大家好,又见面了,我是你们的朋友全栈君。


您好,欢迎关注《认文识字——中文字信息精准化》报告。我是安秀。
这里说的“中文字”,是“中国文字”的简称,也就是我们常说的“汉字”。
【认文识字】是以“中文字信息精准化”为导向,而沉淀出的一整个“从文到字”脉络关系大网和相应的信息数据。
今天发表出来,跟您分享。

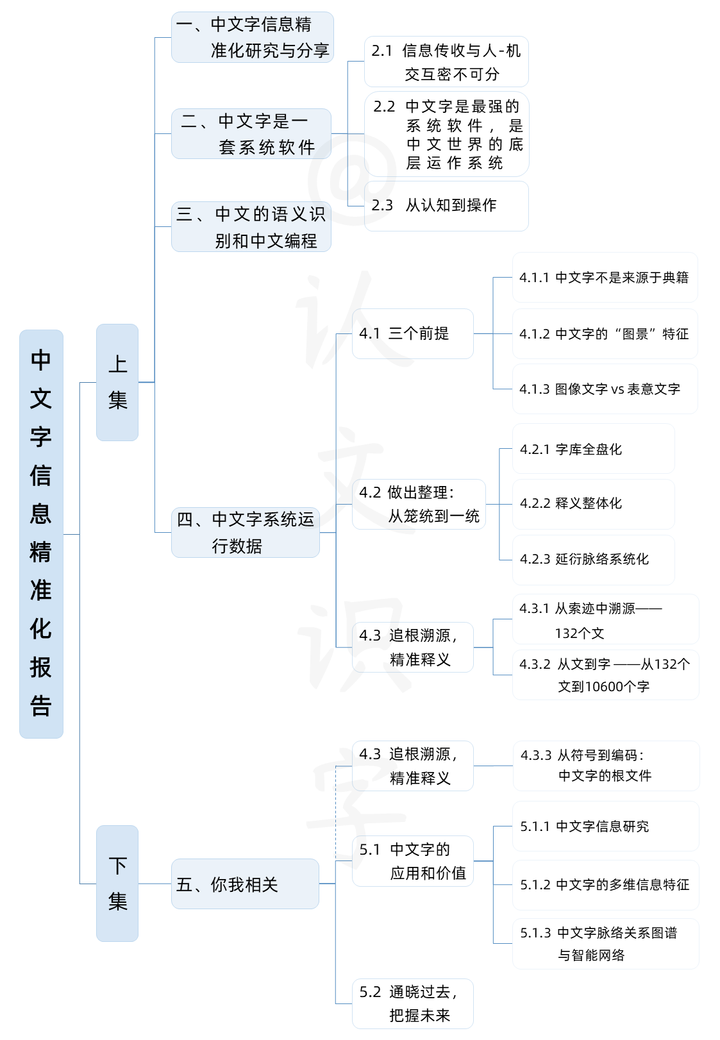
壹○中文字信息精准化研究与分享

中文字,是人类文明进程的全息存储;同时,也是人类智能的载体之一。它以多维多元的编码方式,将人脑多维智力运行过程、全息呈现。使用【认文识字】的信息数据,可以在包括人工智能领域的各行各业各领域中,做到更精准、更高效的信息交互;更进一步,还可以作为“中文编程”的基础符号,让中文自然语言的人-机对话得以实现;让包括了生命组织、和社会组织等复杂网络的系统运行,得以全息涌现。
这个报告的开篇简述是28分钟,分了上下两集,内容包括了中文字的核心概念认知、和中文字信息数据处理、以及应用方向与价值实现。前面5分钟,也许会颠覆您对中文字的认知范式;但当您看完90分钟完整的报告,必然会扩大您对它的认知版图。
好,我们先来说说,如何“颠覆中文字的认知范式”。

贰○中文字是一套系统软件
2.1 信息传收与人-机交互密不可分
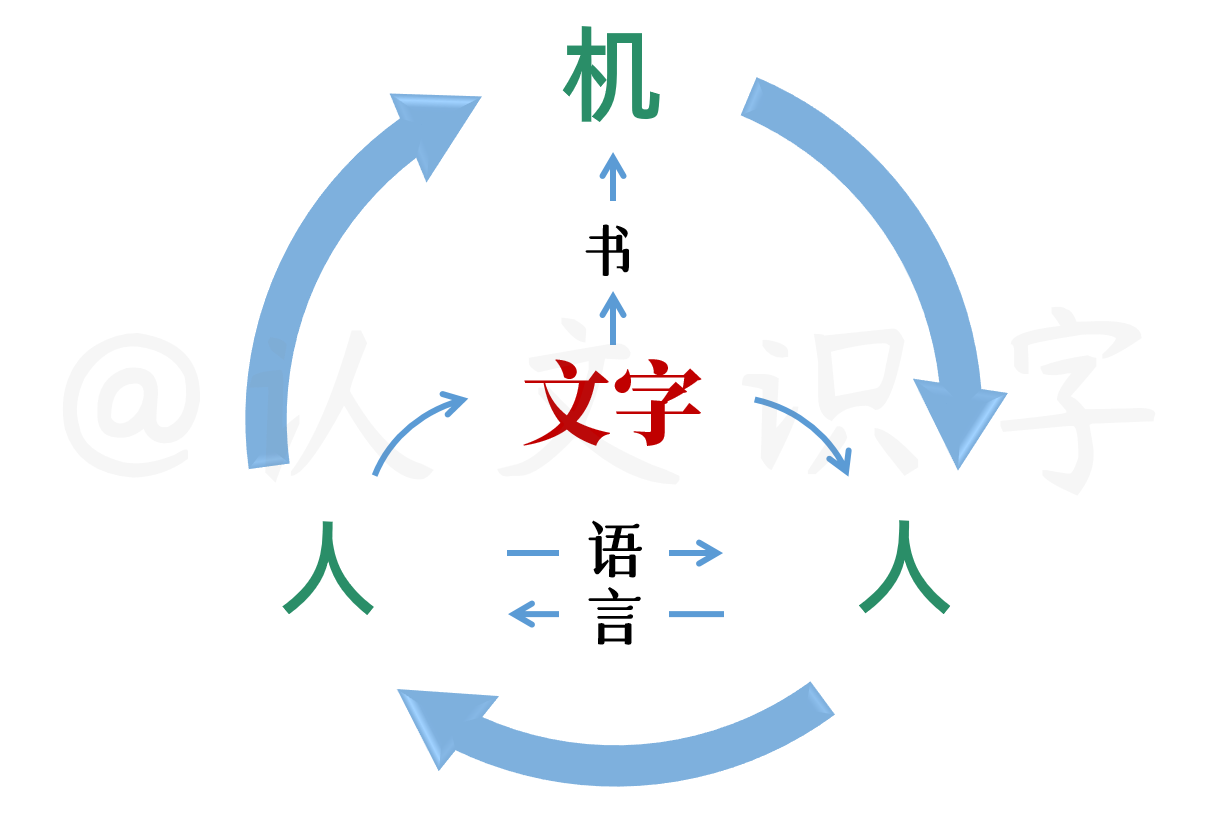
中文字,是世界文字中的一种,是人脑多维智力运行的编码之一,以此,形成出了中文自然语言的符号化呈现。
在文字没有出现之前,我们人与人之间使用语言进行面-面交流,信息传收的距离很有限;后来,信息衍化成文字和语法,用甲骨、泥板、石碑、绢帛、竹简、纸张等等的物质载体装载起来,以“书-面”形式,进行远距离信息传播。到了当下,除了人与人的直接交流、也就是人-人交流以外,我们更多是使用人-机交互,来进行更广阔的信息传收。包括你我现在的交流,表面上是声音和图像的信息传收;实际上,是以中文字承载的思想和语法逻辑做底层信息编码,给支撑运转起来的“隔空交流”。
也就是说,以中文字为信息编码运转的人-机交互,跟我们的生活已经是密不可分了。这是我们当下“人与世界”的基本运行模型。
2.2 中文字是最强的系统软件,是中文世界的底层运作系统

这个事情背后的道理是,我们现在已经处在“软件定义硬件、系统统一世界”的社会运行中了;而中文字,是世界上最强大的“系统软件”:从“软件”的属性来看,它是所有“中文应用场景”的基本单位,自动迭代、历久弥新;从“系统”的属性来看,它是中文字世界的基本盘。没有哪个软件比中文字更经得起应用考验。对,这就是中文字认知范式的颠覆:中文字不仅仅是一个个独立的象形文字;其实,它是一整套实实在在的系统软件,已经融合好了社会运行的各种协议,支撑着整个中文字世界良好运行了几千年。
2.3 从认知到操作

当有了这个认知,我们就可以从系统的角度,给中文字的底层编码做挖掘和沉淀。同时,区别于字母文字,中文字是我们人的自然语言最原始最本质的记录,是所有人、事、物最丰富最全面的信息保全。在中文字的世界里,百家有姓、万物有名,活灵活现、延衍至今,是人类思想的至重要载体、和最庞大、最真实的大数据积淀,综合反映出了我们人脑对信息进行采集、存储、封装处理和应用的一整个多维智力运行过程。所以,区别于字母文字,中文字应该有一套独立而专属的方法,对延衍使用了几千年的文字脉络做出梳理,来还原它从源出到当下的整个信息过程。

叁○中文的语义识别和中文编程

今天我发表这份报告,就是把“中文字是一套系统软件”的概念认知,具体落实到它的底层编码,从132个文到10600多个字、这个组织顺序的脉络关系上来。也就是说,将这几千年的中文字信息数据给全面打开,把它从模糊的“符号”属性,具体落实到它的编码规则、和编码过程上来;以此、提供出以132个文为锚点,衍生至现在10600个当用字、的脉络关系图谱出来。从而,以这些信息数据为基础,让中文字得以更深度地走进数字化、信息化和智能化,在人工智能领域,打破符号主义与联结主义的概念壁垒,直接实现中文语义识别;让人机对话、自然流畅;更进一步,让中文自然语言编程、得以实现,人人可以轻松参与到科技与文化的高度融合中来,发展创新、倍日并行。

肆○中文字系统运行数据
4.1 三个前提
好,我们开始报告的简述。
将已经传衍几千年的中文字做信息精准化处理,这事,是怎么做到的呢?首先,我们要放下常规的概念认知,调用我们全新的思维方式,重新梳理和认识关于中文字的三个前提。它们分别是:来源追溯、应用理解、和属性定义。我们来看看:
4.1.1 中文字不是来源于字典

第一,是来源追溯。从信息方面来看待中文字,它不是来源于史册和字典;史册和字典纪录的中文字信息不全。
中文字在被编进典籍前、被载进史册前、甚至是被刻进甲片前,它其实是一整套业已成熟的文字系统;字与字之间,具有复杂而严密的衍生关系。

包括历史中的甲骨、泥板、石碑、绢帛、竹简、纸张等等,其实都是中文字有形的物质载体之一,但并不是全部;包括《说文解字》、及继后各时期的字典,它们不是遵循中文字本身的“衍生逻辑”来做纪录的;而是以“可检索”为目标,使用“编订逻辑”对中文字的“字形”信息给做出整理、纪录下“印记信息”;既没有中文字的源出纪录,其保存的文字信息也很有限。意思是说,历史中各种有形的物质载体,只能提供出中文字的使用印记;但它们都不是中文字本身。
现在,我们使用计算机网络,用“搜索”或“推送”方式,与传统物质纸张的“检索”结果做内容匹配;用当下的“信息逻辑”、与延衍使用了近两千年的“编订逻辑”,给信息内容做匹配。这之间,就因为存在了巨大的信息差、而导致了诸多语义理解隔阂了。

中文字不仅仅是一个个独立的语言符号,其实,它是一套兼具了“秩序”和“灵活”两个特性的自运行系统。它除了被装载在各种有形的物质载体中、作“印记信息”使用以外,更多的是承载着“自然语言”的传衍,运行在我们无形的真实生活中、使用在千变万化的“语义信息”中,轮转迭代、历久弥新。
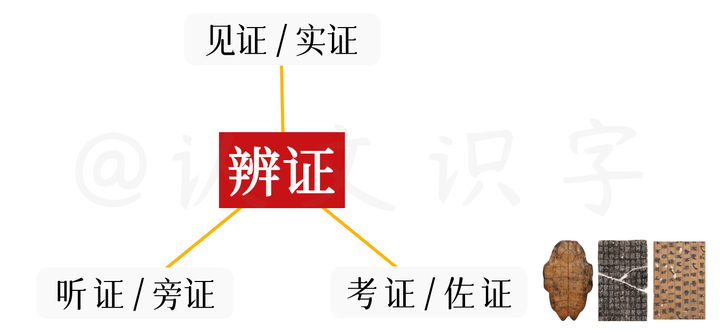
交叉验证模型
所以,当以“信息精准化”的要求去对待中文字,我们就不但要使用考证到的、过去的、静态的信息做佐证,还要使用现在见到的、听到的、正在动态使用的信息、做实证和旁证,辨证的对待中文字,才能充分打开它的语义信息。
4.1.2 中文字的“图景”特征

第二,是应用理解。中文字是使用图景信息和声音信息进行交融编码的文字,它的“字义”信息与“笔画多寡”、没有直接对应关系。

中文字是一种信息载体,它把我们主观意识里的印象、映射到客观现实中做现象描绘,再以图景和声音交融的方式做出信息表达。因为它是使用符合我们直觉认知的图景方式进行编码;我们将之内化进大脑,就能直接产生身体感知,给图像信息进行解码。即是说,我们是通过中文字的图景信息,执行内外往复的编码-解码运转、来做信息传收的,以此对其符号赋予了共同的意义。
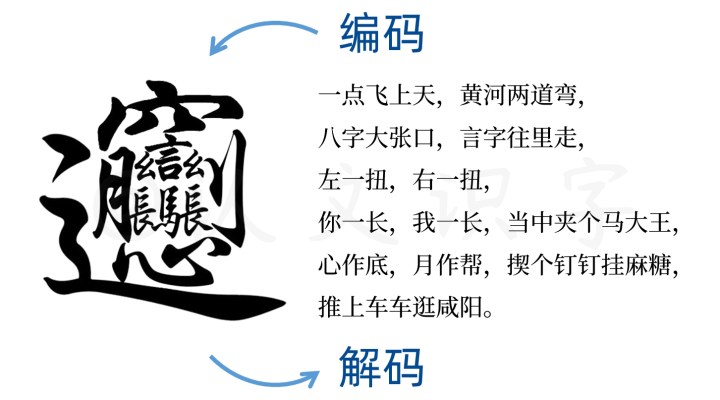
人脑对文字的编码解码能力
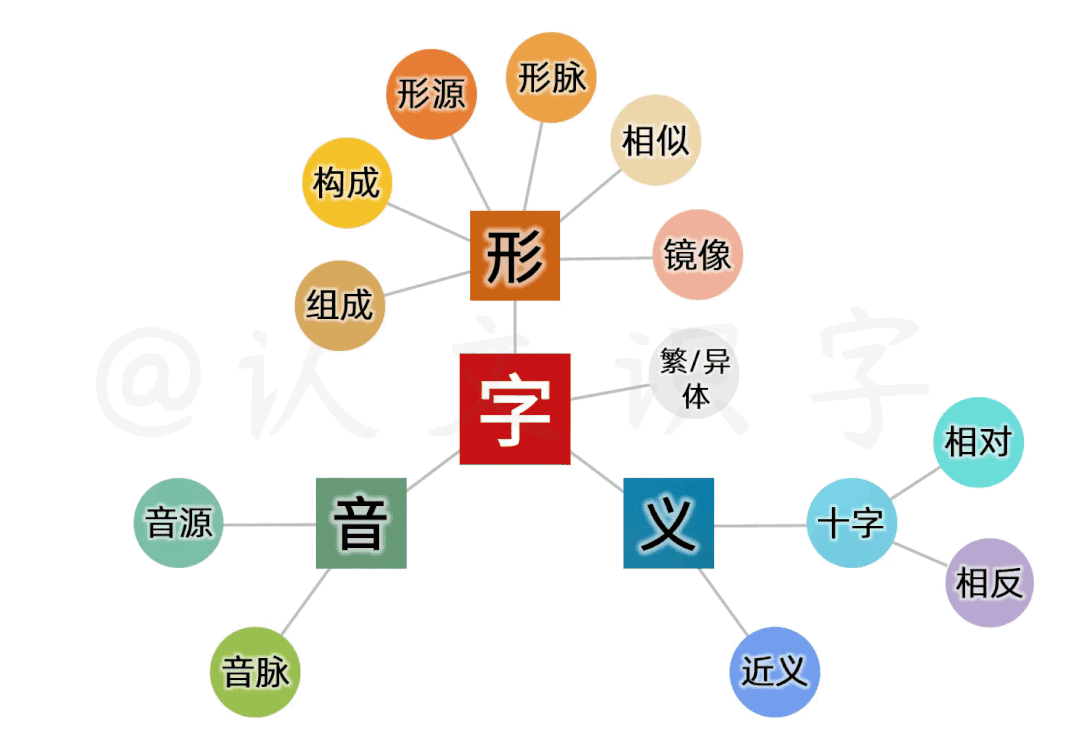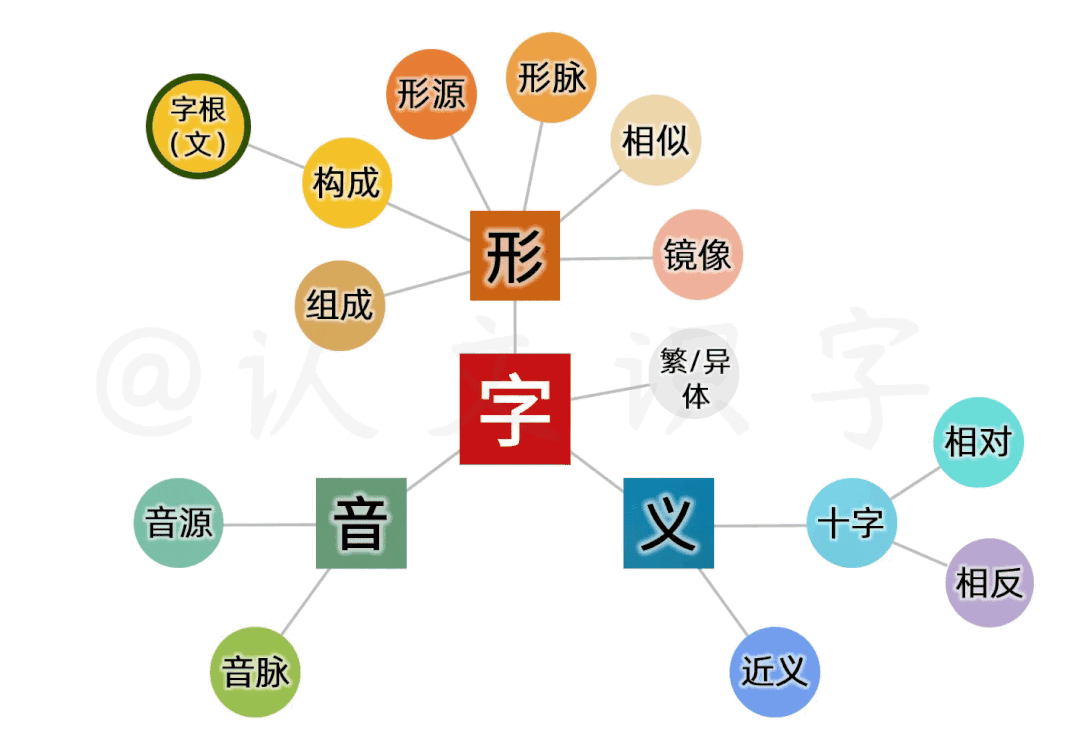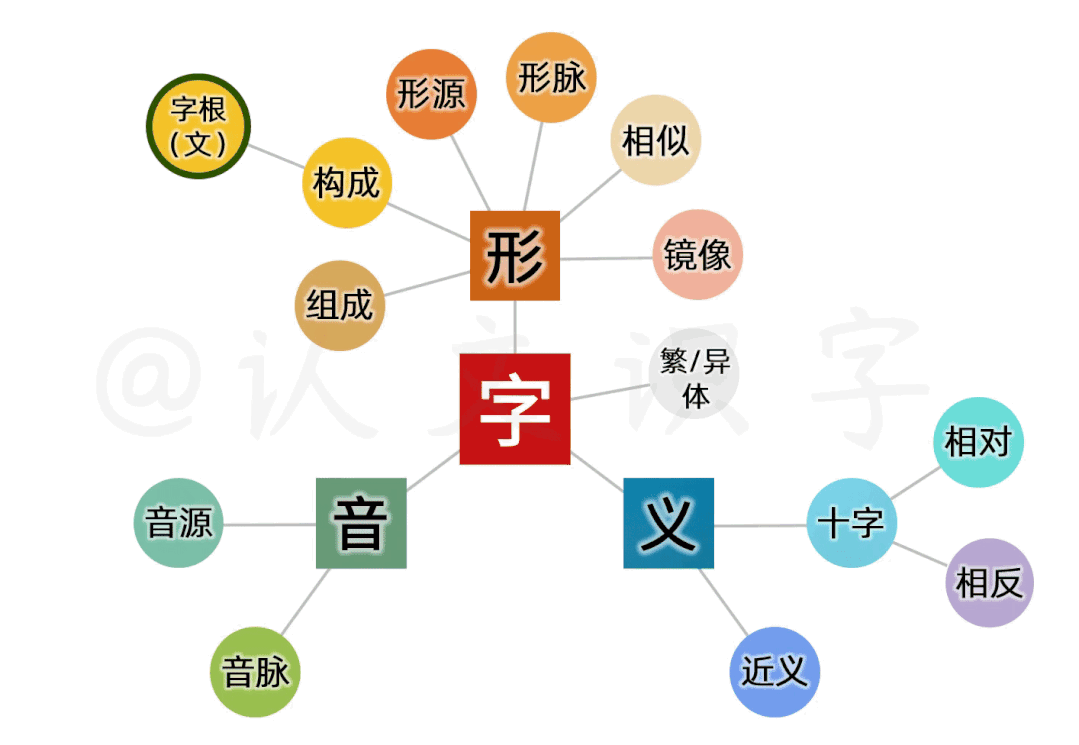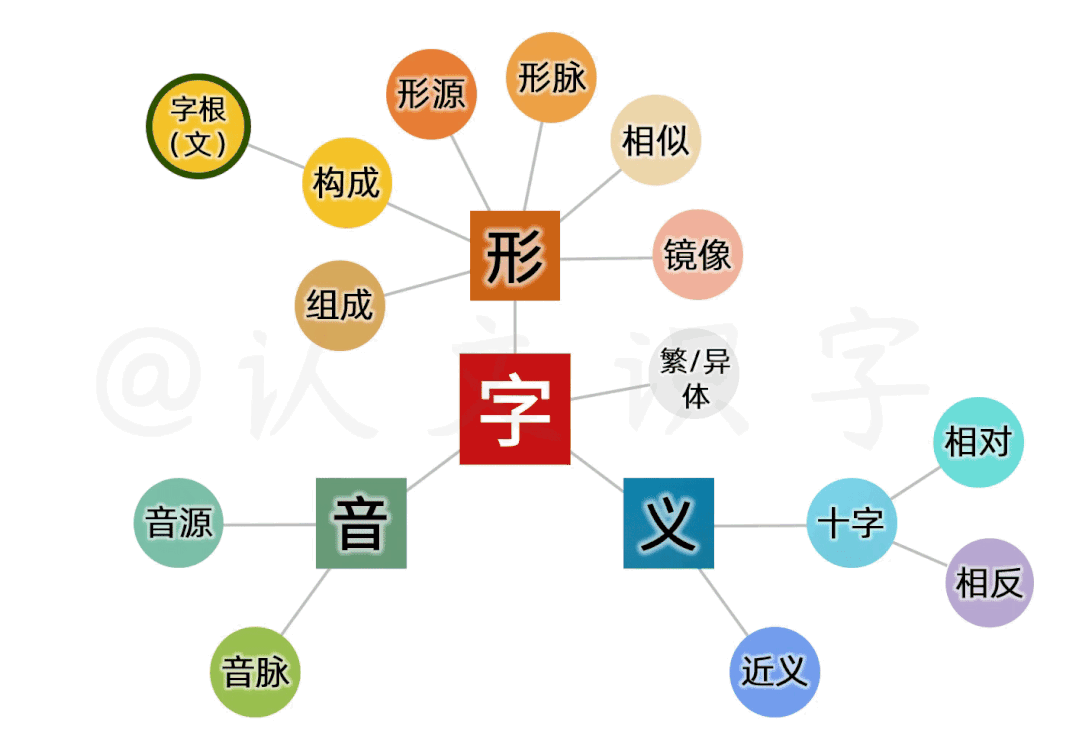
这个让大脑“快速成像”的特征,跟字母文字“线性逻辑”的特征不同,它是我们人脑多维智力运行的结果。每一个中文字,都包含了从信息采集、到纪录存储、再到封装处理和应用的一整个多维智力运行过程,整合出了包含了形、音、义三元素的全息文字系统。
相应的,它需要既站在鸟瞰的高度,在一个整体而系统的架构上去做研究;还要以全盘承托的低姿态去做容纳和梳理。这是中文字全盘、整体而系统的独有特征。所以,在应用理解上,我们要摆脱字典范式的“偏旁、部首、笔画”等“笔画多寡”的思维桎梏,而要从“图景信息”本身去理解字义。
4.1.3 图像文字v.s表意文字
第三,是属性定义。中文字是有迹可循的图像文字,而不是难以精确的表意文字。

图形,是一种自成一体的信息方式;它结合声音,生成了中文语言中最小的语义单位——语素。以此,中文字开启了“形、音”二元的语素方式做信息纪录。它是比字母文字多了一元的信息数据;相应的,就有了比字母文字多了一个维度的信息数据交互能力。所以做中文语言的语义识别,不在于语料上的多寡,而在于语素上的精准。
中文字,从远古的象形文字,到后来规范的方块字,都属于“图像文字”;再到现在的“表意文字”,这其实是一个从形象、到图像、再到抽象的认知过程。其用“图形”方式,对抽象的概念或指令进行“全息封装”,循环往复、一以贯通而延衍至今。这个“形”,是有迹可循、可被数据化的。从这个角度来c看,我们可以先放下“中文字是表意文字”的定义框锁,从“中文字是图像文字”这个事实特征出发,开展研究和整理。
4.2 做出整理:从笼统到一统
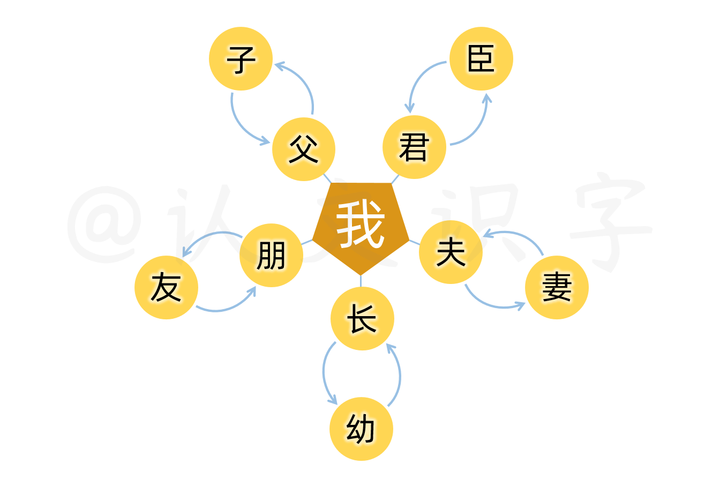
中文字是全息的,是有生命力的、活的,就像我们大活人一样,从群体到个体、从个体到器官、从器官再到组成器官的组织和细胞、直到细胞包含的基因。我们的生命,就从基因中衍生,生出了一个个全新的“我”。
探索一个个“我”的基因、来源和意义,要从身份与角色交织的“五伦”中进行交互比对和确认;
同样的,探索一个个中文字的基因、来源和字义,也要从形、音、义交织的本质特征中做相互校准。这之间,是观滴水而知沧海、牵一发而动全身的相互关系。
我建立系统,从时间和空间两个维度、分了三个层面,从最宏观的全部“中文字”、到每个文字最本质的字形、字音和字义之间,进行“交叉验证、相互校准”来处理。
4.2.1字库全盘化

第一个层面,是字库全盘化。我摒弃惯常使用的“偏旁、部首”的字典编订范式,而以形、音、义、三元素齐全的独立字为前提,采取以时间线为导向、以简体字作主字的方式,把甲骨文、金文、大篆,隶书、异体字和繁体字等等各种形态的、共20多万中文字做数据化处理,建立出全盘的数据关系。
4.2.2释义整体化
第二个层面,是释义整体化。我摒弃惯常使用的“六书”释义范式,而秉持它“形音义三元交织”的特征,使用三个步骤来处理:
第一步:建立模型

每个中文字,以形、音、义,划分属性
从空间上,按中文字的形、音、义这三个本质特征划分属性;
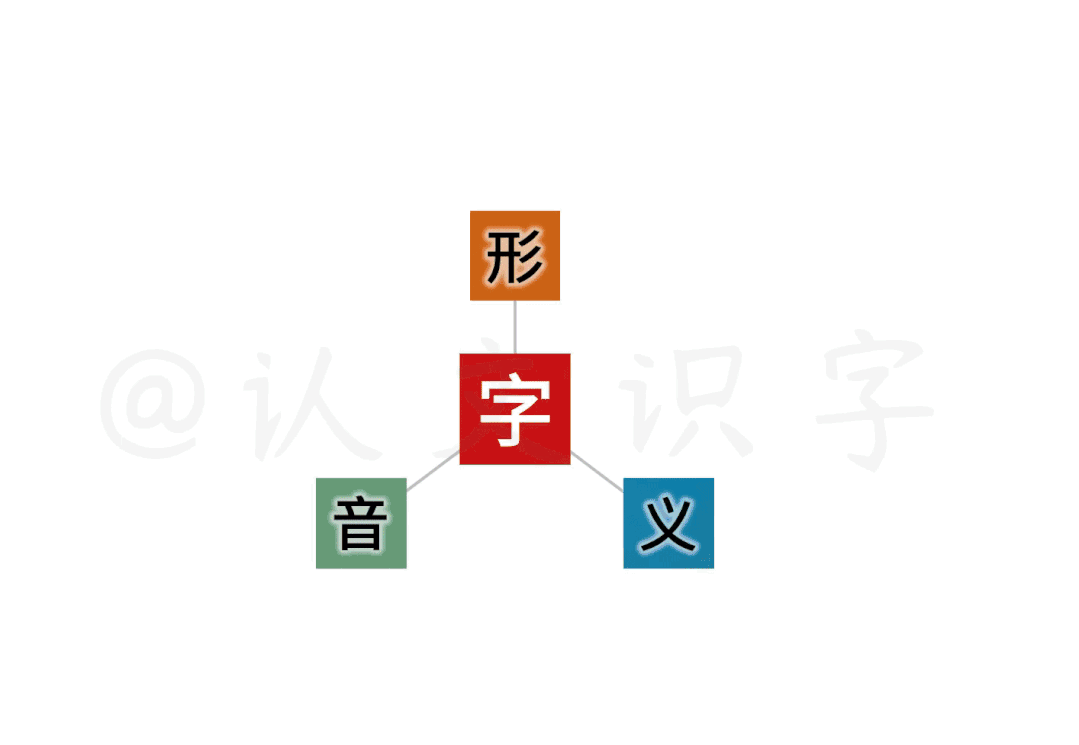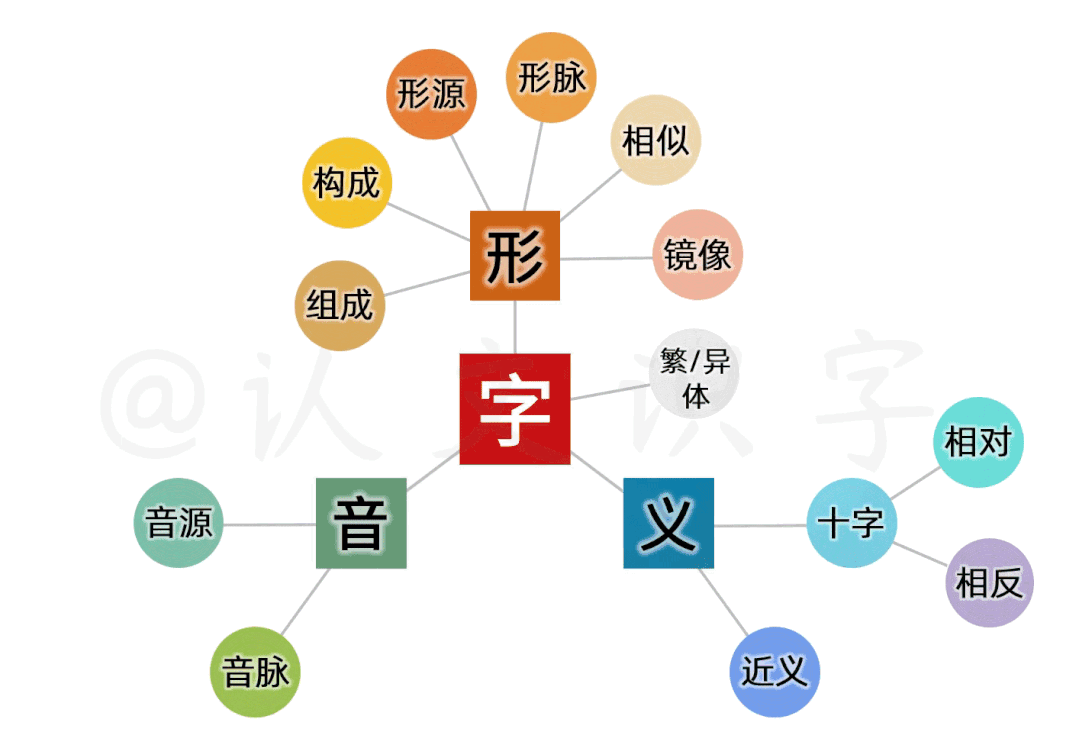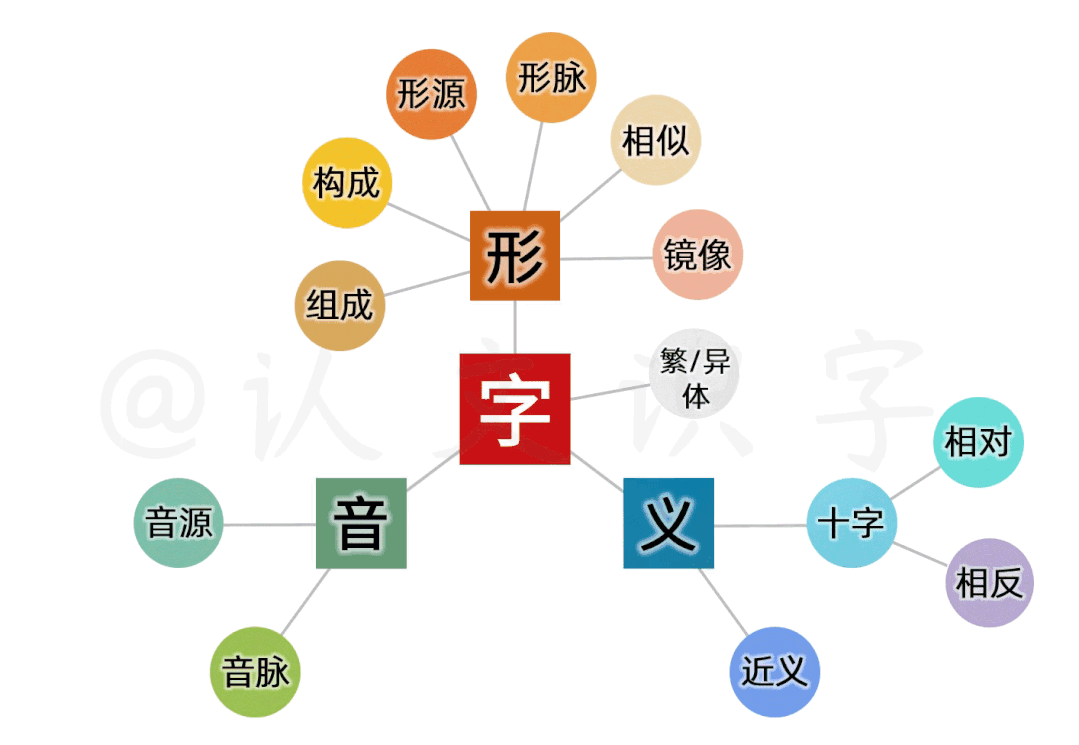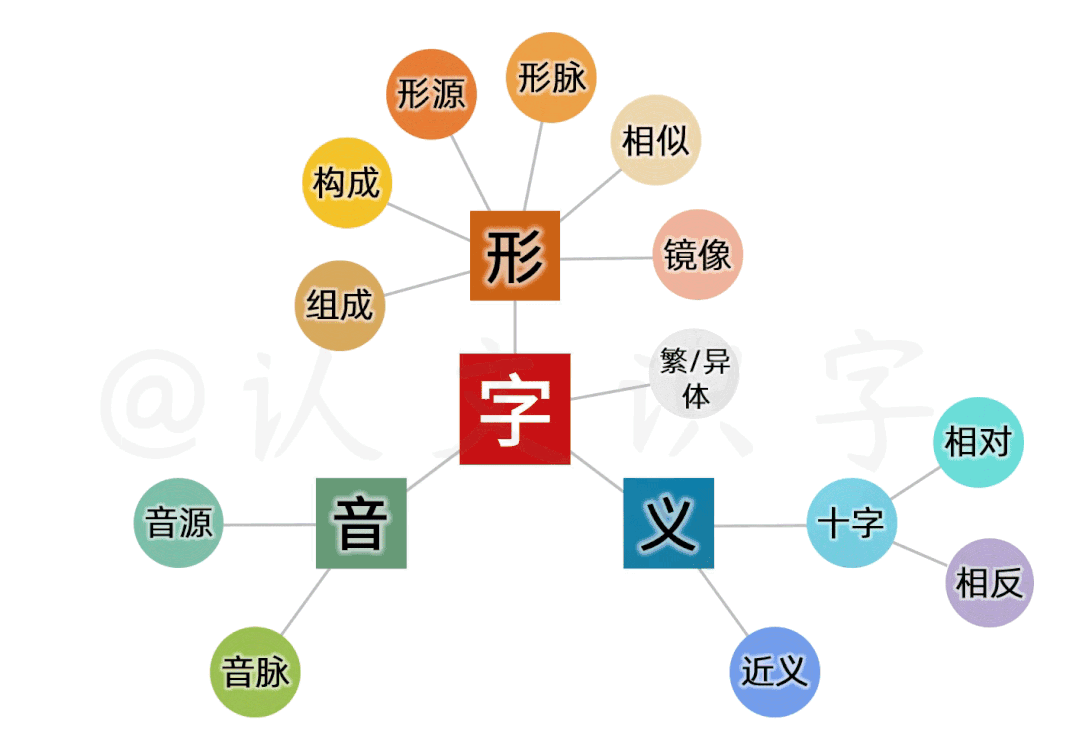
每个字,以三大项11小项,建立起属性关系模型
以此基础,又细分出11个小项,建立起一个字的属性关系模型;以此模型,来还原出这个字的形音义“生态场景”。
第二步:校准
(视频
以这个字的“属性关系”信息,进行“交叉验证、相互校准”,来核准出它的字义信息。
第三步:衍生
以此种方式,在“核准每一个字的字义信息”的过程中,形成出了字与字之间的衍生关系网络。经过这三个步骤处理,每一个中文字的语境信息,都得以在其生态场景和衍生关系中一一打开,全息呈现。这是第二个层面。
4.2.3延衍脉络系统化
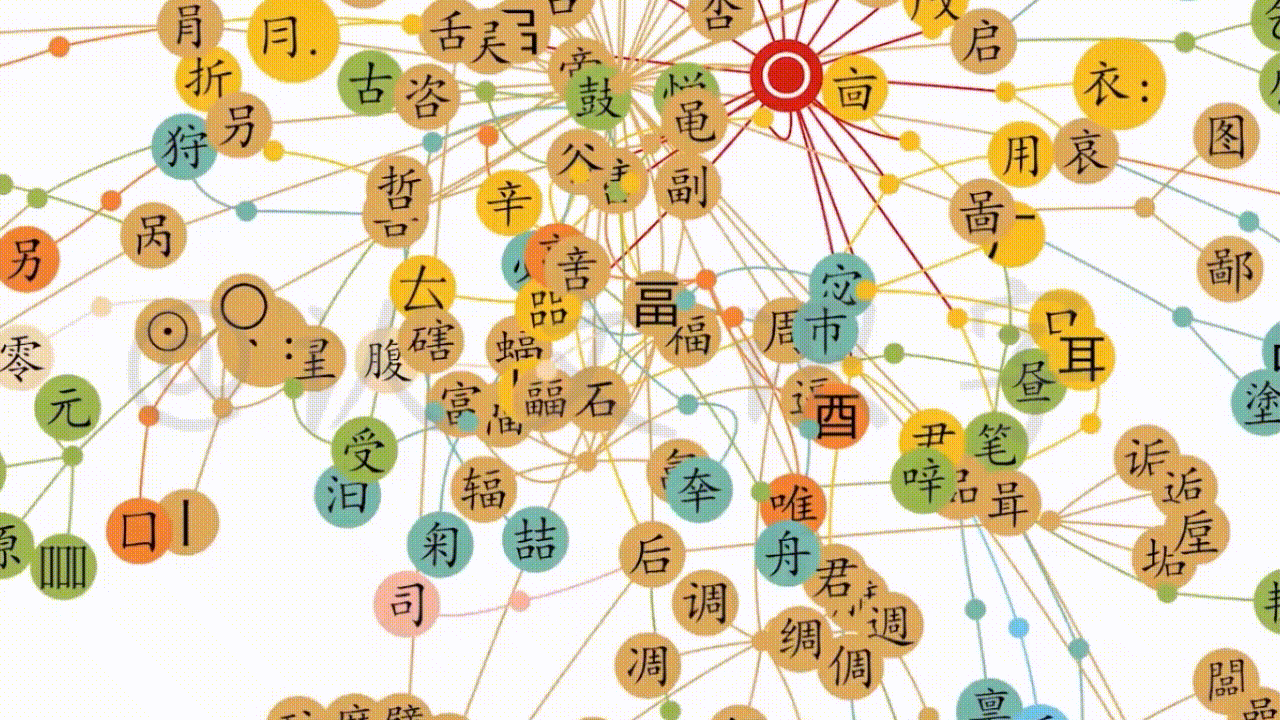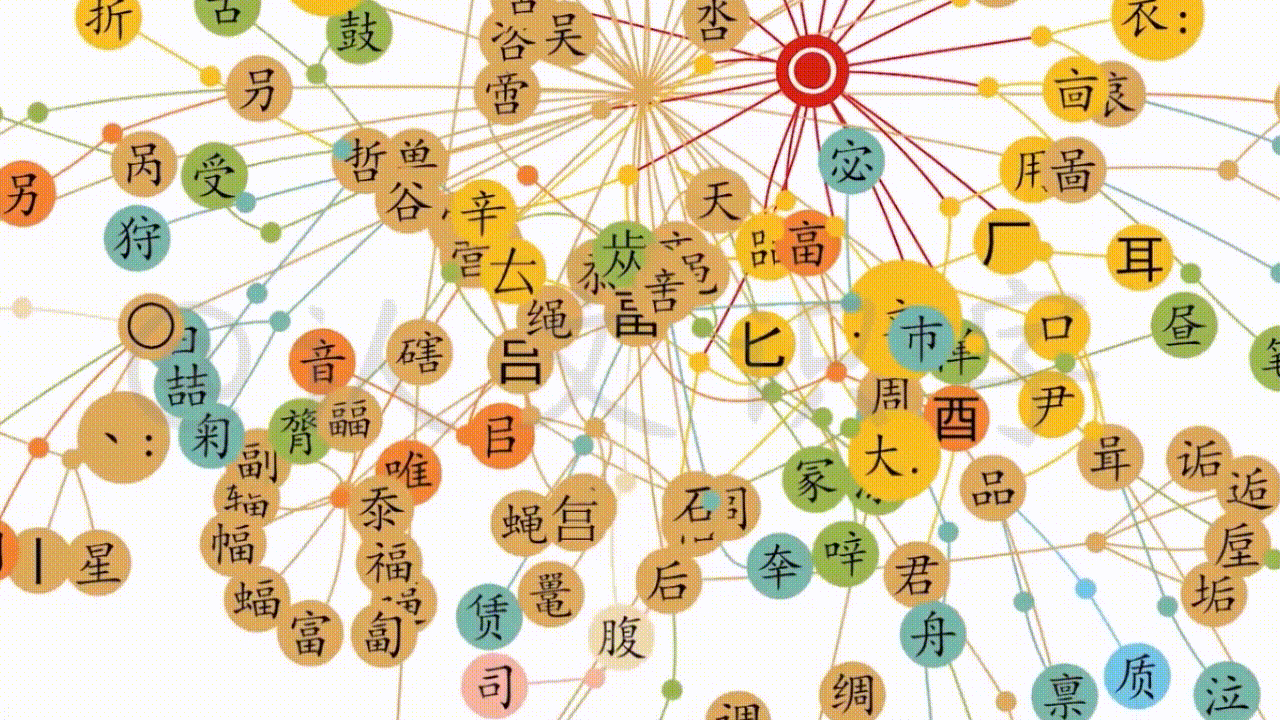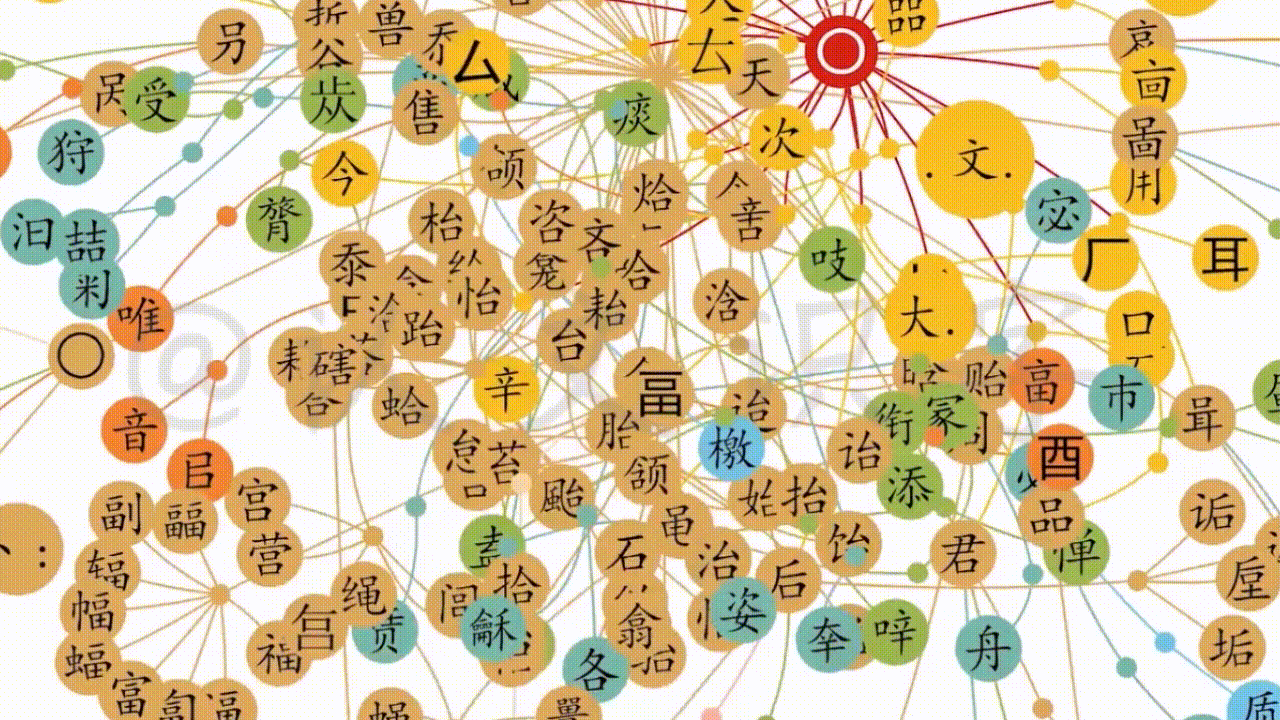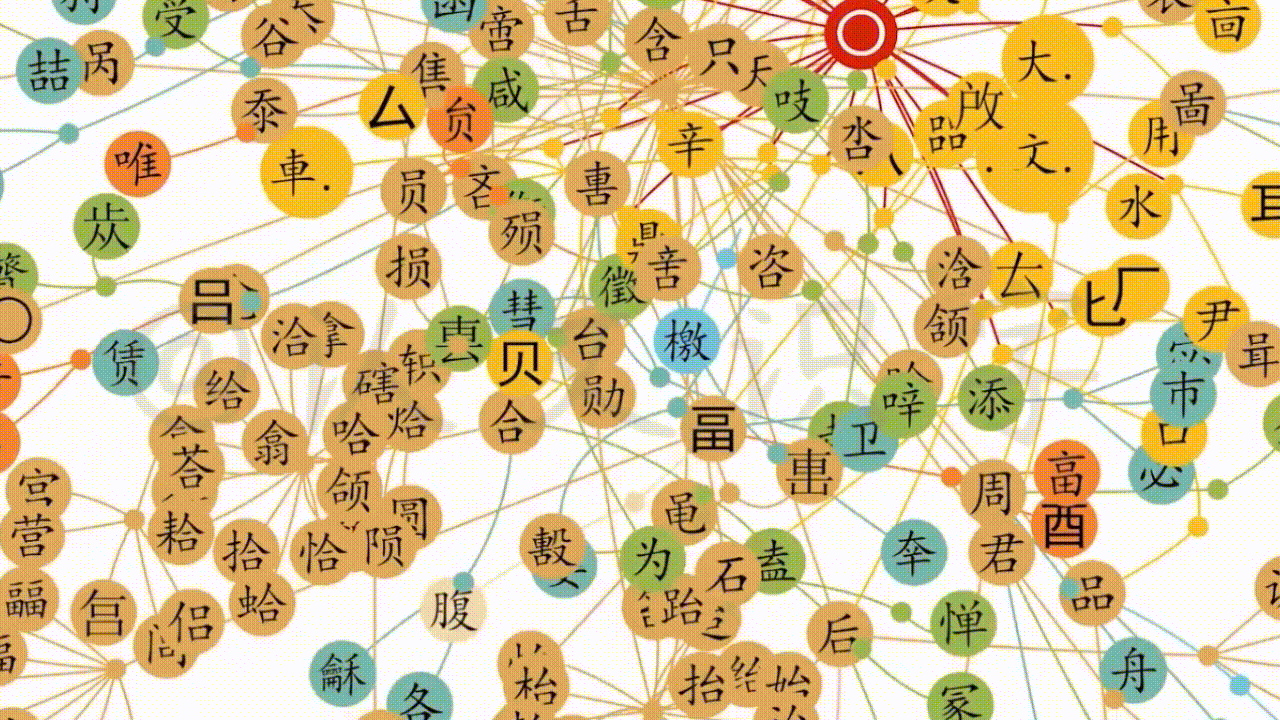
第三个层面,是延衍脉络系统化。在对以上两个层面的信息数据处理的过程中,逐渐形成出了中文字脉络关系的“大网”。以此“大网”,提供出了最大化地鸟瞰全盘数据、和最小化的信息核准。这个系统操作,就像一道大型的逻辑证明题,超越了常规字典范式,从当下使用的简体字,一直到商代的甲骨文,延衍了几千年的各种形态的中文字、和相应的形音义脉络关系信息,都全面还原、辨证呈现。
4.3 追根溯源,精准释义
4.3.1从索迹中溯源——132个文
这时,惯例之外而必然之中的事情出现了:

各种同被诠释为“跪着的人”的出土甲骨文
在做了这三个层面的数据整理后,我发现,甲骨文还不是“源出的文”,而是“合体的字”;早在商周之前,中文字已经是一整套成熟的文字系统;其字与字之间,具有复杂而严密的衍生关系。

我们素有“临池学书、画荻教子”的习惯;善书不择纸、心手不在物矣。只是,“蘸水练字、用荻草在地上书画教子”这些最原始、最质朴、最日常的做法,少有在“书面”上留下印记而已。我相信,中文字在被编进典籍前、被载进史册前、被刻进甲片前,就早已融进我们老祖宗的日常生活了。
所以,我们要将它超出典籍纪录的“衍生关系”给捋出来,才能提供出“中文字信息精准化”的证据。

于是,我遵照“独体为文、合体为字”的原理,继续使用上面“三层”方式,对甲骨文做信息比照和分解。

以此,从中沉淀出了132个具有独立“形、音、义”的文出来。这132个文的《文源表》,就像《元素周期表》一样,不是被我“发明”出来的,而是被我“发现”出来的,是通过20多万中文字的信息数据比照沉淀而来的;跟其它中文字一样,它们都有其独立的【汉字国标码】,是计算机可以识别的中文字;相应的,由这132个文,组成出了当下使用的全部中文字。这是以可校验的“索迹”方式,对中文字进行的“全程溯源”。可以超越现有的检索或搜索模式,对任何一个文和字的信息数据,进行精准、定点的索引了。
4.3.2从文到字:从132个文到10600个字
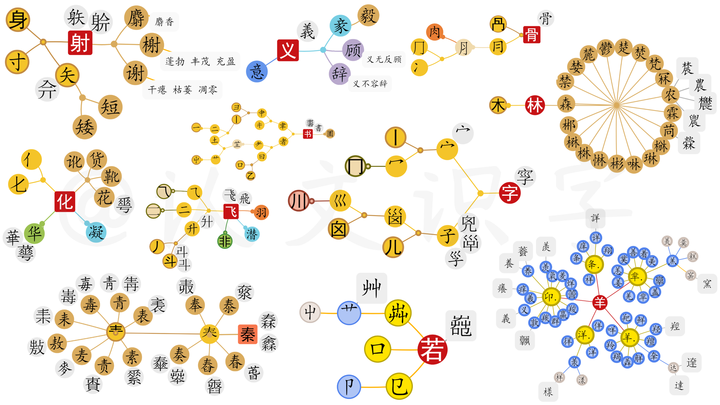
好,我们继续看。独体为文、合体为字。我遵照这个原理,以这132个源出的文为锚点,从文到字,来回校验整理全盘数据,给分别生成出了10600多幅“文和字的属性关系图”,和随之形成的“中文字延衍脉络关系”大网。这是个往复校验的过程,也是个“证伪”的过程。经过这样的“大数据多维多元信息比对”,中文字从底层的编码、到它编码-解码过程与规则等的整个衍生脉络,都得以条分缕析的展示了出来;从132个文、到10600多个字,以及与其相对应的20多万不同字体,也在其语境信息、场景信息和衍生关系信息的交互验证中,一统呈现。
这是上集。以下是思维导图,期待您继续关注下集。
本文原创首发于微信公众号。版权所有,禁止转载,欢迎转发。
@认文识字 全平台同名,本文同步更新于微博、知乎、B站、CSDN@RenWenShiZi 。
本文部分图片来源于网络,版权归原作者所有。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/126349.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
