大家好,又见面了,我是你们的朋友全栈君。
levelDB为什么需要版本控制
在一个使用levelDB的服务中,必然存在多个线程同时访问数据库的情况。例如,如果正好有thread2正在访问sstable4。与此同时,thread1在写数据时,发生了compaction,level0中的sstable1需要与level1中的sstable4进行compaction,这是thread1应该基于当前version,去产出一个新的version,以免线程之间的互相影响,保证数据的一致性。
level0: sstable1 sstable2
level1: sstable3 sstable4 sstable5
FileMetaDatas类
FileMetaDatas是对每个本次磁盘文件sstable的描述,是磁盘文件和version的桥梁。而 version是词表文件和数据之间的桥梁。
之前我们在LevelDB-总体介绍 中提到一个疑问,levelDB是将磁盘文件以层的结构存在,那么哪里维护这个层结构呢,其实就是在Version类中。
FileMetaDatas 中记录着文件的名字,文件所占的字节大小,文件的最小InternalKey和最大的InternalKey以及有多少线程正在使用该文件。
版本控制
levelDB中,版本控制涉及的类有Version 、 VersionSet 、VersionEdit 以及 Build,他们之间的关系如下:
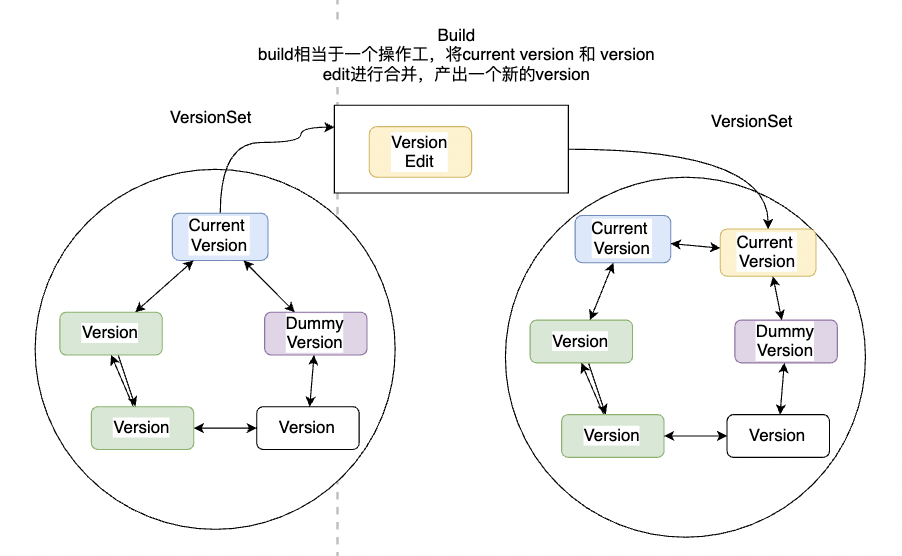

VersionSet 中维护一个双向链表,其中每一个节点为Version对象。在version类中,维护着一系列指向FileMetaData的指针。levelDB中任何对磁盘sstable的修改/增加/删除,首先将变更生成一个 VersionEdit 对象,然后基于Build类,生成一个新的Version,存储到VersionSet维护的双向链表中。
即 Version + VersionEdit = New Version,其中 += 操作由Build类完成。
首先明确一点:什么时候会发生版本变更:
就是在发生compaction的时候,在levelDB中compaction的类型有:
- minor compaction : immutable 到 sstable,不一定一定会落盘到level0层;
- size compaction :
- seek compaction:
本文着重讲解一下minor compaction。具体如何实现呢,下面简化LevelDB中的源码,大致讲一下这个过程:
// 首先初始化一个文件元信息
FileMetaData meta;
// memtbale的迭代器
Iterator* iter = mem->NewIterator();
// 真正地向磁盘写一个sstable,这时候,并不知道该sstable应该放到第几层
s = BuildTable(dbname_, env_, options_, table_cache_, iter, &meta);
// base 指向当前version
Version* base = ....;
// 判断刚才写入的sstable应该放到第几层中
level = base->PickLevelForMemTableOutput(min_user_key, max_user_key);
// 将SSTable文件序列号对应的层,Key等信息写入manifest中
edit->AddFile(level, meta.number, meta.file_size, meta.smallest,
meta.largest);
Version* v = new Version(this);
{
Builder builder(this, current_);
builder.Apply(edit);
builder.SaveTo(v);
}
VersionEdit 类
minor compaction的第一步就是将immutable转换成VersionEdit。
VersionEdit类是保存变更的类。其中有两个特别重要的类成员deleted_files_, new_files_。
new_files_ 记录新增sstable磁盘文件,采用pair结构记录,第一个参数记录的level,即放在第几层中,第二个记录的文件的元信息;
deleted_files_ 记录的是删除 第几层的那个sstable。
typedef std::set<std::pair<int, uint64_t>> DeletedFileSet;
// 和VersionSet里面的compact_pointers_相同
std::vector<std::pair<int, InternalKey>> compact_pointers_;
// 有哪些文件被删除,就是Version里哪些SSTable被删除
DeletedFileSet deleted_files_;
// 有哪些文件被增加,pair的第一个参数是Level,第二个参数是文件的元信息
std::vector<std::pair<int, FileMetaData>> new_files_;
Version类
Version其实很好理解,就是记录着当前版本有那些文件,并且记录这些文件的层级结构。
class Version {
public:
...
Status Get(const ReadOptions&, const LookupKey& key, std::string* val,
GetStats* stats);
bool UpdateStats(const GetStats& stats);
bool RecordReadSample(Slice key);
// Reference count management (so Versions do not disappear out from
// under live iterators)
void Ref();
void Unref();
... ...
// Return the level at which we should place a new memtable compaction
// result that covers the range [smallest_user_key,largest_user_key].
/* 该函数用来选择 需要将从MemTable dump出的sstable file放入第几层*/
int PickLevelForMemTableOutput(const Slice& smallest_user_key,
const Slice& largest_user_key);
/*判断某层level的文件个数*/
int NumFiles(int level) const {
return files_[level].size(); }
// Return a human readable string that describes this version's contents.
std::string DebugString() const;
private:
friend class Compaction;
friend class VersionSet;
class LevelFileNumIterator;
explicit Version(VersionSet* vset)
: vset_(vset),
next_(this),
prev_(this),
refs_(0),
file_to_compact_(nullptr),
file_to_compact_level_(-1),
compaction_score_(-1),
compaction_level_(-1) {
}
Version(const Version&) = delete;
Version& operator=(const Version&) = delete;
~Version();
Iterator* NewConcatenatingIterator(const ReadOptions&, int level) const;
void ForEachOverlapping(Slice user_key, Slice internal_key, void* arg,
bool (*func)(void*, int, FileMetaData*));
/*所有的version都属于一个集合即Version Set*/
VersionSet* vset_; // VersionSet to which this Version belongs
Version* next_; // Next version in linked list
Version* prev_; // Previous version in linked list
int refs_; // Number of live refs to this version
// SSTable的信息,每一项代表相应Level的SSTable信息
// 除了Level 0外,每个Level里的文件都是按照最小键的顺序排列的,并且没有重叠
// 通过这个数据项,搜索SSTable时,就可以从Level 0开始搜索
std::vector<FileMetaData*> files_[config::kNumLevels];
// Next file to compact based on seek stats.
FileMetaData* file_to_compact_; // 哪个文件需要 seek compaction
int file_to_compact_level_; // seek compaction 发生在哪一层中
double compaction_score_; // 所有level层中 最大的compaction core
int compaction_level_; // size compaction 发生在哪一层中
};
/** 判断以smallest_user_key为最小值,larget_user_key为最大只的sstable应该放到当前version的第几层 **/
int Version::PickLevelForMemTableOutput(const Slice& smallest_user_key,
const Slice& largest_user_key) {
int level = 0;
if (!OverlapInLevel(0, &smallest_user_key, &largest_user_key)) {
// Push to next level if there is no overlap in next level,
// and the #bytes overlapping in the level after that are limited.
InternalKey start(smallest_user_key, kMaxSequenceNumber, kValueTypeForSeek);
InternalKey limit(largest_user_key, 0, static_cast<ValueType>(0));
std::vector<FileMetaData*> overlaps;
while (level < config::kMaxMemCompactLevel) {
if (OverlapInLevel(level + 1, &smallest_user_key, &largest_user_key)) {
break;
}
if (level + 2 < config::kNumLevels) {
// Check that file does not overlap too many grandparent bytes.
GetOverlappingInputs(level + 2, &start, &limit, &overlaps);
const int64_t sum = TotalFileSize(overlaps);
if (sum > MaxGrandParentOverlapBytes(vset_->options_)) {
break;
}
}
level++;
}
}
return level;
}
疑问:
为什么在Version类中,将VersionSet设置为友元,设置一个成员变量VersionSet* vset_?
我的理解: 所有一系列的Version构成了VersionSet,那么一个Version归属于那个VersionSet呢?就用这个成员对象进行记录。并且在Version的成员函数中需要使用VersionSet的私有变量,所以将VersionSet设置为友元。
下面重点讲解一下 Version::PickLevelForMemTableOutput 函数。在 immutable落盘sstable时,即 minor compaction 时使用。作用是判断新增sstable需要放在哪一层中。该函数的流程图如下所示:
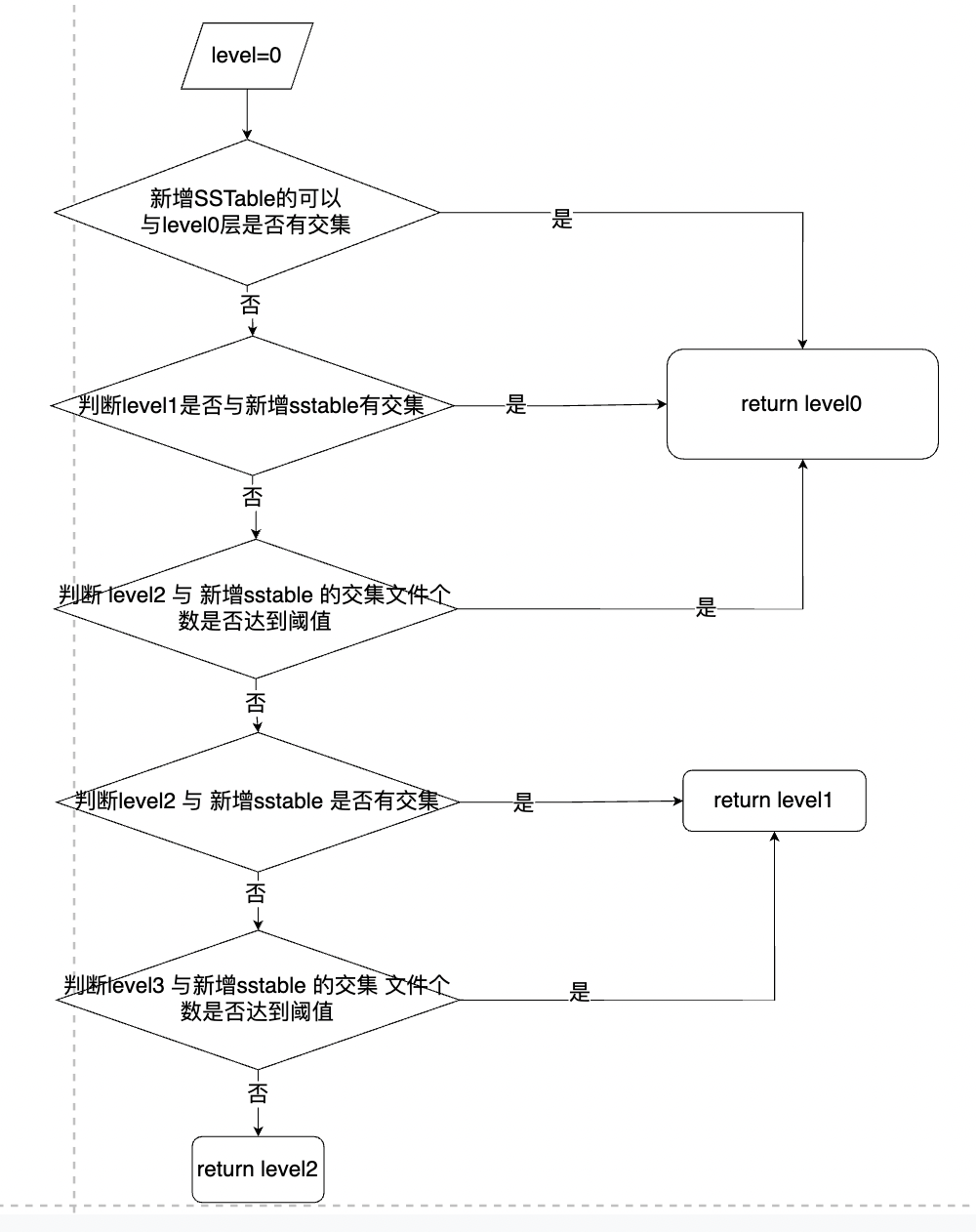
首先读者要知道两点:
- 在levelDB中,level0的数据要比level1中的数据新,level1中的数据 要比level2中的数据新;
- level0中的sstable之间,key是可以有交集的,level1 … leveln中的sstable之间key之间是没有交集的。
回到 PickLevelForMemTableOutput 函数,下面详细说一下具体流程:
- 首先判断新增sstable是否与level0有交集,如果有交集,直接插入到level0中。
- 如果新增sstable与level1 没有交集,并且与level2中有交集的sstable个数小于阈值,则可以插入到level1中;
- 如果新增sstable与level2 没有交集,并且与level3中有交集的sstable个数小于阈值,则插入到level2中;
从流程图中可以看出来,新增sstable最多就插入到level2中;提问1:拿level1来举例子,为什么不光要判断是否与level1有交集,还要判断与level2的交集文件个数呢?
答案:首先对于>level1的层,层中的sstable之间是无交集的。所以第一个判断很好理解;第二个判断是问了降低size compaction的成本;假设new sstable插入到level1中,但与level2中的交集有10个(很多了)。当new sstable需要进行size compaction时,那么compaction的文件就可能达到>15个,那么本次size compaction的成本就相当高了。
VersionSet类
到这里,我们已经基于immutable生成了VersionEdit对象,并生成了 new version。那么现在,我们需要将new version应用起来。即让levelDB感知到新增的version。
这里只介绍添加VersionEdit对象的函数LogAndApply。 VersionSet类的具体细节后面再加,因为现在我也不太清楚,嘻嘻嘻
Status VersionSet::LogAndApply(VersionEdit* edit, port::Mutex* mu) {
if (edit->has_log_number_) {
assert(edit->log_number_ >= log_number_);
assert(edit->log_number_ < next_file_number_);
} else {
edit->SetLogNumber(log_number_);
}
if (!edit->has_prev_log_number_) {
edit->SetPrevLogNumber(prev_log_number_);
}
edit->SetNextFile(next_file_number_);
edit->SetLastSequence(last_sequence_);
// 以上内容 我也没太明白
Version* v = new Version(this);
{
Builder builder(this, current_);
builder.Apply(edit);
builder.SaveTo(v);
}
// 计算版本 v 中,compaction score
// 到这里,新的version已经构造完毕
Finalize(v);
// Initialize new descriptor log file if necessary by creating
// a temporary file that contains a snapshot of the current version.
std::string new_manifest_file;
Status s;
if (descriptor_log_ == nullptr) {
// No reason to unlock *mu here since we only hit this path in the
// first call to LogAndApply (when opening the database).
assert(descriptor_file_ == nullptr);
new_manifest_file = DescriptorFileName(dbname_, manifest_file_number_);
edit->SetNextFile(next_file_number_);
s = env_->NewWritableFile(new_manifest_file, &descriptor_file_);
if (s.ok()) {
descriptor_log_ = new log::Writer(descriptor_file_);
s = WriteSnapshot(descriptor_log_);
}
}
// Unlock during expensive MANIFEST log write
// 日志操作
{
...
}
// Install the new version
if (s.ok()) {
AppendVersion(v);
log_number_ = edit->log_number_;
prev_log_number_ = edit->prev_log_number_;
} else {
delete v;
if (!new_manifest_file.empty()) {
delete descriptor_log_;
delete descriptor_file_;
descriptor_log_ = nullptr;
descriptor_file_ = nullptr;
env_->RemoveFile(new_manifest_file);
}
}
return s;
}
// A helper class so we can efficiently apply a whole sequence
// of edits to a particular state without creating intermediate
// Versions that contain full copies of the intermediate state.
class VersionSet::Builder {
private:
// Helper to sort by v->files_[file_number].smallest
struct BySmallestKey {
const InternalKeyComparator* internal_comparator;
bool operator()(FileMetaData* f1, FileMetaData* f2) const {
int r = internal_comparator->Compare(f1->smallest, f2->smallest);
if (r != 0) {
return (r < 0);
} else {
// Break ties by file number
return (f1->number < f2->number);
}
}
};
typedef std::set<FileMetaData*, BySmallestKey> FileSet;
struct LevelState {
std::set<uint64_t> deleted_files;
FileSet* added_files;
};
VersionSet* vset_;
Version* base_;
LevelState levels_[config::kNumLevels];
public:
// Initialize a builder with the files from *base and other info from *vset
// 根据VersionSet,构造internal的比较函数;
// 构造磁盘level结构
Builder(VersionSet* vset, Version* base) : vset_(vset), base_(base) {
base_->Ref();
BySmallestKey cmp;
cmp.internal_comparator = &vset_->icmp_;
for (int level = 0; level < config::kNumLevels; level++) {
levels_[level].added_files = new FileSet(cmp);
}
}
~Builder() {
for (int level = 0; level < config::kNumLevels; level++) {
const FileSet* added = levels_[level].added_files;
std::vector<FileMetaData*> to_unref;
to_unref.reserve(added->size());
for (FileSet::const_iterator it = added->begin(); it != added->end();
++it) {
to_unref.push_back(*it);
}
delete added;
for (uint32_t i = 0; i < to_unref.size(); i++) {
FileMetaData* f = to_unref[i];
f->refs--;
if (f->refs <= 0) {
delete f;
}
}
}
base_->Unref();
}
// Apply all of the edits in *edit to the current state.
// 应用VersionEdit对象中的所有记录,填充Builder构造函数中 构造出来的层结构
void Apply(VersionEdit* edit) {
// Update compaction pointers
// 这块不知道干嘛用的,需要再看 TODO
for (size_t i = 0; i < edit->compact_pointers_.size(); i++) {
const int level = edit->compact_pointers_[i].first;
vset_->compact_pointer_[level] =
edit->compact_pointers_[i].second.Encode().ToString();
}
// Delete files
for (const auto& deleted_file_set_kvp : edit->deleted_files_) {
const int level = deleted_file_set_kvp.first;
const uint64_t number = deleted_file_set_kvp.second;
levels_[level].deleted_files.insert(number);
}
// Add new files
for (size_t i = 0; i < edit->new_files_.size(); i++) {
const int level = edit->new_files_[i].first;
FileMetaData* f = new FileMetaData(edit->new_files_[i].second);
f->refs = 1;
// We arrange to automatically compact this file after
// a certain number of seeks. Let's assume:
// (1) One seek costs 10ms
// (2) Writing or reading 1MB costs 10ms (100MB/s)
// (3) A compaction of 1MB does 25MB of IO:
// 1MB read from this level
// 10-12MB read from next level (boundaries may be misaligned)
// 10-12MB written to next level
// This implies that 25 seeks cost the same as the compaction
// of 1MB of data. I.e., one seek costs approximately the
// same as the compaction of 40KB of data. We are a little
// conservative and allow approximately one seek for every 16KB
// of data before triggering a compaction.
f->allowed_seeks = static_cast<int>((f->file_size / 16384U));
if (f->allowed_seeks < 100) f->allowed_seeks = 100;
levels_[level].deleted_files.erase(f->number);
levels_[level].added_files->insert(f);
}
}
// Save the current state in *v.
void SaveTo(Version* v) {
BySmallestKey cmp;
cmp.internal_comparator = &vset_->icmp_;
for (int level = 0; level < config::kNumLevels; level++) {
// Merge the set of added files with the set of pre-existing files.
// Drop any deleted files. Store the result in *v.
const std::vector<FileMetaData*>& base_files = base_->files_[level];
std::vector<FileMetaData*>::const_iterator base_iter = base_files.begin();
std::vector<FileMetaData*>::const_iterator base_end = base_files.end();
const FileSet* added_files = levels_[level].added_files;
v->files_[level].reserve(base_files.size() + added_files->size());
for (const auto& added_file : *added_files) {
// Add all smaller files listed in base_
for (std::vector<FileMetaData*>::const_iterator bpos =
std::upper_bound(base_iter, base_end, added_file, cmp);
base_iter != bpos; ++base_iter) {
MaybeAddFile(v, level, *base_iter);
}
MaybeAddFile(v, level, added_file);
}
// Add remaining base files
for (; base_iter != base_end; ++base_iter) {
MaybeAddFile(v, level, *base_iter);
}
#ifndef NDEBUG
// Make sure there is no overlap in levels > 0
if (level > 0) {
for (uint32_t i = 1; i < v->files_[level].size(); i++) {
const InternalKey& prev_end = v->files_[level][i - 1]->largest;
const InternalKey& this_begin = v->files_[level][i]->smallest;
if (vset_->icmp_.Compare(prev_end, this_begin) >= 0) {
std::fprintf(stderr, "overlapping ranges in same level %s vs. %s\n",
prev_end.DebugString().c_str(),
this_begin.DebugString().c_str());
std::abort();
}
}
}
#endif
}
}
void MaybeAddFile(Version* v, int level, FileMetaData* f) {
if (levels_[level].deleted_files.count(f->number) > 0) {
// File is deleted: do nothing
} else {
std::vector<FileMetaData*>* files = &v->files_[level];
if (level > 0 && !files->empty()) {
// Must not overlap
assert(vset_->icmp_.Compare((*files)[files->size() - 1]->largest,
f->smallest) < 0);
}
f->refs++;
files->push_back(f);
}
}
};
提问的时间到了。
问题1: 为什么Builder类要设计在VersionSet类内?
答案:Builder是在VersionSet的private中声明的,Builder就作用就是将一些函数再次封装,使得整体代码,看起来更加整洁。这些函数只会在VersionSet类函数中使用。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/127336.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
