大家好,又见面了,我是你们的朋友全栈君。
键值对 RDD 通常用来进行聚合计算。我们一般要先通过一些初始 ETL(抽取、转化、装载)操作来将数据转化为键值对形式。键值对 RDD 提供了一些新的操作接口(比如统计每个产品的评论,将数据中键相同的分为一组,将两个不同的 RDD 进行分组合并等)。
1. 动机
Spark 为包含键值对类型的 RDD 提供了一些专有的操作。这些 RDD 被称为 pair RDD 。PairRDD 是很多程序的构成要素,因为它们提供了并行操作各个键或跨节点重新进行数据分组的操作接口。例如,pair RDD 提供 reduceByKey() 方法,可以分别归约每个键对应的数据,还有 join() 方法,可以把两个 RDD 中键相同的元素组合到一起,合并为一个 RDD。
2. 创建Pair RDD
Pair RDD就是元素为二元组(tuple)的RDD。在Spark中有多种方式创建Pair RDD,其中有两种比较常见:
- 很多存储键值对的数据格式会在读取时直接返回由其键值对数据组成的 pair RDD。
- 当需要把一个普通的 RDD 转为 pair RDD 时,可以调用
map()函数来实现,传递的函数需要返回键值对。
Example(Python):
listRDD = sc.parallelize([1, 2, 3, 4])
pairRDD = listRDD.map(lambda x: (x, "brown"))Example(Scala):
val listRDD = sc.parallelize(List(1, 2, 3, 4))
val pairRDD = listRDD.map(x => (x, "brown"))3. Pair RDD的转化操作
Pair RDD 可以使用所有标准 RDD 上的可用的转化操作。表 4-1 和表 4-2 总结了对 pair RDD 的一些转化操作:




(1)聚合操作
当数据集以键值对形式组织的时候,聚合具有相同键的元素进行一些统计是很常见的操作。之前讲解过基础 RDD 上的 fold() 、 combine() 、 reduce() 等行动操作,pair RDD 上则有相应的针对键的转化操作。Spark 有一组类似的操作,可以组合具有相同键的值。这些操作返回 RDD,因此它们是转化操作而不是行动操作。
聚合操作主要涉及三个函数:reduceByKey(),foldByKey(),combineByKey()。
reduceByKey():reduceByKey()与reduce()相当类似;它们都接收一个函数,并使用该函数对值进行合并。reduceByKey()会为数据集中的每个键进行并行的归约操作,每个归约操作会将键相同的值合并起来。它会返回一个由各键和对应键归约出来的结果值组成的新的 RDD。foldByKey(): 与fold()相当类似;它们都使用一个与 RDD 和合并函数中的数据类型相同的零值作为初始值。与fold()一样,foldByKey()操作所使用的合并函数对零值与另一个元素进行合并,结果仍为该元素。(??)-
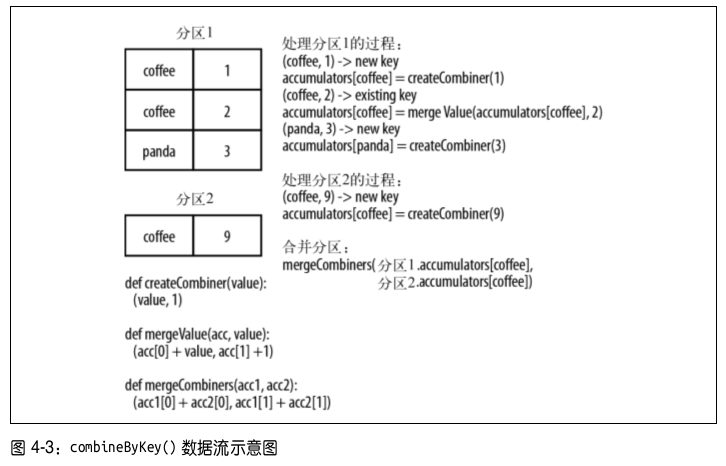
combineByKey(): 它是最为常用的基于键进行聚合的函数。大多数基于键聚合的函数都是用它实现的。和aggregate()一样,combineByKey()可以让用户返回与输入数据的类型不同的返回值。要 理 解
combineByKey(), 要 先 理 解 它 在 处 理 数 据 时 是 如 何 处 理 每 个 元 素 的。 由 于combineByKey()会遍历分区中的所有元素,因此每个元素的键要么还没有遇到过,要么就和之前的某个元素的键相同。- 如果这是一个新的元素,
combineByKey()会使用一个叫作createCombiner()的函数来创建那个键对应的累加器的初始值。需要注意的是,这一过程会在每个分区中第一次出现各个键时发生,而不是在整个 RDD 中第一次出现一个键时发生。 - 如果这是一个在处理当前分区之前已经遇到的键,它会使用
mergeValue()方法将该键的累加器对应的当前值与这个新的值进行合并。 - 由于每个分区都是独立处理的,因此对于同一个键可以有多个累加器。如果有两个或者更多的分区都有对应同一个键的累加器,就需要使用用户提供的
mergeCombiners()方法将各个分区的结果进行合并。
- 如果这是一个新的元素,
Example1:
在 Python 中使用 reduceByKey() 和 mapValues() 计算每个键对应的平均值:
rdd.mapValues(lambda x: (x, 1)).reduceByKey(lambda x, y: (x[0] + y[0], x[1] + y[1]))在 Scala 中使用 reduceByKey() 和 mapValues() 计算每个键对应的平均值:
rdd.mapValues(x => (x, 1)).reduceByKey((x, y) => (x._1 + y._1, x._2 + y._2))数据流图示:
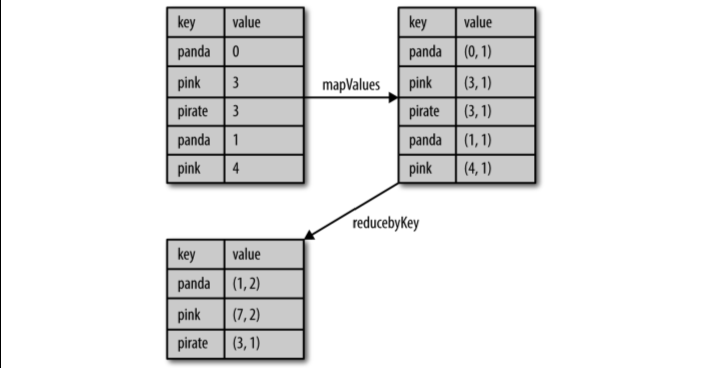
注意: 熟悉 MapReduce 中的合并器(combiner)概念的读者可能已经注意到,调用 reduceByKey() 和 foldByKey() 会 在 为 每 个 键 计 算 全 局 的 总 结 果 之 前先自动在每台机器上进行本地合并。用户不需要指定合并器。更泛化的combineByKey() 接口可以让你自定义合并的行为。
Example2:
combineByKey() 有多个参数分别对应聚合操作的各个阶段,因而非常适合用来解释聚合操作各个阶段的功能划分。为了更好地演示combineByKey() 是如何工作的,下面来看看如何计算各键对应的平均值:
在 Python 中使用 combineByKey() 求每个键对应的平均值:
sumCount = nums.combineByKey((lambda x: (x,1)),
(lambda x, y: (x[0] + y, x[1] + 1)),
(lambda x, y: (x[0] + y[0], x[1] + y[1])))
sumCount.map(lambda key, xy: (key, xy[0]/xy[1])).collectAsMap()在 Scala 中使用 combineByKey() 求每个键对应的平均值:
val result = input.combineByKey(
(v) => (v, 1),
(acc: (Int, Int), v) => (acc._1 + v, acc._2 + 1),
(acc1: (Int, Int), acc2: (Int, Int)) => (acc1._1 + acc2._1, acc1._2 + acc2._2)
).map{ case (key, value) => (key, value._1 / value._2.toFloat) }
result.collectAsMap().map(println(_))数据流向图:
(2)并行度,分区数调节
每个 RDD 都有固定数目的分区,分区数决定了在 RDD 上执行操作时的并行度。Spark 始终尝试根据集群的大小推断出一个有意义的默认值,但是有时候你可能要对并行度进行调优来获取更好的性能表现。
如何调节分区数(并行度)呢?
- 在执行聚合或分组操作时,可以要求 Spark 使用给定的分区数。聚合分组操作中,大多数操作符都能接收第二个参数,这个参数用来指定分组结果或聚合结果的RDD 的分区数。如:
rdd.reduceByKey((x, y) => x + y, 10)。 - 在除分组操作和聚合操作之外的操作中也能改变 RDD 的分区。Spark 提供了
repartition()函数。它会把数据通过网络进行混洗,并创建出新的分区集合。切记,对数据进行重新分区是代价相对比较大的操作。Spark 中也有 一 个 优 化 版 的 repartition() , 叫 作coalesce()。 你 可 以 使 用 Java 或 Scala 中 的rdd.partitions.size()以及 Python 中的rdd.getNumPartitions查看 RDD 的分区数,并确保调用coalesce()时将 RDD 合并到比现在的分区数更少的分区中。
(3) 数据分组
数据分组主要涉及三个函数:groupByKey(),groupBy(),cogroup()。
groupByKey(): 它会使用 RDD 中的键来对数据进行分组。对于一个由类型K的键和类型V的值组成的 RDD,所得到的结果 RDD 类型会是[K, Iterable[V]]。groupBy(): 它可以用于未成对的数据上,也可以根据除键相同以外的条件进行分组。它可以接收一个函数,对源 RDD 中的每个元素使用该函数,将返回结果作为键再进行分组。cogroup(): 除了对单个 RDD 的数据进行分组,还可以使用一个叫作cogroup()的函数对多个共享同一个键的 RDD 进行分组。对两个键的类型均为K而值的类型分别为V和W的 RDD 进行cogroup()时,得到的结果 RDD 类型为[(K, (Iterable[V], Iterable[W]))]。如果其中的一个 RDD 对于另一个 RDD 中存在的某个键没有对应的记录,那么对应的迭代器则为空。cogroup()提供了为多个 RDD 进行数据分组的方法。
注意:
- 如果你发现自己写出了先使用
groupByKey()然后再对值使用reduce()或者fold()的代码,你很有可能可以通过使用一种根据键进行聚合的函数来更高效地实现同样的效果。你不应该使用前者,因为前者涉及到了行动操作,更消耗内存,后者只是转化操作。 cogroup()不仅可以用于实现连接操作,还可以用来求键的交集。除此之外,cogroup()还能同时应用于三个及以上的 RDD。
(4)连接
连接数据可能是 pair RDD 最常用的操作之一。连接方式多种多样:右外连接、左外连接、交叉连接以及内连接。
-
内连接: 普通的join操作符表示内连接。只有两个 pair RDD 中都存在的键才有输出。当一个输入对应的某个键有多个值时,生成的 pair RDD 会包括来自两个输入 RDD 的每一组相对应的记录。看个例子:
storeAddress = { (Store("Ritual"), "1026 Valencia St"), (Store("Philz"), "748 Van Ness Ave"), (Store("Philz"), "3101 24th St"), (Store("Starbucks"), "Seattle") } storeRating = { (Store("Ritual"), 4.9), (Store("Philz"), 4.8)) } storeAddress.join(storeRating) == { (Store("Ritual"), ("1026 Valencia St", 4.9)), (Store("Philz"), ("748 Van Ness Ave", 4.8)), (Store("Philz"), ("3101 24th St", 4.8)) } -
左外连接: 在使用
leftOuterJoin()产生的 pair RDD 中,源 RDD 的每一个键都有对应的记录。每个键相应的值是由第一个 RDD 中的值与一个包含第二个 RDD 的值的Option(在 Java 中为Optional)对象组成的二元组。在 Python 中,如果一个值不存在,则使用None来表示,而数据存在时就用常规的值来表示,不使用任何封装。看这个例子:
storeAddress = { (Store("Ritual"), "1026 Valencia St"), (Store("Philz"), "748 Van Ness Ave"), (Store("Philz"), "3101 24th St"), (Store("Starbucks"), "Seattle") } storeRating = { (Store("Ritual"), 4.9), (Store("Philz"), 4.8)) } storeAddress.leftOuterJoin(storeRating) =={ (Store("Ritual"),("1026 Valencia St",Some(4.9))), (Store("Starbucks"),("Seattle",None)), (Store("Philz"),("748 Van Ness Ave",Some(4.8))), (Store("Philz"),("3101 24th St",Some(4.8))) } -
右连接:
rightOuterJoin()几乎与leftOuterJoin()完全一样,只不过预期结果中的键必须出现在第二个 RDD 中,而二元组中的可缺失的部分则来自于第一个 RDD 而非第二个 RDD。看这个例子:
storeAddress = { (Store("Ritual"), "1026 Valencia St"), (Store("Philz"), "748 Van Ness Ave"), (Store("Philz"), "3101 24th St"), (Store("Starbucks"), "Seattle") } storeRating = { (Store("Ritual"), 4.9), (Store("Philz"), 4.8)) } storeAddress.rightOuterJoin(storeRating) =={ (Store("Ritual"),(Some("1026 Valencia St"),4.9)), (Store("Philz"),(Some("748 Van Ness Ave"),4.8)), (Store("Philz"), (Some("3101 24th St"),4.8)) }
(5)数据排序
我们经常要将 RDD 倒序排列,因此 sortByKey() 函数接收一个叫作 ascending 的参数,表示我们是否想要让结果按升序排序(默认值为 true )。有时我们也可能想按完全不同的排序依据进行排序。要支持这种情况,我们可以提供自定义的比较函数。
在 Python 中以字符串顺序对整数进行自定义排序:
rdd.sortByKey(ascending=True, numPartitions=None, keyfunc = lambda x: str(x))在 Scala 中以字符串顺序对整数进行自定义排序:
// 隐式排序
implicit val sortIntegersByString = new Ordering[Int] {
override def compare(a: Int, b: Int) = a.toString.compare(b.toString)
}
rdd.sortByKey()4. Pair RDD行动操作
和转化操作一样,所有基础 RDD 支持的传统行动操作也都在 pair RDD 上可用。Pair RDD提供了一些额外的行动操作,可以让我们充分利用数据的键值对特性。这些操作列在了下表:

5. 数据分区
在分布式程序中,通信的代价是很大的,因此控制数据分布以获得最少的网络传输可以极大地提升整体性能。只有当数据集多次在诸如连接这种基于键的操作中使用时,分区才会有帮助。
Spark的分区方法:
Spark 中所有的键值对 RDD 都可以进行分区。系统会根据一个针对键的函数对元素进行分区。尽管 Spark 没有给出显示控制每个键具体落在哪一个工作节点上的方法(部分原因是Spark 即使在某些节点失败时依然可以工作),但 Spark 可以确保同一分区的键出现在同一个节点上。比如,你可能使用哈希分区将一个 RDD 分成了 100 个分区,此时键的哈希值对100 取模的结果相同的记录会被放在一个节点上。你也可以使用范围分区法,将键在同一个范围区间内的记录都放在同一个节点上。
分区,RDD,节点的关系:
- a single RDD has one or more partitions scattered across multiple nodes.
- a single partition is processed on a single node.
- a single node can handle multiple partitions.
Example:
我们分析这样一个应用,它在内存中保存着一张很大的用户信息表——也就是一个由 (UserID, UserInfo) 对组成的 RDD,其中 UserInfo 包含一个该用户所订阅的主题的列表。该应用会周期性地将这张表与一个小文件进行组合,这个小文件中存着过去五分钟内发生的事件——其实就是一个由 (UserID, LinkInfo) 对组成的表,存放着过去五分钟内某网站各用户的访问情况。例如,我们可能需要对用户访问其未订阅主题的页面的情况进行统计。我们可以使用 Spark 的 join() 操作来实现这个组合操作,其中需要把UserInfo 和 LinkInfo 的有序对根据 UserID 进行分组。我们的应用如下例所示:
// 初始化代码;从HDFS上的一个Hadoop SequenceFile中读取用户信息
// userData中的元素会根据它们被读取时的来源,即HDFS块所在的节点来分布
// Spark此时无法获知某个特定的UserID对应的记录位于哪个节点上
val sc = new SparkContext(...)
val userData = sc.sequenceFile[UserID, UserInfo]("hdfs://...").persist()
// 周期性调用函数来处理过去五分钟产生的事件日志
// 假设这是一个包含(UserID, LinkInfo)对的SequenceFile
def processNewLogs(logFileName: String) {
val events = sc.sequenceFile[UserID, LinkInfo](logFileName)
val joined = userData.join(events)// RDD of (UserID, (UserInfo, LinkInfo)) pairs
val offTopicVisits = joined.filter {
case (userId, (userInfo, linkInfo)) => // Expand the tuple into its components
!userInfo.topics.contains(linkInfo.topic)
}.count()
println("Number of visits to non-subscribed topics: " + offTopicVisits)
}这段代码可以正确运行,但是不够高效。这是因为在每次调用 processNewLogs() 时都会用到 join() 操作,而我们对数据集是如何分区的却一无所知。默认情况下,连接操作会将两个数据集中的所有键的哈希值都求出来,将该哈希值相同的记录通过网络传到同一台机器上,然后在那台机器上对所有键相同的记录进行连接操作(见图 4-4)。
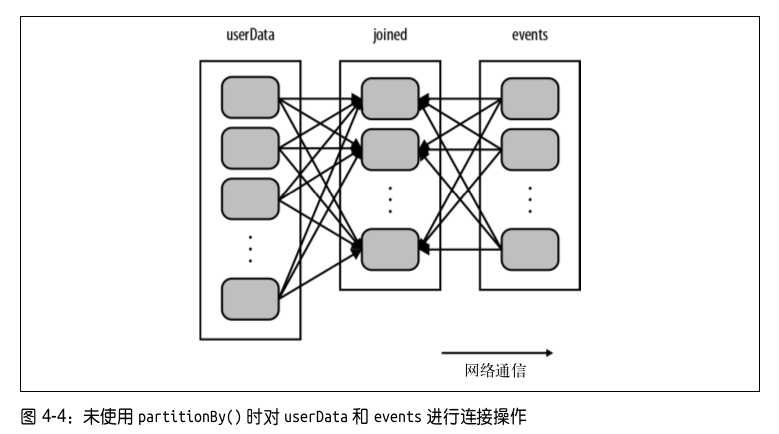
因为 userData 表比每五分钟出现的访问日志表 events 要大得多,所以要浪费时间做很多额外工作:在每次调用时都对 userData 表进行哈希值计算和跨节点数据混洗,虽然这些数据从来都不会变化。
要解决这一问题也很简单:在程序开始时,对userData 表使用 partitionBy() 转化操作,将这张表转为哈希分区。可以通过向 partitionBy 传递一个 spark.HashPartitioner 对象来实现该操作。
Scala 自定义分区方式:
val sc = new SparkContext(...)
val userData = sc.sequenceFile[UserID, UserInfo]("hdfs://...")
.partitionBy(new HashPartitioner(100)) // 构造100个分区
.persist()processNewLogs() 方 法 可 以 保 持 不 变,由于在构建 userData 时 调 用 了 partitionBy() ,Spark 就 知 道 了 该 RDD 是 根 据 键 的 哈 希 值 来 分区的,这样在调用 join()时,Spark 就会利用到这一点。具体来说,当调用 userData.join(events) 时,Spark 只会对 events 进行数据混洗操作,将 events 中特定 UserID 的记录发送到 userData 的对应分区所在的那台机器上,如下图:
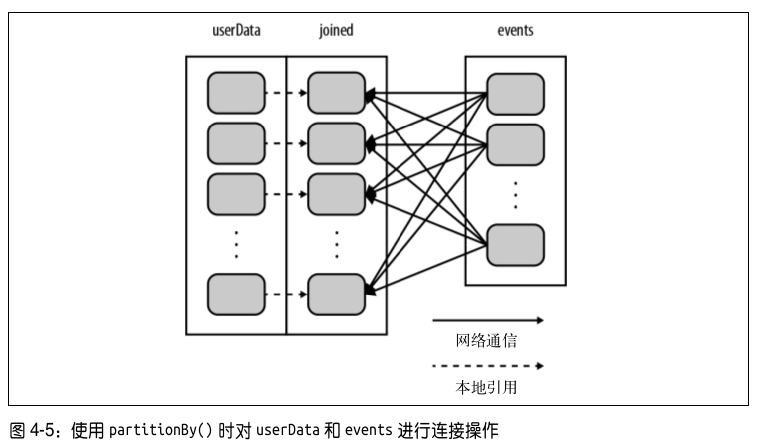
这样,需要通过网络传输的数据就大大减少了,程序运行速度也可以显著提升了。
Q:为什么分区之后userData就不会发生混洗(shuffle)了?
A:先看一下混洗的定义:混洗是Spark对于重新分发数据的机制,以便于它在整个分区中分成不同的组。这通常会引起在执行器和机器上之间复制数据,使得混洗是一个复杂而开销很大的操作。我们使用了哈希分区方式,它会将具有相同的key的元素放到同一个分区/分组,也就是说不存在了两个分区有相同key的元素的情况,所以join时就不会再次发生分组,不会有shuffle的操作。(个人理解,有误请指正)
注意:
在 Python 中,你不能将 HashPartitioner 对象传给 partitionBy ,而需要把需要的分区数传递过去(例如 rdd.partitionBy(100) )。
(1)获取RDD的分区方式
在 Scala 和 Java 中,你可以使用 RDD 的 partitioner 属性(Java 中使用 partitioner() 方法)来获取 RDD 的分区方式。它会返回一个 scala.Option 对象,这是 Scala 中用来存放可能存在的对象的容器类。你可以对这个 Option 对象调用 isDefined() 来检查其中是否有值,调用 get() 来获取其中的值。如果存在值的话,这个值会是一个 spark.Partitioner对象。这本质上是一个告诉我们 RDD 中各个键分别属于哪个分区的函数。
获取 RDD 的分区方式:
scala> val pairs = sc.parallelize(List((1, 1), (2, 2), (3, 3)))
pairs: spark.RDD[(Int, Int)] = ParallelCollectionRDD[0] at parallelize at <console>:12
scala> pairs.partitioner
res0: Option[spark.Partitioner] = None
scala> val partitioned = pairs.partitionBy(new spark.HashPartitioner(2))
partitioned: spark.RDD[(Int, Int)] = ShuffledRDD[1] at partitionBy at <console>:14
scala> partitioned.partitioner
res1: Option[spark.Partitioner] = Some(spark.HashPartitioner@5147788d)初始时没有分区方式信息(一个值为 None 的 Option 对象)。然后通过对第一个 RDD 进行哈希分区,创建出了第二个 RDD。
(2)从分区中获益的操作
Spark 的许多操作都引入了将数据根据键跨节点进行混洗的过程。所有这些操作都会从 数 据 分 区 中 获 益。就 Spark 1.0 而 言, 能 够 从 数 据 分 区 中 获 益 的 操 作 有 cogroup() 、groupWith() 、 join() 、 leftOuterJoin() 、rightOuterJoin() 、 groupByKey() 、 reduceByKey() 、combineByKey() 以及 lookup() 。
- 对于像
reduceByKey()这样只作用于单个 RDD 的操作,运行在未分区的 RDD 上的时候会导致每个键的所有对应值都在每台机器上进行本地计算,只需要把本地最终归约出的结果值从各工作节点传回主节点,所以原本的网络开销就不算大。 - 而对于诸如
cogroup()和join()这样的二元操作,预先进行数据分区会导致其中至少一个 RDD(使用已知分区器的那个 RDD)不发生数据混洗。 - 如果两个 RDD 使用同样的分区方式,并且它们还缓存在同样的机器上(比如一个 RDD 是通过 mapValues() 从另一个 RDD 中创建出来的,这两个RDD 就会拥有相同的键和分区方式),或者其中一个 RDD 还没有被计算出来,那么跨节点的数据混洗就不会发生了。
(3)影响分区方式的操作
Spark 内部知道各操作会如何影响分区方式,并将会对数据进行分区的操作的结果 RDD 自动设置为对应的分区器。
转化操作的结果并不一定会按已知的分区方式分区,这时输出的 RDD 可能就会没有设置分区器。例如,当你对一个哈希分区的键值对 RDD 调用 map() 时,由于传给 map()的函数理论上可以改变元素的键,因此结果就不会有固定的分区方式。Spark 不会分析你的函数来判断键是否会被保留下来,因而更不会保留之前设置的分区方式。不过,Spark 提供了另外两个操作 mapValues() 和flatMapValues() 作为替代方法,它们可以保证每个二元组的键保持不变。
所有会为生成的结果 RDD 设好分区方式的操作:
cogroup() 、 groupWith() 、join() 、 lef tOuterJoin() 、 rightOuterJoin() 、 groupByKey() 、 reduceByKey() 、combineByKey() 、 partitionBy() 、 sort() 、 mapValues() (如果父 RDD 有分区方式的话)、flatMapValues() (如果父 RDD 有分区方式的话),以及 filter() (如果父 RDD 有分区方式的话)。其他所有的操作生成的结果都不会存在特定的分区方式。
对于二元操作,输出数据的分区方式取决于父 RDD 的分区方式。默认情况下,结果会采用哈希分区,分区的数量和操作的并行度一样。不过,如果其中的一个父 RDD 已经设置过分区方式,那么结果就会采用那种分区方式;如果两个父 RDD 都设置过分区方式,结果 RDD 会采用第一个父 RDD 的分区方式。
(4)实例: PageRank
PageRank算法是以 Google 的拉里· 佩吉(Larry Page)的名字命名的,用来根据外部文档指向一个文档的链接,对集合中每个文档的重要程度赋一个度量值。该算法可以用于对网页进行排序,当然,也可以用于排序科技文章或社交网络中有影响的用户。
PageRank 是执行多次连接的一个迭代算法,因此它是 RDD 分区操作的一个很好的用例。算法会维护两个数据集:一个由(pageID, linkList) 的元素组成,包含每个页面的相邻页面的列表;另一个由 (pageID, rank) 元素组成,包含每个页面的当前排序权值。它按如下步骤进行计算:
- (1) 将每个页面的排序值初始化为
1.0。 - (2) 在每次迭代中,对页面
p,向其每个相邻页面(有直接链接的页面)发送一个值为rank(p)/numNeighbors(p)的贡献值。 - (3) 将每个页面的排序值设为
0.15 + 0.85 * contributionsReceived。
最后两步会重复几个循环,在此过程中,算法会逐渐收敛于每个页面的实际 PageRank 值。在实际操作中,收敛通常需要大约 10 轮迭代。
Scala 版 PageRank:
// 假设相邻页面列表以Spark objectFile的形式存储
val links = sc.objectFile[(String, Seq[String])]("links")
.partitionBy(new HashPartitioner(100))
.persist()
// 将每个页面的排序值初始化为1.0;由于使用mapValues,生成的RDD
// 的分区方式会和"links"的一样
var ranks = links.mapValues(v => 1.0)
// 运行10轮PageRank迭代
for(i <- 0 until 10) {
val contributions = links.join(ranks).flatMap {
case (pageId, (links, rank)) =>
links.map(dest => (dest, rank / links.size))
}
ranks = contributions.reduceByKey((x, y) => x + y).mapValues(v => 0.15 + 0.85*v)
}
// 写出最终排名
ranks.saveAsTextFile("ranks")注意:
- 当我们第一次创建 ranks 时,我们使用
mapValues()而不是map()来保留父 RDD(links)的分区方式,这样对它进行的第一次连接操作就会开销很小。 - 在循环体中,我们在 reduceByKey() 后使用 mapValues() ;因为 reduceByKey() 的结果已经是哈希分区的了,这样一来,下一次循环中将映射操作的结果再次与 links 进行连接操作时就会更加高效。
为了最大化分区相关优化的潜在作用,你应该在无需改变元素的键时尽量使用 mapValues() 或 flatMapValues() 。
(5)自定义分区方式
可能需要自定义分区方式的场景:
举个例子,假设我们要在一个网页的集合上运行前一节中的 PageRank 算法。在这里,每个页面的 ID(RDD 中的键)是页面的 URL。当我们使用简单的哈希函数进行分区时,拥有相似的 URL 的页面(比如 http://www.cnn.com/WORLD 和 http://www.cnn.com/US)可能会被分到完全不同的节点上。然而,我们知道在同一个域名下的网页更有可能相互链接。由于 PageRank 需要在每次迭代中从每个页面向它所有相邻的页面发送一条消息,因此把这些页面分组到同一个分区中会更好。可以使用自定义的分区器来实现仅根据域名而不是整个 URL 来分区。
Scala中:
要实现自定义的分区器,你需要继承 org.apache.spark.Partitioner类并实现下面三个方法:
numPartitions: Int:返回创建出来的分区数。getPartition(key: Any): Int:返回给定键的分区编号(0到numPartitions-1)。equals():Java 判断相等性的标准方法。这个方法的实现非常重要,Spark 需要用这个方法来检查你的分区器对象是否和其他分区器实例相同,这样 Spark 才可以判断两个RDD 的分区方式是否相同。
使用自定义的 Partitioner 是很容易的:只要把它传给 partitionBy() 方法即可。
下面展示了如何编写一个前面构思的基于域名的分区器,这个分区器只对 URL 中的域名部分求哈希。
Scala 自定义分区方式:
class DomainNamePartitioner(numParts: Int) extends Partitioner {
override def numPartitions: Int = numParts
override def getPartition(key: Any): Int = {
val domain = new Java.net.URL(key.toString).getHost()
val code = (domain.hashCode % numPartitions)
if(code < 0) {
code + numPartitions // 使其非负
}else{
code
}
}
// 用来让Spark区分分区函数对象的Java equals方法
override def equals(other: Any): Boolean = other match {
case dnp: DomainNamePartitioner => dnp.numPartitions == numPartitions
case _ => false
}
}注意:
1. 当你的算法依赖于 Java 的 hashCode() 方法时,这个方法有可能会返回负数。你需要十分谨慎,确保 getPartition() 永远返回一个非负数。
2. 我们在 equals() 方法中,使用 Scala 的模式匹配操作符( match )来检查 other 是否是DomainNamePartitioner ,并在成立时自动进行类型转换。
Python中:
在 Python 中,不需要扩展 Partitioner 类,而是把一个特定的哈希函数作为一个额外的参数传给 RDD.partitionBy() 函数。
Python 自定义分区方式:
import urlparse
def hash_domain(url):
return hash(urlparse.urlparse(url).netloc)
rdd.partitionBy(20, hash_domain) # 创建20个分区注意:
这里你所传过去的哈希函数会被与其他 RDD 的分区函数区分开来。如果你想要对多个 RDD 使用相同的分区方式,就应该使用同一个函数对象,比如一个全局函数,而不是为每个 RDD 创建一个新的函数对象。
Ref:
《Spark快速大数据分析》
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/126622.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
