大家好,又见面了,我是你们的朋友全栈君。
什么是全文索引?
全文索引首先是 MySQL 的一种索引类型,也是搜索引擎的关键技术。
试想在1M大小的文件中搜索一个词,可能需要几秒,在100M的文件中可能需要几十秒,如果在更大的文件中搜索那么就需要更大的系统开销,这样的开销是不现实的。
所以在这样的矛盾下出现了全文索引技术,有时候有人叫倒排文档技术。
全文索引的作用是什么?
全文索引是将存储在数据库中的大段文本中的任意内容信息查找出来的技术。
既然是查找包含某些内容的文本,用 like + 通配符 或者正则表达式就可以实现模糊匹配,为什么还要全文索引?
- 性能:通配符和正则表达式匹配通常要求MySQL尝试匹配表中所有行(而且这些搜索极少使用表索引)。因此,由于被搜索行数不断增加,这些搜索可能非常耗时。
- 明确控制:使用通配符和正则表达式匹配,很难明确地控制匹配什么和不匹配什么。例如,指定一个词必须匹配,一个词必须不匹配;而一个词仅在第一个词确实匹配的情况下,才可以匹配或者才可以不匹配等。这些情况,使用通配符和正则表达式都不满足。
- 智能化的结果:虽然基于通配符和正则表达式的搜索提供了非常灵活的搜索方式,但它们都不能提供一种智能化的选择结果的方法。 例如,一个特殊词的搜索将会返回包含该词的所有行,而不区分包含单个匹配的行和包含多个匹配的行(按照可能是更好的匹配来排列它们)。类似,一个特殊词的搜索将不会找出不包含该词但 包含其他相关词的行。
所有这些限制以及更多的限制都可以用全文本搜索来解决。在使用全文本搜索时,MySQL不需要分别查看每个行,不需要分别分析和处理每个词,可以根据需要获取全文中有关章,节,段,句,词等信息,也可以进行各种统计和分析。MySQL创建指定列中各词的一个索引,搜索可以针对这些词进行。这样,MySQL可以快速有效地决定哪些词匹配(哪些行包含它们), 哪些词不匹配,它们匹配的频率,等等。
但是全文索引可能存在精度问题。
假如我们要搜索 胡歌很帅,拿百度来举个例子:
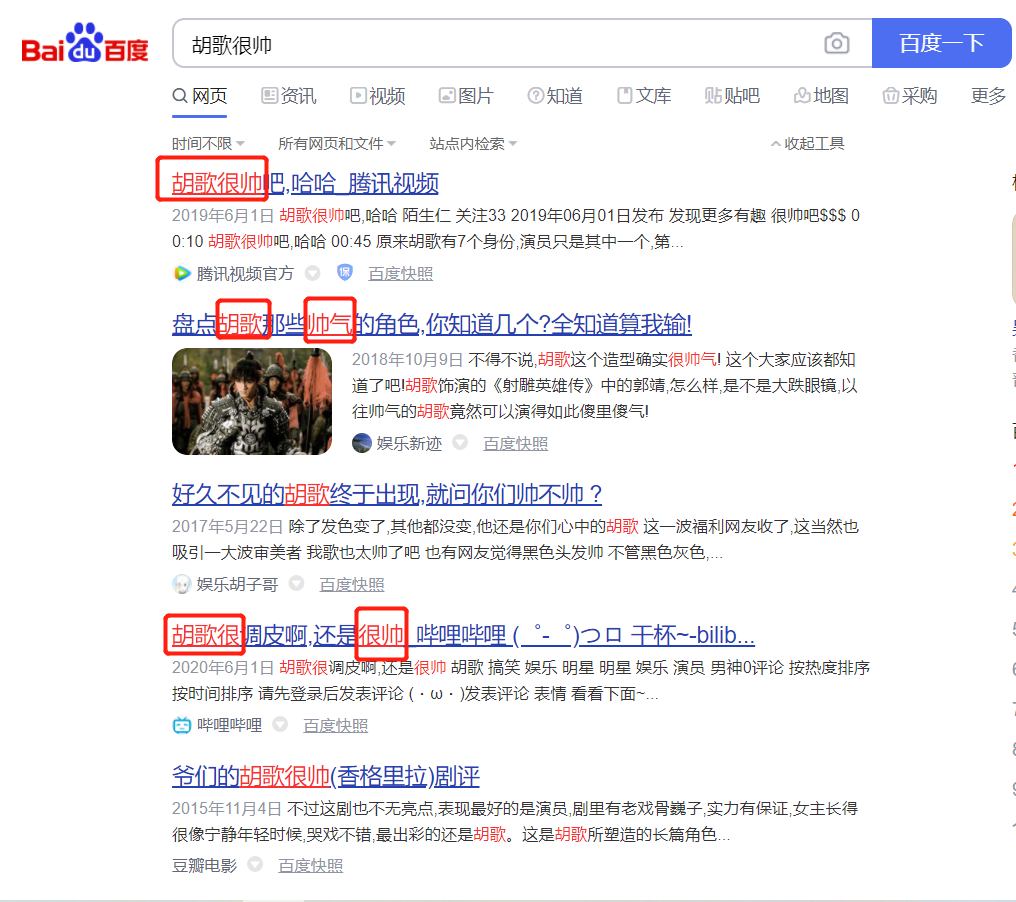

可以看到我明明搜索的是 ‘胡歌很帅’,但是百度搜索的关键字(标红的就是关键字)却不只是完整的 ‘胡歌很帅’,这一句话被分割为’胡歌’,‘很帅’,‘帅’,‘胡歌很’,’胡歌很帅’等,这就是全文索引里的分词机制,也是导致精度问题的原因。
版本支持
- MySQL 5.6 以前的版本,只有 MyISAM 存储引擎支持全文索引,InnoDB存储引擎并不支持全文索引技术,大多数的用户转向MyISAM存储引擎,虽然可以通过表的拆分,将进行全文索引的数据存储为MyIsam表,这样方式解决逻辑业务的需求,但是却丧失了INNODB存储引擎的事务性;
- MySQL 5.6 及以后的版本,MyISAM 和 InnoDB 存储引擎均支持全文索引;
- 只有字段的数据类型为 char、varchar、text 及其系列才可以建全文索引。
索引的创建、修改、删除
具体操作就不重复了,请看上一篇博客:MySQL索引系列:索引概述
使用全文索引
首先创建表,插入测试数据
create table test (
id int(11) unsigned not null auto_increment,
content text not null,
primary key(id),
fulltext key content_index(content)
) engine=Innodb default charset=utf8;
insert into test (content) values ('a'),('b'),('c');
insert into test (content) values ('aa'),('bb'),('cc');
insert into test (content) values ('aaa'),('bbb'),('ccc');
insert into test (content) values ('aaaa'),('bbbb'),('cccc');
按照全文索引的使用语法执行下面查询:
select * from test where match(content) against('a');
select * from test where match(content) against('aa');
select * from test where match(content) against('aaa');
# 使用完整的 Match() 说明传递给 Match() 的值必须与 FULLTEXT() 定义中的相同。如果指定多个列,则必须列
# 出它们(而且次序正确)。且搜索不区分大小写。
结果发现只有最后那条SQL有一条记录,为什么呢?
这个问题有很多原因,其中最常见的就是 最小搜索长度 导致的。另外插一句,使用全文索引时,测试表里至少要有 4 条以上的记录,否则,会出现意想不到的结果。
MySQL 中的全文索引,有两个变量,最小搜索长度和最大搜索长度,对于长度小于最小搜索长度和大于最大搜索长度的词语,都不会被索引。通俗点就是说,想对一个词语使用全文索引搜索,那么这个词语的长度必须在以上两个变量的区间内。
这两个的默认值可以使用以下命令查看
show variables like '%ft%';
可以看到这两个变量在 MyISAM 和 InnoDB 两种存储引擎下的变量名和默认值
// MyISAM
ft_min_word_len = 4;
ft_max_word_len = 84;
// InnoDB
innodb_ft_min_token_size = 3;
innodb_ft_max_token_size = 84;1234567
可以看到最小搜索长度 MyISAM 引擎下默认是 4,InnoDB 引擎下是 3,也即,MySQL 的全文索引只会对长度大于等于 4 或者 3 的词语建立索引,而刚刚搜索的只有 rabbit 的长度大于等于 3。
配置最小搜索长度
全文索引的相关参数都无法进行动态修改,必须通过修改 MySQL 的配置文件来完成。修改最小搜索长度的值为 1,首先打开 MySQL 的配置文件 /etc/my.cnf,在 [mysqld] 的下面追加以下内容
[mysqld]
innodb_ft_min_token_size = 1
然后重启 MySQL 服务器,并修复全文索引。注意,修改完参数以后,一定要修复下索引,不然参数不会生效。
两种修复方式,可以使用下面的命令修复
repair table productnotes quick;
或者直接删掉重新建立索引,再次执行上面的查询,就都可以查出来了。
全文搜索的分类
-
自然语言的全文搜索
-
布尔全文搜索
-
带查询扩展的全文搜索
MySQL必知必会
全文索引的原理
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/127476.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
