大家好,又见面了,我是你们的朋友全栈君。
最近在学习数据挖掘,其实决策树分类看过去好久了,但是最近慢慢的想都实现一下,加深一下理解。
知道决策树有很多现成的算法(ID3,C4.5、CART),但是毕竟核心思想就是那几点,所以本篇博客就是我随便实现的,没有参考现有的决策树算法。考虑到实现分类起码需要一个数据集,所以我选择了经典的鸢尾花数据集,下载地址:Iris
选择iris.data点击右键连接另存为,即可下载,我是下载到桌面,文档为iris.data.txt
5.1,3.5,1.4,0.2,Iris-setosa
4.9,3.0,1.4,0.2,Iris-setosa
4.7,3.2,1.3,0.2,Iris-setosa
4.6,3.1,1.5,0.2,Iris-setosa
5.0,3.6,1.4,0.2,Iris-setosa
5.4,3.9,1.7,0.4,Iris-setosa
4.6,3.4,1.4,0.3,Iris-setosa
5.0,3.4,1.5,0.2,Iris-setosa
4.4,2.9,1.4,0.2,Iris-setosa
4.9,3.1,1.5,0.1,Iris-setosa
5.4,3.7,1.5,0.2,Iris-setosa
4.8,3.4,1.6,0.2,Iris-setosa
4.8,3.0,1.4,0.1,Iris-setosa
4.3,3.0,1.1,0.1,Iris-setosa
5.8,4.0,1.2,0.2,Iris-setosa
5.7,4.4,1.5,0.4,Iris-setosa
5.4,3.9,1.3,0.4,Iris-setosa
5.1,3.5,1.4,0.3,Iris-setosa
5.7,3.8,1.7,0.3,Iris-setosa
5.1,3.8,1.5,0.3,Iris-setosa
5.4,3.4,1.7,0.2,Iris-setosa
5.1,3.7,1.5,0.4,Iris-setosa
4.6,3.6,1.0,0.2,Iris-setosa
5.1,3.3,1.7,0.5,Iris-setosa
4.8,3.4,1.9,0.2,Iris-setosa
5.0,3.0,1.6,0.2,Iris-setosa
5.0,3.4,1.6,0.4,Iris-setosa
5.2,3.5,1.5,0.2,Iris-setosa
5.2,3.4,1.4,0.2,Iris-setosa
4.7,3.2,1.6,0.2,Iris-setosa
4.8,3.1,1.6,0.2,Iris-setosa
5.4,3.4,1.5,0.4,Iris-setosa
5.2,4.1,1.5,0.1,Iris-setosa
5.5,4.2,1.4,0.2,Iris-setosa
4.9,3.1,1.5,0.1,Iris-setosa
5.0,3.2,1.2,0.2,Iris-setosa
5.5,3.5,1.3,0.2,Iris-setosa
4.9,3.1,1.5,0.1,Iris-setosa
4.4,3.0,1.3,0.2,Iris-setosa
5.1,3.4,1.5,0.2,Iris-setosa
5.0,3.5,1.3,0.3,Iris-setosa
4.5,2.3,1.3,0.3,Iris-setosa
4.4,3.2,1.3,0.2,Iris-setosa
5.0,3.5,1.6,0.6,Iris-setosa
5.1,3.8,1.9,0.4,Iris-setosa
4.8,3.0,1.4,0.3,Iris-setosa
5.1,3.8,1.6,0.2,Iris-setosa
4.6,3.2,1.4,0.2,Iris-setosa
5.3,3.7,1.5,0.2,Iris-setosa
5.0,3.3,1.4,0.2,Iris-setosa
7.0,3.2,4.7,1.4,Iris-versicolor
6.4,3.2,4.5,1.5,Iris-versicolor
6.9,3.1,4.9,1.5,Iris-versicolor
5.5,2.3,4.0,1.3,Iris-versicolor
6.5,2.8,4.6,1.5,Iris-versicolor
5.7,2.8,4.5,1.3,Iris-versicolor
6.3,3.3,4.7,1.6,Iris-versicolor
4.9,2.4,3.3,1.0,Iris-versicolor
6.6,2.9,4.6,1.3,Iris-versicolor
5.2,2.7,3.9,1.4,Iris-versicolor
5.0,2.0,3.5,1.0,Iris-versicolor
5.9,3.0,4.2,1.5,Iris-versicolor
6.0,2.2,4.0,1.0,Iris-versicolor
6.1,2.9,4.7,1.4,Iris-versicolor
5.6,2.9,3.6,1.3,Iris-versicolor
6.7,3.1,4.4,1.4,Iris-versicolor
5.6,3.0,4.5,1.5,Iris-versicolor
5.8,2.7,4.1,1.0,Iris-versicolor
6.2,2.2,4.5,1.5,Iris-versicolor
5.6,2.5,3.9,1.1,Iris-versicolor
5.9,3.2,4.8,1.8,Iris-versicolor
6.1,2.8,4.0,1.3,Iris-versicolor
6.3,2.5,4.9,1.5,Iris-versicolor
6.1,2.8,4.7,1.2,Iris-versicolor
6.4,2.9,4.3,1.3,Iris-versicolor
6.6,3.0,4.4,1.4,Iris-versicolor
6.8,2.8,4.8,1.4,Iris-versicolor
6.7,3.0,5.0,1.7,Iris-versicolor
6.0,2.9,4.5,1.5,Iris-versicolor
5.7,2.6,3.5,1.0,Iris-versicolor
5.5,2.4,3.8,1.1,Iris-versicolor
5.5,2.4,3.7,1.0,Iris-versicolor
5.8,2.7,3.9,1.2,Iris-versicolor
6.0,2.7,5.1,1.6,Iris-versicolor
5.4,3.0,4.5,1.5,Iris-versicolor
6.0,3.4,4.5,1.6,Iris-versicolor
6.7,3.1,4.7,1.5,Iris-versicolor
6.3,2.3,4.4,1.3,Iris-versicolor
5.6,3.0,4.1,1.3,Iris-versicolor
5.5,2.5,4.0,1.3,Iris-versicolor
5.5,2.6,4.4,1.2,Iris-versicolor
6.1,3.0,4.6,1.4,Iris-versicolor
5.8,2.6,4.0,1.2,Iris-versicolor
5.0,2.3,3.3,1.0,Iris-versicolor
5.6,2.7,4.2,1.3,Iris-versicolor
5.7,3.0,4.2,1.2,Iris-versicolor
5.7,2.9,4.2,1.3,Iris-versicolor
6.2,2.9,4.3,1.3,Iris-versicolor
5.1,2.5,3.0,1.1,Iris-versicolor
5.7,2.8,4.1,1.3,Iris-versicolor
6.3,3.3,6.0,2.5,Iris-virginica
5.8,2.7,5.1,1.9,Iris-virginica
7.1,3.0,5.9,2.1,Iris-virginica
6.3,2.9,5.6,1.8,Iris-virginica
6.5,3.0,5.8,2.2,Iris-virginica
7.6,3.0,6.6,2.1,Iris-virginica
4.9,2.5,4.5,1.7,Iris-virginica
7.3,2.9,6.3,1.8,Iris-virginica
6.7,2.5,5.8,1.8,Iris-virginica
7.2,3.6,6.1,2.5,Iris-virginica
6.5,3.2,5.1,2.0,Iris-virginica
6.4,2.7,5.3,1.9,Iris-virginica
6.8,3.0,5.5,2.1,Iris-virginica
5.7,2.5,5.0,2.0,Iris-virginica
5.8,2.8,5.1,2.4,Iris-virginica
6.4,3.2,5.3,2.3,Iris-virginica
6.5,3.0,5.5,1.8,Iris-virginica
7.7,3.8,6.7,2.2,Iris-virginica
7.7,2.6,6.9,2.3,Iris-virginica
6.0,2.2,5.0,1.5,Iris-virginica
6.9,3.2,5.7,2.3,Iris-virginica
5.6,2.8,4.9,2.0,Iris-virginica
7.7,2.8,6.7,2.0,Iris-virginica
6.3,2.7,4.9,1.8,Iris-virginica
6.7,3.3,5.7,2.1,Iris-virginica
7.2,3.2,6.0,1.8,Iris-virginica
6.2,2.8,4.8,1.8,Iris-virginica
6.1,3.0,4.9,1.8,Iris-virginica
6.4,2.8,5.6,2.1,Iris-virginica
7.2,3.0,5.8,1.6,Iris-virginica
7.4,2.8,6.1,1.9,Iris-virginica
7.9,3.8,6.4,2.0,Iris-virginica
6.4,2.8,5.6,2.2,Iris-virginica
6.3,2.8,5.1,1.5,Iris-virginica
6.1,2.6,5.6,1.4,Iris-virginica
7.7,3.0,6.1,2.3,Iris-virginica
6.3,3.4,5.6,2.4,Iris-virginica
6.4,3.1,5.5,1.8,Iris-virginica
6.0,3.0,4.8,1.8,Iris-virginica
6.9,3.1,5.4,2.1,Iris-virginica
6.7,3.1,5.6,2.4,Iris-virginica
6.9,3.1,5.1,2.3,Iris-virginica
5.8,2.7,5.1,1.9,Iris-virginica
6.8,3.2,5.9,2.3,Iris-virginica
6.7,3.3,5.7,2.5,Iris-virginica
6.7,3.0,5.2,2.3,Iris-virginica
6.3,2.5,5.0,1.9,Iris-virginica
6.5,3.0,5.2,2.0,Iris-virginica
6.2,3.4,5.4,2.3,Iris-virginica
5.9,3.0,5.1,1.8,Iris-virginica
- 将数据集载入matlab
参考 UCI数据集使用
function [attrib]=Iris_tree_preprocess( )
%数据预处理
[attrib1, attrib2, attrib3, attrib4, class] = textread('C:\Users\Administrator\Desktop\iris.data', '%f%f%f%f%s', 'delimiter', ',');
% delimiter , 是跳过符号“,”
a = zeros(150, 1);
a(strcmp(class, 'Iris-setosa')) = 1;
a(strcmp(class, 'Iris-versicolor')) = 2;
a(strcmp(class, 'Iris-virginica')) = 3;
%% 导入鸢yuan尾花数据
for i=1:150
attrib(i,1)=attrib1(i);
attrib(i,2)=attrib2(i);
attrib(i,3)=attrib3(i);
attrib(i,4)=attrib4(i);
attrib(i,5)=a(i);
end
end完成这一步后,我们会得到四个属性集的矩阵和进行了类别转化的a矩阵。
- 熵的计算 属性的选择
决策树算法最关键的问题无非就是选择哪个属性哪个值进行分类才能达到最好的效果,这是我们要考虑的问题。
如果你已经了解过决策树算法,那你一定知道有三种熵度量

在这里不做过多介绍,我选择了第一种熵度量,但是在matlab里面有个问题就是,我们在matlab中会有 ,但是在第一种熵的定义中有,表示纯度最好的情况,所以我们要重新定义下算法啦。
function y = sjlog(x)
%% 重新定义,使0*log0=0
if x==0
y = 0;
else
y = log(x);
end
end
熵值越小表示在所测子集中,属性越纯,极端情况下,某一子集全部为一种属性,则熵为0.这种类似穷举的方法有个弊端就是要比较的划分数值太多啦,而且大家应该发现鸢尾花的四类属性都是连续值,也就意味着有不可数的比较次数等着我们。。但是前人们已经指引了我们方向。我们将按每一类属性进行从小到大的排序,然后储存在元胞数组attri中。所有可能的最优划分数值一定是这样的,它的左右相邻的样例类别不同。如果这里理解上有困难,那么我推荐大家去读一下《数据挖掘导论》Pang-Ning Tan等著的page99-100页。
function [point,class,num_diff,gain]=Gain(attrib)
%求熵,并根据最小熵进行划分子集
% point 划分的数值
% class 划分类别
% num_diff 划分的小子集基数
numberExamples = length(attrib(:,1));
attri{1,1}=sortrows(attrib,1);
attri{1,2}=sortrows(attrib,2);
attri{1,3}=sortrows(attrib,3);
attri{1,4}=sortrows(attrib,4);
% 按照某行排序
class=1;
point=0;
gain=20;
for s=1:4
j=1;
clear different
for i=1:numberExamples-1
if attri{1,s}(i,5)~=attri{1,s}(i+1,5)
different(j)=i;
j=j+1;
end
end
for i=1:length(different)
classs=s;
pointt=attri{1,s}(different(i),s);
num_class_1=sum(attri{1,s}((1:different(i)),5)==1);
num_class_2=sum(attri{1,s}((1:different(i)),5)==2);
num_class_3=sum(attri{1,s}((1:different(i)),5)==3);
num0_class_1=sum(attri{1,s}(:,5)==1)- num_class_1;
num0_class_2=sum(attri{1,s}(:,5)==2)- num_class_2;
num0_class_3=sum(attri{1,s}(:,5)==3)- num_class_3;
gainn=-(different(i)/numberExamples)*((num_class_1/different(i))*sjlog(num_class_1/different(i))+(num_class_2/different(i))*sjlog(num_class_2/different(i))+(num_class_3/different(i))*sjlog(num_class_3/different(i)))-(1-different(i)/numberExamples)*((num0_class_1/(numberExamples-different(i)))*sjlog(num0_class_1/(numberExamples-different(i)))+(num0_class_2/(numberExamples-different(i)))*sjlog(num0_class_2/(numberExamples-different(i)))+(num0_class_3/(numberExamples-different(i)))*sjlog(num0_class_3/(numberExamples-different(i))));
%计算熵
if gainn<gain
point=pointt;
class=classs;
gain=gainn;
num_diff=different(i);
end
end
end
end因为我本科数学,现在在计算机专业读研一,相信大家的代码水平一定高我不少,代码我就不解释啦,而且也有注释嘛hhh。
- 生成决策树
我们选择产生最小熵的划分子集方式,但是这样会一直划分下去,所以我们还要计算信息增益
,
即是父节点的熵减去划分后各子集熵的加权和,权值就是样例所占的比重啦。增益大于0的情况我们才会进行分枝。
细节方面:
创建结构体tree,包含值 value(如果有子树就记录划分的属性和划分的具体数值,如果没有子树,就记录子集中占比例最大的样例的属性)、左子树left、右子树right,两个子树就是用来递归用的了。。。
通过之前的Gain函数我们得到某结点熵最小的划分属性和划分的具体数值,通过这两个信息,我们可以将该节点的子集划分,但是划分后会有特殊情况,比如左子树(默认为小于等于划分数值的样例子集)全部都是一个属性或者空,那么就没必要再次递归,还有就是如果一直划分下去,会出现过拟合的问题,所有我在这里设定了精确度的概念,也就是结点样例子集三个类别中占比最大的那个所占整体的百分比。如果达到我们的要求,那么也没必要再分枝下去。
function [ tree ] = Iris_tree(attrib,P)
%P为子集最大样例所占比例,取值应在[0,1]内
tree = struct('value', 'null', 'left', 'null', 'right', 'null');
numberExamples = length(attrib(:,1));
num_class_1=sum(attrib(:,5)==1);
num_class_2=sum(attrib(:,5)==2);
num_class_3=sum(attrib(:,5)==3);
I_parent=-((num_class_1/numberExamples)*log(num_class_1/numberExamples)+(num_class_2/numberExamples)*log(num_class_2/numberExamples)+(num_class_3/numberExamples)*log(num_class_3/numberExamples));
% 节点熵
[point,class,num_diff,gain]=Gain(attrib);
if num_class_1>max( num_class_2, num_class_3)
tree.value=1;
else if num_class_2< num_class_3
tree.value=3;
else
tree.value=2;
end
end
if I_parent>gain
tree.value=[class,point];
attrib=sortrows(attrib,class);
% 按照选中的属性排序
attrib_0=attrib(1:num_diff,:);
%左子树样例子集
attrib_1=attrib(num_diff:end,:);
%右子树样例子集
%划分样本子集
if ~isempty(attrib_0)
num_0=length(attrib_0(:,1));
value_class_1=sum(attrib_0(:,5)==1);
value_class_2=sum(attrib_0(:,5)==2);
value_class_3=sum(attrib_0(:,5)==3);
if value_class_1>max( value_class_2, value_class_3)
tree.left=1;
else if value_class_2< value_class_3
tree.left=3;
else
tree.left=2;
end
end
if num_0~=bijiao( value_class_1, value_class_2, value_class_3) && bijiao( value_class_1, value_class_2, value_class_3)/num_0<P
tree.left=Iris_tree(attrib_0,P);
end
end
if ~isempty(attrib_1)
num_1=length(attrib_1(:,1));
value_class_1=sum(attrib_1(:,5)==1);
value_class_2=sum(attrib_1(:,5)==2);
value_class_3=sum(attrib_1(:,5)==3);
if value_class_1>max( value_class_2, value_class_3)
tree.right=1;
else if value_class_2< value_class_3
tree.right=3;
else
tree.right=2;
end
end
if num_1~=bijiao( value_class_1, value_class_2, value_class_3) && bijiao( value_class_1, value_class_2, value_class_3)/num_1<P
tree.right=Iris_tree(attrib_1,P);
end
end
end
end上面的代码里有一个bijiao函数,因为matlab的max函数只能比较两个数的大小,所以我又重新定义了一下。
function max=bijiao(a,b,c)
%三个函数取最大
max=a;
if max<b
max=b;
end
if max<c
max=c;
end
end- 决策树的遍历和treeplot的利用
利用treeplot绘图之前我们先需要遍历决策树,并将结点表示成treeplot函数想要的结点表示模样。我采用先序遍历,但是要注意的是,以上的分枝思想里有两种可能会终止分枝。
- 如果划分后的子集纯度(精确度)达到要求,这时的该节点左右分枝树的值tree.left或tree.right就是此时样例子集中各类别样例在其中达到最大占比的类别标号1或2或3.为数值类型而不是结构体。
- 如果划分后的子集纯度(精确度)未达到要求,这时的该节点左右分枝树的值虽然之前被赋值为样例子集中各类别样例在其中达到最大占比的类别标号,但会被重新赋值,也就是进行迭代。但迭代后不一定满足的条件是最佳划分的熵比父节点的熵要小,也就是信息增益变大,所以在这种情况下左右分枝树的值tree.left或tree.right是结构体哦(因为进行了迭代)!!!但是里面除了tree.left.value或tree.right.value会有值之外,其他值为null。
以上一坨要表达的是,按先序遍历得到的数据矩阵中,会包含null值,如果不做处理会影响到决策树的绘图,毕竟会增加分枝,而且还是null…所以我的遍历算法中会有null值的判断语句。并且不只要遍历和表示出包含结点值的数据矩阵就行,还需要表示各值所代表的结点的父子关系啊。毕竟给你一个一维数组,你能判断出来谁是谁的父节点吗,当然不行啦,缺少条件,缺少的就是treeplot函数所需要的nodes序列。
function [A,i]=prev(T,A,i,j)
%遍历树 并产生可以被treeplot用来画图的结点序列
% 输入i应为1;j应为0;
%% 函数迭代过程中传递不了A值,所以要在输入和输出上将cell设为变量
if isstruct(T)==1 && (strcmp(T.left,'null')==0 || strcmp(T.right,'null')==0)
A{i,1}=T.value;
A{i,2}=j;
i=i+1;j=i-1;
%% i随迭代不断增加,但j是固定在每步迭代当中
[A,i]=prev(T.left,A,i,j);
i=i+1;
[A,i]=prev(T.right,A,i,j);
else if isstruct(T)==1 && strcmp(T.left,'null')==1 && strcmp(T.right,'null')==1
A{i,1}=T.value;
A{i,2}=j;
else
A{i,1}=T;
A{i,2}=j;
end
end
end插曲
我一开始写遍历的算法的时候出现很多问题,比如每次迭代的A值,我心里算盘打的啪啪响,想每次取了值就存在相应的i元胞内,结果每一次迭代A元胞数组都会重新被初始化,之前的值都没了没了了…所以发现要在输入和输出中加上A,以便数据的传递,同理,用来计数第几个 结点的i也需要输入输出都加上它。我最初发现A没办法传递下去的时候还在想matlab函数好不方便啊,结果在我想生成表示各结点关系的数列的过程中,我以为是很大的工作量,没想到….灵光一闪,matlab函数的这种“传递不下去”的属性可以被利用一下,我用j表示了遍历的结点中父节点的结点标号,大家看出来了不?hhh 我用j赋值到了A元胞数组的第二列来表示各结点关系,而A元胞数组的第二列也就是treeplot函数需要的结点序列。
决策树生成之后会存储在名为tree的结构体内。但是对决策树绘图是一个头疼的问题。貌似matlab对树形结构的绘图没有过多的工具,我查了一些资料,发现treeplot函数可以做到,但每个结点的标记又成了新的问题,我参考了如何在treeplot画出的树图上标记结点权值这篇文章。
function print_tree(A,P)
%打印树
for i=1:length(A)
nodes(1,i)=A{i,2};
end
treeplot(nodes)
[x,y]=treelayout(nodes);
x=x';
y=y';
%name1=cellstr(num2str((1:count)'));
for i=1:length(A)
name{i,1}=A{i,1};
end
text(x(:,1),y(:,1),name,'VerticalAlignment','bottom','HorizontalAlignment','right')
d=num2str(100*P);
s=strcat('鸢尾花决策树 精确度为',d,'%');
title({s},'FontSize',12,'FontName','宋体');
end至此,算法基本就实现完全了,加上主函数后的完整代码如下:
function Iris(P)
%主函数
%P为子集最大样例所占比例,取值应在[0,1]内
[attrib]=Iris_tree_preprocess();
tree= Iris_tree(attrib,P);
A=cell(1,1);
[A,]=prev(tree,A,1,0);
print_tree(A,P)
end
function print_tree(A,P)
%打印树
for i=1:length(A)
nodes(1,i)=A{i,2};
end
treeplot(nodes)
[x,y]=treelayout(nodes);
x=x';
y=y';
%name1=cellstr(num2str((1:count)'));
for i=1:length(A)
name{i,1}=A{i,1};
end
text(x(:,1),y(:,1),name,'VerticalAlignment','bottom','HorizontalAlignment','right')
d=num2str(100*P);
s=strcat('鸢尾花决策树 精确度为',d,'%');
title({s},'FontSize',12,'FontName','宋体');
end
function [A,i]=prev(T,A,i,j)
%遍历树 并产生可以被treeplot用来画图的结点序列
% 输入i应为1;j应为0;
%% 函数迭代过程中传递不了A值,所以要在输入和输出上将cell设为变量
if isstruct(T)==1 && (strcmp(T.left,'null')==0 || strcmp(T.right,'null')==0)
A{i,1}=T.value;
A{i,2}=j;
i=i+1;j=i-1;
%% i随迭代不断增加,但j是固定在每步迭代当中
[A,i]=prev(T.left,A,i,j);
i=i+1;
[A,i]=prev(T.right,A,i,j);
else if isstruct(T)==1 && strcmp(T.left,'null')==1 && strcmp(T.right,'null')==1
A{i,1}=T.value;
A{i,2}=j;
else
A{i,1}=T;
A{i,2}=j;
end
end
end
function [ tree ] = Iris_tree(attrib,P)
%P为子集最大样例所占比例,取值应在[0,1]内
tree = struct('value', 'null', 'left', 'null', 'right', 'null');
numberExamples = length(attrib(:,1));
num_class_1=sum(attrib(:,5)==1);
num_class_2=sum(attrib(:,5)==2);
num_class_3=sum(attrib(:,5)==3);
I_parent=-((num_class_1/numberExamples)*log(num_class_1/numberExamples)+(num_class_2/numberExamples)*log(num_class_2/numberExamples)+(num_class_3/numberExamples)*log(num_class_3/numberExamples));
% 节点熵
[point,class,num_diff,gain]=Gain(attrib);
if num_class_1>max( num_class_2, num_class_3)
tree.value=1;
else if num_class_2< num_class_3
tree.value=3;
else
tree.value=2;
end
end
if I_parent>gain
tree.value=[class,point];
attrib=sortrows(attrib,class);
% 按照选中的属性排序
attrib_0=attrib(1:num_diff,:);
attrib_1=attrib(num_diff:end,:);
%划分样本子集
if ~isempty(attrib_0)
num_0=length(attrib_0(:,1));
value_class_1=sum(attrib_0(:,5)==1);
value_class_2=sum(attrib_0(:,5)==2);
value_class_3=sum(attrib_0(:,5)==3);
if value_class_1>max( value_class_2, value_class_3)
tree.left=1;
else if value_class_2< value_class_3
tree.left=3;
else
tree.left=2;
end
end
if num_0~=bijiao( value_class_1, value_class_2, value_class_3) && bijiao( value_class_1, value_class_2, value_class_3)/num_0<P
tree.left=Iris_tree(attrib_0,P);
end
end
if ~isempty(attrib_1)
num_1=length(attrib_1(:,1));
value_class_1=sum(attrib_1(:,5)==1);
value_class_2=sum(attrib_1(:,5)==2);
value_class_3=sum(attrib_1(:,5)==3);
if value_class_1>max( value_class_2, value_class_3)
tree.right=1;
else if value_class_2< value_class_3
tree.right=3;
else
tree.right=2;
end
end
if num_1~=bijiao( value_class_1, value_class_2, value_class_3) && bijiao( value_class_1, value_class_2, value_class_3)/num_1<P
tree.right=Iris_tree(attrib_1,P);
end
end
end
end
function max=bijiao(a,b,c)
%三个函数取最大
max=a;
if max<b
max=b;
end
if max<c
max=c;
end
end
function [point,class,num_diff,gain]=Gain(attrib)
%求熵,并根据最小熵进行划分子集
% point 划分的数值
% class 划分类别
% num_diff 划分的小子集基数
numberExamples = length(attrib(:,1));
attri{1,1}=sortrows(attrib,1);
attri{1,2}=sortrows(attrib,2);
attri{1,3}=sortrows(attrib,3);
attri{1,4}=sortrows(attrib,4);
% 按照某行排序
class=1;
point=0;
gain=20;
for s=1:4
j=1;
clear different
for i=1:numberExamples-1
if attri{1,s}(i,5)~=attri{1,s}(i+1,5)
different(j)=i;
j=j+1;
end
end
for i=1:length(different)
classs=s;
pointt=attri{1,s}(different(i),s);
num_class_1=sum(attri{1,s}((1:different(i)),5)==1);
num_class_2=sum(attri{1,s}((1:different(i)),5)==2);
num_class_3=sum(attri{1,s}((1:different(i)),5)==3);
num0_class_1=sum(attri{1,s}(:,5)==1)- num_class_1;
num0_class_2=sum(attri{1,s}(:,5)==2)- num_class_2;
num0_class_3=sum(attri{1,s}(:,5)==3)- num_class_3;
gainn=-(different(i)/numberExamples)*((num_class_1/different(i))*sjlog(num_class_1/different(i))+(num_class_2/different(i))*sjlog(num_class_2/different(i))+(num_class_3/different(i))*sjlog(num_class_3/different(i)))-(1-different(i)/numberExamples)*((num0_class_1/(numberExamples-different(i)))*sjlog(num0_class_1/(numberExamples-different(i)))+(num0_class_2/(numberExamples-different(i)))*sjlog(num0_class_2/(numberExamples-different(i)))+(num0_class_3/(numberExamples-different(i)))*sjlog(num0_class_3/(numberExamples-different(i))));
%计算熵
if gainn<gain
point=pointt;
class=classs;
gain=gainn;
num_diff=different(i);
end
end
end
end
function y = sjlog(x)
%% 重新定义,使0*log0=0
if x==0
y = 0;
else
y = log(x);
end
end
function [attrib]=Iris_tree_preprocess( )
%数据预处理
[attrib1, attrib2, attrib3, attrib4, class] = textread('C:\Users\Administrator\Desktop\iris.data', '%f%f%f%f%s', 'delimiter', ',');
% delimiter , 是跳过符号“,”
a = zeros(150, 1);
a(strcmp(class, 'Iris-setosa')) = 1;
a(strcmp(class, 'Iris-versicolor')) = 2;
a(strcmp(class, 'Iris-virginica')) = 3;
%% 导入鸢yuan尾花数据
for i=1:150
attrib(i,1)=attrib1(i);
attrib(i,2)=attrib2(i);
attrib(i,3)=attrib3(i);
attrib(i,4)=attrib4(i);
attrib(i,5)=a(i);
end
% attrib=sortrows(attrib,1);
end效果如下
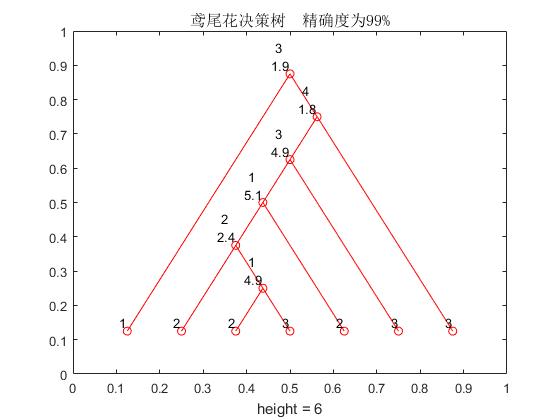
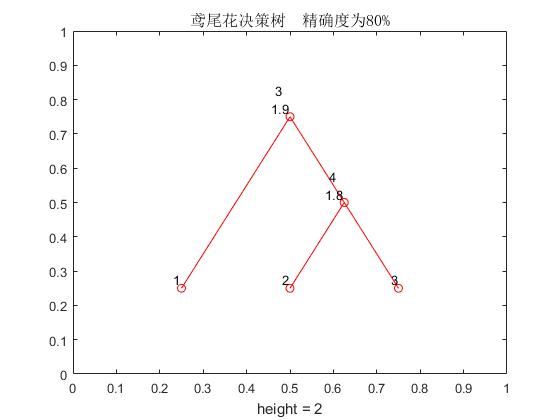
我还是想解释一波,图中的[3,1.9]表示的是划分的属性是第三个属性,用来划分的数值是1.9,比1.9小的部分划分到左子树,比1.9大的部分划分到右子树。而叶节点的数值是样例子集中占最大比例的类别样例的标号。
就是这样了,第一次写博客hhh,仅供小白们参考,当然也可以供大神们一笑嘛。欢迎指教。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/126486.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
