大家好,又见面了,我是你们的朋友全栈君。
一.大数据运维相关答疑与概述
1.0 Class介绍
本课程是专门培养大数据运维与架构方向专业人才的体系化课程。课程所有讲师小伙伴全部是在职的知名企业大数据开发专家,大数据技术专家职位员工,非专门的培训机构老师(小伙伴当前在职企业阿里巴巴,哔哩哔哩,平安集团,苏宁易购,美团等,运维集群规模大到10000+节点,课程内容可以满足市面上80%以上企业的大数据运维工作)。
课程以企业大数据集群运维实战和招聘需求为出发点,深入浅出,有重点地为大家系统化地讲解整个大数据运维需要的知识点,实战教学,多年运维经验分享,拒绝demo教学,让学员在大数据红利时代,顺利拿到高薪,华丽转型职业。
1.1 为啥是大数据运维课程not大数据开发?
1.企业中大数据运维的职责,干什么的?


其实对于主流的中小厂来说,大数据运维其实主要就是负责(数据中台)大数据平台的建设(集群搭建这种都是小概率,一般公司集群都搭建好了),集群的维护,调优,升级,监控,故障排查处理,其次解决大数据用户(开发)使用集群的日常一些问题等,保障生产上的SLA。相对来说不接触业务层面。当然小公司因为没有基础运维,所以你需要掌握一些基础运维的工作,比如服务器系统的安装等等,不过这些问题都比较简单,用工具批量化模板化处理即可,当然小公司一般上云的比较多,自有服务器成本高,维护麻烦,所以一般不牵扯到硬件问题。
故:小公司的大数据运维≈大数据集群/组件运维+基础运维
但是对于大厂来说一个数据中台都是上百人的规模,以某站为例,负责各个组件的开发都有很多人,会要求更加严格的术业有专攻,分工更加明细。比如你们几个就做主机层面的监控,你们一拨人就做hbase组件的二次开发维护优化。中大型公司如果是自有服务器,一般都有专门的基础运维,管理底层的网络架构,服务器维修处理,硬件布置,系统的安装,权限的管理等等。大数据运维更偏向于大数据生态的大数据应用运维。
故:中大型公司大数据运维≈大数据组件/应用的运维
2.为啥选择大数据运维课程而不是大数据开发

小厂来说,有些大数据部们就几个人,开发和集群运维管理都是一起的。你懂集群,懂组件优化,做大数据开发很容易,就是熟悉一些函数结合业务应用。反之,开发做运维很难。懂集群运维管理去中小公司找公司更加有优势,他们更看重这点。
当然这些大数据运维课程学完,你也完全可以胜任一些大数据开发工作,如果你想转行大数据开发也很容易。后面我们会上大数据开发课程,其实大数据开发和大数据运维课程很多跟运维课程是重叠的,只是掌握的着重点不同。
1.2 开Class的目的
当前小伙伴都是企业在职的,对技术也有一定的沉淀。给大家攒到一起开课的目的之一就是为了赚点散碎的银子,小金库私房钱(小伙伴年薪总包都在40w以上了)。所以为了保障课程的质量,本着负责任的态度,课程的收费不会特别便宜,不适合白嫖。其次希望通过我们的技术教学,对有需要的小伙伴有所帮助,在高性价比的投入下能找到一份高薪的工作。
- 如果你是大学计算机/网络/通信等大类相关专业毕业,毕业两年以上薪水还没有达到20k,对现在工作,薪水不满意,可以考虑下我们的课程,我们有信心让你实现小目标!
- 如果你是非计算机大类相关专业想转行进入IT,当前薪水没有20k也可以,但是相对难度会大点,虽然说IT相对最不看重出生,但是很多企业会要求专业属于IT大类相关专业,尤其是头部大厂。当然小厂一般只要能干活,技术不错,这些都不是问题。毕竟中小厂占比80%,大厂才那几十家。我身边也有很多小伙伴是其他专业转行进入大数据行业的,也混的风生水起。
1.3 课程适合哪些人群
- 传统IT运维人员,想升职加薪(最容易转行)
- 大专以上学历非科班想入行大数据的人
- 其他IT行业开发人员想转行大数据
- 在职大数据开发,运维想提升技术
题外话,非常不建议小白自学。自学适合进阶的学习,网上最不缺的就是免费教程,甚至体系化的教程,但你见有几个小白靠免费教程自学后拿到高薪了,或者转行成功了。首先很难坚持下去,其次期间会遇到各种问题,苦苦摸索无法解决,其次学的知识都是零散的,不知道如何应用也不知道如何找工作,不是非要自己撞得头破血流得到的才是经验,专业的事交给专业的人做,就像考研政治大家都会报一个辅导班一样,有些事花点钱给中介黄牛去做不香嘛等。)
1.4Class亮点与区别
1.系统性知识体系,但有重点教学
课程系统化全面化教学很容易,但是短时间内学员根本没法掌握,举个例子教你学英语,短时间带你把牛津词典翻了一遍,看上去全面,实际效果可想而知。所以本次课程会在系统化教学中告诉大家什么程度人应该掌握成什么样,比如工作2年的人应该掌握哪些,什么深度,5年的人该是什么样,让大家有重点的学习掌握,结合自己的实际情况掌握,而不是一视同仁没有重点的学习,最终都是万精油。学技术记住一句话,术业有专攻,要有专攻
2.专注于实战,拒绝demo
课程以完全企业生产模式教学,包含linux基础掌握,重点掌握,大数据集群规划,集群部署实施,集群调优(重点,没有性能瓶颈的调优都是耍流氓),集群监控管理,集群日常运维,大数据组件原理剖析,源码演示,二次组件开发等。小伙伴基于日常工作内容演示教学,学到的就是实战,学到甚至是很多小厂的人几年都没有的经验(接触不到)。实战才能让你学有所用,知道怎么用,才知道怎么学,也让你在面试中披荆斩棘。
3.定制化学习,职业规划与辅导
互联网时代学习最不缺乏的就是资源。因材施教,重点会针对每个小伙伴的情况,基本水平,确立职业规划,基于职业规划定制学习计划。比如有基础和没基础的人学习方式,学习深度肯定都不一样。我们会结合个人经验,企业实际招聘需求,企业实际应用情况会每个小伙伴定制化学习。
1.5 Class相关问题解答
1.课程授课方式与时间
课程第一期授课方式以网络录播的视频为主,以部分直播为辅,定期更新,方便大家在不耽误现有工作的同时学习。注意课程其次最主要的是课后辅导,让你有问题可以及时得到解决,答疑解惑,帮你规划学习,定期check,抱团学习成长,一个人自学坚持还是比较难的,会有考核考勤,督促大家进步。
课程我们预期3-5个月,看你实际的学习情况,结合大家整体情况会对课程的深度有所调整。课程我们第一期预期教学内容的价值在15k-30k工作薪水之间。所以第一期适合当前薪水低于25k的小伙伴报名。后面会上线高阶课程,所以课程非常适合收入低于20k的小伙伴学习。因为更高的薪水很难靠短时间培训了,我们也都是很多年的积累(学历+工作经历+工作经验)才拿到这个薪水。
2.课程收费问题
大数据开发课程,运维课程网上有很多,也有很多免费的,注意有些课程不全面,或者纯粹demo。也有专门培训机构在开课,平均课程授课时长4个月,价格平均2万左右。加上生活开销,吃喝住行,全职培训下来花费四万左右。也有纯粹网络视频课程卖1.5万元左右的(课后辅导)。当然也有分章节卖(没有辅导的)几百元课程,拍即发货。
本次课程收费初步定价1000-3000之间(可能会有调整,结合成本,主要我们想让每一个小伙伴学有所成,也会针对小伙伴的情况进行减免)。我们的目标是绝对低于你学完课程后的单月薪资涨幅,让你的付出有回报。有些人不要看到收费课程就柠檬精,排斥,培训机构,培训课程式的看不起。上士闻道,勤而行之;中士闻道,若存若亡;下士闻道,大笑之,不笑不足以为道。最终判断的标准很简单,看自己的投入与产出比。
注意,注意,注意,网络课程最重要就两点,其一课程质量,其二就是辅导,两者缺一不可,缺一都难走下去。没有辅导,如学习规划,答疑解惑,职业规划,简历指导,面试指导,更难走下去。所以小白建议要不选个靠谱的培训机构前天后地去学,要不一定要选择有辅导的网络课程。
3.课程购买与课程的学习
注意,无论是什么课程,最主要的还是靠自己学。就像国家扶贫一样,重点是扶,最终还是要靠自己努力改变命运,你要是自己躺在地上不起来谁都没办法。人最难的就是选择,面对选择时会有迟疑,犹豫,彷徨,不安,因为选择意味着走出舒适区,意味着不确定。那首先要看你要不要选择,失去和得到的分别是什么,选择了就要义无反顾。这一点要想清楚,想明白。
课程的重点都是我们自己设计的,自己录制的。但是也会根据小伙伴的基本情况,针对每个人私人定制规划,也会从网络上找一些篇章优秀的课程,讲的非常好的课程送给小伙伴自学或者深入学习,我们进行辅导,也会补充一讲解些核心的内容。
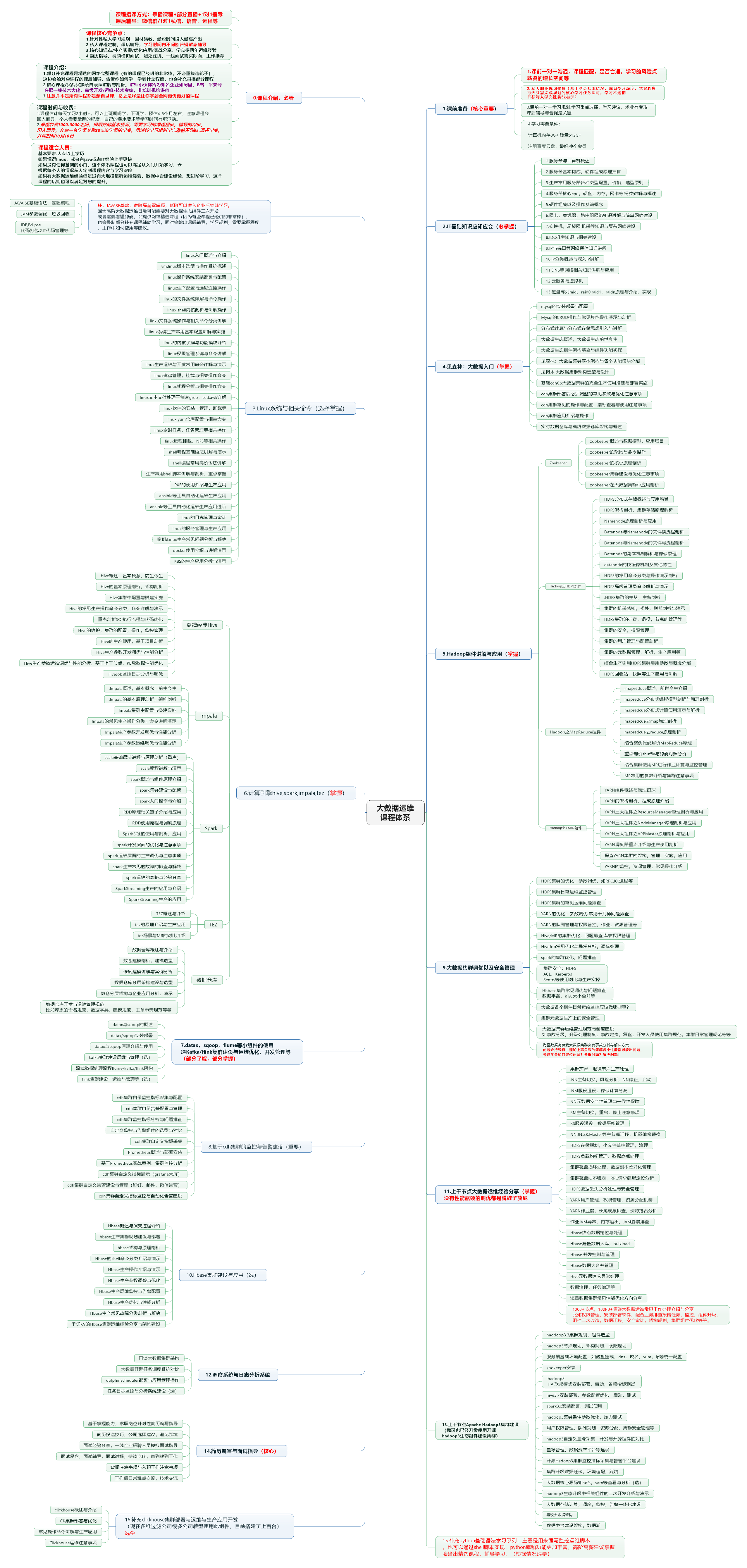
二. 大数据运维课程框架与内容体系
课程大致分成如下几个大类模块,现在比较粗放,很多细节会在教学中不断丰富完善。
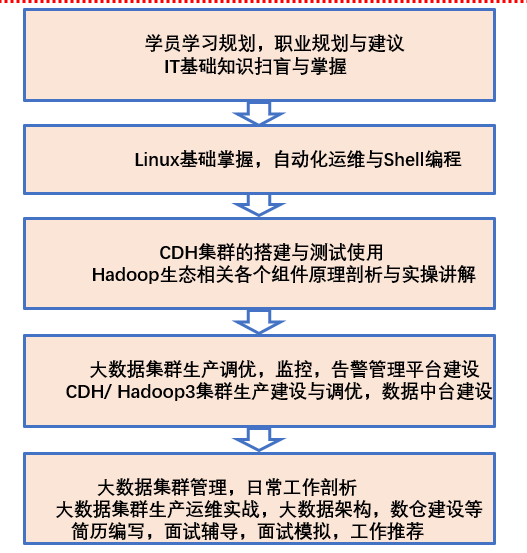
IT基础和linux基础这是大数据运维重点需要掌握的基础知识,尤其中小型公司大数据运维和基础运维职责区分的不是很细。当然这些重点掌握也要分了解,理解,掌握,有些命令知识知道就行,实际使用的去百度查询一下即可。不然一个linux系列可以深入讲2个月,但是实际很多是暂时用不着的,课程中会给大家标记出来,有重点学习即可,后期在企业中可以根据实际需求深入自我学习,初学者不要贪多。
如下是课程模块大类和大章节,具体其中细节小类还在不断完善中,每个章节实际可能会分成多个细节小类课程讲解。注意,下面只有课程的大类和章节,实际的小类还没有完全编写完上线哈。
1.IT基础知识运维与开发应知应会(大类)
1.服务器构成,计算机,硬盘,内存,CPU等基础硬件讲解(章节)
1.1 服务器基本构成,硬件组成原理扫盲(细节)
1.2 生产常用服务器各种类型配置,价格,选型原则
1.3 服务器核心cpu,硬盘,内存等讲解
1.4磁盘阵列raid,raid0,raid1,raidn原理与介绍,实现
2.硬件组成以及操作系统概念
3.网卡,路由器,交换机,局域网,机架,IDC等相关知识讲解
4.网络IP分类,DNS相关网络知识讲解
5.云服务,虚拟机原理与应用等基础知识讲解
2 需要的掌握的linux系统与shell编程
1.linux入门概述与介绍
2.vm,linux版本选型与安装实施
3.linux生产配置与远程连接操作
4.linux的文件系统介绍与配置讲解
5.linux shell介绍与讲解
6.linxu文件系统操作与相关命令分类讲解
7.linux系统生产常用基本配置讲解与实施
8.linux的内核了解与功能模块介绍
9.linux权限管理系统与命令讲解
10.linux生产运维与开发常用命令详解与演示
11.linux磁盘管理,挂载与相关操作命令
12.linux线程分析与相关操作命令
13.linux文本文件处理三剑客grep,sed,awk详解
14linux软件的安装,管理,卸载等
15.linux yum仓库配置与相关命令
16.linux定时任务,任务管理等相关操作
17.linux远程挂载,NFS等相关操作
18.shell编程基础语法讲解与演示
19.shell编程常用高阶语法讲解
20.生产常用shell脚本讲解与剖析,重点掌握
21.PXE的使用介绍与生产应用
22.ansible等工具生产应用
23.linux的日志管理与审计
24.linux的服务管理与生产应用
25.生产常见问题分析与解决
26.案例:生产mysql的安装,使用与简介
27.docker.k8s等使用介绍与分析
3.Hadoop大数据生态概述与集群搭建
大数据本质就解决两件事:海量数据的存储和海量数据的计算。其他所有的组件都是围绕这两件事展开的。会根据企业的实际情况选用不同的组件实现,比如时效性,比如性能,比如成本而选型不同组件等等。这一章节主要是了解大数据生态的框架,基本情况,然后搭建基于cdh版本的集群,先不用深入了解组件的原理。后续基于此集群介绍其中组件的原理。
1.分布式计算与分布式存储思想引入与讲解
2.大数据生态概述,大数据生态前世今生
3.大数据生态组件架构与组件功能初探
4.见森林:大数据集群基本架构与功能模块介绍
5.见树木:大数据集群架构选型与设计,部署实施流程
6.基础cdh6.x大数据集群的生产搭建与部署实施流程
7.cdh集群部署后必须调整的常见参数与优化注意事项
8.cdh集群常见的操作与配置,指标查看与使用注意事项
4.大数据生态组件原理初级剖析
本章主要是剖析大数据存储框架,资源调度框架,集群计算框架的基本原理,要熟悉掌握部分组件的核心原理,架构情况。其中的操作,组件的原理剖析,应用实施都是基于上面搭建的集群。
这里先不用着急掌握集群的调优,参数的配置,常见故障的处理等等。先掌握组件原理,基本应用,命令操作等。这一章节是核心章节,也是后面学习的基础。
4.1 zookeeper组件
1.zookeeper概述与数据模型,应用场景
2.zookeeper的架构与命令操作
3.zookeeper的原理剖析与集群架构介绍
4.2 Hadoop之HDFS组件
1.HDFS分布式存储概述与应用场景
2.HDFS架构剖析,集群存储原理解析
3.Namenode原理剖析与应用
4.Datanode与Namenode的配合使用,文件读写流程
5.Datanode的副本机制解析与存储原理
6.HDFS的常用命令操作与演示解析
7.HDFS高级管理员命令解析与演示
8.HDFS集群的主从,主备剖析
9.集群的机架感知,拓扑,联邦剖析与演示
10.HDFS集群的扩容,退役,节点的管理等
11.集群的安全,权限管理,用户管理等
12.集群的元数据管理,解析,生产应用等
4.3 Hadoop之MapReduce组件
1.mapreduce概述,前世今生介绍
2.mapreduce分布式编程模型剖析与原理剖析
3.mapredcue分布式计算使用演示与解析
4.mapredcue之map原理剖析
5. mapredcue之reduce原理剖析
6.结合案例代码解析MapReduce原理
7.结合集群使用MR进行作业计算与监控管理
8.MR常用的参数介绍与集群注意事项
4.4 Hadoop之YARN组件
1.YARN组件概述与原理初探
2.YARN的架构剖析,组成原理介绍
3.YARN三大组件之ResourceManager原理剖析与应用
4. YARN三大组件之NodeManager原理剖析与应用
5. YARN三大组件之APPMaster原理剖析与应用
6.YARN调度器重点介绍与使用
7.探查YARN集群的架构,管理,实施,应用
8.YARN的监控,资源管理,常见操作介绍
4.5 Hive/Impala组件
1.Hive概述,基本概念,前生今生
2.Hive的基本原理剖析,架构剖析
3.Hive的常见生产操作,命令讲解演示
4Hive的维护,集群的配置,操作,监控管理
5.Hive的生产使用,项目剖析
6.数据仓库概述,基本概念介绍
7.数仓架构设计剖析,建模介绍
4.6 Spark组件原理与常见使用操作
1.Spark概述,基本概念,前生今生
2.Spark的基本原理剖析,架构剖析
3.Spark的常见生产操作,命令讲解演示
4.Spark的维护,集群的配置,操作,监控管理
5.Spark的生产使用,项目剖析,调优管理
4.7 工具DataX、Sqoop,Flume组件原理与使用介绍
这些组件都比较简单,实际结合情况使用。
5.大数据集群的维护和优化
大数据集群的优化维护并不像网上统一模板的答案一样,参数应该设置多少,开启什么参数。实际优化调优需要结合公司集群的实际情况,如负载,集群的架构,业务类型等不断尝试优化,所以要清楚集群组件的原理,参数的核心原理,这样才能结合实际进行优化。所以参数的优化,集群问题的排查都需要结合实际去处理,没有什么合不合适,只有好不好用,甚至需要结合业务对组件进行二次开发。
5.1 HDFS集群的优化,参数调优
5.2 HDFS集群日常运维监控管理
5.3HDFS集群的常见运维问题排查
5.4 YARN的优化,几十个参数调优
5.5 YARN集群日常运维监控管理
5.6YARN集群的常见运维问题排查
5.7 Hive/MR生产集群几十个核心参数调优,参数讲解
5.8Hive/MR生产集群常见故障排查
5.9 Spark生产集群调优,参数讲解
5.10 Spark生产集群常见故障排查
5.11 集群其他如zk等组件的优化与整体维护
5.12大数据集群常见日常管理,工作剖析
6. Hbase/Kakfa/presto集群的建设与生产维护,优化
Hbase/Kakfa集群生产是相对独立的一套集群,依赖HDFS,有些公司有这个需求,有些公司没有这个需求,这里单独剖析,Hbase/Kakfa的原理,常见的操作,生产集群的配置搭建,优化,生产常见故障的排查。
1. Hbase的组件原理学习,概述
2.Hbase集群的搭建与配置优化
3.Hbase的常见操作与原理剖析,应用
4.Hbase生产集群的常见管理,调优,监控等
5.Hbase集群常见故障分析,总结
1. Kakfa的组件原理学习,概述
2.Kakfa集群的搭建与配置优化
3.Kakfa的常见操作与原理剖析,应用
4.Kakfa生产集群的常见管理,调优,监控等
5.Kakfa集群常见故障分析,总结
7.大数据集群监控与告警建设
集群的监控与告警是运维的核心,监控指标的采集,有主机层面的指标采集,服务层面的指标采集,这些监控指标是日常运维需要排查问题,解决问题,集群管理必备的数据。告警,简单来说基于采集的监控指标配置告警,集群出任何问题运维都能知道,分不同情况配置不同的告警,如邮件告警,钉钉告警,电话告警等等。
1.集群监控采集,配置与处理
2.生产集群服务监控与调优
3.集群安全,权限管理
4.Prometheus+Grafana+自定义
8.集群运维实战与案例剖析(几十个生产案例)
集群生产应用中面临者各种各样的治理,如存储治理,如何规范化使用,集群常见的治理有哪些?集群资源不足时如何进行治理,任务监控治理,元数据安全,元数据治理等等,如何模块化系统化治理,避免人为暴力治理。大集群如何规划,从硬件网络的规划,到管理规划,应用规划等等,可以剖析的地方很多。这里会结合上千节点集群的日常实战,几家公司的生产剖析,几十个案例逐一剖析。
1.集群数据治理篇
2.集群算力治理篇
3.集群架构与规划篇
4.集群管理篇
9. 求职:面试题,简历与面试
为什么你投递的简历如泥牛入海?为什么技术不如你的人顺利通过而你不幸被刷?为什么跟你差不多的人薪水职级比你高很多?同样的简历,如何给人耳目一新的感觉,如何避免简历投递踩坑。大数据面试不同阶段,不同职级的面试题分类总结剖析,公司面试模拟,一线企业面试官直接面试,模拟即实战。工作推荐,面试经验分享总结,薪资谈判,背调注意事项等等。避免大家最后100米踩坑。
1.大数据运维面试题分类总结剖析
2.简历编写一对一指导
3.求职模拟面试一对一指导
4.面试经验分享与工作推荐
毕业工作几年,月入还不到2万的建议速看_涤生手记-CSDN博客
尖叫提示:双击放大图片即可查看详细内容
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/127152.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
