大家好,又见面了,我是你们的朋友全栈君。


一、哈希表概述
首先简单介绍几个概念:哈希表(散列表)、映射、冲突、链地址、哈希函数。
哈希表(Hash table)的初衷是为了将数据映射到数组中的某个位置,这样就能够通过数组下标访问该数据,提高数据的查找速度,这样的查找的平均期望时间复杂度是O(1)的。
例如四个整数 6、7、9、12 需要映射到数组中,我们可以开一个长度为13(C语言下标从0开始)的数组,然后将对应值放到对应的下标,但是这样做,就会浪费没有被映射到的位置的空间。


采用哈希表的话,我们可以只申请一个长度为4的数组,如下图所示:
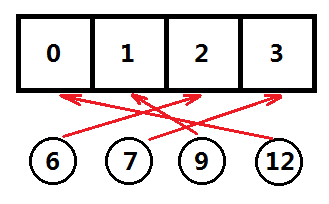
将每个数的值对数组长度4取模,然后放到对应的数组槽位中,这样就把离散的数据映射到了连续的空间,所以哈希表又称为散列表。这样做,最大限度上提高空间了利用率,并且查找效率还很高。
那么问题来了,如果这四个数据是6、7、8、11呢?继续看图:
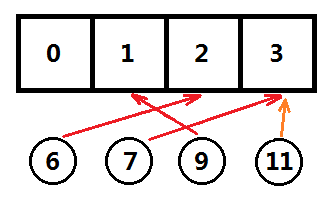
7 和 11 对4取模的值都是 3,所以占据了同一个槽位,这种情况我们称为冲突 (collision)。一般遇到冲突后,有很多方法解决冲突,包括但不限于 开放地址法、再散列法、链地址法 等等。 Redis采用的是链地址法,所以这里只介绍链地址法,其它的方法如果想了解请自行百度。
链地址法就是将有冲突的数据用一个链表串联起来,如图所示:
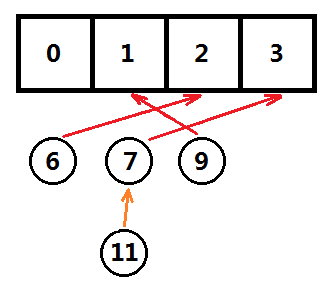
这样一来,就算有冲突,也可以将有冲突的数据存储在一起了。存储结构需要稍加变化,哈希表的每个元素将变成一个指针,指向数据链表的链表头,每次有新数据来时从链表头插入,可以达到插入的时间复杂度保持O(1)。
再将问题进行变形,如果4个数据是 “are”, “you”, “OK”, “?” 这样的字符串,如何进行映射呢?没错,我们需要通过一个哈希函数将字符串变成整数,哈希函数的概念会在接下来详细讲述,这里只需要知道它可以把一个值变成另一个值即可,比如哈希函数f(x),调用 f(“are”) 就可以得到一个整数,f(“you”) 也可以得到一个整数。
一个简易的大小写不敏感的字符串哈希函数如下:
unsigned int hashFunction(const unsigned char *buf, int len) {
unsigned int hash = (unsigned int)5381; // hash初始种子,实验值
while (len--)
hash = ((hash << 5) + hash) + (tolower(*buf++)); // hash * 33 + c
return hash;
}我们看到,哈希函数的作用就是把非数字的对象通过一系列的算法转化成数字(下标),得到的数字可能是哈希表数组无法承载的,所以还需要通过取模才能映射到连续的数组空间中。对于这个取模,我们知道取模的效率相比位运算来说是很低的,那么有没有什么办法可以把取模用位运算来代替呢?
答案是有!我们只要把哈希表的长度 L 设置为2的幂(L = 2^n),那么 L-1 的二进制表示就是n个1,任何值 x 对 L 取模等同于和 (L-1) 进行位与(C语言中的&)运算。
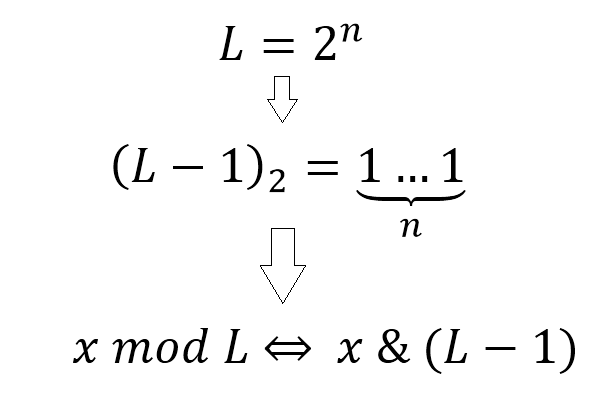
介绍完哈希表的基础概念,我们来看看 Redis 中是如何实现字典的。
二、Redis数据结构定义
1、哈希表
哈希表的结构定义在 dict.h/dictht :
typedef struct dictht {
dictEntry **table; // 哈希表数组
unsigned long size; // 哈希表数组的大小
unsigned long sizemask; // 用于映射位置的掩码,值永远等于(size-1)
unsigned long used; // 哈希表已有节点的数量
} dictht;table 是一个数组,数组的每个元素都是一个指向 dict.h/dictEntry 结构的指针;
size 记录哈希表的大小,即 table 数组的大小,且一定是2的幂;
used 记录哈希表中已有结点的数量;
sizemask 用于对哈希过的键进行映射,索引到 table 的下标中,且值永远等于 size-1。具体映射方法很简单,就是对 哈希值 和 sizemask 进行位与操作,由于 size 一定是2的幂,所以 sizemask=size-1,自然它的二进制表示的每一个位(bit)都是1,等同于上文提到的取模;
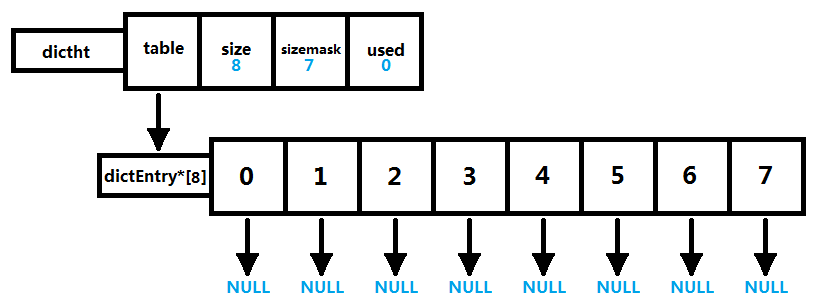
如图所示,为一个长度为8的空哈希表。
2、哈希表节点
哈希表节点用 dict.h/dictEntry 结构表示,每个 dictEntry 结构存储着一个键值对,且存有一个 next 指针来保持链表结构:
typedef struct dictEntry {
void *key; // 键
union { // 值
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next; // 指向下一个哈希表节点,形成单向链表
} dictEntry;key 是键值对中的键;
v 是键值对中的值,它是一个联合类型,方便存储各种结构;
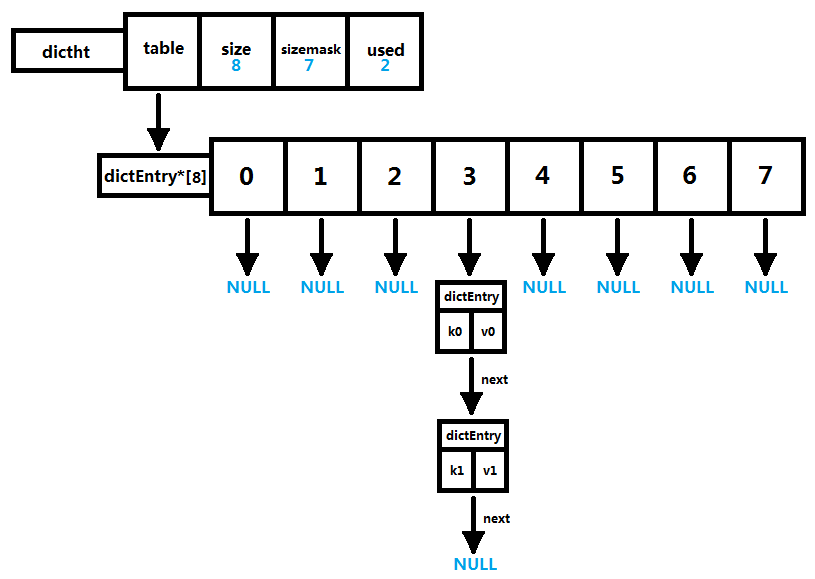
next 是链表指针,指向下一个哈希表节点,他将多个哈希值相同的键值对串联在一起,用于解决键冲突;如图所示,两个dictEntry 的 key 分别是 k0 和 k1,通过某种哈希算法计算出来的哈希值和 sizemask 进行位与运算后都等于 3,所以都被放在了 table 数组的 3号槽中,并且用 next 指针串联起来。
3、字典
Redis中字典结构由 dict.h/dict 表示:
typedef struct dict {
dictType *type; // 和类型相关的处理函数
void *privdata; // 上述类型函数对应的可选参数
dictht ht[2]; // 两张哈希表,ht[0]为原生哈希表,ht[1]为 rehash 哈希表
long rehashidx; // 当等于-1时表示没有在 rehash,否则表示 rehash 的下标
int iterators; // 迭代器数量(暂且不谈)
} dict;type 是一个指向 dict.h/dictType 结构的指针,保存了一系列用于操作特定类型键值对的函数;
privdata 保存了需要传给上述特定函数的可选参数;
ht 是两个哈希表,一般情况下,只使用ht[0],只有当哈希表的键值对数量超过负载(元素过多)时,才会将键值对迁移到ht[1],这一步迁移被称为 rehash (重哈希),rehash 会在下文进行详细介绍;
rehashidx 由于哈希表键值对有可能很多很多,所以 rehash 不是瞬间完成的,需要按部就班,那么 rehashidx 就记录了当前 rehash 的进度,当 rehash 完毕后,将 rehashidx 置为-1;
4、类型处理函数
类型处理函数全部定义在 dict.h/dictType 中:
typedef struct dictType {
unsigned int (*hashFunction)(const void *key); // 计算哈希值的函数
void *(*keyDup)(void *privdata, const void *key); // 复制键的函数
void *(*valDup)(void *privdata, const void *obj); // 复制值的函数
int (*keyCompare)(void *privdata, const void *key1, const void *key2); // 比较键的函数
void (*keyDestructor)(void *privdata, void *key); // 销毁键的函数
void (*valDestructor)(void *privdata, void *obj); // 销毁值的函数
} dictType;以上的函数和特定类型相关,主要是为了实现多态,看到这个如果懵逼也没关系,下面会一一对其进行介绍。
三、哈希函数
类型处理函数中的第一个函数 hashFunction 就是计算某个键的哈希值的函数,对于不同类型的 key,哈希值的计算是不同的,所以在字典进行创建的时候,需要指定哈希函数。
哈希函数可以简单的理解为就是小学课本上那个函数,即y = f(x),这里的 f(x)就是哈希函数,x是键,y就是哈希值。好的哈希函数应该具备以下两个特质:
1、可逆性;
2、雪崩效应:输入值(x)的1位(bit)的变化,能够造成输出值(y)1/2的位(bit)的变化;
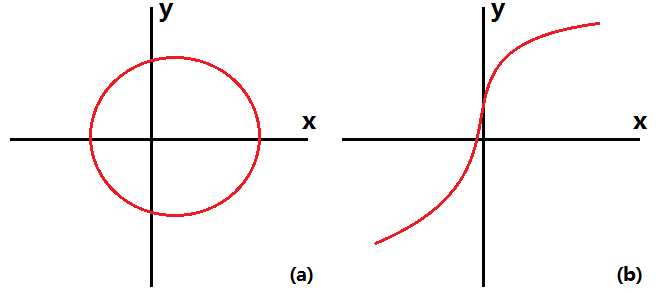
可逆性很容易理解,来看两个图。图(a)中已知哈希值 y 时,键 x 可能有两种情况,所以显然是不可逆的;而图(b)中已知哈希值 y 时,键 x 一定是唯一确定的,所以它是可逆的。从图中看出,函数可逆的好处是:减少冲突。由于 x 和 y 一一对应,所以在没有取模之前,至少是没有冲突的,这样就从本原上减少了冲突。
雪崩效应是为了让哈希值更加符合随机分布的原则,哈希表中的键分布的越随机,利用率越高,效率也越高。
Redis源码中提供了一些哈希函数的实现:
1、整数哈希
unsigned int dictIntHashFunction(unsigned int key)
{
key += ~(key << 15);
key ^= (key >> 10);
key += (key << 3);
key ^= (key >> 6);
key += ~(key << 11);
key ^= (key >> 16);
return key;
}2、字符串哈希
unsigned int dictGenCaseHashFunction(const unsigned char *buf, int len) {
unsigned int hash = (unsigned int)dict_hash_function_seed;
while (len--)
hash = ((hash << 5) + hash) + (tolower(*buf++)); /* hash * 33 + c */
return hash;
}这些哈希函数是前人经过一系列的实验,科学计算总结得出来的,我们只需要知道有这么些函数就行了。当字典被用作数据库的底层实现, 或者哈希键的底层实现时, Redis 使用 MurmurHash2 算法来计算键的哈希值。MurmurHash 算法最初由 Austin Appleby 于 2008 年发明, 这种算法的优点在于, 即使输入的键是有规律的, 算法仍能给出一个很好的随机分布性, 并且算法的计算速度也非常快。
四、哈希算法
1、索引
当要将一个新的键值对添加到字典里面或者通过键查找值的时候都需要执行哈希算法,主要是获得一个需要插入或者查找的dictEntry 所在下标的索引,具体算法如下:
1、通过宏 dictHashKey 计算得到该键对应的哈希值
#define dictHashKey(d, key) (d)->type->hashFunction(key)2、将哈希值和哈希表的 sizemask 属性做位与,得到索引值 index,其中 ht[x] 可以是 ht[0] 或者 ht[1]
index = dictHashKey(d, key) & d->ht[x].sizemask;2、冲突解决
哈希的冲突一定发生在键值对插入时,插入的 API 是 dict.c/dictAddRaw:
dictEntry *dictAddRaw(dict *d, void *key)
{
int index;
dictEntry *entry;
dictht *ht;
if (dictIsRehashing(d)) _dictRehashStep(d); // 1、执行rehash
if ((index = _dictKeyIndex(d, key)) == -1) // 2、索引定位
return NULL;
ht = dictIsRehashing(d) ? &d->ht[1] : &d->ht[0]; // 3、根据是否 rehash ,选择哈希表
entry = zmalloc(sizeof(*entry)); // 4、分配内存空间,执行插入
entry->next = ht->table[index];
ht->table[index] = entry;
ht->used++;
dictSetKey(d, entry, key); // 5、设置键
return entry;
} 1、判断当前的字典是否在进行 rehash,如果是,则执行一步 rehash,否则忽略。判断 rehash 的依据就是 rehashidx 是否为 -1;
2、通过 _dictKeyIndex 找到一个索引,如果返回-1表明字典中已经存在相同的 key,具体参见接下来要讲的 索引定位;
3、根据是否在 rehash 选择对应的哈希表;
4、分配哈希表节点 dictEntry 的内存空间,执行插入,插入操作始终在链表头插入,这样可以保证每次的插入操作的时间复杂度一定是 O(1) 的,插入完毕,used属性自增;
5、dictSetKey 是个宏,调用字典处理函数中的 keyDup 函数进行键的复制;
3、索引定位
插入时还需要进行索引定位,以确定节点要插入到哈希表的哪个位置,实现在静态函数 dict.c/_dictKeyIndex 中:
static int _dictKeyIndex(dict *d, const void *key)
{
unsigned int h, idx, table;
dictEntry *he;
if (_dictExpandIfNeeded(d) == DICT_ERR) // 1、rehash 判断
return -1;
h = dictHashKey(d, key); // 2、哈希函数计算哈希值
for (table = 0; table <= 1; table++) {
idx = h & d->ht[table].sizemask; // 3、哈希算法计算索引值
he = d->ht[table].table[idx];
while(he) {
if (key==he->key || dictCompareKeys(d, key, he->key)) // 4、查找键是否已经存在
return -1;
he = he->next;
}
if (!dictIsRehashing(d)) break; // 5、rehash 判断
}
return idx;
} 1、判断当前哈希表是否需要进行扩展,具体参见接下来要讲的 rehash;
2、利用给定的哈希函数计算键的哈希值;
3、通过位与计算索引,即插入到哈希表的哪个槽位中;
4、查找当前槽位中的链表里是否已经存在该键,如果存在直接返回 -1;这里的 dictCompareKeys 也是一个宏,用到了keyCompare 这个比较键的函数;
5、这个判断比较关键,如果当前没有在做 rehash,那么 ht[1] 必然是一个空表,所以不能遍历 ht[1],需要及时跳出循环;
五、rehash
千呼万唤始出来,提到了这么多次的 rehash 终于要开讲了。其实没有想象中的那么复杂,随着字典操作的不断执行,哈希表保存的键值对会不断增多(或者减少),为了让哈希表的负载因子维持在一个合理的范围之内,当哈希表保存的键值对数量太多或者太少时,需要对哈希表大小进行扩展或者收缩。
1、负载因子
这里提到了一个负载因子,其实就是当前已使用结点数量除上哈希表的大小,即:
load_factor = ht[0].used / ht[0].size2、哈希表扩展
1、当哈希表的负载因子大于5时,为 ht[1] 分配空间,大小为第一个大于等于 ht[0].used * 2 的 2 的幂;
2、将保存在 ht[0] 上的键值对 rehash 到 ht[1] 上,rehash 就是重新计算哈希值和索引,并且重新插入到 ht[1] 中,插入一个删除一个;
3、当 ht[0] 包含的所有键值对全部 rehash 到 ht[1] 上后,释放 ht[0] 的控件, 将 ht[1] 设置为 ht[0],并且在 ht[1] 上新创件一个空的哈希表,为下一次 rehash 做准备;
Redis 中 实现哈希表扩展调用的是 dict.c/_dictExpandIfNeeded 函数:
static int _dictExpandIfNeeded(dict *d)
{
if (dictIsRehashing(d)) return DICT_OK;
if (d->ht[0].size == 0) return dictExpand(d, DICT_HT_INITIAL_SIZE); // 大小为0需要设置初始哈希表大小为4
if (d->ht[0].used >= d->ht[0].size &&
(dict_can_resize ||
d->ht[0].used/d->ht[0].size > dict_force_resize_ratio)) // 负载因子超过5,执行 dictExpand
{
return dictExpand(d, d->ht[0].used*2);
}
return DICT_OK;
}
3、哈希表收缩
哈希表的收缩,同样是为 ht[1] 分配空间, 大小等于 max( ht[0].used, DICT_HT_INITIAL_SIZE ),然后和扩展做同样的处理即可。
六、渐进式rehash
扩展或者收缩哈希表的时候,需要将 ht[0] 里面所有的键值对 rehash 到 ht[1] 里,当键值对数量非常多的时候,这个操作如果在一帧内完成,大量的计算很可能导致服务器宕机,所以不能一次性完成,需要渐进式的完成。
渐进式 rehash 的详细步骤如下:
1、为 ht[1] 分配指定空间,让字典同时持有 ht[0] 和 ht[1] 两个哈希表;
2、将 rehashidx 设置为0,表示正式开始 rehash,前两步是在 dict.c/dictExpand 中实现的:
int dictExpand(dict *d, unsigned long size)
{
dictht n;
unsigned long realsize = _dictNextPower(size); // 找到比size大的最小的2的幂
if (dictIsRehashing(d) || d->ht[0].used > size)
return DICT_ERR;
if (realsize == d->ht[0].size) return DICT_ERR;
n.size = realsize; // 给ht[1]分配 realsize 的空间
n.sizemask = realsize-1;
n.table = zcalloc(realsize*sizeof(dictEntry*));
n.used = 0;
if (d->ht[0].table == NULL) { // 处于初始化阶段
d->ht[0] = n;
return DICT_OK;
}
d->ht[1] = n;
d->rehashidx = 0; // rehashidx 设置为0,开始渐进式 rehash
return DICT_OK;
}3、在进行 rehash 期间,每次对字典执行 增、删、改、查操作时,程序除了执行指定的操作外,还会将 哈希表 ht[0].table中下标为 rehashidx 位置上的所有的键值对 全部迁移到 ht[1].table 上,完成后 rehashidx 自增。这一步就是 rehash 的关键一步。为了防止 ht[0] 是个稀疏表 (遍历很久遇到的都是NULL),从而导致函数阻塞时间太长,这里引入了一个 “最大空格访问数”,也即代码中的 enmty_visits,初始值为 n*10。当遇到NULL的数量超过这个初始值直接返回。
这一步实现在 dict.c/dictRehash 中:
int dictRehash(dict *d, int n) {
int empty_visits = n*10;
if (!dictIsRehashing(d)) return 0;
while(n-- && d->ht[0].used != 0) {
dictEntry *de, *nextde;
assert(d->ht[0].size > (unsigned long)d->rehashidx);
while(d->ht[0].table[d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == 0) return 1; // 设置一个空访问数量 为 n*10
}
de = d->ht[0].table[d->rehashidx]; // dictEntry的迁移
while(de) {
unsigned int h;
nextde = de->next;
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
d->ht[0].used--;
d->ht[1].used++;
de = nextde;
}
d->ht[0].table[d->rehashidx] = NULL;
d->rehashidx++; // 完成一次 rehash
}
if (d->ht[0].used == 0) { // 迁移完毕,rehashdix 置为 -1
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
d->rehashidx = -1;
return 0;
}
return 1;
}4、最后,当 ht[0].used 变为0时,代表所有的键值对都已经从 ht[0] 迁移到 ht[1] 了,释放 ht[0].table, 并且将 ht[0] 设置为 ht[1],rehashidx 标记为 -1 代表 rehash 结束。
七、字典API
1、创建字典
内部分配字典空间,并作为返回值返回,并调用 _dictInit 进行字典的初始化,时间复杂度O(1)。
dict *dictCreate(dictType *type, void *privDataPtr) 2、增加键值对
调用 dictAddRaw 增加一个 dictEntry,然后调用 dictSetVal 设置值,时间复杂度O(1)。
int dictAdd(dict *d, void *key, void *val) 3、查找键
利用哈希算法找到给定键的 dictEntry,时间复杂度O(1)。
dictEntry *dictFind(dict *d, const void *key) 4、查找值
利用 dictFind 找到给定键的 dictEntry,然后获得值,值的类型不确定,所以返回一个万能指针,时间复杂度O(1)。
void *dictFetchValue(dict *d, const void *key)5、删除键
通过哈希算法找到对应的键,从对应链表移除,时间复杂度O(1)。
int dictDelete(dict *ht, const void *key)发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/127012.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
