大家好,又见面了,我是你们的朋友全栈君。


一、常用开发工具
1. Navicate
Navicat是一套快速、可靠并价格相宜的数据库管理工具,专为简化数据库的管理及降低系统管理成本而设。它的设计符合数据库管理员、开发人员及中小企业的需要。Navicat 是以直觉化的图形用户界面而建的,让你可以以安全并且简单的方式创建、组织、访问并共用信息。
pojie方式:https://www.jb51.net/database/710931.html
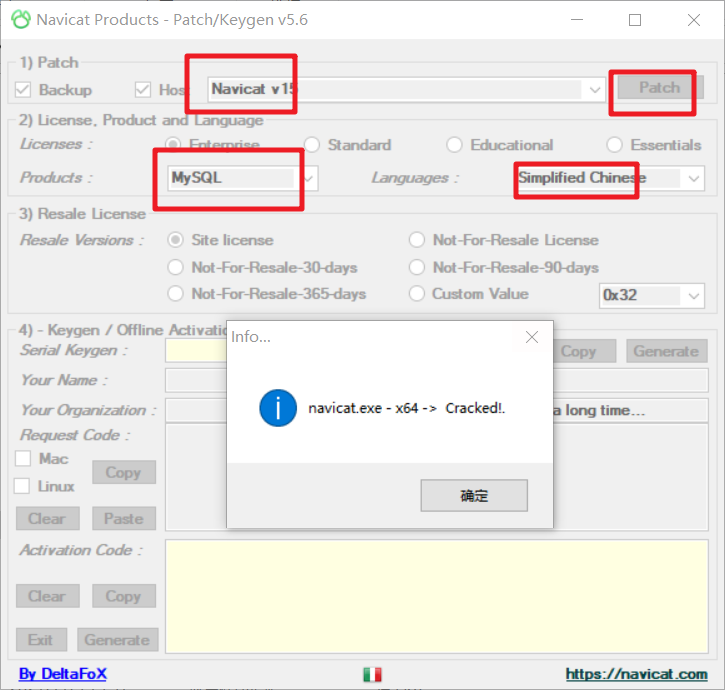
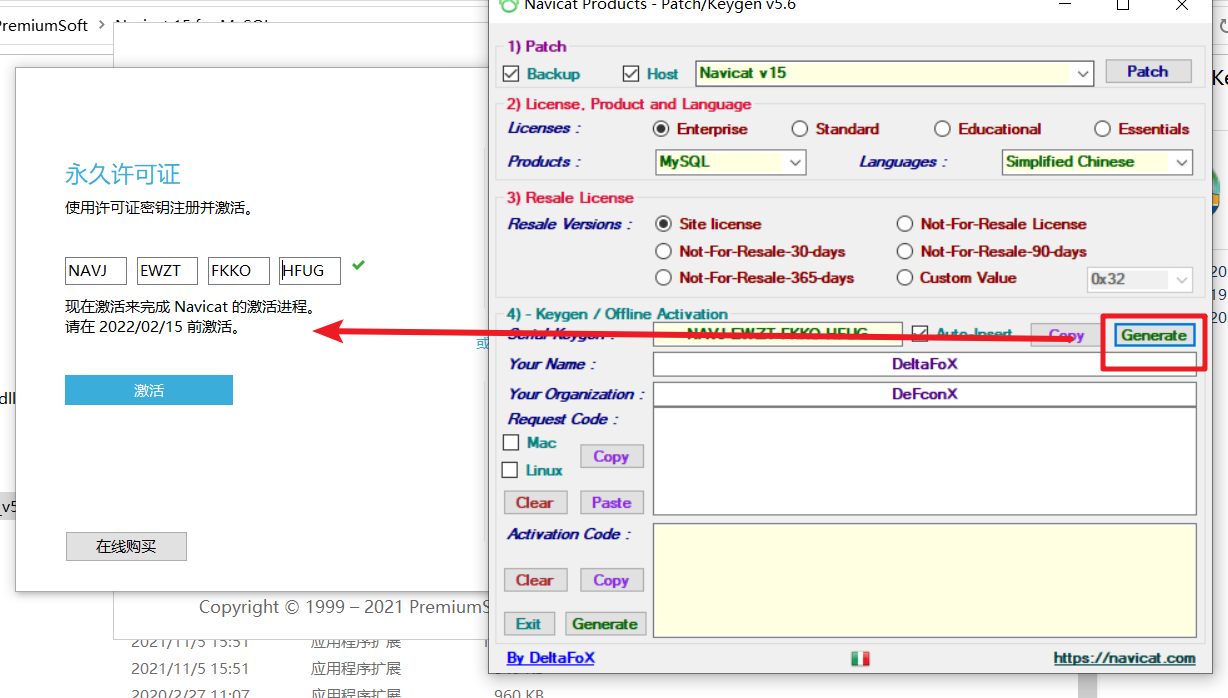
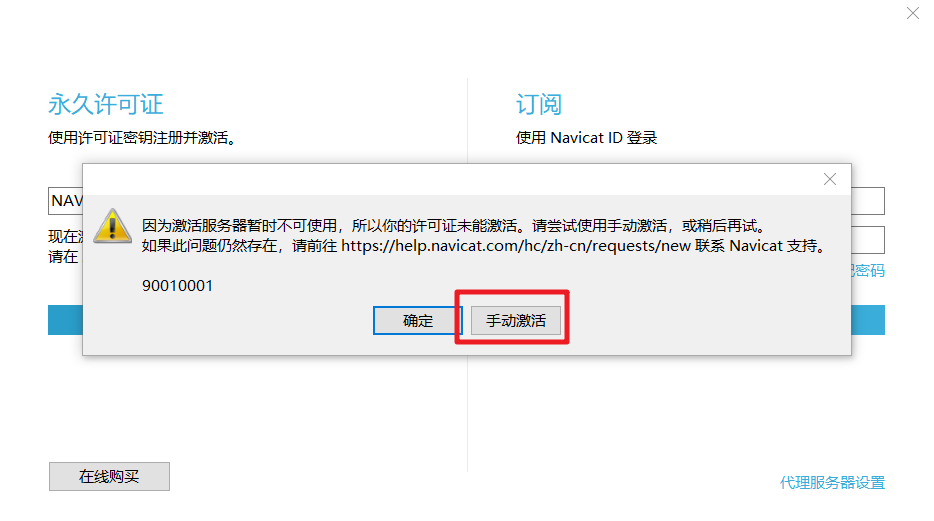
再手动激活
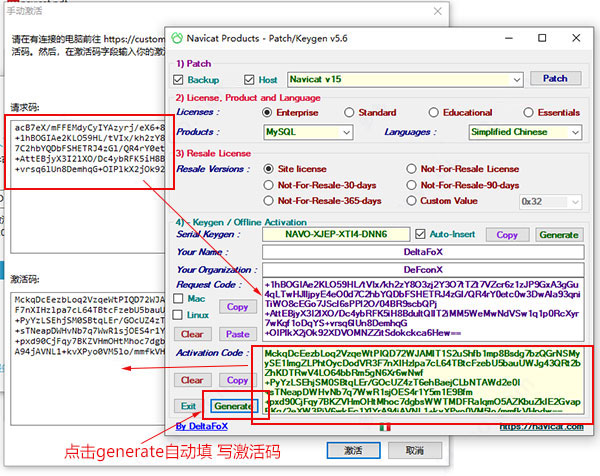

搞定,就可以使用了
2. SQLyog
MySQL可能是世界上最流行的开源数据库引擎,但是使用基于文本的工具和配置文件可能很难进行管理。SQLyog提供了完整的图形界面,即使初学者也可以轻松使用MySQL的强大功能。其拥有广泛的预定义工具和查询、友好的视觉界面、类似 Excel 的查询结果编辑界面等优点。
3. 使用客户端工具
1:创建一个数据库;选择编码为utf-8
2: 创建数据表
3: 往数据表里面存储数据
二、SQL语句基础
结构化查询语言(Structured Query Language)简称SQL,结构化查询语言是一种数据库查询和程序设计语言,用于存放数据以及查询、更新和管理关系数据库系统;同时也是数据库脚本文件的扩展名。结构化查询语言是高级的非过程化编程语言,允许用户在高层数据结构上工作。它不要求用户指定对数据的存放方法,也不需要用户了解具体的数据存放方式,所以具有完全不同底层结构的不同数据库系统,可以使用相同的结构化查询语言作为数据输入与管理的接口。结构化查询语言语句可以嵌套,这使它具有极大的灵活性和强大的功能。

1.SQL分类
1.1 数据定义语言(DDL)
数据定义语言 (Data Definition Language, DDL) 是SQL语言集中,负责数据结构定义与数据库对象定义的语言,由CREATE、ALTER与DROP三个语法所组成,最早是由 Codasyl (Conference on Data Systems Languages) 数据模型开始,现在被纳入 SQL 指令中作为其中一个子集。
1.2 数据操纵语言(DML)
数据操纵语言(Data Manipulation Language, DML)是SQL语言中,负责对数据库对象运行数据访问工作的指令集,以INSERT、UPDATE、DELETE三种指令为核心,分别代表插入、更新与删除。
1.3 数据查询语言(DQL)
数据查询语言(Data Query Language, DQL)是SQL语言中,负责进行数据查询而不会对数据本身进行修改的语句,这是最基本的SQL语句。保留字SELECT是DQL(也是所有SQL)用得最多的动词,其他DQL常用的保留字有FROM,WHERE,GROUP BY,HAVING和ORDER BY。这些DQL保留字常与其他类型的SQL语句一起使用。
1.4 数据控制语言(DCL)
数据控制语言 (Data Control Language) 在SQL语言中,是一种可对数据访问权进行控制的指令,它可以控制特定用户账户对数据表、查看表、预存程序、用户自定义函数等数据库对象的控制权。由 GRANT 和 REVOKE 两个指令组成。DCL以控制用户的访问权限为主,GRANT为授权语句,对应的REVOKE是撤销授权语句。
2.DDL
数据定义语言 (Data Definition Language, DDL) ,它主要包括三个关键字:create ,alter , drop(数据库关键字不分大小写 ),主要操作对象 有数据库、表、索引、视图等.
2.1 操作数据库
创建数据库
create databases 数据库名称;
使用这个数据库
use 数据库名称;
删除这个数据库
drop database 数据库名称;
注意:执行的SQL语句不区分大小写,一个SQL语句末尾要加上;
2.2 操作表结构
表【TABLE】是数据库中存储数据的载体。
2.2.1 语法结构
然后我们来看下DDL是如何来操作表【TABLE】的。
CREATE TABLE 表名称
(
列名称1 数据类型,
列名称2 数据类型,
列名称3 数据类型,
....
)
创建一张用户表
CREATE TABLE T_USER(
id int(3) ,
user_name varchar(30)
)
2.2.2 添加注释
为了让别人能清楚我们定义的字段的含义,我们需要给我们创建的字段添加对应的注释来说明。
CREATE TABLE T_USER(
id int(3) ,
user_name varchar(30) COMMENT '用户名'
)COMMENT='用户表'
或者在建表后添加
ALTER TABLE t_user
MODIFY COLUMN user_name varchar(20) COMMENT 'aaa' ;
2.2.3 删除表
删除表通过DROP关键字来实现
DROP TABLE T_USER;
2.2.4 修改表
添加字段
ALTER TABLE T_USER ADD address VARCHAR(2);
修改字段类型
ALTER TABLE T_USER MODIFY address VARCHAR(50);
修改字段名称
ALTER TABLE T_USER RENAME COLUMN address TO address666;
删除字段
ALTER TABLE T_USER DROP COLUMN address666;
2.2.5 表结构的约束
非空约束
ALTER TABLE T_USER
CHANGE id id INT NOT NULL COMMENT '主键';
或者在建表的时候指定
# 删除表
DROP TABLE T_USER;
CREATE TABLE T_USER(
id INT(5) NOT NULL COMMENT '主键',
user_name VARCHAR(20) COMMENT '账号' ,
age INT(2) COMMENT '年龄' DEFAULT 18
)COMMENT='用户表' ;
默认值
DROP TABLE T_USER;
CREATE TABLE T_USER(
id INT(5) NOT NULL COMMENT '主键',
user_name VARCHAR(20) COMMENT '账号' ,
age INT(2) COMMENT '年龄' DEFAULT 18
)COMMENT='用户表' ;
唯一约束
该字段中不能出现相同的值,null除外
DROP TABLE T_USER;
CREATE TABLE T_USER(
id INT(5) UNIQUE COMMENT '主键',
user_name VARCHAR(20) COMMENT '账号' ,
age INT(2) COMMENT '年龄' DEFAULT 18
)COMMENT='用户表' ;
建表后设置字段的唯一约束条件
ALTER TABLE t_user add CONSTRAINT unique_name UNIQUE(user_name);
alter table t_user add unique (user_name);
主键
能唯一标识一条记录的字段,不能为空,唯一约束,只能有一个主键。
DROP TABLE T_USER;
CREATE TABLE T_USER(
id INT(5) PRIMARY KEY COMMENT '主键',
user_name VARCHAR(20) COMMENT '账号' ,
age INT(2) COMMENT '年龄' DEFAULT 18
)COMMENT='用户表' ;
联合主键:多个字段组合的信息是不能出现重复的
ALTER TABLE t_user
ADD PRIMARY KEY (id, user_name);
外键
外键就是在主表中可以重复出现,但是它的值是另一个表的主键,外键使两个表相关,外键可约束表的数据的更新,外键和主键表联系,数据类型要统一,长度(存储大小)要统一,在更新数据的时候会保持一致性
# 删除表
DROP TABLE T_USER;
CREATE TABLE T_USER(
id INT(5) PRIMARY KEY COMMENT '主键',
user_name VARCHAR(20) COMMENT '账号' ,
age INT(2) COMMENT '年龄' DEFAULT 18,
deptid INT(30) ,
CONSTRAINT FK_DEPT_ID FOREIGN KEY(deptid) REFERENCES T_DEPT(dept_id)
)COMMENT='用户表' ;
ALTER TABLE T_USER ADD
CONSTRAINT FK_DEPT_ID FOREIGN KEY(deptid) REFERENCES T_DEPT(dept_id)
注意:外键字段的级联关系,如果我们要删除外键对应的主键记录,那么必须要先删除该注解对应的所有的外键记录,否则删除不成功,
实际开发中我们对主键的使用比较少。
check
粒度更细的约束。
DROP TABLE T_USER;
CREATE TABLE T_USER(
id INT(5) PRIMARY KEY COMMENT '主键',
user_name VARCHAR(20) COMMENT '账号' ,
age INT(3) COMMENT '年龄' ,
CHECK (age > 0 AND age < 40)
)COMMENT='用户表' ;
between and
in not in or
2.2.6 字段类型
MySQL 中定义数据字段的类型对你数据库的优化是非常重要的。
MySQL 支持多种类型,大致可以分为三类:数值、日期/时间和字符串(字符)类型。
数值类型
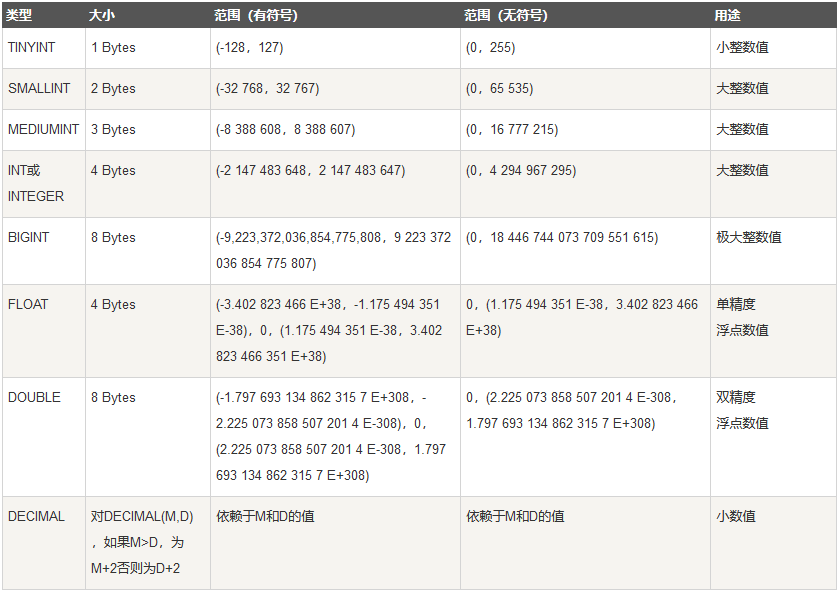
日期和时间类型
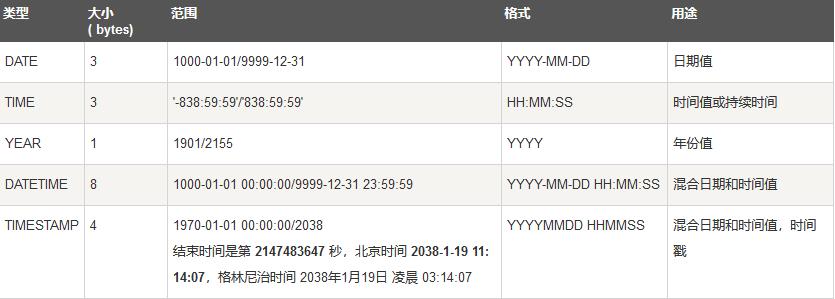
字符串类型
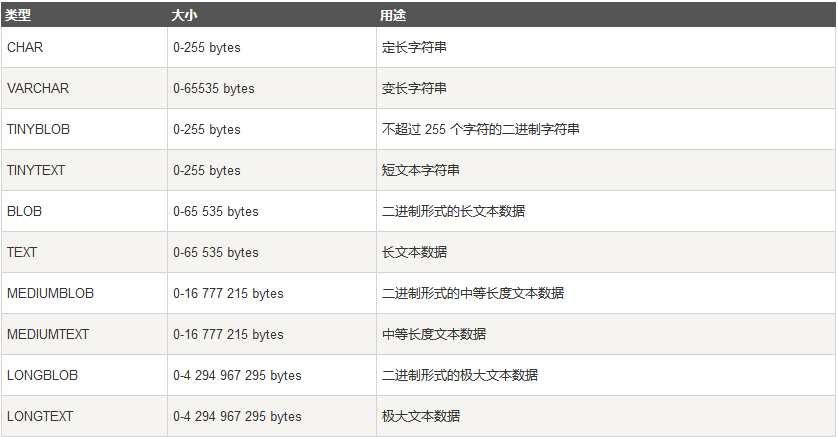
char(n) 和 varchar(n) 中括号中 n 代表字符的个数,并不代表字节个数,比如 CHAR(30) 就可以存储 30 个字符。
CHAR 和 VARCHAR 类型类似,但它们保存和检索的方式不同。它们的最大长度和是否尾部空格被保留等方面也不同。在存储或检索过程中不进行大小写转换
3.DML
数据操纵语言(Data Manipulation Language, DML)是SQL语言中,负责对数据库对象运行数据访问工作的指令集,以INSERT、UPDATE、DELETE三种指令为核心,分别代表插入、更新与删除。
3.1 INSERT
插入单行记录
INSERT into 列名(列名,。。)values(,)
插入多行记录
复制表结构和数据
create table t_student_beifen as select * from t_student
复制表结构
create table t_student_beifen as select * from t_student where 1 <> 1
把其他表结构中的数据插入到表中:
insert into t_student(id,stuname) select id,stuname from t_student01
可以在单行插入的后面添加多个插入的信息列。
# 插入语句后面可以跟多个插入的信息
insert into t_user (user_name,age)values('烤鱼1',22),('烤鱼2',22),('烤鱼3',22);
3.2 UPDATE
语法结构
update 表名 set 字段名=值,字段名=值。。 where 。。。
案例:
创建一张学生表
CREATE TABLE t_student
(
id int(3) primary key,
stuname varchar(30) not null,
sex char(3) ,
birthday date
)
把学生表中的性别全部改成女
update t_student set sex = '女' ;
把’张三’的性别改成’男’
update t_student set sex = '男' where stuname = '张三';
把出生日期改成当前时间now()
# select now()
update t_student set birthday = now()
把性别为女的 所有的出生日期改成2022-01-18
# 直接把一个字符串复制给了一个 date 类型的数据
# str_to_date 把字符串转换为日期类型
update t_student set birthday = str_to_date('2022-01-18','%Y-%m-%d') where sex = '女';
从别的表把值设置到本表中
create table t_student_1 as select * from t_student;
update t_student_1 t1,t_student t2 set t1.stuname = t2.stuname where t1.id = t2.id;
3.3 DELETE
delete删除:
delete from t_student where id = 1;
# 如果不带where 条件 那么表示删除该表中的所有的记录 慎用!!! 删表跑路
delete from t_student ;
# delete insert update 语句都会走事务处理,也就是我们需要显示的commit和rollback;
truncate删除:
# truncate 直接清空表结构中的所有的数据,效率高,但是不能回滚。
TRUNCATE TABLE t_user_1 # where 1 = 1;
4.DQL
数据查询语言(Data Query Language, DQL)是SQL语言中,负责进行数据查询而不会对数据本身进行修改的语句,这是最基本的SQL语句。保留字SELECT是DQL(也是所有SQL)用得最多的动词,其他DQL常用的保留字有FROM,WHERE,GROUP BY,HAVING和ORDER BY。这些DQL保留字常与其他类型的SQL语句一起使用。
4.1 单表查询
查询语句的语法规则
SELECT <字段列表>
FROM <表名>
[WHERE <查询条件>]
[ORDER BY <排序字段>]
[GROUP BY <分组字段>]
# select NOW()
为查询准备的表结构
CREATE TABLE t_student (
id int(3) primary key auto_increment ,
stuname varchar(30) not null ,
age int(3) ,
sex varchar(3) ,
birthday date ,
address varchar(50),
class_id int(3)
);
CREATE TABLE t_class(
class_id varchar(30) PRIMARY KEY ,
class_name varchar(30) UNIQUE ,
class_desc varchar(50)
);
单表查询不带条件的查询
# 1.查询出所有的学生信息 所有的学生的所有字段的信息
select * from t_student ;
# 2.查询出所有的学生的姓名和性别
select stuname,sex from t_student;
# 3.对查询的表和列设置对应的别名
select stuname as '姓名' ,sex as "性别" from t_student;
# 别名简写可以省略 as 和 单引号
select stuname 名称 ,sex 性别 from t_student;
# 表也可以取别名
select t_student.stuname ,t_student.sex from t_student;
select t1.stuname,t1.sex from t_student as t1;
select t1.stuname,t1.sex from t_student t1;
# 自己增加查询的字段
select stuname,sex,18 常量 from t_student;
# 4.查询出所有的学生信息,并且显示的形式是【张三】18【岁】
select stuname,age,concat('【',stuname,'】',age,'【岁】') from t_student;
单表查询带条件的
# 5.查询出学生表中张三的所有的信息
select * from t_student where stuname = '张三';
# 6.查询出学生表中年龄在18到22之间的学生的所有信息
select * from t_student where age >=18 and age <= 22;
select * from t_student where age BETWEEN 18 and 22 ;
# 7.查询出学生表中编号为1和3的学生信息
select *
from t_student
where id = 1 or id = 3;
select * from t_student where id in (1,3)
# 8.查询出学生表中地址信息为空的学生信息
# 不行 #
# select * from t_student where address = '';
# select * from t_student where address = null;
select * from t_student where address is null;
# 不为空的情况
select * from t_student where address is not null;
# 9.查询出所有姓张的学生的所有信息 -- 模糊查询 like
select * from t_student where stuname like '张%' ;
# 如果不加% 其实和=差不多
select * from t_student where stuname like '张三';
select * from t_student where stuname like '%三%';
# 10.查询出学生表中年龄大于20的男同学的所有信息
select * from t_student where age > 20 and sex = '男'
# 11 查询出学生表中年龄大于20或者住址在长沙的同学的所有信息
select * from t_student where age > 20 or address like '%长沙%'
# 12 查询出所有的学生信息,根据id降序 desc 降序 asc 升序【默认就是升序,也就是 asc可以省略】
select *
from t_student
order by id desc;
select *
from t_student
order by id asc;
select *
from t_student
order by id ;
# 排序我们可以根据多个字段来排列,前面的字段优先排序
# 先根据age降序排列,如果age有相同的信息,那么再根据id升序排序
select * from t_student order by age desc ,id asc;
select * from t_student order by age desc ,id desc;
4.2 聚合函数
聚合函数一般用于统计
# 聚合函数 -- 一般用于统计
# 1.统计学员的总数 count 统计某列中非空的数据的条数
select count(*) from t_student ;
select count(id) from t_student ;
select count(address) from t_student;
select count(birthday) from t_student;
## 在实际开发中我们使用 count(1) 来统计,效率会更高
select 1,id from t_student ;
select count(1) from t_student ;
# 2.统计班级中学生最大的年龄
select max(age) from t_student ;
# 3.统计班级中学习最小的年龄
select min(age) from t_student ;
# 4.统计班级中的学员的平均年龄
select avg(age) from t_student ;
# 5.统计班级中学员的年龄总和
select sum(age) from t_student ;
4.3 分组查询
语法规则
SELECT <字段列表>
FROM <表名>
[WHERE <查询条件>]
[ORDER BY <排序字段>]
[GROUP BY <分组字段>]
[HAVING <分组后的查询条件>]
分组查询通常用于统计,一般和聚合函数配合使用
注:分组查询有一个原则,就是 select 后面的所有列中没有使用聚合函数的列,必须出现在group by后面
4.4 常用函数
4.4.1 数字函数
| 函数 | 说明 |
|---|---|
| ABS(x) | 返回x的绝对值 |
| AVG(expression) | 返回一个表达式的平均值,expression 是一个字段 |
| CEIL(x)/CEILING(x) | 返回大于或等于 x 的最小整数 |
| FLOOR(x) | 返回小于或等于 x 的最大整数 |
| EXP(x) | 返回 e 的 x 次方 |
| GREATEST(expr1, expr2, expr3, …) | 返回列表中的最大值 |
| LEAST(expr1, expr2, expr3, …) | 返回列表中的最小值 |
| LN | 返回数字的自然对数 |
| LOG(x) | 返回自然对数(以 e 为底的对数) |
| MAX(expression) | 返回字段 expression 中的最大值 |
| MIN(expression) | 返回字段 expression 中的最大值 |
| POW(x,y)/POWER(x,y) | 返回 x 的 y 次方 |
| RAND() | 返回 0 到 1 的随机数 |
| ROUND(x) | 返回离 x 最近的整数 |
| SIGN(x) | 返回 x 的符号,x 是负数、0、正数分别返回 -1、0 和 1 |
| SQRT(x) | 返回x的平方根 |
| SUM(expression) | 返回指定字段的总和 |
| TRUNCATE(x,y) | 返回数值 x 保留到小数点后 y 位的值(与 ROUND 最大的区别是不会进行四舍五入) |
案例
# 数字函数
# abs函数 取绝对值
select abs(-100) ;
# avg() 取平均值
select avg(age) from t_student;
# CEIL(x)/CEILING(x)
select ceil(2.5) ;
select ceil(avg(age) ) from t_student;
select ceiling(3) ;
select ceil(3) ;
# floor
select floor(2.5) ;
# exp e的3次方
select exp(3) ;
# GREATEST(expr1, expr2, expr3, …) 返回列表中的最大值
select GREATEST(1,4,5,3,9,2) ;
# LEAST(value1,value2,...) 返回列表中的最小值
select LEAST(1,4,5,3,9,2) ;
# LN 自然对数
select ln(2) ;
# LOG(x)
select log(20) ;
# POW(x,y) 返回x的y次方
select POW(2,3) ;
# RAND() 返回0~1的随机值
select RAND() ;
# ROUND(x) 返回离x最近的整数
select round(5.12) ;
# SIGN(x) 判断x的符号 大于0 等于0 小于0 1 0 -1
select sign(99),sign(0),sign(-199);
# SQRT(x) x的平方根
select SQRT(9);
# TRUNCATE(x,y)
select TRUNCATE(3.15926,3),TRUNCATE(3.15926,2) ;
4.4.2 字符串函数
| 函数 | 说明 |
|---|---|
| ASCII(s) | 返回字符串 s 的第一个字符的 ASCII 码 |
| LENGTH/CHAR_LENGTH(s)/CHARACTER_LENGTH(s) | 返回字符串 s 的字符数 |
| CONCAT(s1,s2…sn) | 字符串 s1,s2 等多个字符串合并为一个字符串 |
| FIND_IN_SET(s1,s2) | 返回在字符串s2中与s1匹配的字符串的位置 |
| FORMAT(x,n) | 函数可以将数字 x 进行格式化 “#,###.##”, 将 x 保留到小数点后 n 位,最后一位四舍五入 |
| INSERT(s1,x,len,s2) | 字符串 s2 替换 s1 的 x 位置开始长度为 len 的字符串 |
| LOCATE(s1,s) | 从字符串 s 中获取 s1 的开始位置 |
| LCASE(s)/LOWER(s) | 将字符串 s 的所有字母变成小写字母 |
| UCASE(s)/UPPER(s) | 将字符串 s 的所有字母变成大写字母 |
| TRIM(s) | 去掉字符串 s 开始和结尾处的空格 |
| LTRIM(s) | 去掉字符串 s 开始处的空格 |
| RTRIM(s) | 去掉字符串 s 结尾处的空格 |
| SUBSTR(s, start, length) | 从字符串 s 的 start 位置截取长度为 length 的子字符串 |
| SUBSTR/SUBSTRING(s, start, length) | 从字符串 s 的 start 位置截取长度为 length 的子字符串 |
| POSITION(s1 IN s) | 从字符串 s 中获取 s1 的开始位置 |
| REPEAT(s,n) | 将字符串 s 重复 n 次 |
| REVERSE(s) | 将字符串s的顺序反过来 |
| STRCMP(s1,s2) | 比较字符串 s1 和 s2,如果 s1 与 s2 相等返回 0 ,如果 s1>s2 返回 1,如果 s1<s2 返回 -1 |
# 字符串函数
# ASCII 查看第一个字符的ASCII值
select ascii('ABC'),ascii('BC');
# length 返回字符串的长度 字符个数
select length('abcd1234'),CHAR_LENGTH('abcd1234');
# CONCAT(s1,s2…sn) 字符串拼接
select id,stuname ,age,concat('【',id,'】',stuname) from t_student
# FIND_IN_SET(s1,s2) 返回在字符串s2中与s1匹配的字符串的位置
select FIND_IN_SET("c","a,b,c,d,e,f,g");
select FIND_IN_SET('c','a,b,c,d,e,f,g');
# FORMAT(x,n) 函数可以将数字 x 进行格式化 “#,###.##”, 将 x 保留到小数点后 n 位,最后一位四舍五入
select FORMAT(19999999999.5678,2);
# INSERT(s1,x,len,s2) 字符串 s2 替换 s1 的 x 位置开始长度为 len 的字符串
select INSERT("www.baidu.com",5,5,"sinax") ;
# LOCATE(s1,s) 从字符串 s 中获取 s1 的开始位置
select LOCATE("a","bcdaefg");
# LCASE(s)/LOWER(s) 转换为小写
# UCASE(s)/UPPER(s) 转换为大写
select lcase('ABCedfgDDDddd'),LOWER('ABCedfgDDDddd'),UCASE('ABCedfgDDDddd'),UPPER('ABCedfgDDDddd') ;
# TRIM(s) 去掉字符串 s 开始和结尾处的空格
# LTRIM(s) 去掉字符串 s 开始空格
# RTRIM(s) 去掉字符串 s 结尾处的空格
select TRIM(' abc def '),LTRIM(' abc def '),RTRIM(' abc def ');
# SUBSTR(s, start, length) SUBSTRING 从字符串 s 的 start 位置截取长度为 length 的子字符串
select substr("abcdefg1234566",4,5) ;
# POSITION(s1 IN s) 从字符串 s 中获取 s1 的开始位置
select POSITION("123" in "abcdefg1235")
# REPEAT(s,n) 将字符串 s 重复 n 次
select REPEAT("hello-",5);
# REVERSE(s) 将字符串s的顺序反过来
select REVERSE("abcdefg") ;
# STRCMP(s1,s2) 比较字符串 s1 和 s2,如果 s1 与 s2 相等返回 0 ,如果 s1>s2 返回 1,如果 s1<s2 返回 -1
select STRCMP("abc","abc") ,STRCMP("a1","a2"),STRCMP("a2","a1") ;
4.4.3 日期函数
| 函数 | 说明 |
|---|---|
| CURDATE()/CURRENT_DATE() | 返回当前日期 |
| CURRENT_TIME()/CURTIME() | 返回当前时间 |
| CURRENT_TIMESTAMP() | 返回当前日期和时间 |
| ADDDATE(d,n) | 计算起始日期 d 加上 n 天的日期 |
| ADDTIME(t,n) | 时间 t 加上 n 秒的时间 |
| DATE() | 从日期或日期时间表达式中提取日期值 |
| DAY(d) | 返回日期值 d 的日期部分 |
| DATEDIFF(d1,d2) | 计算日期 d1->d2 之间相隔的天数 |
| DATE_FORMAT(f) | 按表达式 f的要求显示日期 d |
| DAYNAME(d) | 返回日期 d 是星期几,如 Monday,Tuesday |
| DAYOFMONTH(d) | 计算日期 d 是本月的第几天 |
| DAYOFWEEK(d) | 日期 d 今天是星期几,1 星期日,2 星期一,以此类推 |
| EXTRACT(type FROM d) | 从日期 d 中获取指定的值,type 指定返回的值 type可取值为: MICROSECOND SECOND MINUTE HOUR DAY WEEK MONTH QUARTER YEAR SECOND_MICROSECOND MINUTE_MICROSECOND MINUTE_SECOND HOUR_MICROSECOND HOUR_SECOND HOUR_MINUTE DAY_MICROSECOND DAY_SECOND DAY_MINUTE DAY_HOUR YEAR_MONTH |
| DAYOFWEEK(d) | 日期 d 今天是星期几,1 星期日,2 星期一,以此类推 |
| UNIX_TIMESTAMP() | 得到时间戳 |
| FROM_UNIXTIME() | 时间戳转日期 |
# 日期时间函数
select now();
# CURDATE()/CURRENT_DATE() 返回当前日期
select CURDATE(),CURRENT_DATE() ;
# CURRENT_TIME()/CURTIME() 返回当前时间
select CURTIME() , CURRENT_TIME() ;
# now() CURRENT_TIMESTAMP() 返回当前日期和时间
select now(),CURRENT_TIMESTAMP() ;
# ADDDATE(d,n) 计算起始日期 d 加上 n 天的日期
select ADDDATE("2022-01-26",6) ,ADDDATE(now(),10) ;
# ADDTIME(t,n) 时间 t 加上 n 秒的时间
select ADDTIME('2022-01-02 11:11:11',59),ADDTIME(now(),60*60)
# DATE() 从日期或日期时间表达式中提取日期值
select date('2022-01-02 11:11:11') ,date(now());
# DAY(d) 返回日期值 d 的日期部分
select day('2022-01-02 11:11:11'),day(now()) ;
# DATEDIFF(d1,d2) 计算日期 d1->d2 之间相隔的天数
select DATEDIFF("2021-12-23","2022-01-01") ,DATEDIFF("2022-01-01","2021-12-23");
# DATE_FORMAT(f) 按表达式 f的要求显示日期 d
select DATE_FORMAT(now(),"%Y-%m-%d %r") ,DATE_FORMAT(now(),"%Y-%m-%d %H:%I:%S");
# DAYNAME(d) 返回日期 d 是星期几,如 Monday,Tuesday
select DAYNAME(now()),DAYNAME("2022-02-14")
# DAYOFMONTH(d) 计算日期 d 是本月的第几天
select DAYOFMONTH(now()),DAYOFMONTH("2022-02-14");
# DAYOFWEEK(d) 日期 d 今天是星期几,1 星期日,2 星期一,以此类推
select DAYOFWEEK(now()) ,DAYOFWEEK("2022-02-14");
# EXTRACT(type FROM d) 从日期 d 中获取指定的值,type 指定返回的值
select EXTRACT(DAY from now())
,EXTRACT(WEEK from now())
,EXTRACT(HOUR from now())
,EXTRACT(SECOND from now())
,EXTRACT(MINUTE from now())
# UNIX_TIMESTAMP() 获取时间戳
select UNIX_TIMESTAMP('2022-01-01')
# FROM_UNIXTIME() 根据时间戳转换为日志
select FROM_UNIXTIME(1640966400) ;
4.4.4 高级函数
CASE函数,类似于Java中Switch语句
语法:
CASE
WHEN condition1 THEN result1
WHEN condition2 THEN result2
WHEN conditionN THEN resultN
ELSE result
END;
# 高级函数
# case函数
select * from t_student ;
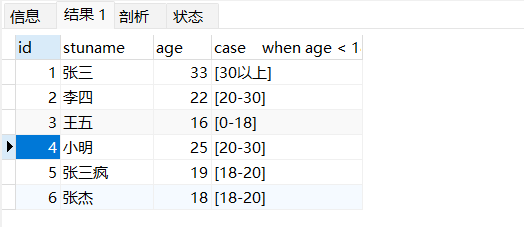
select
id,stuname,age
,case
when age < 18 then '[0-18]'
when age BETWEEN 18 and 20 then '[18-20]'
when age BETWEEN 20 and 30 then '[20-30]'
else '[30以上]'
end
from t_student
IF函数
IF()函数在条件为TRUE时返回一个值,如果条件为FALSE则返回另一个值。
语法:IF(condition, value_if_true, value_if_false)
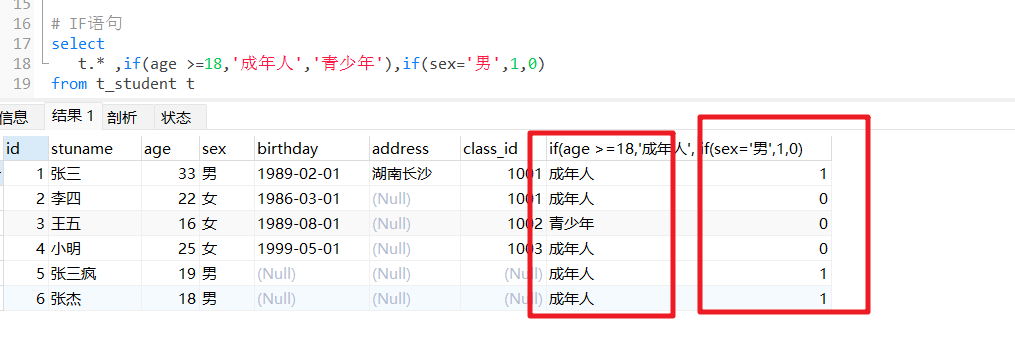
# IF语句
select
t.* ,if(age >=18,'成年人','青少年'),if(sex='男',1,0)
from t_student t
IFNULL函数
如果表达式为NULL,则IFNULL()函数返回指定的值。如果表达式为NOT NULL,则此函数返回表达式。
语法:IFNULL(expression, alt_value)
# IFNULL 函数
select t.* ,ifnull(address,"中国") from t_student t

ISNULL函数
ISNULL()函数返回1或0,具体取决于表达式是否为NULL。如果expression为NULL,则此函数返回1.否则,返回0。
语法:ISNULL(expression)
# ISNULL() 函数
select t.* ,ISNULL(address) from t_student t;

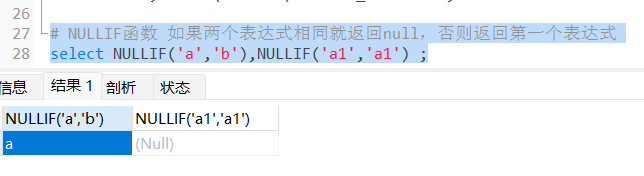
NULLIF函数
NULLIF()函数比较两个表达式,如果它们相等则返回NULL。 否则,返回第一个表达式。
语法:NULLIF(expr1, expr2)
# NULLIF函数 如果两个表达式相同就返回null,否则返回第一个表达式
select NULLIF('a','b'),NULLIF('a1','a1') ;
CAST函数
CAST()函数将(任何类型的)值转换为指定的数据类型。
语法:CAST(value AS datatype)
# CAST函数
select CAST('2022-02-13' as DATE) ;
select CAST('2022-02-13 12:12:24' as TIME) ;
select CAST(97 as CHAR) ;
select CAST(5-20 as SIGNED) ;
select CAST(12.666 as DECIMAL);
select CAST('66' as BINARY);
4.5 多表查询
4.5.1 交叉连接
交叉连接是不带WHERE 子句的多表查询,它返回被连接的两个表所有数据行的笛卡尔积
SELECT *
FROM T_A , T_B
案例
# 交叉连接
select t1.* ,t2.*
from t_student t1,t_class t2;
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HOXXadOP-1644764461096)(img\image-20220213150351624.png)]
4.5.2 内连接
在交叉连接的基础上增加连接的条件,不需要连接无效的记录
SELECT *
FROM T_A INNER JOIN T_B ON T_A.SID = T_B.SID
# 等价于
SELECT *
FROM T_A,T_B
WHERE T_A.SID = T_B.SID
案例
# 内连接 : 在交叉连接的基础上增加连接的条件,不需要连接无效的记录
select t1.*,t2.*
from t_student t1 INNER JOIN t_class t2
on t1.class_id = t2.class_id # on 关键字后面的是连接的条件
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-gkVMeXwE-1644764461096)(img\image-20220213150913627.png)]
4.5.3 外连接
左连接
select t1.*, t2.* from t_student t1 left outer join t_class t2 on t1.classid=t2.id
右连接
select t1.*, t2.* from t_student t1 right join t_class t2 on t1.classid=t2.id
全连接
select t1.*, t2.* from t_student t1 full join t_class t2 on t1.classid=t2.id
案例
# 外连接: 找到学生表中的所有的学生信息及对应的班级信息
# 内连接只会保留满足连接条件的记录
# 左外连接: 在内连接的基础上保留了左侧表结构中不满足连接条件的记录
select t1.*,t2.*
from t_student t1 LEFT JOIN t_class t2
on t1.class_id = t2.class_id
# 右外连接:在内连接的基础上保留了右侧表结构中不满足连接条件的记录
select t1.*,t2.*
from t_Class t1 RIGHT JOIN t_student t2
on t1.class_id = t2.class_id
select t1.*,t2.*
from t_class t1 LEFT JOIN t_student t2
on t1.class_id = t2.class_id
# 全连接
# 全连接的作用是 在内连接的基础上保留的左右两边不满足条件的记录,但是在MySQL中已经移除了全连接,但是在Oracle或者其他的数据库中是存在的。
select t1.*,t2.*
from t_student t1 LEFT JOIN t_class t2
on t1.class_id = t2.class_id;
# 对应的全连接操作
select t1.*,t2.*
from t_student t1 FULL JOIN t_class t2
on t1.class_id = t2.class_id;
select t1.*,t2.*
from t_class t1 LEFT JOIN t_student t2
on t1.class_id = t2.class_id;
select t1.*,t2.*
from t_class t1 FULL JOIN t_student t2
on t1.class_id = t2.class_id;
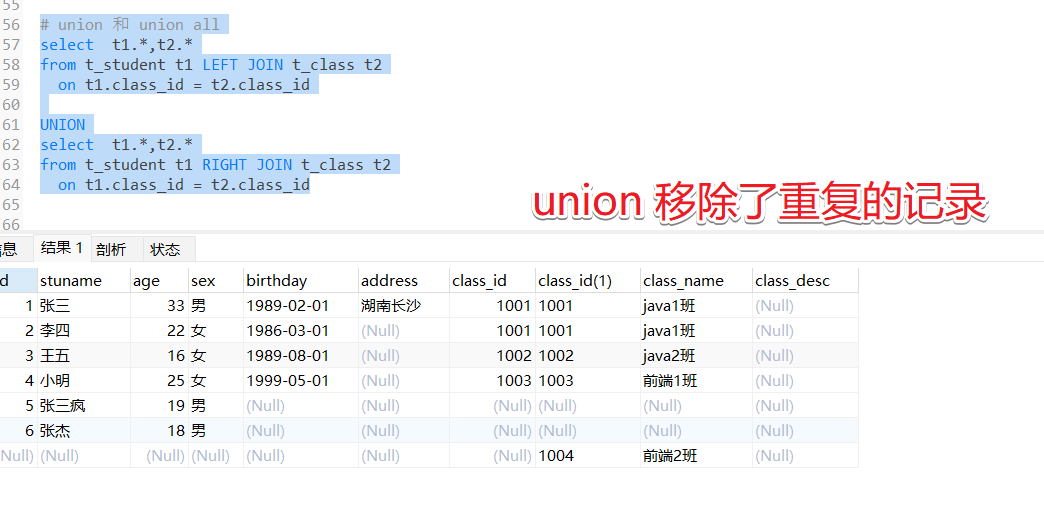
等价于 : union 与union all区别
select t1.*, t2.* from t_student t1 left outer join t_class t2 on t1.classid=t2.id
union
select t1.*, t2.* from t_student t1 right join t_class t2 on t1.classid=t2.id
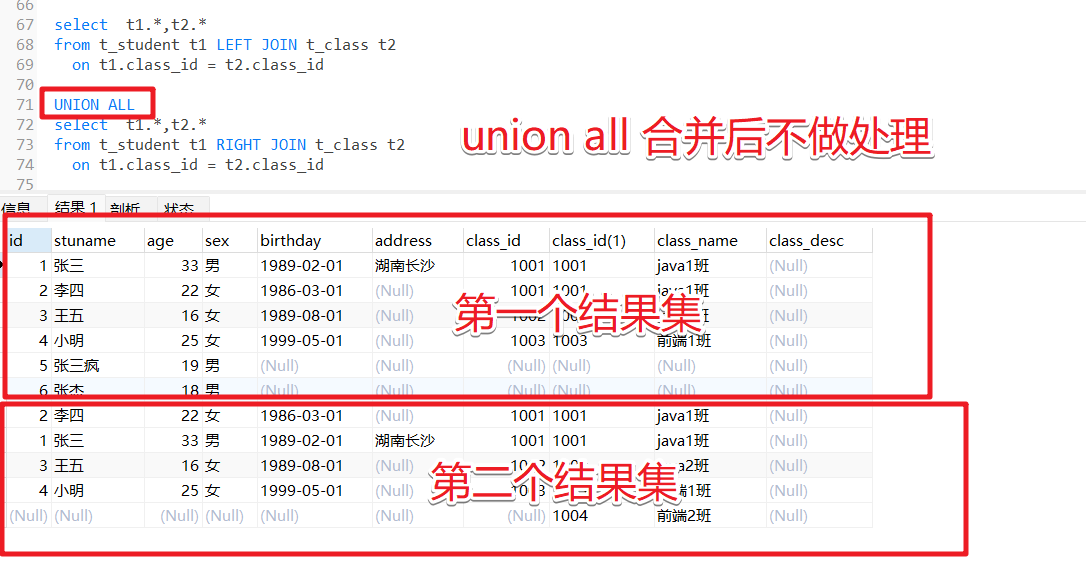
select t1.*, t2.* from t_student t1 left outer join t_class t2 on t1.classid=t2.id
union all
select t1.*, t2.* from t_student t1 right join t_class t2 on t1.classid=t2.id
union和union all都能实现结果集的合并
union合并结果集后会取出重复的记录
union all 合并结果集后不会移除重复的记录
4.5.4 子查询
# 子查询 嵌套查询
# 查询出班级为 java1班 的所有的学员信息
select t1.*
from t_student t1
where class_id in (
select t_class.class_id from t_class where t_class.class_name = 'java1班' or t_class.class_name = 'java2班'
)
# 如果在子查询中只有一条记录那么我们可以用=来替代in
select t1.*
from t_student t1
where class_id = (
select t_class.class_id from t_class where t_class.class_name = 'java1班' or t_class.class_name = 'java2班'
)
select t1.*
from t_student t1
where EXISTS # exists 存在于的含义 外表中的记录存在于子表中 就满足条件 否则就过滤掉
(
select t_class.class_id from t_class where t_class.class_name = 'java1班' and t1.class_id = t_class.class_id
)
4.6 综合案例
drop table student;
create table student (
id int(3) PRIMARY KEY ,
name varchar(20) not null,
sex varchar(4),
birth int(4),
department varchar(20),
address varchar(50));
# 创建score表。SQL代码如下:
drop table score;
create table score(
id int(3) PRIMARY KEY ,
stu_id int(3) not null,
c_name varchar(20) ,
grade int(3)
)
-- 向student表插入记录的INSERT语句如下:
insert into student values(901,'张老大','男',1985,'计算机系','北京市海淀区');
insert into student values(902,'张老二','男',1986,'中文系','北京市昌平区');
insert into student values(903,'张三','女',1990,'中文系','湖南省永州市');
insert into student values(904,'李四','男',1990,'英语系','辽宁省阜新市');
insert into student values(905,'王五','女',1991,'英语系','福建省厦门市');
insert into student values(906,'王六','男',1988,'计算机系','湖南省衡阳市');
-- 向score表插入记录的INSERT语句如下:
insert into score values(1,901,'计算机',98);
insert into score values(2,901,'英语',80);
insert into score values(3,902,'计算机',65);
insert into score values(4,902,'中文',88);
insert into score values(5,903,'中文',95);
insert into score values(6,904,'计算机',70);
insert into score values(7,904,'英语',92);
insert into score values(8,905,'英语',94);
insert into score values(9,906,'计算机',90);
insert into score values(10,906,'英语',85);
SELECT * from student;
select * from score;
1、查询student表的第2条到4条记录
select * from student LIMIT 1,3;
2、从student表查询所有学生的学号(id)、
姓名(name)和院系(department)的信息
select id '学号' ,name as '姓名' ,department 院系
from student t
3、从student表中查询计算机系和英语系的学生的信息
select *
from student t
where t.department = '计算机系' or t.department='英语系'
select *
from student t
where t.department in ('计算机系','英语系')
4、从student表中查询年龄25~30岁的学生信息
select *,EXTRACT(year from now()) ,EXTRACT(year from now())-birth age
from student where (EXTRACT(year from now()) - birth) BETWEEN 30 and 40;
5、从student表中查询每个院系有多少人
select t.department,count(1)
from student t
group by t.department
6、从score表中查询每个科目的最高分
select s.c_name,max(grade)
from score s
group by s.c_name
7、查询李四的考试科目(c_name)和考试成绩(grade)
注意: '=' 只有在确定结果是一个的情况下使用,不确定的使用用 'in'
select c_name,grade
from score
where stu_id in (
select id from student where name = '李四'
)
# 通过exists
select c_name ,grade
from score s
where EXISTS (
select id from student where name = '李四' and student.id = s.stu_id
)
# 通过左连接来实现
select t1.*
from score t1 RIGHT join ( select * from student where name = '李四') t2
on t1.stu_id = t2.id ;
select t1.*,t2.*
from score t1 RIGHT join student t2
on t1.stu_id = t2.id
where t2.name = '李四'
8、用内连接的方式查询所有学生的信息和考试信息
select t1.*,t2.*
from student t1 INNER JOIN score t2
on t1.id = t2.stu_id
9、计算每个学生的总成绩
select stu_id,sum(grade)
from score
group by stu_id
select stu_id,(select name from student where id = stu_id) 姓名,sum(grade)
from score
group by stu_id
select t1.name,sum(t2.grade)
from student t1 INNER JOIN score t2
on t1.id = t2.stu_id
group by t1.name
10、计算每个考试科目的平均成绩
select c_name,TRUNCATE(avg(grade),2) 平均分
from score
group by c_name
11、查询计算机成绩低于95的学生信息
select *
from student
where id in (
select stu_id from score where c_name = '计算机' and grade < 95
)
select *
from student
where EXISTS (
select stu_id from score where c_name = '计算机' and grade < 95 and student.id = stu_id
)
12、查询同时参加计算机和英语考试的学生的信息
select * from score;
# 首先查询出 参加计算机的学员
select * from score where c_name = '计算机'
select * from score where c_name = '英语'
select * from student where id in (
select stu_id from score where stu_id in (
select stu_id from score where c_name = '计算机' )
and c_name = '英语' )
13、将计算机考试成绩按从高到低进行排序
select *
from score
where c_name = '计算机'
order by grade desc
14、从student表和score表中查询出学生的学号,
然后合并查询结果 UNION与union all
select id
from student
union
select stu_id
from score
select id
from student
union all
select stu_id
from score
15、查询姓张或者姓王的同学的姓名、院系和考试科目及成绩
select name 姓名, department 院系, c_name 考试科目 ,grade 成绩
from student t1 left join score t2 on t1.id = t2.stu_id
where t1.name like '张%' or t1.name like '王%'
select name 姓名, department 院系, c_name 考试科目 ,grade 成绩
from (select * from student where name like '张%' or name like '王%') t1 left join score t2 on t1.id = t2.stu_id
16、查询都是湖南的学生的姓名、年龄、院系和考试科目及成绩
select name 姓名, (EXTRACT(year from now()) - birth) 年龄, department 院系, c_name 考试科目 ,grade 成绩
from student t1 left join score t2
on t1.id = t2.stu_id
where address like '湖南%'
5.DCL
数据控制语句,用于控制不同数据段直接的许可和访问级别的语句。这些语句定义了数据库、表、字段、用户的访问权限和安全级别。主要的语句关键字包括grant、revoke 等。
DCL 语句主要是DBA 用来管理系统中的对象权限时所使用,一般的开发人员很少使用。下面
通过一个例子来简单说明一下.
mysql> grant select,insert on plf.* to 'plf'@'%' identified by '123456';
Query OK, 0 rows affected (0.00 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
mysql> revoke insert on plf.* from 'plf'@'%';
Query OK, 0 rows affected (0.00 sec)
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/126370.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
