大家好,又见面了,我是你们的朋友全栈君。
首先放一张我的iPhone手机导出微信聊天记录生成的词云效果图(个别敏感词汇请大家自行忽略hhh):


对于如何导出手机上的微信聊天记录,网上绝大部分教程提到的“楼月微信聊天记录导出恢复助手”和“手机博士微信聊天记录查看”等软件都是收费的,免费版本只能查看很少的几条聊天记录并且不能导出。在这里提供一种绝对免费的方法可以方便地导出微信聊天记录,后面附上根据聊天记录生成词云的教程。由于我个人的手机是ios系统,因此本篇blog暂时只针对ios系统。安卓系统想要导出微信聊天记录貌似需要开启root权限,可以参阅此教程中附的链接进行尝试。
第一步:备份手机
下载iTunes软件,用usb线将手机连接电脑,按下图所示步骤进行手机备份。
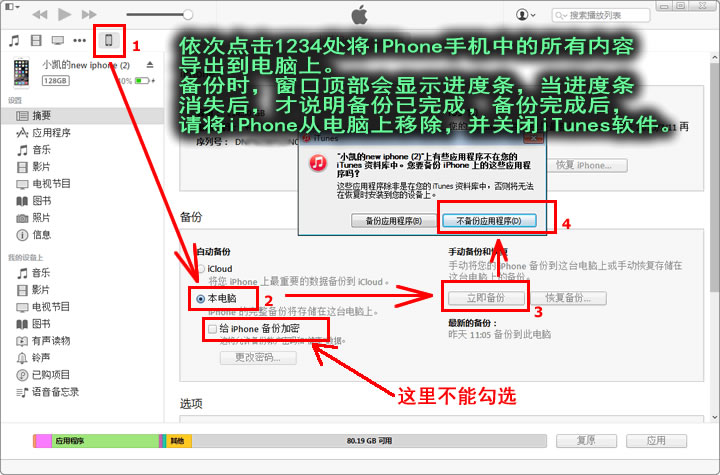
注意第四步的对话框如果显示的为“是否对备份内容进行加密?”,选择“不加密”即可。
备注
-
(针对windows系统)备份的内存问题:
手机备份通常需要很大的空间,而iTunes是默认将备份文件放在C盘的,如果C盘空间不足可能会提示备份失败,此时,可以事先将备份文件夹转成外部超链接,具体操作为:以管理员身份启动cmd命令行,输入mklink /j "C:\Users\你的用户名\AppData\Roaming\Apple Computer\MobileSync" "要更改到的文件地址"比如我的电脑

如果显示“当文件已存在时,无法创建该文件”,则进入上面提到的”C:\Users\你的用户名\AppData\Roaming\Apple Computer”这个目录,把MobileSync文件夹删掉,再执行上述命令即可(AppData是隐藏文件夹,需要先开启“查看隐藏项目”选项才能找到)。这时可以看到上述命令创建了一个文件夹的快捷方式,也就相当于把文件夹的实际存储地址外链到了其它地方,如下: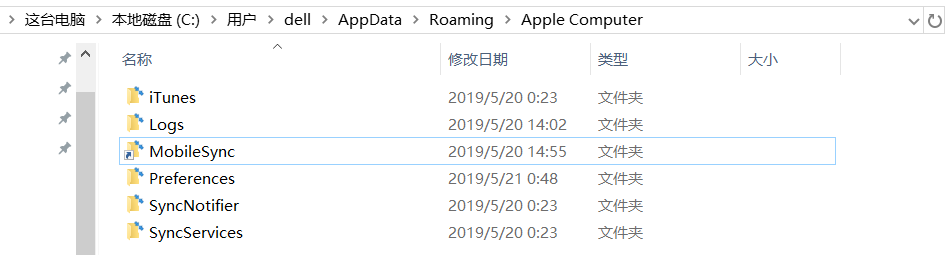 以上移动备份位置,更详细的教程可以参阅
以上移动备份位置,更详细的教程可以参阅
百度经验:ITUNES更改备份保存路径(不放C盘,不占C盘)。 -
针对安卓系统:
备份手机文件的教程链接如下,可以参阅其中的1~6步进行:
如何导出安卓手机微信聊天记录到电脑查看
第二步: 导出聊天记录
(从这里往下就全是针对ios系统了……)
下载iPhone Backup Viewer,以下是网址:
Extract Data from iPhone Backups
下载好后打开软件,软件会自动找到备份文件的位置,并显示出来,如下(大幂幂太美了): 点击中间的屏幕进入备份文件–>点击最后一个图标:然后点击右上方的“树形结构”图标:
点击中间的屏幕进入备份文件–>点击最后一个图标:然后点击右上方的“树形结构”图标:
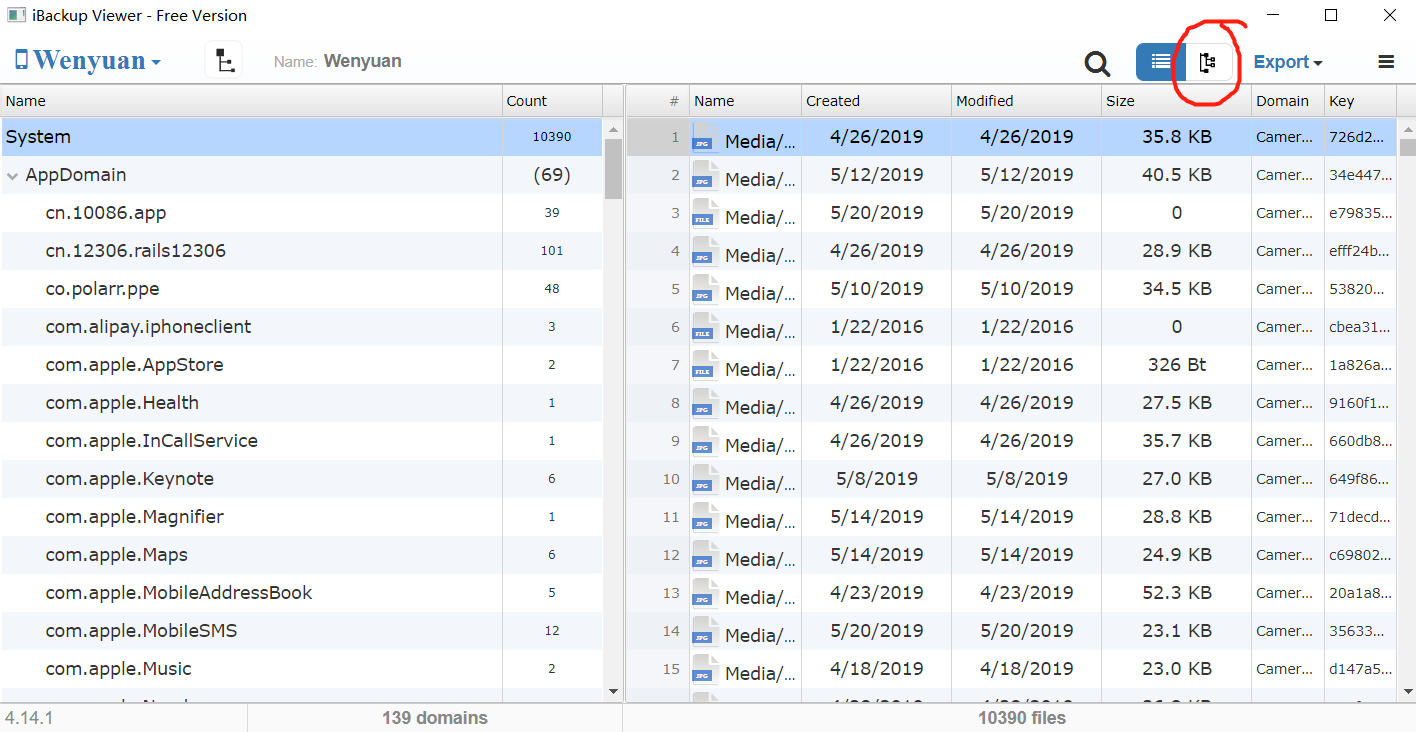 在左侧文件栏找到名为”AppDomain-com.tencent.xin“的文件夹并展开–>展开”Document“子文件夹,可以看到子文件夹里有若干个由32位数字+字母(经过MD5加密过的32位字符串)命名的文件夹,这些文件夹就是在我们的手机微信上存储的不同用户的数据文件,每个文件夹代表一个用户,比如我的手机上登录过两个用户的微信:
在左侧文件栏找到名为”AppDomain-com.tencent.xin“的文件夹并展开–>展开”Document“子文件夹,可以看到子文件夹里有若干个由32位数字+字母(经过MD5加密过的32位字符串)命名的文件夹,这些文件夹就是在我们的手机微信上存储的不同用户的数据文件,每个文件夹代表一个用户,比如我的手机上登录过两个用户的微信: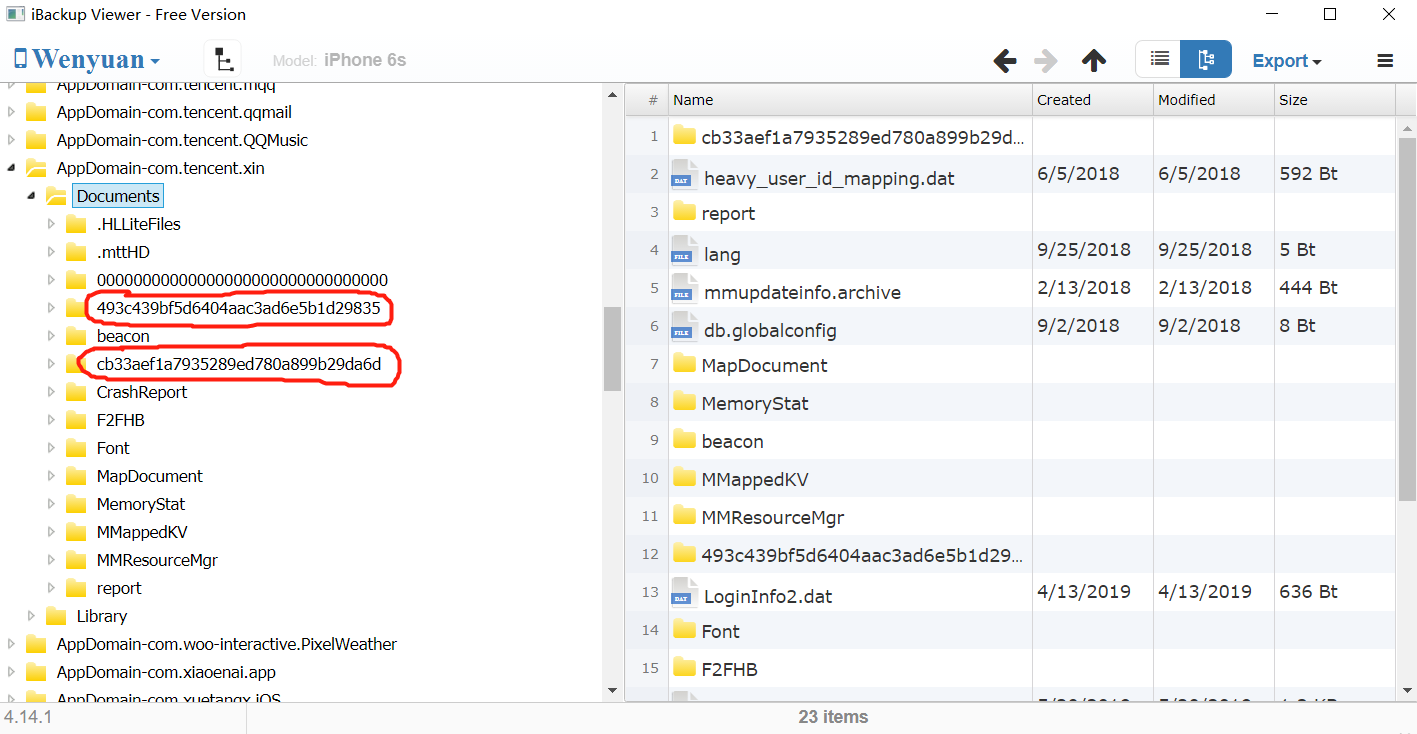 之所以可能有不止一个文件夹,是因为手机上可能短时间登陆过其他用户。如何判断哪个是我经常使用的那个账户?在第二步骤的备注部分将作出解答。
之所以可能有不止一个文件夹,是因为手机上可能短时间登陆过其他用户。如何判断哪个是我经常使用的那个账户?在第二步骤的备注部分将作出解答。
展开上述子文件夹–>找到DB子文件夹打开,可以看到右侧有一个”MM.sqlite“文件,这个就是全部的聊天记录文件。选择右上角的”Export“–>”Selected“即可导出到自己想要的位置。如下: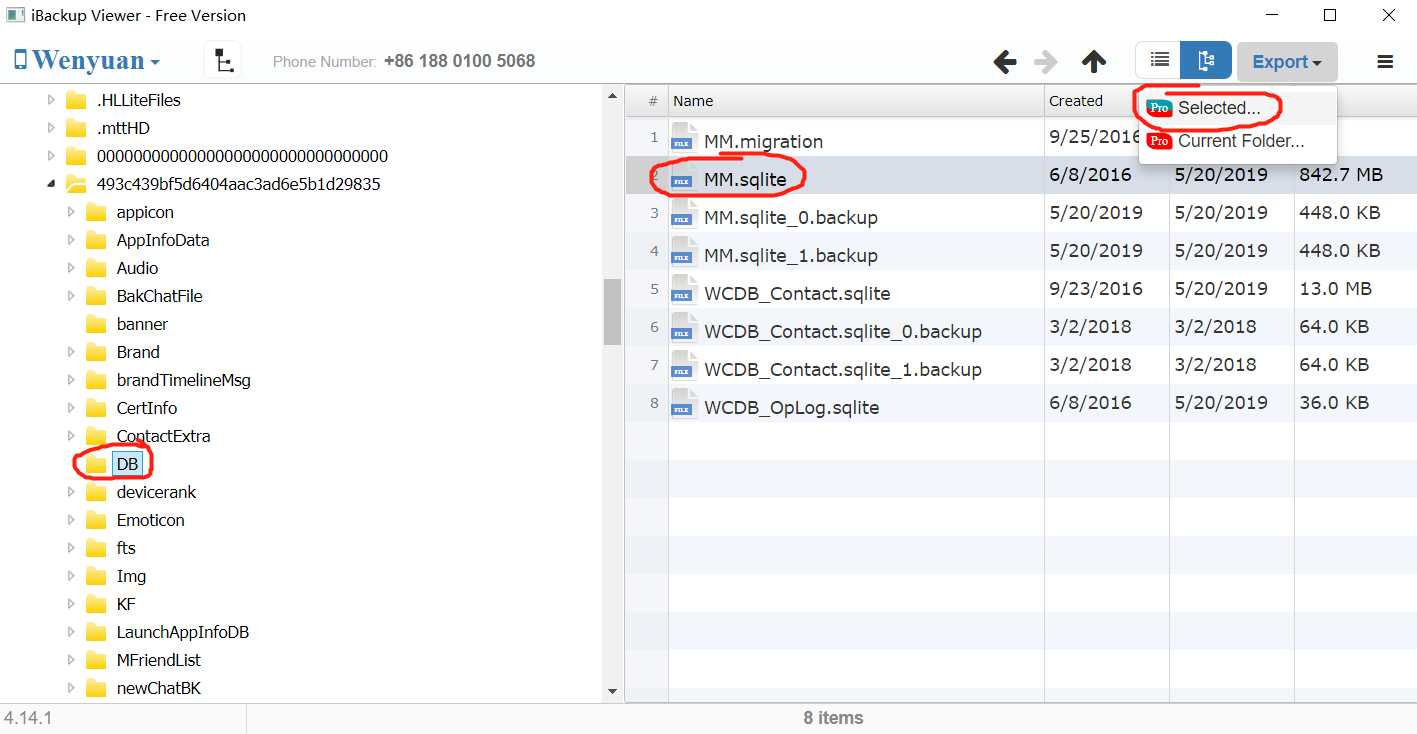
备注
我们可以根据”MM.sqlilte”文件的大小区分我们需要导出哪个用户的聊天记录。通常来说,我们使用最多的那个微信账号,由于聊天记录很多,这个文件会很大。以我的手机为例,在命名为”493c439bf…”的那个文件夹里,我的”MM.sqlite”文件有800M,而在”cb33ae…”那个文件夹中,”MM.sqlite”文件只有600K: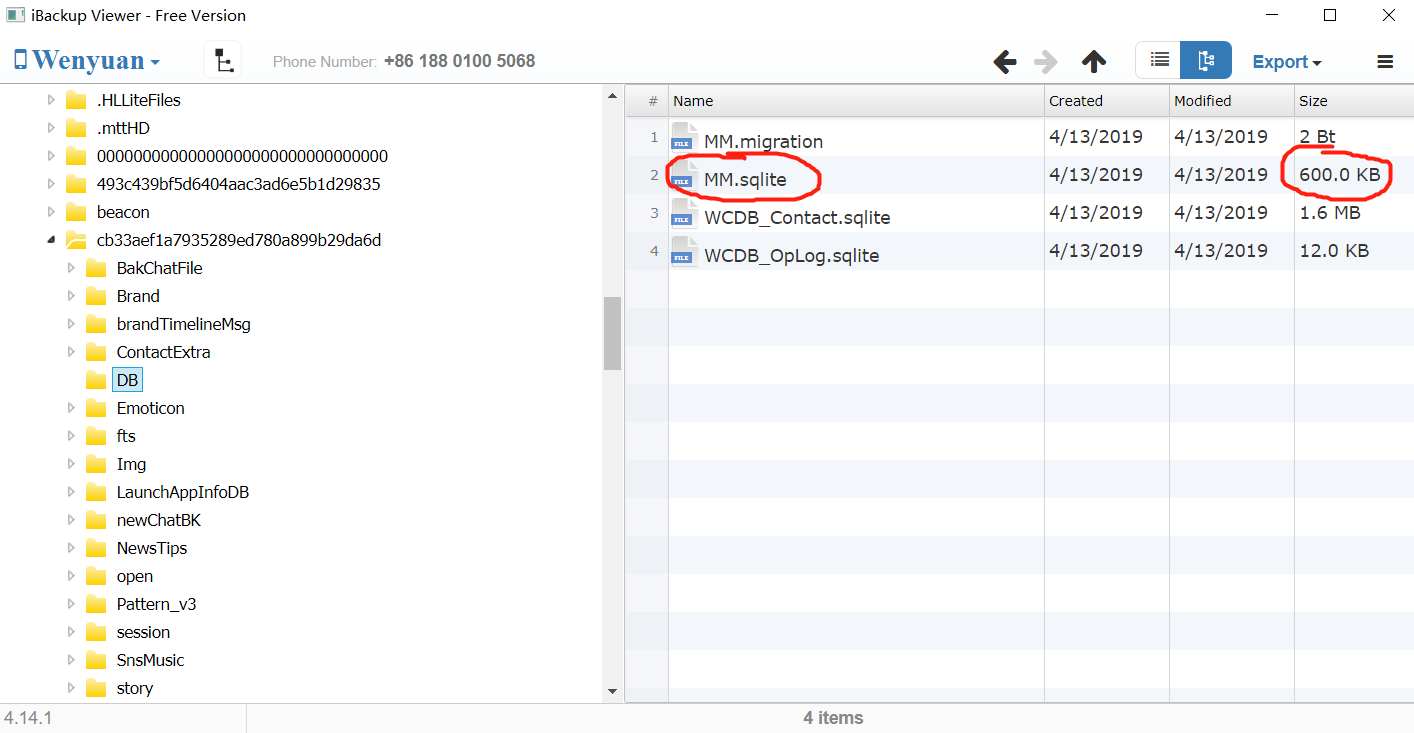 因此我可以确定”493c439bf…”对应的那个数据库是我的主账号的聊天记录。
因此我可以确定”493c439bf…”对应的那个数据库是我的主账号的聊天记录。
第三步: 分析聊天记录
下载数据库查看软件,推荐轻量型的软件SQLiteSpy,下载地址为:
Download SQLiteSpy1.9.13
下载好后,用该软件打开刚才保存下来的”MM.sqlite”文件。在左侧的表中,所有以”Chat_”开头的表就是单人聊天记录或群聊或公众号的聊天记录。以”ChatExt2_”开头的表是没有用的。随便点开一个,在右侧的Message列下面就是所有的聊天记录,如图是我点开的一个群聊: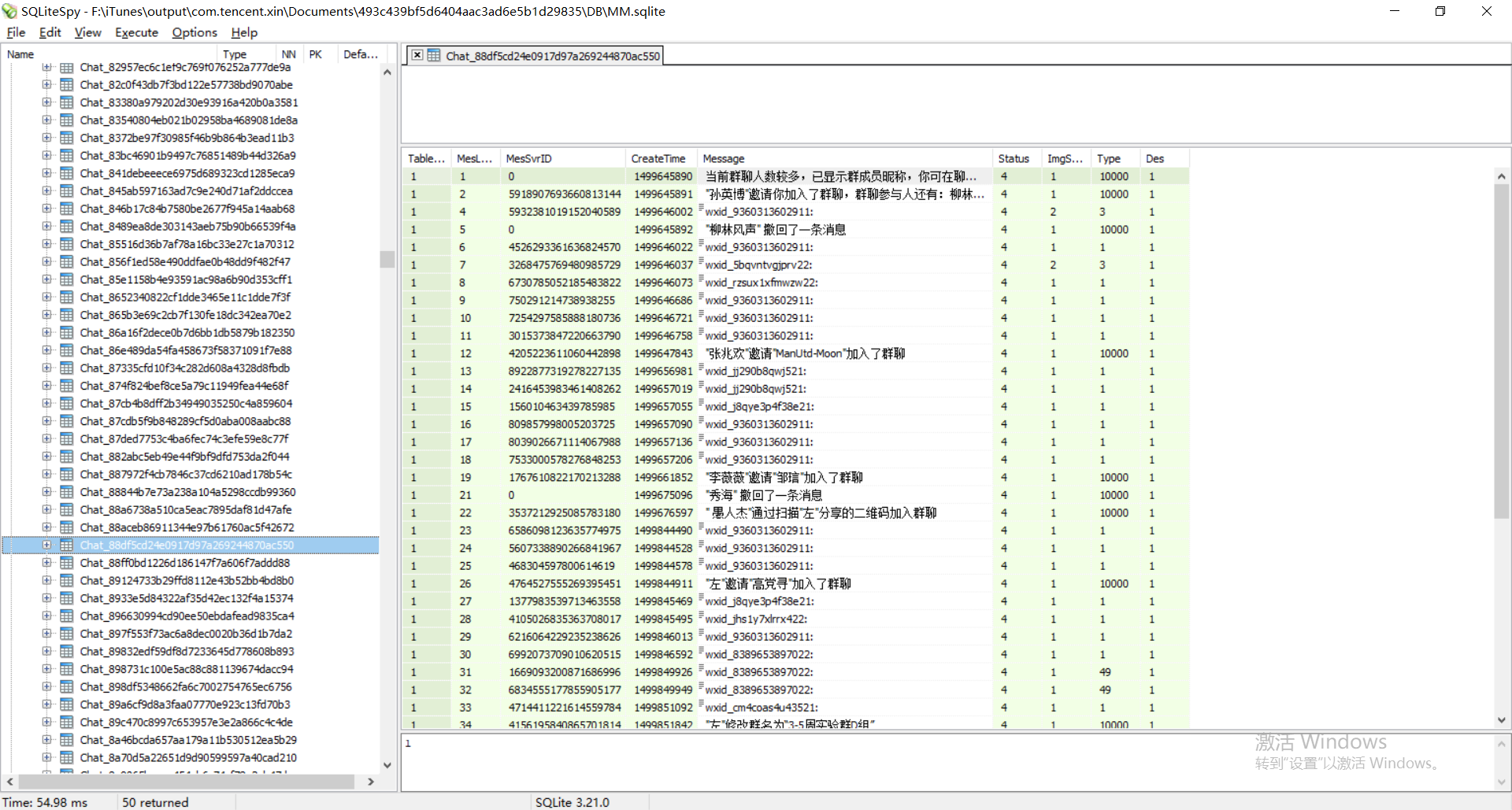 左侧的表名都是乱码,怎么找到与某个特定人的聊天记录?
左侧的表名都是乱码,怎么找到与某个特定人的聊天记录?
在左侧最下面找到一个名为”sqlite_sequence”的表,点开看到该表的内容是name-seq的关系表,其中name就是左侧全部的表名,seq是与这个人互发消息的总条数,点击”seq”列名的地方可以对seq从小到大或从大到小排序。我们可以估计一下我们跟我们要找的人大概发过多少消息,排序后找到对应的表名去打开那个表。
比如在这里,我希望找到的那个人,我确信和他的聊天记录是最多的,因此我可以确信第一行的name就是他的那张表: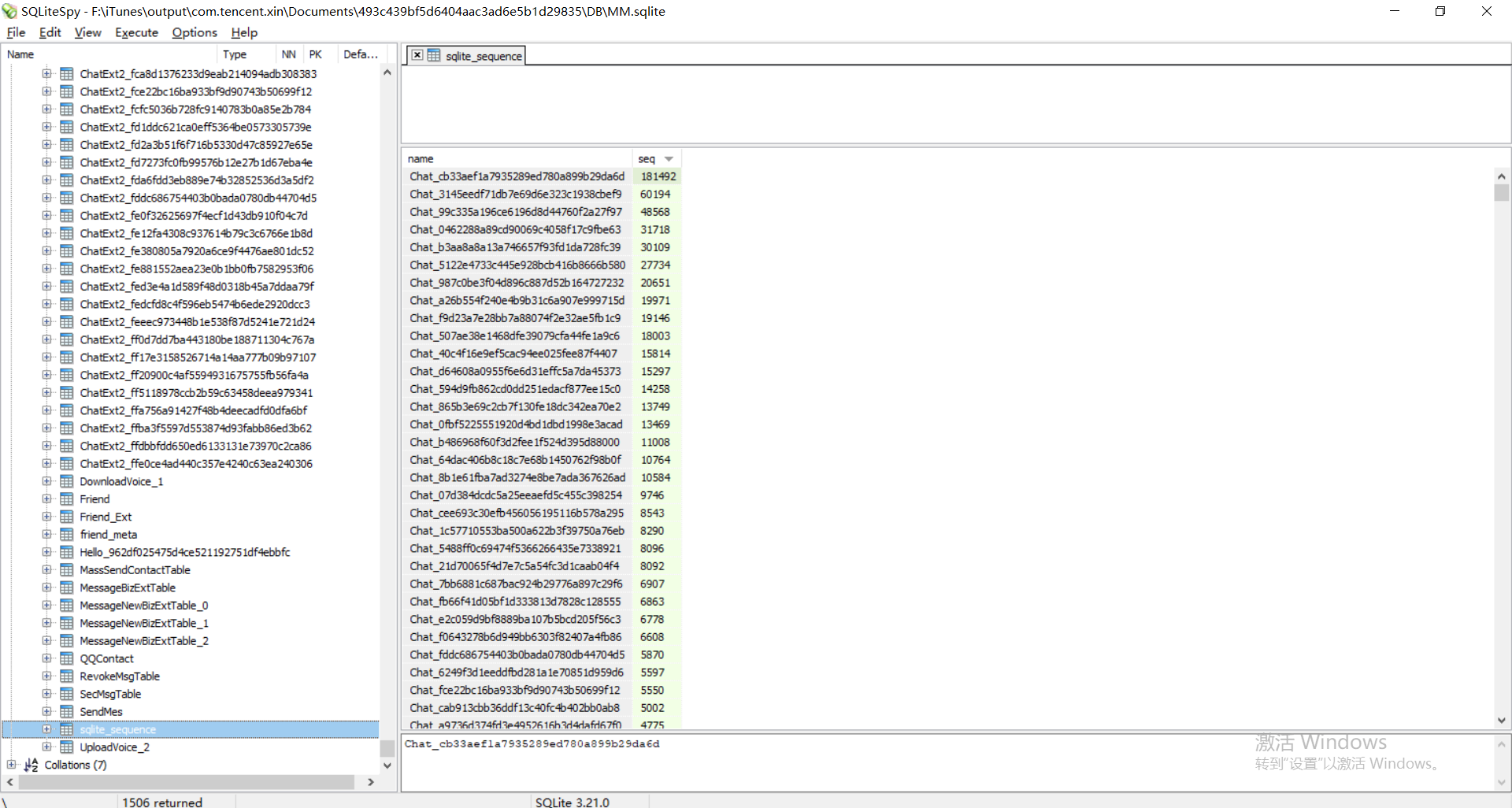 因此在左侧找到名为”Chat_cb33aef1a7935289ed780a899b29da6d”的表,果不其然:
因此在左侧找到名为”Chat_cb33aef1a7935289ed780a899b29da6d”的表,果不其然:
备注
更详细的关于表名与好友的对应关系储存在”WCDB_Contace.sqlite”数据库中,更详细的分析可以参考下面的链接中从第3条往后的内容:
iOS 微信数据库分析
第四步:导出聊天记录生成词云
接下来使用python对”MM.sqlite”数据库进行操作,可以执行导出、显示等。这里以生成词云为例:
先引入必需的包,这些包都需要预先安装(pip的使用可以自行百度~):
import re
import jieba
import wordcloud
import sqlite3
import cv2
首先连接数据库:
# connect database
conn = sqlite3.connect("F:/iTunes/output/com.tencent.xin/Documents/493c439bf5d6404aac3ad6e5b1d29835/DB/MM.sqlite")
c = conn.cursor()
# data = c.execute("select name from sqlite_master where type='table' order by name")
tabelname = "Chat_cb33aef1a7935289ed780a899b29da6d"
search = c.execute("select Message from " + tabelname).fetchall()
第2行的参数是刚才保存的”MM.sqlite”文件的地址,可以用相对路径,不必须用绝对路径。
第4行是执行获取所有表名的SQL语句,如果需要遍历全部聊天记录可以使用该语句。
第5行是第二步中找到的表名。
第6行是从该表中查询所有的消息记录。
之后使用jieba对逐条消息进行分词:
# for each message: cut into words
wordList = []
for each in search:
find = re.findall(r'[\u4e00-\u9fa5]+', each[0])
for sentence in find:
cutResult = jieba.cut(sentence, cut_all=False, HMM=True)
for word in cutResult:
wordList.append(word)
第4行是从查询结果中逐条消息地找到所有的中文字符。
第6~8行是对每句话进行分词,并把分出来的单词加入到wordList中。
之后设置停用词表,并更新分词列表:
# set Stopword list
excludes = ['这个', '不是', '觉得', '什么', '没有', '可以', '一个', '知道', '那个', '现在', '今天', '怎么', '时候', '所以'
'一下', '有点', '可能', '然后', '感觉', '就是', '还是', '这么', '明天', '刚才', '你们', '的话', '要是', '一条',
'那种', '这种', '以后', '而且', '两个', '我要', '反正', '不用', '一会', '直接', '肯定', '特别', '比较', '一次',
'皱眉', '捂脸', '发抖', '愉快', '呲牙', '嘿哈']
# get list of needed words
result = []
for word in wordList:
if len(word) == 1:
continue
elif word in excludes:
continue
else:
result.append(word)
result = ' '.join(result)
第2行设置停用词表是为了不让这些词在词云中出现(因为这些词的出现频率都很高),也可以自己选择性地修改。记得要把各种emoji表情的名字也加进去,因为在聊天记录中emoji的名字会算作文字~
第9行排除单个字形成的词;第11行排除停用词表中的词。
第15行得到要输入给词云的字符串,字符串是以空格分隔的单词。
最后生成词云:
# generate wordcloud
mask_jpg = cv2.imread("F:/Documents/Python/myProject/input/love_mask.jpg")
w = wordcloud.WordCloud(mask=mask_jpg, font_path='C:/Windows/Fonts/小清新中文.TTF',
width=600, height=525, max_words=400, collocations=False,
max_font_size=110, background_color='black')
w.generate(result)
# set color2.jpg's colormap as the cloud's colormap
color_jpg = cv2.imread("F:\Documents\Python\myProject\input\color2.jpg")
img_color = wordcloud.ImageColorGenerator(color_jpg)
w.recolor(color_func=img_color)
# write to file
w.to_file('output/output9.png')
第2行是读入mask(遮罩)图片,目的是让词云匹配该图片的形状,这张图片中所有白色的区域都不会有词云出现。同样,参数的路径可以使用相对路径。在该示例中,我使用的是如下的图片:
第3行建立词云对象,mask参数指定mask图片,font_path指定字体的位置,width和height是生成图像的宽和高,max_words指定词云中最大包含词语的数量,collocations设为False防止词云中出现重复的词,max_font_size指定词云中词语最大的字号background_color指定生成图片的背景色。以上参数均允许为空。
第6行把文本内容加载进词云。
第8~10行读入一张颜色图片,这张图片的目的是让词云的色彩匹配这张图片里面的颜色,而不是使用默认颜色。如果不指定这张图片,词云就会按照预设的颜色方案给各个单词上色。在本示例中,我使用的是如下的图片:
最后一行把生成的词云写入文件。
程序运行结束后,查看生成的词云,最终效果如下图所示:

最后附上完整的代码:
import re
import jieba
import wordcloud
import sqlite3
import cv2
if __name__ == '__main__':
# connect database
conn = sqlite3.connect("F:/iTunes/output/com.tencent.xin/Documents/493c439bf5d6404aac3ad6e5b1d29835/DB/MM.sqlite")
c = conn.cursor()
# data = c.execute("select name from sqlite_master where type='table' order by name")
tabelname = "Chat_cb33aef1a7935289ed780a899b29da6d"
search = c.execute("select Message from " + tabelname).fetchall()
# for each message: cut into words
wordList = []
for each in search:
find = re.findall(r'[\u4e00-\u9fa5]+', each[0])
for sentence in find:
cutResult = jieba.cut(sentence, cut_all=False, HMM=True)
for word in cutResult:
wordList.append(word)
# set Stopword list
excludes = ['这个', '不是', '觉得', '什么', '没有', '可以', '一个', '知道', '那个', '现在', '今天', '怎么', '时候', '所以'
'一下', '有点', '可能', '然后', '感觉', '就是', '还是', '这么', '明天', '刚才', '你们', '的话', '要是', '一条',
'那种', '这种', '以后', '而且', '两个', '我要', '反正', '不用', '一会', '直接', '肯定', '特别', '比较', '一次',
'皱眉', '捂脸', '发抖', '愉快', '呲牙', '嘿哈']
# get list of needed words
result = []
for word in wordList:
if len(word) == 1:
continue
elif word in excludes:
continue
else:
result.append(word)
result = ' '.join(result)
# generate wordcloud
mask_jpg = cv2.imread("F:/Documents/Python/myProject/input/love_mask.jpg")
w = wordcloud.WordCloud(mask=mask_jpg, font_path='C:/Windows/Fonts/小清新中文.TTF',
width=600, height=525, max_words=400, collocations=False,
max_font_size=110, background_color='black')
w.generate(result)
# set color2.jpg's colormap as the cloud's colormap
color_jpg = cv2.imread("F:\Documents\Python\myProject\input\color2.jpg")
img_color = wordcloud.ImageColorGenerator(color_jpg)
w.recolor(color_func=img_color)
# write to file
w.to_file('output/output9.png')
感谢阅读~
有任何问题欢迎在评论区交流~
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/126610.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
