大家好,又见面了,我是你们的朋友全栈君。
目录
一、基础元素Node
static class Node<K,V> implements Map.Entry<K,V> {
//key的hash值
final int hash;
final K key;
V value;
//通过next属性将多个hash值相同的元素关联起来,形成单向链表
Node<K,V> next;
Node(int hash, K key, V value, Node<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
public final K getKey() { return key; }
public final V getValue() { return value; }
public final String toString() { return key + "=" + value; }
public final int hashCode() {
return Objects.hashCode(key) ^ Objects.hashCode(value);
}
public final V setValue(V newValue) {
V oldValue = value;
value = newValue;
return oldValue;
}
public final boolean equals(Object o) {
if (o == this)
return true;
if (o instanceof Map.Entry) {
Map.Entry<?,?> e = (Map.Entry<?,?>)o;
if (Objects.equals(key, e.getKey()) &&
Objects.equals(value, e.getValue()))
return true;
}
return false;
}
}实现很简单,关键是next属性,插入、查找、删除用法如下:
@Test
public void test8() throws Exception {
Node<String,Integer> first=new Node<>(1, "1", 1, null);
Node<String,Integer> node2=new Node<>(1, "2", 1, null);
Node<String,Integer> node3=new Node<>(1, "3", 1, null);
Node<String,Integer> node4=new Node<>(1, "4", 1, null);
Node<String,Integer> node5=new Node<>(1, "5", 1, null);
//插入时建立链式关系
first.next=node2;
node2.next=node3;
node3.next=node4;
node4.next=node5;
//从头元素开始遍历查找
Node<String,Integer> n=first;
do{
if(n.key.equals("5")){
System.out.println("====元素查找======");
System.out.println(n);
}
}while ((n=n.next)!=null);
//移除元素node2
first.next=node3;
node2.next=null;
System.out.println("====移除元素======");
n=first;
do{
System.out.println(n);
}while ((n=n.next)!=null);
}二、红黑树元素TreeNode
1、类定义和类属性
TreeNode继承自LinkedHashMap.Entry<K,V>,后者继承自HashMap.Node<K,V>,只是增加了两个属性before和after,用于保存当前节点的前后节点引用,从而形成一条可以双向遍历的链表。TreeNode继承自LinkedHashMap.Entry<K,V>是为了方便LinkedHashMap实现,本身并没有直接使用before和after两个属性。LinkedHashMap.Entry<K,V>的定义如下图:


TreeNode定义的属性如下图:
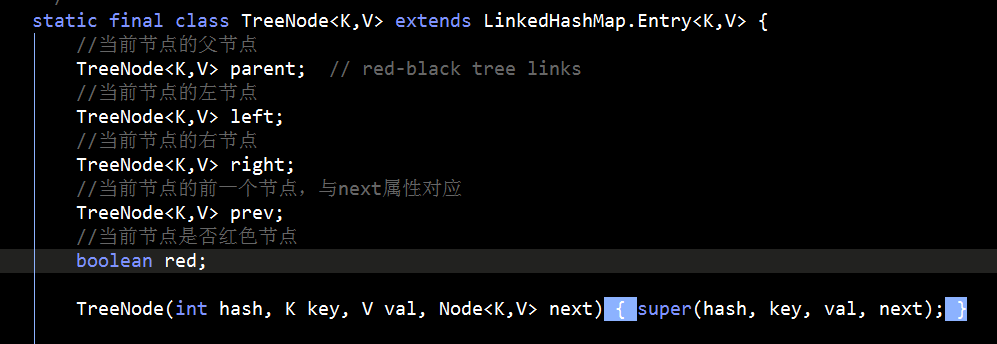
注意TreeNode的实现同时维护了红黑树和双向链式两种应用关系,这样便于在红黑树和链表之间做形态转换。
2、基础方法:
/**
* 返回当前节点的根节点
*/
final TreeNode<K,V> root() {
for (TreeNode<K,V> r = this, p;;) {
//该节点的父节点为null时该节点为根节点
if ((p = r.parent) == null)
return r;
r = p;
}
}
/**
* 递归检查当前节点是否符合双向链表以及红黑树规则
* 该方法在红黑树发生改变时都会执行一次,确保改变后红黑树符合规范
*/
static <K,V> boolean checkInvariants(TreeNode<K,V> t) {
TreeNode<K,V> tp = t.parent, tl = t.left, tr = t.right,
tb = t.prev, tn = (TreeNode<K,V>)t.next;
//是否符合双向链表规则
if (tb != null && tb.next != t)
return false;
if (tn != null && tn.prev != t)
return false;
//是否符合红黑树规则
if (tp != null && t != tp.left && t != tp.right)
return false;
//左节点的hash值必须小于根节点hash值
if (tl != null && (tl.parent != t || tl.hash > t.hash))
return false;
//右节点hash值大于根节点hash值
if (tr != null && (tr.parent != t || tr.hash < t.hash))
return false;
//红色节点的子节点一定不能是红色
if (t.red && tl != null && tl.red && tr != null && tr.red)
return false;
//递归检查左节点和右节点
if (tl != null && !checkInvariants(tl))
return false;
if (tr != null && !checkInvariants(tr))
return false;
return true;
}
/**
* 将根节点变成头元素,即保存在Node[]数组中的元素
*/
static <K,V> void moveRootToFront(Node<K,V>[] tab, TreeNode<K,V> root) {
int n;
if (root != null && tab != null && (n = tab.length) > 0) {
//计算根元素在数组中的索引位置
int index = (n - 1) & root.hash;
TreeNode<K,V> first = (TreeNode<K,V>)tab[index];
if (root != first) {
Node<K,V> rn;
//将对应索引的头元素设置成根元素
tab[index] = root;
//将root前后的元素建立连接,即移除root元素
TreeNode<K,V> rp = root.prev;
if ((rn = root.next) != null)
((TreeNode<K,V>)rn).prev = rp;
if (rp != null)
rp.next = rn;
//将root和first元素建立连接,即将root元素插入到first前面
if (first != null)
first.prev = root;
root.next = first;
root.prev = null;
}
assert checkInvariants(root);
}
}
/**
* 判断两个任意对象大小的通用方法,该方法是正常流程比不出大小时才会使用
*/
static int tieBreakOrder(Object a, Object b) {
int d;
if (a == null || b == null ||
(d = a.getClass().getName().
compareTo(b.getClass().getName())) == 0)
//identityHashCode是本地方法,忽视对象本身对hashCode()方法的重写
d = (System.identityHashCode(a) <= System.identityHashCode(b) ?
-1 : 1);
return d;
}
3、红黑树插入元素实现
红黑树是一种弱平衡的平衡二叉树,即保证相同的黑色高度并不是一定满足平衡因子绝对值不超过1的条件。平衡二叉树查找很快但是插入/删除时因为保持平衡需要旋转的平均次数较多不适应于插入/删除频繁的场景,红黑树是插入和查找都能兼顾的平衡方案,因此应用场景更广泛。
红黑树的定义参考:https://www.cnblogs.com/ysocean/p/8004211.html
平衡二叉树的定义参考:https://blog.csdn.net/qq_23100787/article/details/52506217
此处只是对大神博客中的讲解做补充,只限于红黑树的插入操作。
首先,红黑树新增的节点一定是红色的,因为插入黑色节点总会改变黑色高度,但是插入红色节点只有一半的机会(即父节点是红色时)会违背规则。如果新增节点的父节点是黑色的,那就没有任何问题,直接插入即可。如果新增节点的父节点是红色的,直接插入会违背不能有两个连续的红色节点的规则,因此需要通过变色和旋转来确保这种情形下红黑树是符合规则的。新增节点的父节点为红色包含以下三种情形:
情形一、父节点及父节点的兄弟节点都是红色节点,如下图:
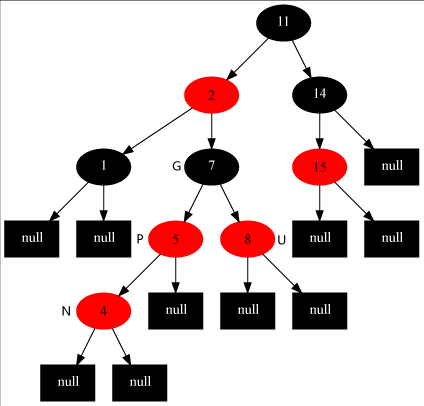
这种情况下首先是变色,把P和U变成黑色,G变成红色。因为无论N是P的左节点还是右节点,P是G的左节点还是右节点,变色后的结果都是新增节点插入到黑色节点上,所以不需要考虑N,P的位置。变色完成后G和2节点成了两个红色的节点,因为黑色高度相同,所以1节点必须是黑色的。因为G和2节点都是左右节点都有可能,因此有四种情形需要讨论。先考虑2节点为左节点,对应的两种情形就是情形二和三了。
情形二、父节点是红色的,父节点的兄弟节点是黑色的,插入的节点为父节点的右节点,如下图:
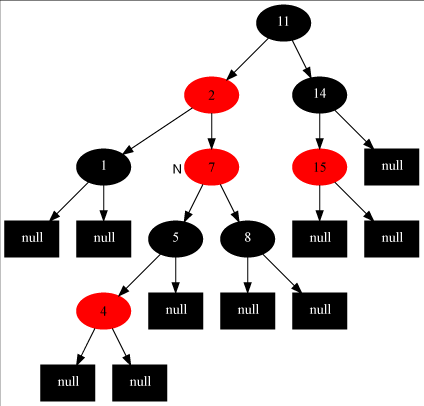
这种情况下已经不能再直接变色了,因为根节点必须是黑色的。假如把2节点变成黑色的,11节点变成红色的,再对2节点右旋呢?这时节点7就成为11的左节点,11节点和7节点都是红色节点,也不行。只能对2节点做左旋,变成情形三。
情形三、父节点是红色的,父节点的兄弟节点是黑色的,插入的节点为父节点的左节点
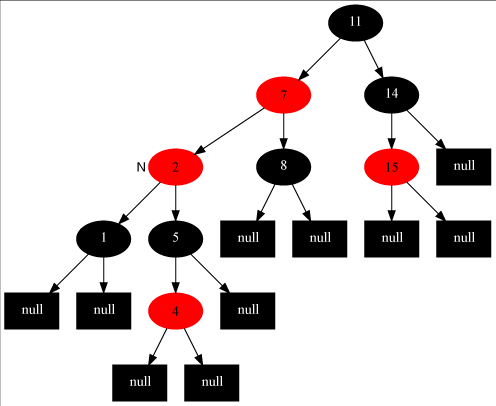
这种情形的处理就很明确了,把节点7变成黑色,节点11变成红色,在对节点7做右旋,变成如下图的平衡红黑树:
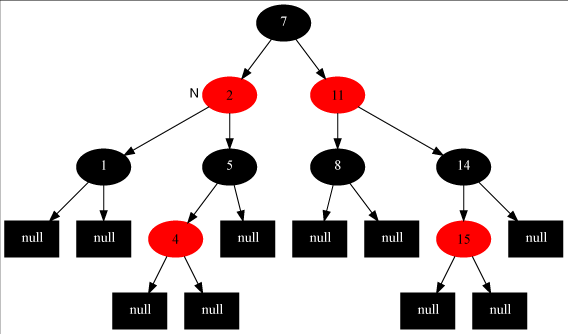
如果2节点是右节点,对情形二和情形三的处理就是相反的,对情形二由左旋变成右旋,情形三由右旋变成左旋。
HashMap中红黑树插入节点的代码实现如下:
// 对节点P做红黑树左旋,返回该节点的根节点
static <K,V> TreeNode<K,V> rotateLeft(TreeNode<K,V> root,
TreeNode<K,V> p) {
TreeNode<K,V> r, pp, rl;
if (p != null && (r = p.right) != null) {
//两个等于号,从右往左计算,即先执行p.right = r.left,后执行rl = p.right,最后判断rl!=null
//将p的右节点的左节点变成p的右节点
if ((rl = p.right = r.left) != null)
rl.parent = p;
//将p的父节点变成r的父节点,判断该父节点是否为空
if ((pp = r.parent = p.parent) == null)
//如果父节点为空,则r是根节点,根节点总是黑色的
(root = r).red = false;
//如果父节点不为空,且p是该父节点的左节点
else if (pp.left == p)
//将pp的左节点置为r
pp.left = r;
else
//将pp的右节点置为r
pp.right = r;
//r的左节点变成p,p的父节点变成r
r.left = p;
p.parent = r;
}
return root;
}
/*
对节点P做红黑树右旋操作,并返回该节点的根节点,是左旋的逆向操作
*/
static <K,V> TreeNode<K,V> rotateRight(TreeNode<K,V> root,
TreeNode<K,V> p) {
TreeNode<K,V> l, pp, lr;
if (p != null && (l = p.left) != null) {
//将p的左节点由l变成l的右节点
if ((lr = p.left = l.right) != null)
lr.parent = p;
//将p设置成l的右节点,p的父节点设置成l,l的父节点设置成p原来的父节点
if ((pp = l.parent = p.parent) == null)
(root = l).red = false;
else if (pp.right == p)
pp.right = l;
else
pp.left = l;
l.right = p;
p.parent = l;
}
return root;
}
//root为原来的根节点,因为插入时会旋转,根节点会发生改变,所以该方法返回的是执行平衡插入
后的根节点
static <K,V> TreeNode<K,V> balanceInsertion(TreeNode<K,V> root,
TreeNode<K,V> x) {
//红黑树新增节点一定是红色的,因为这样违反规则的可能性最小
x.red = true;
//注意此处是for循环,即由当前节点逐步往上处理
for (TreeNode<K,V> xp, xpp, xppl, xppr;;) {
//当前节点的父节点为空,即该节点为根节点,根节点一定是黑色的
if ((xp = x.parent) == null) {
x.red = false;
return x;
}
//父节点是黑色的或者父节点为根节点
else if (!xp.red || (xpp = xp.parent) == null)
return root;
//父节点是祖父节点的左节点,即上述讨论中的2节点是左节点
if (xp == (xppl = xpp.left)) {
//祖父节点的右节点存在且是红色节点,即是情形一
if ((xppr = xpp.right) != null && xppr.red) {
//将其父节点和父节点的兄弟节点涂成黑色
xppr.red = false;
xp.red = false;
//祖父节点置为红色,将当前节点置为祖父节点
xpp.red = true;
//注意此处直接跳到祖父节点了,因为祖父节点成红色的
x = xpp;
}
//如果祖父节点的右节点不存在或者是黑色的
else {
//当前节点是父节点的右节点,即2节点为左节点时的情形二
if (x == xp.right) {
//将当前节点置为父节点,并对父节点左旋
root = rotateLeft(root, x = xp);
xpp = (xp = x.parent) == null ? null : xp.parent;
}
//如果父节点存在,则将父节点涂黑,祖父节点涂红,并将祖父节点右旋
//即2节点为左节点时的情形三
if (xp != null) {
xp.red = false;
if (xpp != null) {
xpp.red = true;
root = rotateRight(root, xpp);
}
}
}
}
//父节点是祖父节点的右节点
else {
//如果祖父节点的左节点存在且是红色的,即是情形一
if (xppl != null && xppl.red) {
//祖父节点和祖父节点的兄弟节点置为黑色的
xppl.red = false;
xp.red = false;
//父节点置为红色的,将当前节点置为祖父节点
xpp.red = true;
x = xpp;
}
//如果祖父节点的左节点并存在或者是黑色的
else {
//如果当前节点是父节点的左节点,即2节点为右节点时的情形二
if (x == xp.left) {
//将当前节点置为父节点,并对父节点右旋
root = rotateRight(root, x = xp);
xpp = (xp = x.parent) == null ? null : xp.parent;
}
//如果父节点存在
if (xp != null) {
//将父节点置为黑色,祖父节点置为红色,对祖父节点做左旋,即2节点为右
节点时的情形三
xp.red = false;
if (xpp != null) {
xpp.red = true;
root = rotateLeft(root, xpp);
}
}
}
}
}
}
/**
* 如果存在key值相等的则返回该节点,否则插入新节点,返回null
*/
final TreeNode<K,V> putTreeVal(HashMap<K,V> map, Node<K,V>[] tab,
int h, K k, V v) {
Class<?> kc = null;
boolean searched = false;
//获取根节点
TreeNode<K,V> root = (parent != null) ? root() : this;
for (TreeNode<K,V> p = root;;) {
int dir, ph; K pk;
//比较key的hash值
if ((ph = p.hash) > h)
dir = -1;
else if (ph < h)
dir = 1;
//hash相等且key相等则返回当前节点
else if ((pk = p.key) == k || (k != null && k.equals(pk)))
return p;
//hash相等,equals方法不等下看key是否实现Comparable接口,如果没有实现或者实现了还是跟父节点key一样
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0) {
if (!searched) {
TreeNode<K,V> q, ch;
searched = true;
//从当前节点的子节点中找到key值相等的节点并返回
if (((ch = p.left) != null &&
(q = ch.find(h, k, kc)) != null) ||
((ch = p.right) != null &&
(q = ch.find(h, k, kc)) != null))
return q;
}
//如果当前节点的子节点还是没有key值相等的则采用系统默认方法比较key大小
dir = tieBreakOrder(k, pk);
}
TreeNode<K,V> xp = p;
//找到待插入的位置
if ((p = (dir <= 0) ? p.left : p.right) == null) {
Node<K,V> xpn = xp.next;
//构造新的节点
TreeNode<K,V> x = map.newTreeNode(h, k, v, xpn);
//插入当前节点的左边或者右边
if (dir <= 0)
xp.left = x;
else
xp.right = x;
//此处维护的链表顺序并不是插入顺序,新插入的节点并不是在最后一个
xp.next = x;
x.parent = x.prev = xp;
if (xpn != null)
((TreeNode<K,V>)xpn).prev = x;
//插入完成后将根节点作为Tab内的第一个节点
moveRootToFront(tab, balanceInsertion(root, x));
return null;
}
}
}4、红黑树的查找实现
红黑树的查找跟二叉树搜索是一样的,通过比较目标key的hash值与红黑树中节点的hash值,判断走左子树还是右子树,不断往下查找直到找到hash值相等且key值相当的节点。
/**
* 根据hash值遍历当前节点的所有子节点,直到hash值相同且key相同
*/
final TreeNode<K,V> find(int h, Object k, Class<?> kc) {
TreeNode<K,V> p = this;
do {
int ph, dir; K pk;
TreeNode<K,V> pl = p.left, pr = p.right, q;
//当前节点hash值大于目标hash值则从左节点查找
if ((ph = p.hash) > h)
p = pl;
//当前节点hash值小于目标hash值则从右节点查找
else if (ph < h)
p = pr;
//如果hash值相同比较key是否相同,相同则返回该节点
else if ((pk = p.key) == k || (k != null && k.equals(pk)))
return p;
//hash碰撞下,hash值相同,key不同或者key为null,如果左节点不存在,查找右节点
else if (pl == null)
p = pr;
//hash碰撞下,hash值相同,key不同或者key为null,如果右节点不存在,查找右节点
else if (pr == null)
p = pl;
//hash碰撞下,hash值相同,key不同,左右节点都存在的情况下
else if ((kc != null ||
(kc = comparableClassFor(k)) != null) &&
(dir = compareComparables(kc, k, pk)) != 0)
p = (dir < 0) ? pl : pr;
else if ((q = pr.find(h, k, kc)) != null)
return q;
else
p = pl;
} while (p != null);
return null;
}
/**
* 从根节点开始查找元素
*/
final TreeNode<K,V> getTreeNode(int h, Object k) {
return ((parent != null) ? root() : this).find(h, k, null);
}5、红黑树的形态转换实现
即将红黑树转换成基础的单向链表,或者由单向链表转换成红黑树结构。
/**
* 将单向链表结构的TreeNode转换成红黑树结构,原有的链表结构基本没有变化,只是将红黑树的根节点作为链表元素的第一个节点而已
* 在调用此方法前,此元素对应的单向链表的Node已经全部转换成TreeNode了
* @return root of tree
*/
final void treeify(Node<K,V>[] tab) {
TreeNode<K,V> root = null;
for (TreeNode<K,V> x = this, next; x != null; x = next) {
next = (TreeNode<K,V>)x.next;
x.left = x.right = null;
//root为空时将当前节点置为根节点,置为黑色
if (root == null) {
x.parent = null;
x.red = false;
root = x;
}
else {
K k = x.key;
int h = x.hash;
Class<?> kc = null;
for (TreeNode<K,V> p = root;;) {
int dir, ph;
K pk = p.key;
//比较根节点和目标节点的hash值,如果dir小于等于0则目标节点作为根节点的左节点,否则作为右节点
if ((ph = p.hash) > h)
dir = -1;
else if (ph < h)
dir = 1;
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0)
dir = tieBreakOrder(k, pk);
TreeNode<K,V> xp = p;
//如果当前根节点的左节点或者右节点为空则将目标节点插入对应的左节点或者右节点
//否则继续遍历,直到找到对应的插入位置
if ((p = (dir <= 0) ? p.left : p.right) == null) {
//将当前节点的父节点设置根节点,根据dir将当前节点设置根节点的左节点或者右节点
x.parent = xp;
if (dir <= 0)
xp.left = x;
else
xp.right = x;
//确保插入后满足红黑树的规则
root = balanceInsertion(root, x);
break;
}
}
}
}
//将红黑树的根节点作为链表结构的第一个节点
moveRootToFront(tab, root);
}
/**
*将红黑树转换成链表
*/
final Node<K,V> untreeify(HashMap<K,V> map) {
Node<K,V> hd = null, tl = null;
for (Node<K,V> q = this; q != null; q = q.next) {
//replacementNode是构造一个普通的链表Node
Node<K,V> p = map.replacementNode(q, null);
//当前节点是链表第一个元素,
if (tl == null)
hd = p;
else
//将当前节点置为上一个节点的下一个节点
tl.next = p;
//tl表示上一个节点
tl = p;
}
return hd;
}6、红黑树的扩容切分实现
具体来说就是将一颗红黑树中的元素几乎均匀的分到两个红黑树中,该实现是基于HashMap的容量的,切分时先将原有的链表转换成两个链表,再判断两个链表的长度是否做形态转换。
//此处的bit是数组长度,即HashMap的容量,是2的n次方,index是数组的索引
final void split(HashMap<K,V> map, Node<K,V>[] tab, int index, int bit) {
TreeNode<K,V> b = this;
// 切分成lo 和 hi的两个链表,lc和hc分别表示两个链表的长度
TreeNode<K,V> loHead = null, loTail = null;
TreeNode<K,V> hiHead = null, hiTail = null;
int lc = 0, hc = 0;
//从当前节点开始往下遍历
for (TreeNode<K,V> e = b, next; e != null; e = next) {
next = (TreeNode<K,V>)e.next;
e.next = null;
//根据此条件判断是hi链表还是lo链表,此处的位运算需要重点关注
if ((e.hash & bit) == 0) {
//不断将当前元素追加到lo链表后面
if ((e.prev = loTail) == null)
loHead = e;
else
loTail.next = e;
loTail = e;
++lc;
}
else {
//不断将当前元素追加到hi链表后面
if ((e.prev = hiTail) == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
++hc;
}
}
if (loHead != null) {
//如果lo链表的长度小于阈值
if (lc <= UNTREEIFY_THRESHOLD)
tab[index] = loHead.untreeify(map);
else {
tab[index] = loHead;
//hiHead为null表明当前tab没有被拆分,依然还是一颗树,不需要重新树化
if (hiHead != null)
loHead.treeify(tab);
}
}
if (hiHead != null) {
if (hc <= UNTREEIFY_THRESHOLD)
tab[index + bit] = hiHead.untreeify(map);
else {
tab[index + bit] = hiHead;
if (loHead != null)
hiHead.treeify(tab);
}
}
}重点关注其中的位运算,假如bit是256,二进制表示为1,0000,0000,计算e.hash & bit时,只有e的hash值的二进制表示的第9位为1时,该表达式才为1,其他情形都是0,因为第9位1和0的概率是相等的,因此就几乎均匀的将原有的链表分成了两个不同的链表。
算数组索引的表达式是(n – 1) & hash,n为数组长度。假如原有的n是256,n-1的二进制表示就是1111,1111,高位的hash值比如1,0000,1111,对应的数组索引位置是1111,低位的hash值比如0,0011,1100, 对应的索引位置是11,1100。执行扩容后n变成512,n-1变成1,1111,1111, 这时高位hash对应的索引位置变成1,0000,1111,即比原来的索引位置增加了原有的容量256,低位hash值对应的索引位置没变依然是11,1100。如此就很巧妙很轻松的算出了切分多出来的另一个链表在数组中的位置。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/126798.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
