大家好,又见面了,我是你们的朋友全栈君。
转载自:https://www.jianshu.com/p/b468abd86f61
Hash表的结构图:
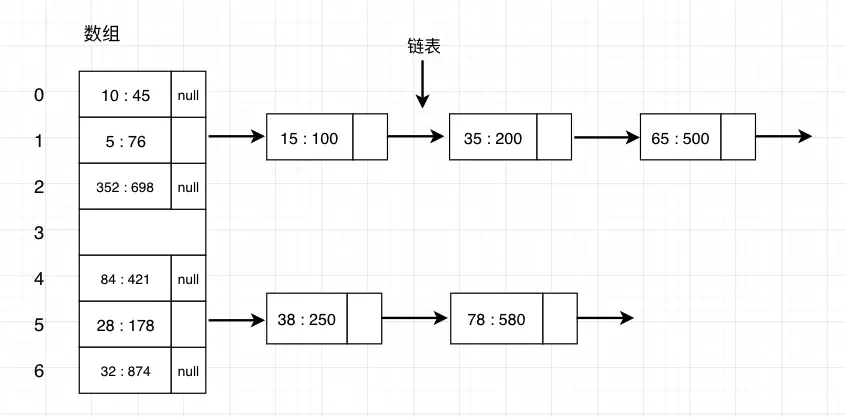

数组 + 链表
哈希表(Hash table,也叫散列表),是根据键(Key)而直接访问在内存存储位置的数据结构。也就是说,它通过计算一个关于键值的函数,将所需查询的数据映射到表中一个位置来访问记录,这加快了查找速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表
白话一点的说就是通过把Key通过一个固定的算法函数(hash函数)转换成一个整型数字,然后就对该数字对数组的长度进行取余,取余结果就当作数组的下标,将value存储在以该数字为下标的数组空间里。
当使用hash表查询时,就是使用hash函数将key转换成对应的数组下标,并定位到该下标的数组空间里获取value,这样就充分利用到数组的定位性能进行数据定位。
先了解一下下面几个常说的几个关键字是什么:
- key:我们输入待查找的值
- value:我们想要获取的内容
- hash值:key通过hash函数算出的值(对数组长度取模,便可得到数组下标)
- hash函数(散列函数):存在一种函数F,根据这个函数和查找关键字key,可以直接确定查找值所在位置,而不需要一个个遍历比较。这样就预先知道key在的位置,直接找到数据,提升效率。
即 - 地址index=F(key)
hash函数就是根据key计算出该存储地址的位置,hash表就是基于hash函数建立的一种查找表。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/127425.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
