大家好,又见面了,我是你们的朋友全栈君。
决策树(decision tree)是一种基本的分类与回归方法,本文主要讨论用于分类的决策树。决策树学习通常包括三个步骤:特征选择,决策树的生成和决策树的修剪。而随机森林则是由多个决策树所构成的一种分类器,更准确的说,随机森林是由多个弱分类器组合形成的强分类器。
说实话我也没想到这篇文章能有这么多收藏以及点赞量,因此这里重新整了一下排版,希望能更好地帮助大家!
目录
1. 信息论知识
1.1 信息熵的概念
设离散型随机变量X的取值有 x 1 , x 2 , x 3 , . . . , x n x_{1},x_{2},x_{3},…,x_{n} x1,x2,x3,...,xn,其发生概率分别为 p 1 , p 2 , p 3 , . . . , p n p_{1},p_{2},p_{3},…,p_{n} p1,p2,p3,...,pn,那么就可以定义信息熵为:


一般对数的底数是2,当然也可以换成e,当对数底数为2时,信息熵的单位为比特,信息熵也称香农熵。当对数不为2而是其他大于2的整数r时,我们称信息熵为r-进制熵,记为 H r ( X ) H_{r}(X) Hr(X),它与信息熵转换公式为:

信息熵用以描述信源的不确定度, 概率越大,可能性越大,但是信息量越小,不确定性越小,熵越小。
1.2 条件熵
设随机变量(X,Y)具有联合概率分布:

条件熵 H ( Y ∣ X ) H(Y|X) H(Y∣X)表示 在已知随机变量X的条件下随机变量Y的不确定性。可以这样理解:(X,Y)发生所包含的熵,减去X单独发生的熵,就是在X发生的前提下,Y发生新带来的熵。
所以条件熵有如下公式成立:

推导如下:
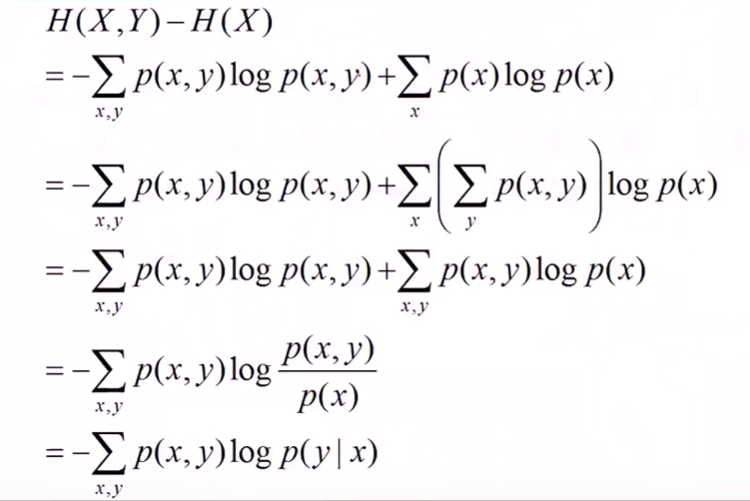
1.3 相对熵
相对熵,又称互熵,交叉熵,鉴别信息,Kullback熵,Kullback-Leible散度等。定义如下:
设p(x),q(x)是随机变量X中取值的两个概率分布,则p对q的相对熵为:

在信息理论中,相对熵等价于两个分布的信息熵(Shannon entropy)的差值。 即:

1.4 互信息
两个随机变量X和Y的互信息,定义为X,Y的联合分布和独立分布乘积的相对熵。即:

所以根据KL散度也就是相对熵的定义,可以推出互信息的表达式如下:

继续推导如下:
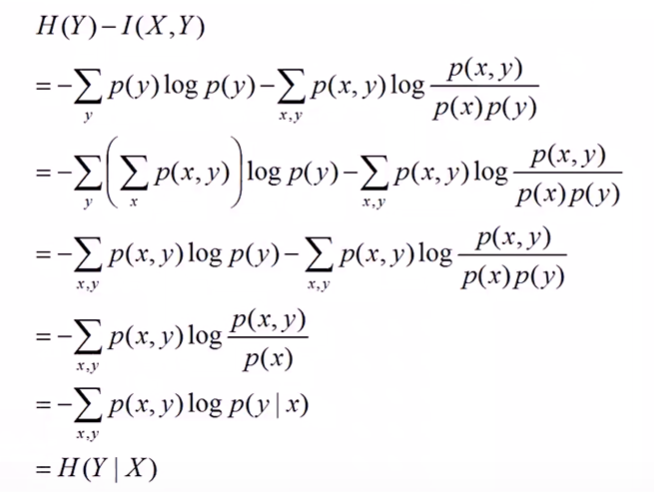
所以最后有:

1.5 几个量之间的关系
结合上述条件熵的两个表达式,可以进一步推出:
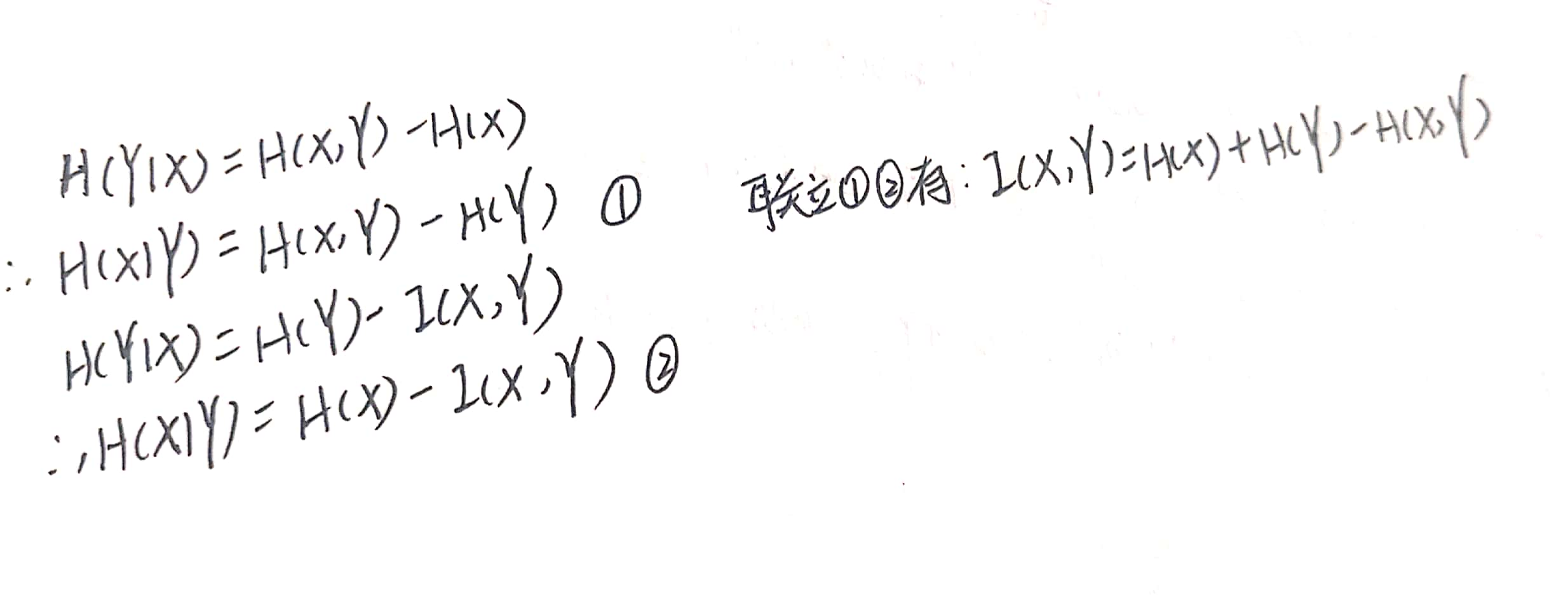
当然我们也可以根据熵的定义来直接推出上面这个互信息的公式:
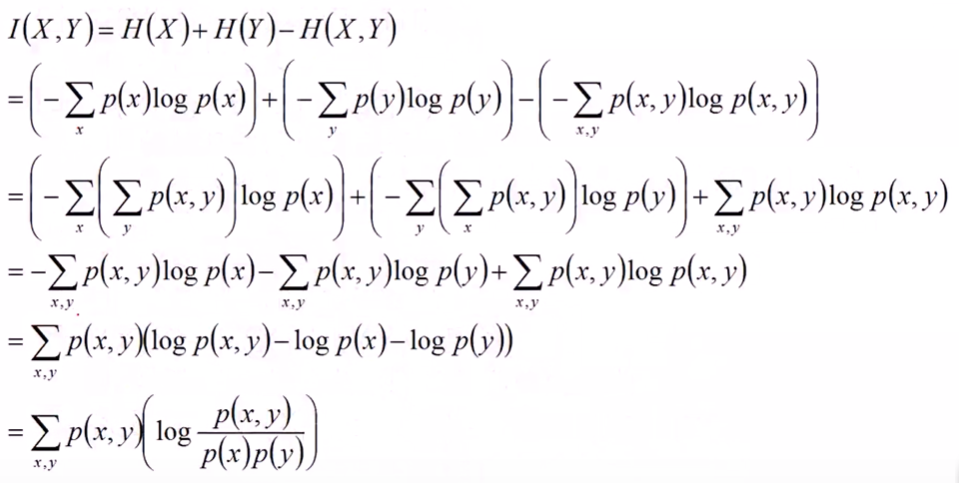
同时我们也可以得到两个不等式:

上面这个不等式告诉我们,对于一个与X相关的随机变量Y,只要我们得知了一点关于Y的信息,那么X的不确定度就会减小。
最后,借助强大的韦恩图来记住这些关系:
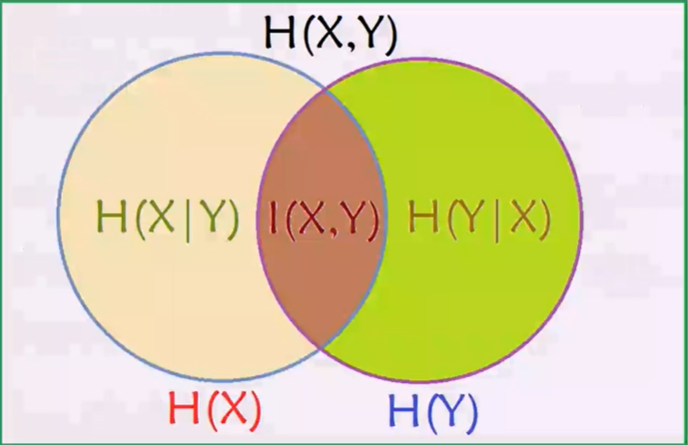
2. 决策树
2.1 引入
决策树,顾名思义,就是帮我们做出决策的树。现实生活中我们往往会遇到各种各样的抉择,把我们的决策过程整理一下,就可以发现,该过程实际上就是一个树的模型。比如相亲的时候:
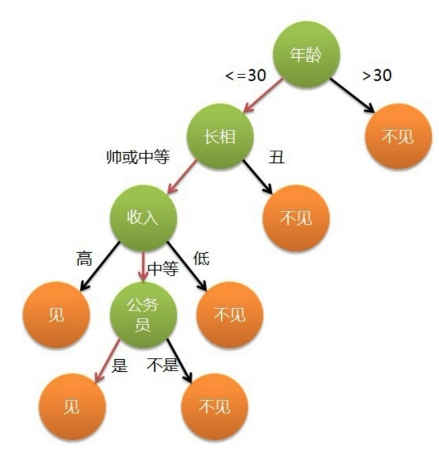
我们可以认为年龄,长相,收入是一个人的三个特征,每次我们做出抉择都是基于这三个特征来把一个节点分成好几个新的节点。
一颗完整的决策树包含以下三个部分:
- 根节点:就是树最顶端的节点,比如上面图中的“年龄”。
- 叶子节点:树最底部的那些节点,也就是决策结果,见还是不见。
- 内部节点,除了叶子结点,都是内部节点。
树中每个内部节点表示在一个属性特征上的测试,每个分支代表一个测试输出,每个叶节点表示一种类别。
给定一个决策树的实例:
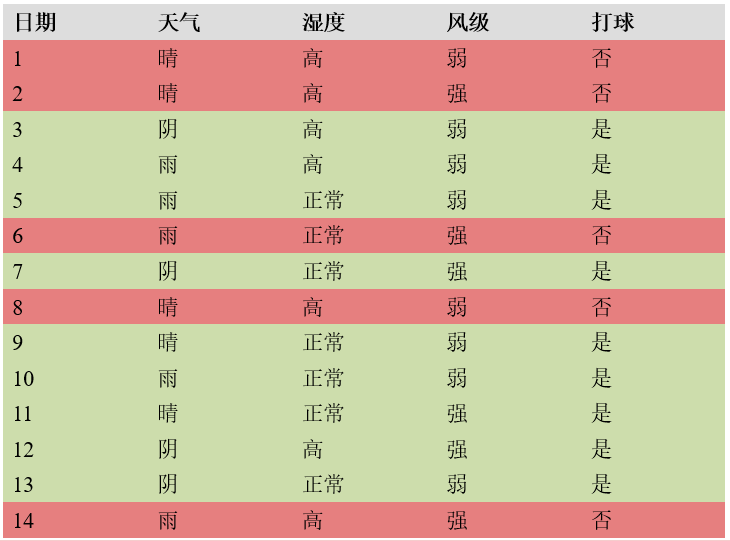
构造决策树如下:
-
第一层根节点
被分成14份,9是/5否,总体的信息熵为:
H 0 = − [ ( 5 / 14 ) l o g 5 / 14 + ( 9 / 14 ) l o g 9 / 14 ] = 0.9403 H_0= -[(5/14)log5/14+(9/14)log9/14]=0.9403 H0=−[(5/14)log5/14+(9/14)log9/14]=0.9403. -
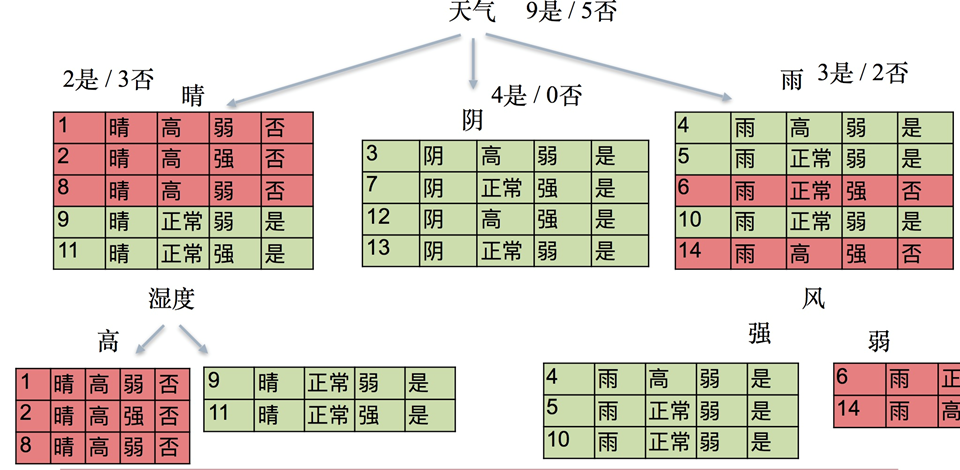
第二层
晴:被分为5份,2是/3否,它的信息熵为:
H 1 = − [ ( 2 / 5 ) l o g 2 / 5 + ( 3 / 5 ) l o g 3 / 5 ] = 0.9710 H_1=-[(2/5)log2/5+(3/5)log3/5]=0.9710 H1=−[(2/5)log2/5+(3/5)log3/5]=0.9710.
阴:被分为4份,4是/0否,它的信息熵为:
H 2 = − [ l o g 1 ] = 0 H_2= -[log1]=0 H2=−[log1]=0.
雨:被分为5份,3是/2否,它的信息熵为:
H 3 = − [ ( 2 / 5 ) l o g 2 / 5 + ( 3 / 5 ) l o g 3 / 5 ] = 0.9710 H_3=-[(2/5)log2/5+(3/5)log3/5]=0.9710 H3=−[(2/5)log2/5+(3/5)log3/5]=0.9710.
我们规定,假设我们选取天气为分类依据,把它作为根节点,那么第二层的加权信息熵可以定义为:
H ′ = 5 / 14 H 1 + 4 / 14 H 2 + 5 / 1 4 H 3 H^{‘}=5/14H_1+4/14H_2+5/14_H3 H′=5/14H1+4/14H2+5/14H3
我们规定 H ′ H^{‘} H′要比H0小,也就是随着决策的进行,其不确定度要减小才行,要不然我们还决策干什么。。。决策肯定是一个由不确定到确定状态的转变。算出 H ′ = 0.6936 < H 0 = 0.9403 H^{‘}=0.6936<H_0=0.9403 H′=0.6936<H0=0.9403,符合要求。
事实上,随着分类的进行,越来越多的信息被知道,那么总体的熵肯定是会下降的。
同样,对于晴这个节点,它的两个叶子结点的熵都是0,到了叶子结点之后,熵就变为0了,就得到了决策结果。
因此,决策树采用的是自顶向下的递归方法,其基本思想是以信息熵为度量构造一棵熵值下降最快的树,到叶子节点处的熵值为0,此时每个叶子节点中的实例都属于同一类。 至于怎么定义下降最快,下面接着讲。
2.2 决策树的生成算法
首先我们要选择一个根节点,那么选谁当做根节点呢?比如上面的例子,有天气,湿度以及风级三个属性,所以我们要在三个当中选择一个。三个属性 f 1 , f 2 , f 3 f_1,f_2,f_3 f1,f2,f3,以三个属性分别为根节点可以生成三棵树(从第一层到第二才层),而究竟选择谁来当根节点的准则,有以下三种。
2.2.1 信息增益与ID3
决策树中信息增益定义如下:
给定一个样本集D,划分前样本集合D的熵是一定的 ,用 H 0 H_0 H0表示; 使用某个特征A划分数据集D,计算划分后的数据子集的熵,用 H 1 H_1 H1表示,则:
信息增益可以表示为 H 0 − H 1 H_0-H_1 H0−H1,也可以表示为:

比如上面实例中我选择天气作为根节点,将根节点一分为三,设 f 1 f_1 f1表示天气,则有:
g ( D , f 1 ) = H 0 − H ′ = 0.9403 − 0.6936 = 0.2467 g(D,f_1)=H_0-H^{‘}=0.9403-0.6936=0.2467 g(D,f1)=H0−H′=0.9403−0.6936=0.2467
意思是,没有选择特征 f 1 f_1 f1前,是否去打球的信息熵为0.9403,在我选择了天气这一特征之后,信息熵下降为0.6936,信息熵下降了0.2467,也就是信息增益为0.2467.
信息增益的局限:信息增益偏向取值较多的特征。
原因:当特征的取值较多时,根据此特征划分更容易得到纯度更高的子集,因此划分之后的熵更低,由于划分前的熵是一定的,因此信息增益更大,因此信息增益比较偏向取值较多的特征。
比如说有一个特征可以把训练集的每一个样本都当成一个分支,也就说有n个样本,该特征就把树分成了n叉树,那么划分后的熵变为0,此时信息增益当然是下降最大的。 也就是说,如果我们在生成决策树的时候以信息增益作为判断准则,那么分类较多的特征会被优先选择。
利用信息增益作为选择指标来生成决策树的算法称为ID3算法。
2.2.2 信息增益率与C4.5
为了解决信息增益的局限,引入了信息增益率的概念。分支过多容易导致过拟合,造成不理想的后果。假设原来的熵为0.9,选择 f 1 f_1 f1特征划分后整体熵变成了0.1,也就是信息增益为0.8,而选择 f 2 f_2 f2划分后,熵变为0.3,也就是信息增益为0.6。我们不想选择 f 1 f_1 f1,因为它让决策树分支太多了,那么就可以定义如下决策指标:

g r ( D , A ) g_r(D,A) gr(D,A)就是信息增益率,信息增益率=信息增益/特征本身的熵。 f 1 f_1 f1划分后分支更多,也就是特征 f 1 f_1 f1本身的熵比 f 2 f_2 f2更大,大的数除以一个大的数,刚好可以中和一下。
还是以这张图为例子算一下:
现在我们要利用信息增益率来决定谁做根节点。
未划分前我们有: H 0 = 0.9403 H_0= 0.9403 H0=0.9403.
现在选择天气作为根节点,则有:
- 晴:被分为5份,2是/3否,它的信息熵为:
H 1 = 0.9710 H_1=0.9710 H1=0.9710. - 阴:被分为4份,4是/0否,它的信息熵为:
H 2 = − [ l o g 1 ] = 0 H_2= -[log1]=0 H2=−[log1]=0. - 雨:被分为5份,3是/2否,它的信息熵为:
H 3 = 0.9710 H_3=0.9710 H3=0.9710.
划分后总体的信息熵为:
H ′ = 5 / 14 H 1 + 4 / 14 H 2 + 5 / 14 H 3 = 0.6936 H^{‘}=5/14H1+4/14H2+5/14H3=0.6936 H′=5/14H1+4/14H2+5/14H3=0.6936
一定要注意,这个算的是总体的信息熵, 那么信息增益为:
g ( D , f 1 ) = H 0 − H ′ = 0.2467 g(D, f_1)=H_0-H^{‘}=0.2467 g(D,f1)=H0−H′=0.2467
这个时候我们考虑天气本身的熵,这里算的是天气本身的熵,而不是样本X,也就是是否外出打球的熵,这里一定要将二者区分开。天气本身有三种可能,每种概率都已知,则天气的熵为:
H ( f 1 ) = − [ ( 5 / 14 ) l o g 5 / 14 + ( 4 / 14 ) l o g 4 / 14 + ( 5 / 14 ) l o g 5 / 14 ] = 1.5774 H(f_1)= -[(5/14)log5/14+(4/14)log4/14+(5/14)log5/14]=1.5774 H(f1)=−[(5/14)log5/14+(4/14)log4/14+(5/14)log5/14]=1.5774
那么选择天气作为分类依据时,信息增益率为:
g r ( D , f 1 ) = g ( D , f 1 ) / H ( f 1 ) = 0.2467 / 1.5774 = 0.1566 g_r(D, f_1)=g(D, f_1)/H(f_1)=0.2467/1.5774=0.1566 gr(D,f1)=g(D,f1)/H(f1)=0.2467/1.5774=0.1566
这里还是想要强调一下,很多人在算信息增益率的时候总是出错,是因为搞混了总体的熵与特征的熵!!! 我在算信息增益的时候,两个相减的熵都是算的总体的熵,也就是依据是否外出来划分的,而我计算特征本身的熵的时候,是依据这个特征本身来算的,比我算天气的熵,那么就看天气分为了哪几类,比如晴天,阴天,雨天之类的,每一类又有自己的概率,然后再根据信息熵的定义来计算,二者相除即是信息增益率。
利用信息增益率作为选择指标来生成决策树的算法称为C4.5算法。
2.2.3 Gini系数与CART
定义:基尼指数(基尼不纯度):表示在样本集合中一个随机选中的样本被分错的概率。
定义如下:
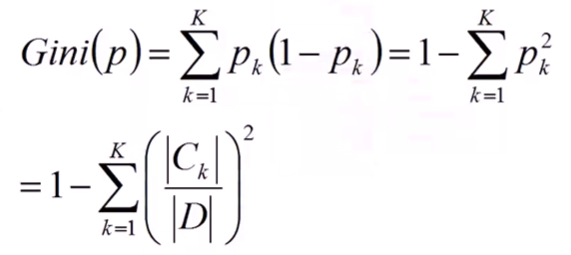
一些参数的说明:
- pk表示选中的样本属于k类别的概率,则这个样本被分错的概率是(1-pk)。
- 样本集合中有K个类别,一个随机选中的样本可以属于这k个类别中的任意一个。
- 易知,当样本属于每一个类别的概率都相等即均为1/K时,基尼系数最大,也就是说此时不确定度最小。
关于基尼系数的理解,网上有一种说法比较通俗易懂。现解释如下:
我们知道信息熵的定义式为:

那么基尼系数实际上就是用 1 − p i 1-p_{i} 1−pi来代替了 − l o g ( p i ) -log(p_{i}) −log(pi),画出二者图像:
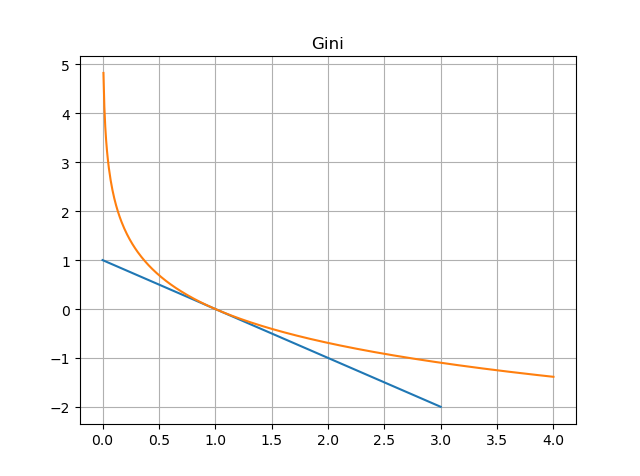
因为概率是属于0到1之间,所以我们只看01区间上的图像:基尼系数对于信息熵而言,就是在01区间内近似的用切线来代替了对数函数。因此,既然信息熵可以表述不确定度,那么基尼系数自然也可以,只不过存在一些误差。
CART决策树又称分类回归树,当数据集的因变量为连续性数值时,该树算法就是一个回归树,可以用叶节点观察的均值作为预测值;当数据集的因变量为离散型数值时,该树算法就是一个分类树,可以很好的解决分类问题。
当CART是分类树时,采用GINI值作为结点分裂的依据;当CART是回归树时,采用MSE(均方误差)作为结点分裂的依据。我们这里只讨论分类。
2.3 决策树的评价
假定样本总类别为K,而对于决策树的某叶节点,假定该叶子节点包含的样本数目为n,其中第k类的样本数目为 n k n_{k} nk,k=1,2,…,K。
若某类样本的 n j n_{j} nj=n,其他类别个数全为0,也就是说该叶结点中所有样本完全属于同一个类,则称该结点为纯结点,其熵为0.
若某一叶子结点中包含了所有类别的样本且各类数目相同,则称该结点为均结点。 其熵为 l o g K logK logK。
那么我们对所有叶子结点的熵求和,该值越小说明越精确。 而又由于各个叶子结点包含的样本数目不同,所以我们采用加权熵和。
评价函数定义如下:

其中 N t N_{t} Nt表示叶子结点的样本数目,评价函数越小说明决策树越好。
2.4 决策树的过拟合
当决策树深度过大时,在训练集上表现特别好,往往就会出现过拟合现象,我们需要一些解决办法:
2.4.1 剪枝
剪枝总体思路:由完全树T0开始,剪枝部分结点得到树T1,然后再剪枝部分结点得到树T2,…,直到仅剩树根的Tk。在验证数据集上对这K个树分别评价,选择损失函数最小的树 T α T_{α} Tα。
三种决策树的生成算法过程相同,只是对于当前树的评价标准不同。
3. 随机森林
随机森林也是为了解决决策树的过拟合问题。
3.1 Bootstrap
假设有一个大小为N的样本,我们希望从中得到m个大小为N的样本用来训练。bootstrap的思想是:首先,在N个样本里随机抽出一个样本x1,然后记下来,放回去,再抽出一个x2,… ,这样重复N次,即可得到N个新样本,这个新样本里可能有重复的。重复m次,就得到了m个这样的样本。实际上就是一个有放回的随机抽样问题。每一个样本在每一次抽的时候有同样的概率(1/N)被抽中。
3.2 bagging策略
bagging的名称来源于: Bootstrap Aggregating,意为自助抽样集成。既然出现了Bootstrap那么肯定就会使用到Bootstrap方法,其基本策略是:
- 利用Bootstrap得到m个样本大小为N的样本集。
- 在所有属性上,对每一个样本集建立分类器。
- 将数据放在这m个分类器上,最后根据m个分类器的投票结果,决定数据最终属于哪一类。如果是回归问题,就采用均值。
什么时候用bagging?当模型过于复杂容易产生过拟合时,才使用bagging,决策树就容易产生过拟合。
3.3 out of bag estimate(包外估计)
在使用bootstrap来生成样本集时,由于我们是有放回抽样,那么可能有些样本会被抽到多次,而有的样本一次也抽不到。我们来做个计算:假设有N个样本,每个样本被抽中的概率都是1/N,没被选中的概率就是1-1/N,重复N次都没被选中的概率就是 ( 1 − 1 / N ) N (1-1/N)^N (1−1/N)N,当N趋于无穷时,这个概率就是1/e,大概为36.8%。也就是说样本足够多的时候,一个样本没被选上的概率有36.8%,那么这些没被选中的数据可以留作验证集。每一次利用Bootstrap生成样本集时,其验证集都是不同的。
以这些没被选中的样本作为验证集的方法称为包外估计。
3.4 样本随机与特征随机
在我们使用Bootstrap生成m个样本集时,每一个样本集的样本数目不一定要等于原始样本集的样本数目,比如我们可以生成一个含有0.75N个样本的样本集,此处0.75就称为采样率。
同样,我们在利用0.75N个样本生成决策树时,假设我们采用ID3算法,生成结点时以信息增益作为判断依据。我们的具体做法是把每一个特征都拿来试一试,最终信息增益最大的特征就是我们要选的特征。但是,我们在选择特征的过程中,也可以只选择一部分特征,比如20个里面我只选择16个特征。
那可能有的人就要问了,假设你没选的4个特征里面刚好有一个是最好的呢?这种情况是完全可能出现的,但是我们在下一次的分叉过程中,该特征是有可能被重新捡回来的,另外别的决策树当中也可能会出现那些在另一颗决策树中没有用到的特征。
随机森林的定义就出来了,利用bagging策略生成一群决策树的过程中,如果我们又满足了样本随机和特征随机,那么构建好的这一批决策树,我们就称为随机森林(Random Forest)。
实际上,我们也可以使用SVM,逻辑回归等作为分类器,这些分类器组成的总分类器,我们习惯上依旧称为随机森林。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/126315.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
