大家好,又见面了,我是你们的朋友全栈君。作者:刘诗昆
链接:https://www.zhihu.com/question/41979241/answer/123545914
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
2018.1. 二次更新 / 重点介绍迁移学习和其相关方向,完整删除之前的答案,并重新规整了迁移学习内容和代表性文章。
先简单说下自己的想法:综合faster rcnn等一些列相关论文来看,迁移学习的本质就是将任务A训练出来的模型用来初始化任务B的模型参数,使任务B能够更快的学习训练收敛。指的注意的是,任务A和B有强烈的相关性,不能跨越不同类型的任务;同时,原有网络层要么删掉要么添加新的连接层关系,直接改动原有网络的参数的时候,再拿来做任务B的预训练模型的话,会产生参数爆炸现象,使得任B的训练结果很差。小结一下(如果错误欢迎批评指正):
1.删除原有自己不需要的层;
2.需要留下的层的参数不改变;
3.可辅助增加新的层关系;
4.保证相互衔接的层之间的数据维度关系匹配,比如原A输入到全连接层的数据维度是512*7*7,修改网络后输入到FC层的维度也要是512*7*7,保持一致;
5.可使用全连接层改变输出的数据维度;
什么是/为什么要迁移学习?
迁移学习(Transfer learning) 顾名思义就是就是把已学训练好的模型参数迁移到新的模型来帮助新模型训练。考虑到大部分数据或任务是存在相关性的,所以通过迁移学习我们可以将已经学到的模型参数(也可理解为模型学到的知识)通过某种方式来分享给新模型从而加快并优化模型的学习效率不用像大多数网络那样从零学习(starting from scratch,tabula rasa)。
迁移学习的粗略介绍
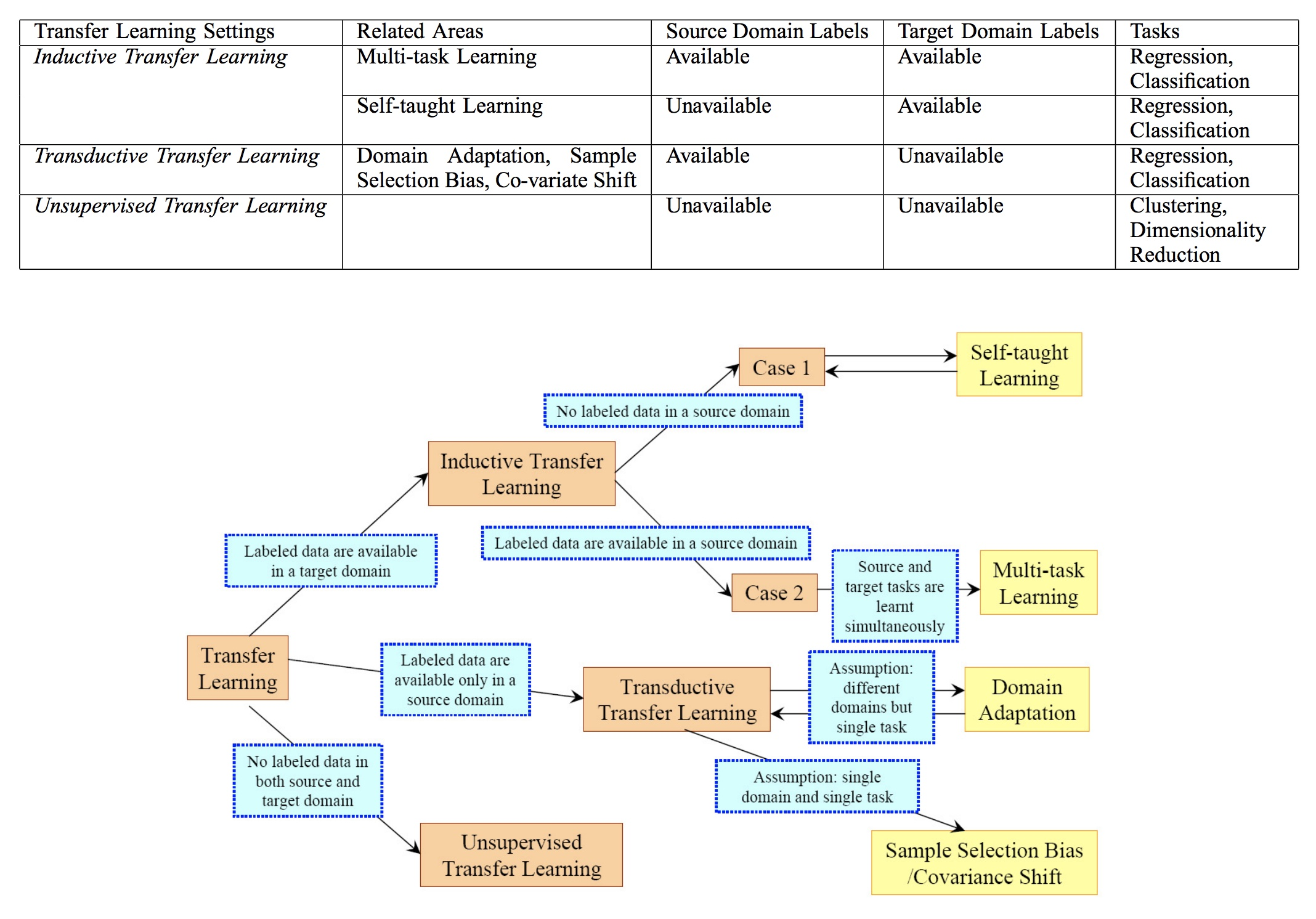
早在2009年,Sinno Jialin Pan 和 Qiang Yang 就发表了一篇迁移学习的survey [link]。他们将迁移学习通过Source (迁移源) / Target (迁移目标) Domain Label 更细节的分支为以下几个方向:

并给出了数学定义:
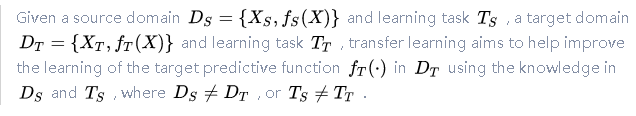
Inductive Transfer Learning
Inductive 的语义解释为归纳,我们可以直接理解为学习适用于Target Domain的网络特征。尤其注意,在 inductive 的迁移学习里,我们有 Target Domain 的 Ground Truth Label,这就意味着我们想要迁移的数据所在 Domain 将直接会学习网络和其特征提供指导作用(假设用深度学习方法,则通过Back-progagation方式)。
Self-Taught Learning
Self-Taught Learning 若直接放在现在深度学习的背景下意义并不明。根据原作者引用的文献来看,他们先从网络上下载大量的图片,通过 Sparse Coding 的方式学习通用普世的图片特征,再直接从中找给定的任务比如图片分类所用的图片特征来做迁移学习。(注意文章发表于09年前,所以那时候 Sparse Coding 的热潮相当于现在 Deep Learning 的热潮)
我们把这个思想放在现在的深度学习上,有点类同于通过 ImageNet 或其他大型数据集学习到的网络特征运用于一个图片分类或其他基于图片特征的任务。
而基于 pre-trained model 的网络训练对于 train-from-scratch 的提升有多少,相信大家对于不同的实验任务里有自己的经验。但不可否认,在绝大多数的情况下,有 ImageNet pre-trained 训练的模型在泛化能力上有或多或少的提升。其中有一篇论文也论述了好的初始值对于模型训练的重要性:[ALL YOU NEED IS A GOOD INIT]
由于神经网络训练局限于一个性质叫 Catastrophic Forgetting,意思是如果我们将 pre-trained 的模型作为初始值训练一个全新的任务,模型之前学习到的特征将灾难性遗忘,也意味着之前网络训练的任务结果将非常糟糕。
由于这一的性质,所有单一基于最原始的深度学习的任务看上去都像暴力求解,只适用于特定任务,并无法得到像人类一样通向普世的学习特征。
当然,也有部分工作尝试寻找解决 Catastrophic Forgetting 的方法,认知度较高的是:
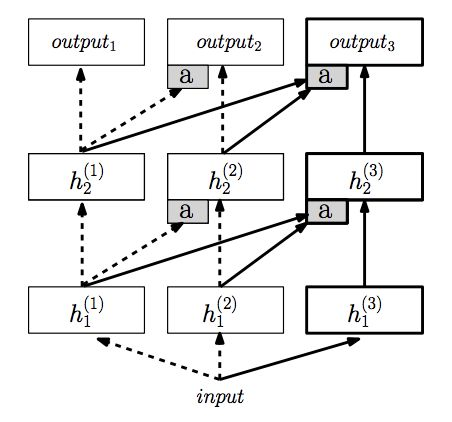
- Progressive Neural Networks – 通过 Lateral Connection 的方式将一学习好的模型参数通过另一层网络教给一个新的任务。由于在网络设计中,已训练完成的模型将会被 Freeze 因此在 back-propagation 优化参数的方式并不影响已学习完成的网络。这种网络设计很自然的避免了 Catastrophic Forgetting 的出现,但也引出了一些新的问题。
- 不断的加入新的任务会引出新的网络分支,以及 lateral connection 分支,这种学习效率显然是很低的,因为我们一次只能学一个任务。
- 我们无法确定先学哪个任务将会给后续的任务有一个最好的结果。i.e. 我们不清楚任何关于任务的相关和层级信息,因此找到最优方法需要 n 个任务的排列也就是 n! 种方式,再一次突出了学习效率之低。(better to learn from A -> B or B -> A?)
Progressive Neural Network / Visualisation
- Overcoming catastrophic forgetting in neural networks – 显然 DeepMind 自己也不会满足这样的网络设计,对此问题再次进行研究。这次他们不直接用于 Deep Learning 的 back-propagation 方式而专注于 Bayesian Learning 通过 Full Bayesian posterior distribution 来计算网络参数。他们的方法,Elastic Weight Consolidation (EWC), 通过 Laplace Approximation 的方式来计算 Bayesian 那也无法进行数值计算的 log-likelihood,最后取得相当不错的效果。更多 comment 和介绍可参看这篇博文[link]。
Multi-task Learning
多任务学习 (multi-task learning) 与上个章节介绍的方向最大的不同是我们需要把 Source 和 Target 两个或者更多任务同时学好。在多任务学习中,任一任务的训练目标都是同等重要的。因此,这里 Source/Target Domain 的分类姑且没有太大意义(除非特定情况)。
进行多任务学习我们主要希望观察并研究:
- 多任务学习是否可以帮助网络学习一个泛化能力更好的特征?
- 通过多任务学习,我们能否寻找并理解不同任务的相关性和层级性?
最简单直接的多任务学习网络就是直接应用一个普通的网络结构在最后输出层前分叉到不同的任务预测层。而这样的设计真的可以帮助网络学习到好的特征么?
- Cross-stitch Networks for Multi-task Learning – 这篇文章就直接暴力了测试了所有分叉的可能性,并指出不同的任务在不同的分叉上效果。后续他们提出了一个叫 Cross-Stitch Network 的网络结构,通过矩阵中 linear combination 的方式来融合不同任务里学到的特征。
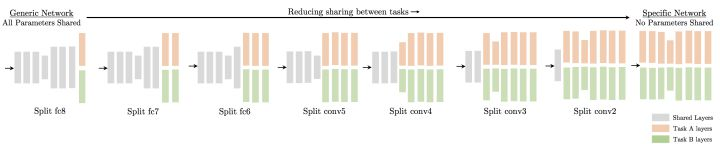
- Multi-task Self-Supervised Visual Learning – 类似的想法也出现在 Zisserman 最新的文章里。与 Cross-stitch Network 最大的不同是,这篇文章里并未将不同的任务分成不同的网络分支,而使用单一的网络结构,仅仅在基于 ResNet-101 的网络结构尾部 block 3 里的 23个 residual unit 通过 sparse linear combination的方式来输出各自的任务预测层。
除了网络设计,多任务学习中还有一个 Open Question 就是,如何寻找训练权重?
由于任务难度和数据集不同的缘故,在进行多任务学习中,有一种情况是网络中学到的特征被某一任务 dominate。一个简单的例子:我们同时训练 MNIST 和 ImageNet。由于我们知道MNIST是一个极其简单的数据集,而ImageNet是一个数据量大且复杂的多的数据集。那么模型训练将飞快的收敛 MNIST 的识别任务,且慢慢变成是基于 MNIST 特征网络的初始值的 ImageNet 训练。
近期 Kaiming He 提出的 Focal Loss for Dense Object Detection 重新刷新了我们对分类和识别任务的认知,尤其对 gradient propagation 的重要性有了新的理解。那么我们能否也找到一种类似的改进 loss function 的方法来帮助网络去训练一个 unbiased feature representation 呢?
- Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics – 这篇文章就探讨了这个问题,提出了同样基于 Bayesian 的 maximise log-likelihood 来优化 loss function。
- GRADNORM: GRADIENT NORMALIZATION FOR ADAPTIVE LOSS BALANCING IN DEEP MULTITASK NETWORKS – 在最新的 ICLR 2017 会议中也出现了一篇文章讨论这个问题。他们的方法更偏向于解决:如何数值定义什么是一个 easy task。文章的观点是在每个training step,如果你的 training loss 相比较 step 0 的 training loss 越小,那么就越可能是 easy step。 以此通过计算 relative training rate 来更新每个任务的权重。
对于 Multi-task Learning 的更多介绍可参考这个博文:An Overview of Multi-Task Learning for Deep Learning。
Transductive Transfer Learning
Transductive 的字面意思是转导,通常来说要比 inductive transfer learning 要难的多。由于直接缺乏 Target Domain Label,在这个情况,我们只能依赖于 Source Domain 信息来尽可能的训练出泛化能力强的特征。
Domain Adaptation / Generalisation
Domain Adaptation 目标是学习 domain-invariant feature 使得学习到的特征不受限于 Source Domain 而导致 over-fitting。其主要会测试于 Office Dataset –Domain Adaptation – UC Berkeley,其中分为三个 Domain 其一是 Amazon 上扒的图片,另外两个是实体拍摄图片但一个高分辨率一个是低分辨率。
比较具有代表性的作品:
- Unsupervised Domain Adaptation by Backpropagation – 个人很喜欢这篇文章。这篇文章的新颖点是利用 classifier 在 Source 和 Target Domain 的相似性,通过 Source Domain 的 back-propagation 同时算出 Source 和 Target Domain 的 gradient 并将两者梯度结合来更新 feed-forward 的 feature extractor 。这样的设计会将 feature extractor 在没有 Target Label 的情况下也能学会 Target Domain 的 feature。
- Learning Transferable Features with Deep Adaptation Networks – 本文作者是清华大学的Mingsheng Long 也是 Domain Adaptation 的专家,可从 Google Scholar 上看出他的近乎所有文章都在研究这个问题。这篇文章包括作者后续的文章里都用到了一个叫作 max mean discrepancies (MMD) 定义为 Source Target Domain 的 feature 距离方式。将此距离包含于 loss function 会有助于网络避免出现 co-variant shift 使得学习到的特征是 domain-invariant。
因此不可否认,现在尝试解决 Domain Adaptation 的方法都不得不利用 Target Domain 的信息去缩小 co-variant shift. 完全只利用于 Source Domain 的信息仍然是个重要的课题。
Unsupervised Transfer Learning
在这个方向可适用于的任务非常有限,比如 Dimension Reduction。由于缺乏 Source Label 因此也无法采用绝大部分的 Deep Learning 方法,(但比如Auto-encoder 是其中一个基于 Deep Learning 的降维方式,但很难归类于 Transfer Learning)。因此这里不展开讨论了。
关于迁移学习大致概括到此为止,更多相关文献希望读者直接找相关的论文研读。
后面是我提出一些公开问题,让大家重新思考迁移学习的意义和重要性。
重新思考1:迁移学习一定有用吗?
事实上,即使在前文 survey 的数学定义里都提到了迁移学习是 “aim to improve”。但事实上,在特定情况下迁移学习甚至会产生相反的效果。这种情况叫 negative transfer。在进行迁移学习的时候,我们都默认不同的任务具备相关性,但如何定义相关性,如何数学描述任务之间相关性的强弱都是偏向人类的主观决定。我们经常使用 ImageNet 作为 fine-tuning 的 pre-trained model 因为 ImageNet 本身数据集之大保证了学习的网络有较高的泛化性,但如果用的小的数据集呢?结果还会一样么?还是会比从零学习的网络更差?
e.g. DeepMind 新出的 AlphaGo Zero 就是从零学习的比前一个版本基于人类图谱的 AlphaGo Lee 要强的多。
重新思考2:多任务学习一定在学通用的特征吗?
即使有相当多的实验结果表明,多任务学习比单任务学习的准确率较高,或者说泛化能力更强。但是多任务学习是否真正在学通用的特征我们无从得知。也有可能多任务学习仅仅是部分神经元负责负责特定网络,由于这多任务的分配导致网络结构比单任务小了而提高准确度我们也可说不是不可能。如何理解多任务网络结构,如何观察并确认特征的泛化能力也是一个重要的问题。
一些总结和展望
迁移学习无疑是机器学习里重要的问题之一。理解迁移学习不仅可以让我们理解学习到的特征而且让我们重新理解了神经网络”学习“的本质和方式。近期在迁移学习上的文章和研究不断的增多,但仍然有很多公开问题值得我们去挖掘和思考。希望这篇回答能给读者对迁移学习有着一定的认知,后期我会继续更新此回答如果有高价值的研究更新。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/126772.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
