大家好,又见面了,我是你们的朋友全栈君。
本文讲的是利用nodejs以及相关库,爬取JRS爆照区内的爆照贴,并保存相关数据到本地。
依赖选择
const superagent = require('superagent');
//nodejs里一个非常方便的客户端请求代理模块
const cheerio = require('cheerio');
//Node.js 版的jQuery
const async = require('async');
const fs = require('fs');
//fs操作IO
const url = require('url');
//url模块
初步准备
既然是要爬取网站内容,那我们就应该先去看看网站的基本构成
选取的是BXJ作为目标网站,想要去爬取爆照区的前5页的帖子里的数据
分析页面
要爬取前5个分页的内容,就要先找到分页的规律
先进入自行查看分页规律
可以看出,页面都是以 https://bbs.hupu.com/selfie- 加上1/2/3/4/5 作为分页
找到了分页规律,继续去第一页找帖子入口
页面结构如下:

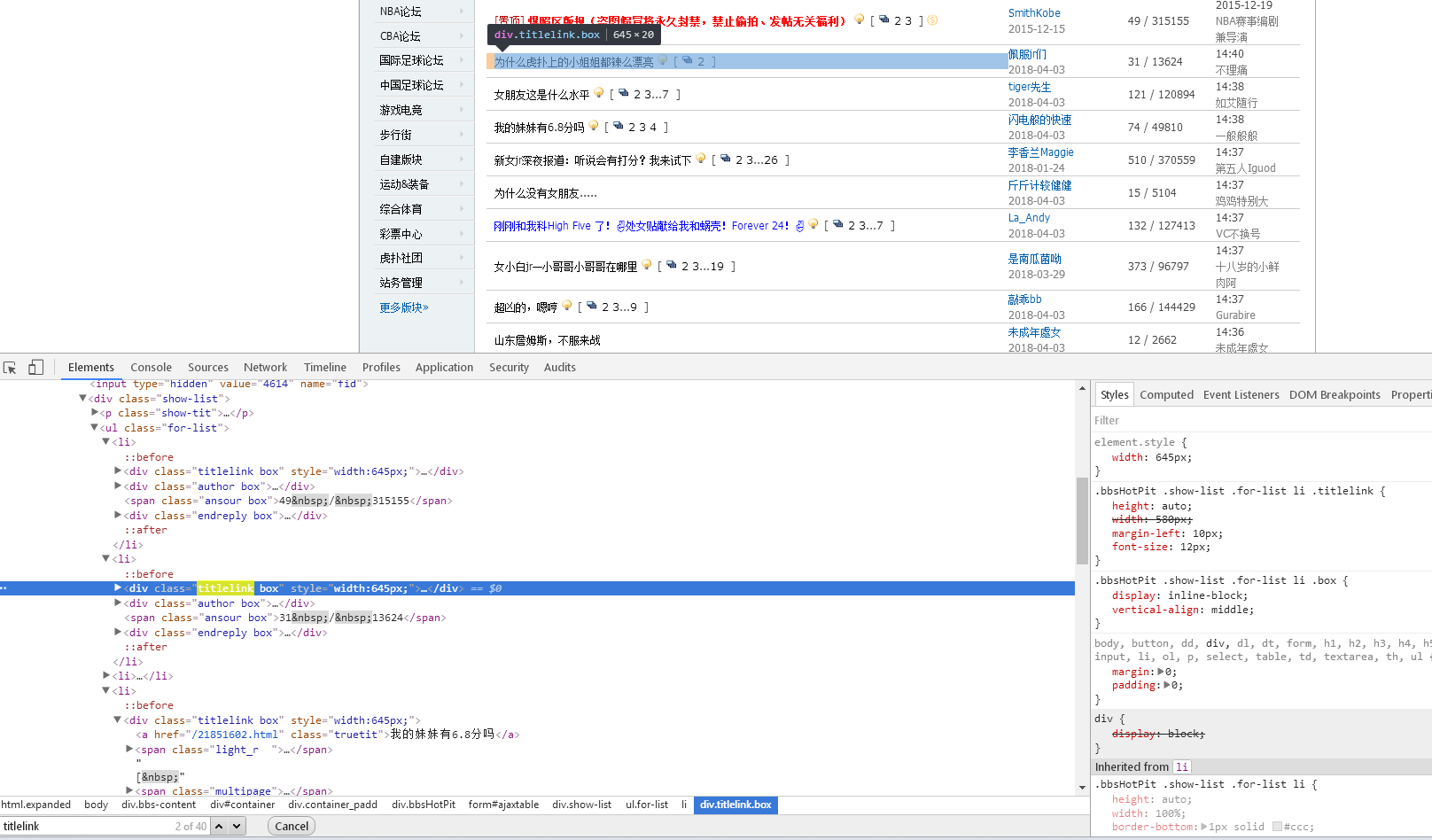
可以看到,每个class为titlelink下的第一个a标签元素是帖子的路径
再进入到帖子内部
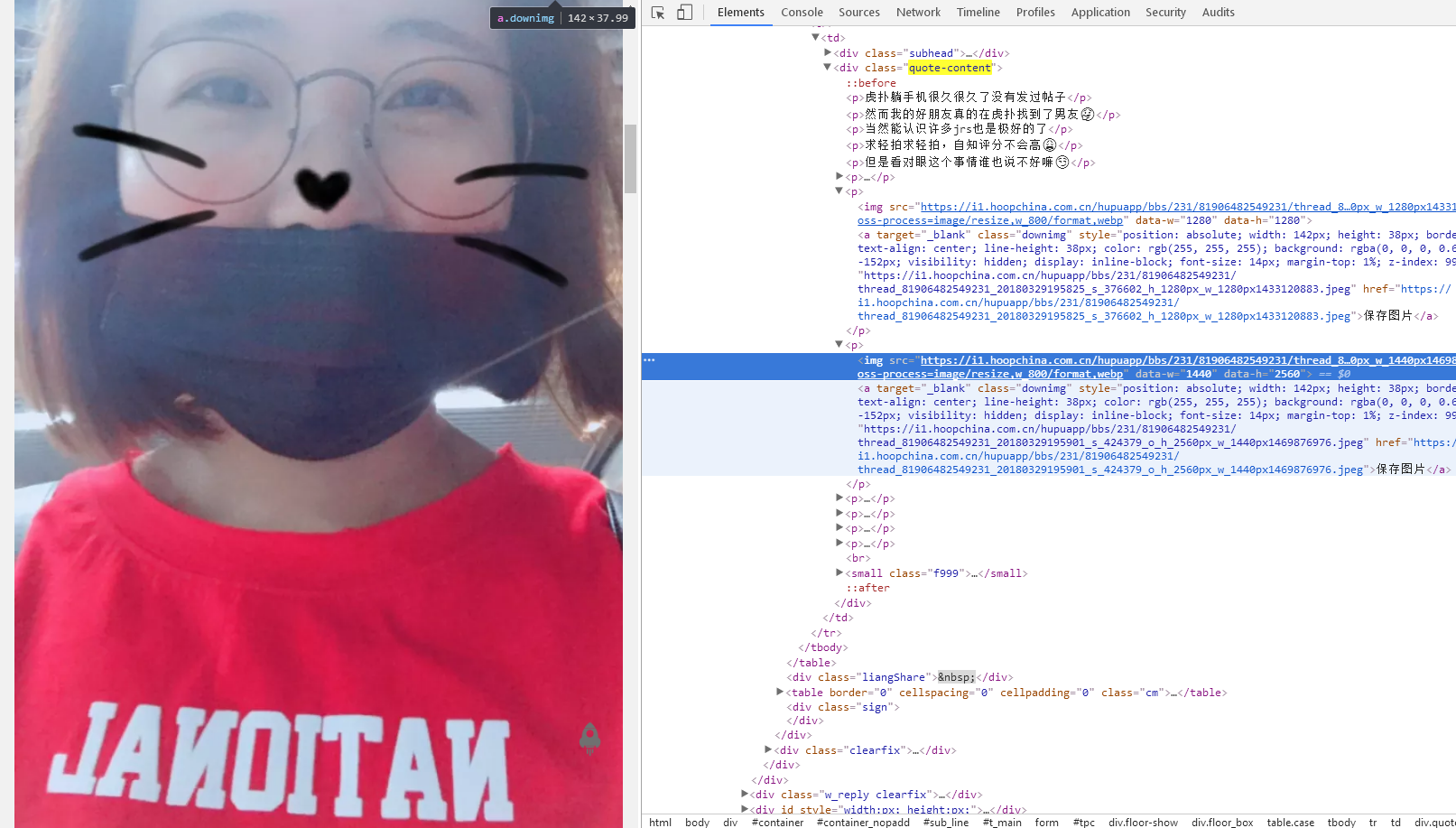
可以发现相关数据都是有对应的关系的,以下我总结一下
标题:bbs-hd-h1>h1
头像:headpic:first-child>img
用户ID:j_u
正文图片:quote-content>p>img
ok,有了以上这些信息,可以开工了。
开始编码
const superagent = require('superagent');
const cheerio = require('cheerio');
const async = require('async');
const fs = require('fs');
const url = require('url');
const request =require('request');
const hupuUrl = 'https://bbs.hupu.com/selfie-1';
let ssr = [];
let allUrl = [];
let curCount = 0;
for (let i = 1; i <= 4; i++) {
hupuUrl2 = 'https://bbs.hupu.com/selfie-' + i;
//for循环把五页的页面循环出来
superagent.get(hupuUrl2)
//通过superagent去请求每一页
.end(function (err, res) {
if (err) {
return console.error(err);
}
//cheerio nodejs版的JQ
let $ = cheerio.load(res.text);
//获取首页所有的链接
$('.titlelink>a:first-child').each(function (idx, element) {
let $element = $(element);
let href = url.resolve(hupuUrl2, $element.attr('href'));
allUrl.push(href);
curCount++;
//获取到此url,异步进行以下操作,此操作为进入到这个帖子中爬取数据
superagent.get(href)
.end(function (err, res) {
if(err){
return console.error(err);
}
let $ = cheerio.load(res.text);
let add = href;
let title = $('.bbs-hd-h1>h1').attr('data-title');//帖子标题
let tximg = $('.headpic:first-child>img').attr('src');//用户头像
let txname = $('.j_u:first-child').attr('uname');//用户ID
let contentimg1 = $('.quote-content>p:nth-child(1)>img').attr('src');//爆照图1
let contentimg2 = $('.quote-content>p:nth-child(2)>img').attr('src');//爆照图2
let contentimg3 = $('.quote-content>p:nth-child(3)>img').attr('src');//爆照图3
ssr.push({
'tx': tximg,
'name': txname,
'pic': contentimg1,contentimg2,contentimg3
});
//把数据存储到一个对象里
let stad = {
"address": add,
"title":title,
"ID" : txname,
"touxiang" : tximg,
"pic1" : contentimg1,
"pic2" : contentimg2,
"pic3" : contentimg3
};
let picArr = [contentimg1,contentimg2,contentimg3];
//console.log(stad);
//通过fs模块把数据写入本地json
fs.appendFile('data/result1.json', JSON.stringify(stad) ,'utf-8', function (err) {
if(err) throw new Error("appendFile failed...");
//console.log("数据写入success...");
});
//定义一个以title为文件夹名的路径,作为以后下载图片时使用
let lujin = 'data/' + title + '/';
//判断文件夹是否存在
fs.exists('data/111',function (exists) {
if(!exists){
fs.mkdir("data/111", function(err) {
if (err) {
throw err;
}
async.mapSeries(picArr,function(item, callback){
setTimeout(function(){
//downloadPic方法下载图片
downloadPic(item, 'data/'+ (new Date()).getTime() +'.jpg');
callback(null, item);
},400);
}, function(err, results){});
});
console.log('ye')
}else {
console.log('er')
}
})
})
});
});
}完成
(以上代码整洁性非常差,随手写下,欢迎大神滋醒)
最终效果
看一下存储的json对象
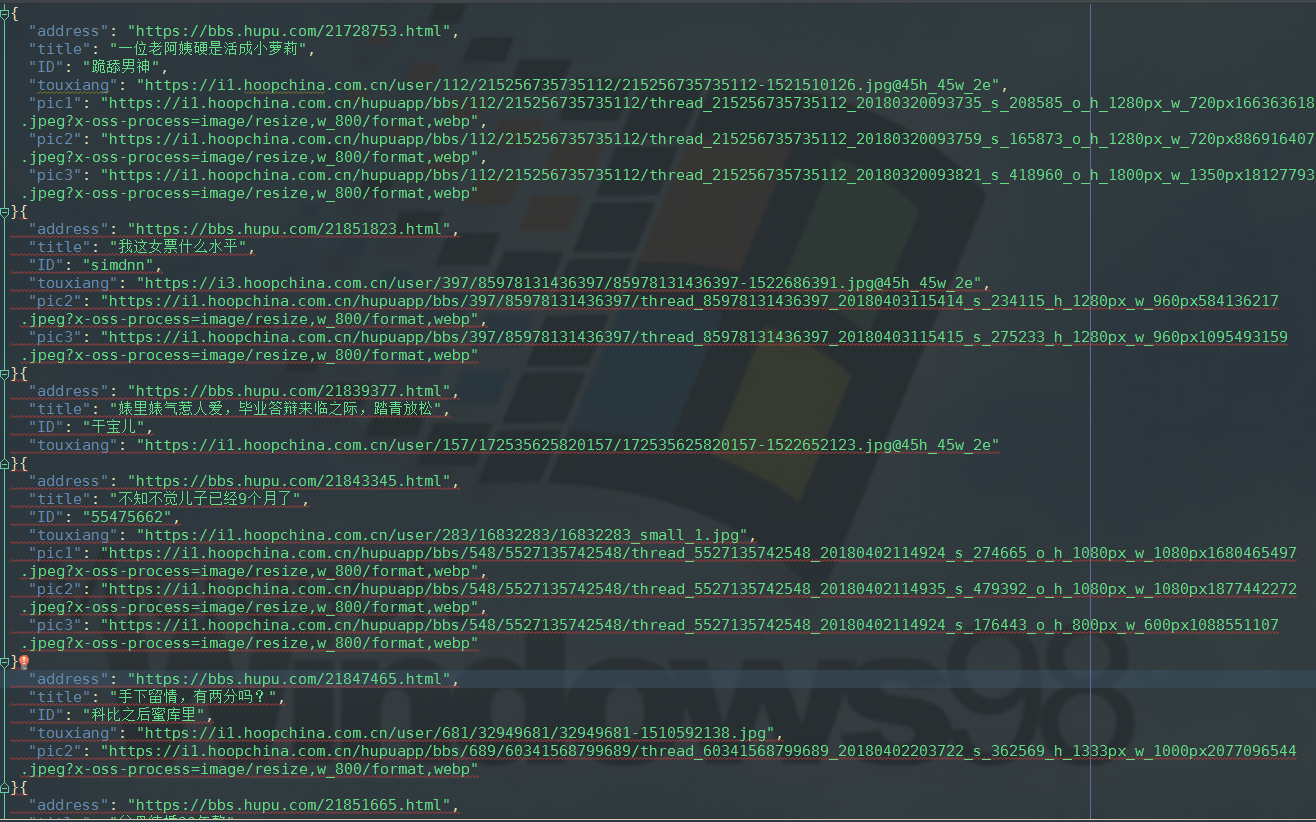
{
"address": "https://bbs.hupu.com/21728753.html",
"title": "一位老阿姨硬是活成小萝莉",
"ID": "跪舔男神",
"touxiang": "https://i1.hoopchina.com.cn/user/112/215256735735112/215256735735112-1521510126.jpg@45h_45w_2e",
"pic1": "https://i1.hoopchina.com.cn/hupuapp/bbs/112/215256735735112/thread_215256735735112_20180320093735_s_208585_o_h_1280px_w_720px1663636189.jpeg?x-oss-process=image/resize,w_800/format,webp",
"pic2": "https://i1.hoopchina.com.cn/hupuapp/bbs/112/215256735735112/thread_215256735735112_20180320093759_s_165873_o_h_1280px_w_720px886916407.jpeg?x-oss-process=image/resize,w_800/format,webp",
"pic3": "https://i1.hoopchina.com.cn/hupuapp/bbs/112/215256735735112/thread_215256735735112_20180320093821_s_418960_o_h_1800px_w_1350px1812779326.jpeg?x-oss-process=image/resize,w_800/format,webp"
},
{
"address": "https://bbs.hupu.com/21851823.html",
"title": "我这女票什么水平",
"ID": "simdnn",
"touxiang": "https://i3.hoopchina.com.cn/user/397/85978131436397/85978131436397-1522686391.jpg@45h_45w_2e",
"pic2": "https://i1.hoopchina.com.cn/hupuapp/bbs/397/85978131436397/thread_85978131436397_20180403115414_s_234115_h_1280px_w_960px584136217.jpeg?x-oss-process=image/resize,w_800/format,webp",
"pic3": "https://i1.hoopchina.com.cn/hupuapp/bbs/397/85978131436397/thread_85978131436397_20180403115415_s_275233_h_1280px_w_960px1095493159.jpeg?x-oss-process=image/resize,w_800/format,webp"
},
{
"address": "https://bbs.hupu.com/21839377.html",
"title": "婊里婊气惹人爱,毕业答辩来临之际,踏青放松",
"ID": "干宝儿",
"touxiang": "https://i1.hoopchina.com.cn/user/157/172535625820157/172535625820157-1522652123.jpg@45h_45w_2e"
},
{
"address": "https://bbs.hupu.com/21843345.html",
"title": "不知不觉儿子已经9个月了",
"ID": "55475662",
"touxiang": "https://i1.hoopchina.com.cn/user/283/16832283/16832283_small_1.jpg",
"pic1": "https://i1.hoopchina.com.cn/hupuapp/bbs/548/5527135742548/thread_5527135742548_20180402114924_s_274665_o_h_1080px_w_1080px1680465497.jpeg?x-oss-process=image/resize,w_800/format,webp",
"pic2": "https://i1.hoopchina.com.cn/hupuapp/bbs/548/5527135742548/thread_5527135742548_20180402114935_s_479392_o_h_1080px_w_1080px1877442272.jpeg?x-oss-process=image/resize,w_800/format,webp",
"pic3": "https://i1.hoopchina.com.cn/hupuapp/bbs/548/5527135742548/thread_5527135742548_20180402114924_s_176443_o_h_800px_w_600px1088551107.jpeg?x-oss-process=image/resize,w_800/format,webp"
},
{
"address": "https://bbs.hupu.com/21847465.html",
"title": "手下留情,有两分吗?",
"ID": "科比之后蜜库里",
"touxiang": "https://i1.hoopchina.com.cn/user/681/32949681/32949681-1510592138.jpg",
"pic2": "https://i1.hoopchina.com.cn/hupuapp/bbs/689/60341568799689/thread_60341568799689_20180402203722_s_362569_h_1333px_w_1000px2077096544.jpeg?x-oss-process=image/resize,w_800/format,webp"
}部分摘选
图片大多是webp格式的
其实存储下来也不是json格式,有想法的同学可以自行拼接成合适的格式,再进行一些拓展的利用嘿嘿嘿。
本文仅为了学习交流,请勿进行一些非法或不道德的操作。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/127216.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
