,但时间复杂度高,为O(n)。其特点就是存储空间离散,空间复杂度低,插入和删除方便,但是时间复杂度高,导致查询比较慢。
综合以上两者的特点,就产生了一个时间复杂度低,占内存比较宽松,增删改查都比较方便的数据结构,也就是经常提到的哈希表。
哈希表最常用的实现方法就是拉链法,也可以理解为“链表的数组”。其模型大概如下图所示:

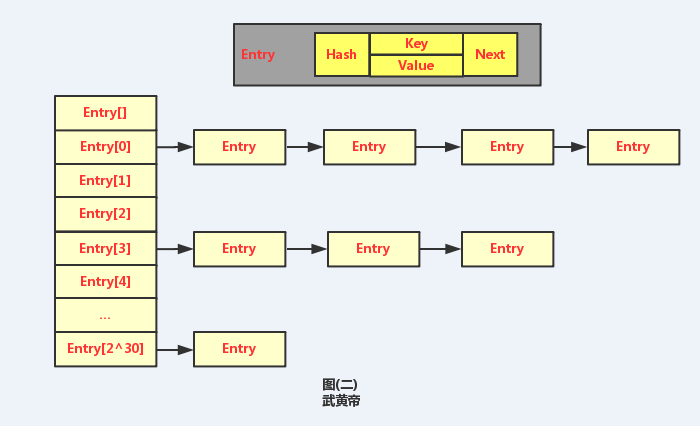
从上图中,比较容易看出,HashMap是Y轴方向是数组,X轴方向就是链表的存储方式。而每个数组的元素存储的都是链表的头结点。
那么这些元素是按照什么样的规则存储到数组中呢。一般情况是通过hash=index把链表和数组关联起来的,而hash=hash(key)%len获得,index就为数组的元素序列号,也就是元素的key的哈希值对数组长度取模得到。
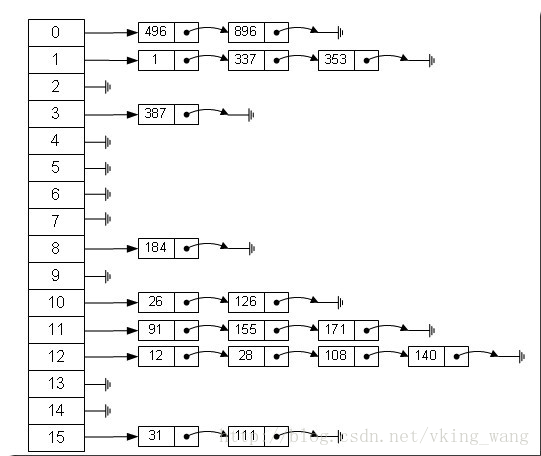
比如上述长度为16的哈希表中,链表元素中其key的hash值为的12有:12%16=12,28%16=12,108%16=12,140%16=12。所以12、28、108以及140都存储在index(数组下标)为12的位置。
二,Hashmap的存取实现
为什么说hashmap能随机进行存取呢?那是因为hashmap里有一个小小的算法,如下:
// 存储时:
int hash = key.hashCode(); // 这个hashCode方法这里不详述,只要理解每个key的hash是一个固定的int值
int index = hash % Entry[].length;
Entry[index] = value;
// 取值时:
int hash = key.hashCode();
int index = hash % Entry[].length;
return Entry[index];1)put
在存储的时候,万一多个个元素的hash值(也就是hash(key)%Entry[].length)都等于同一个index,这样会不会导致后面一个元素覆盖掉前一个元素呢?答案是不会的。从上面的例子中就可以看出,hash=12的有四个元素在index=12的那一行。其实数组中存储的就是最后插入的元素,该元素的next值的就是之前的那个元素,并不是覆盖掉。
2)get
通过传入的key,先找到Y轴index为hash(key)%Entry[].length 的数组元素,然后再遍厉该元素所处的链表。
3)null key的存取
null key总是存放在Entry[]数组的第一个元素。
4)确定数组index:hashcode % table.length取模
HashMap存取时,都需要计算当前key应该对应Entry[]数组哪个元素,即计算数组下标;算法如下:
/**
* Returns index for hash code h.
*/
static int indexFor(int h, int length) {
return h & (length-1);
}
按位取并,作用上相当于取模mod或者取余%。
这意味着数组下标相同,并不表示hashCode相同。
5)再散列rehash过程
当哈希表的容量超过默认容量时,必须调整table的大小。当容量已经达到最大可能值时,那么该方法就将容量调整到Integer.MAX_VALUE返回,这时,需要创建一张新表,将原表的映射到新表中。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/127531.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
