大家好,又见面了,我是你们的朋友全栈君。
作为一只超级硬核的兔子,从来不给你说废话,只有最有用的干货!这些神级算法送给你
![超硬核!小白读了这篇文章,就能在算法圈混了[通俗易懂]](https://img-blog.csdnimg.cn/20210329102221438.png)
![超硬核!小白读了这篇文章,就能在算法圈混了[通俗易懂]](http://javaforall.cn/wp-content/themes/justnews/themer/assets/images/lazy.png)
目录
第一节
1.1bogo排序
Bogo排序(Bogo-sort),又被称为猴子排序,是一种恶搞排序算法。
将元素随机打乱,然后检查其是否符合排列顺序,若否,则继续进行随机打乱,继续检查结果,直到符合排列顺序。
Bogo排序的最坏时间复杂度为O(∞),一辈子也不能输出排序结果,平均时间复杂度为O(n·n!)。
这让我想到了另一个理论:猴子理论,只要让一只猴子一直敲打计算机,理论上会有一天,它能敲出一本圣经出来,但是这个概率小到宇宙毁灭也很难敲出来。。
真的不知道这个排序应该叫做天才还是垃圾哈哈哈,但是闲的没事的我就把他实现出来了。
public class Main {
public static void main(String[] args) {
int[] arr = { 9,8,7,6,5,4,3,2,1};
System.out.println("排序次数" + bogo(arr));
for (int i : arr) {
System.out.print(i + " ");
}
}
public static int bogo(int[] arr) {
int count = 0;
while (!isOrdered(arr)) {
shuffle(arr);
count++;
}
return count;
}
// 判断是否有序方法
public static boolean isOrdered(int[] arr) {
for (int i = 1; i < arr.length; i++) {
if (arr[i - 1] > arr[i]) {
return false;
}
}
return true;
}
// 随机排序方法
public static void shuffle(int[] arr) {
int temp;
for (int i = 0; i < arr.length; i++) {
int j = (int) (Math.random() * arr.length);
temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
}
}
9是中国最大的数字嘛,我就把数组长度设为9,结果平均排序次数要60万次,不知道我的运气怎么样哈哈,你们也试试吧?
然而,有个看似笑话的方法声称可以用O(n)实现Bogo排序,依照量子理论的平行宇宙解释,使用量子随机性随机地重新排列元素,不同的可能性将在不同的宇宙中展开,总有一种可能猴子得到了正确的顺序,量子计算机找到了这个宇宙后,就开始毁灭其他排序不成功的宇宙,剩下一个观察者可以看到的正确顺序的宇宙。
如果想要迈出这个看似荒诞,但令人无比兴奋的”高效算法”的第一步,请先证明”平行宇宙解释”的正确性。
1.2位运算
关于位运算有很多天秀的技巧,这里举一个例子。
给定一个非空整数数组,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。
说明:你的算法应该具有线性时间复杂度。 你可以不使用额外空间来实现吗?
示例 1:
输入: [2,2,1]输出: 1
示例 2:
输入: [4,1,2,1,2]输出: 4
思路:拿map,set,都不符合要求,那怎么办呢?
我们知道什么数字和自己异或,都等于0.
什么数字和0异或,都等于它本身,
异或又符合交换律
所以全部异或一遍,答案就是那个出现一次的数字。
class Solution {
public int singleNumber(int[] nums) {
int ans = 0;
for(int i :nums)ans ^= i;
return ans;
}
}有没有被秒了?
1.3打擂台
给定一个大小为 n 的数组,找到其中的多数元素。多数元素是指在数组中出现次数大于 ⌊ n/2 ⌋ 的元素。
你可以假设数组是非空的,并且给定的数组总是存在多数元素。
把狂野般的思绪收一收,咱们来看看最优解。
class Solution {
public int majorityElement(int[] nums) {
int count = 0;//当前答案出现的次数
Integer candidate = null;//答案
for (int num : nums) {
if (count == 0) candidate = num;
count += (num == candidate) ? 1 : -1;
}
return candidate;
}
}我来解释一下策略:记录当前的答案candidate ,记录count。这时,我们遍历了一个新的数字,如果和candidate 一样,我们就让count+1,否则让count-1.如果count变成了0,那candidate 就下擂台,换新的擂主(数字)上,也就是说把candidate 更新成新的数字,count也更新成1.
最后在擂台上的一定是答案。
肯定有人怀疑这个做法的正确性吧?我就来说一下它为啥对?
首先,我们想像一下对最终隐藏答案ans最不利的情况:每个其他数字全部都打擂这个答案ans,那ans的count最后也会剩1,不会被打下来。
正常情况呢?其他数字还会互相打擂,这些数字如此“内耗”,又怎么能斗得过最终答案ans呢?对不对?
1.4morris遍历
通常,实现二叉树的前序(preorder)、中序(inorder)、后序(postorder)遍历有两个常用的方法:一是递归(recursive),二是使用栈实现的迭代版本(stack+iterative)。这两种方法都是O(n)的空间复杂度(递归本身占用stack空间或者用户自定义的stack),我分别给出一个例子
递归:
void PreorderTraversal( BinTree BT )
{
if(BT==NULL)return ;
printf(" %c", BT->Data);
PreorderTraversal(BT->Left);
PreorderTraversal(BT->Right);
}非递归:
*p=root;
while(p || !st.empty())
{
if(p)//非空
{
//visit(p);进行操作
st.push(p);//入栈
p = p->lchild;左
}
else//空
{
p = st.top();//取出
st.pop();
p = p->rchild;//右
}
}为啥这个O(n)的空间就是省不掉呢?因为我们需要空间来记录之前的位置,好在遍历完了可以回到父节点。所以这个空间是必须的!如下图:
![超硬核!小白读了这篇文章,就能在算法圈混了[通俗易懂]](https://img-blog.csdnimg.cn/20191216203828458.png)
比如我们遍历2,想遍历4,这时候我们要保证遍历完4以后,还能回到2,我们好去继续遍历5等等结点,所以必须花空间记录。
但是,还就有这么一种算法,能实现空间O(1)的遍历,服不服。
你们可能会问,你刚说的,必须有空间来记录路径,怎么又可以不用空间了呢?
这就是morris遍历,它其实是利用了叶子节点大量的空余空间来实现的,只要把他们利用起来,我们就可以省掉额外空间啦。
我们不说先序中序后序,先说morris遍历的原则:
1、如果没有左孩子,继续遍历右子树,比如:
![超硬核!小白读了这篇文章,就能在算法圈混了[通俗易懂]](https://img-blog.csdnimg.cn/20191216204334673.png)
这个2就没有左孩子,这时直接遍历右孩子即可。
2、如果有左孩子,找到左子树最右节点。
比如上图,6就是2的最右节点。
1)如果最右节点的右指针为空(说明第一次遇到),把它指向当前节点,当前节点向左继续处理。
修改后:
![超硬核!小白读了这篇文章,就能在算法圈混了[通俗易懂]](https://img-blog.csdnimg.cn/20191216204441238.png)
2)如果最右节点的右指针不为空(说明它指向之前结点),把右指针设为空,当前节点向右继续处理。
这就是morris遍历。
请手动模拟深度至少为4的树的morris遍历来熟悉流程。
下面给出实现:
定义结点:
public static class Node {
public int value;
Node left;
Node right;
public Node(int data) {
this.value = data;
}
}先序:(完全按规则写就好。)
//打印时机(第一次遇到):发现左子树最右的孩子右指针指向空,或无左子树。
public static void morrisPre(Node head) {
if (head == null) {
return;
}
Node cur1 = head;
Node cur2 = null;
while (cur1 != null) {
cur2 = cur1.left;
if (cur2 != null) {
while (cur2.right != null && cur2.right != cur1) {
cur2 = cur2.right;
}
if (cur2.right == null) {
cur2.right = cur1;
System.out.print(cur1.value + " ");
cur1 = cur1.left;
continue;
} else {
cur2.right = null;
}
} else {
System.out.print(cur1.value + " ");
}
cur1 = cur1.right;
}
System.out.println();
}morris在发表文章时只写出了中序遍历。而先序遍历只是打印时机不同而已,所以后人改进出了先序遍历。至于后序,是通过打印所有的右边界来实现的:对每个有边界逆序,打印,再逆序回去。注意要原地逆序,否则我们morris遍历的意义也就没有了。
完整代码:
public class MorrisTraversal {
public static void process(Node head) {
if(head == null) {
return;
}
// 1
//System.out.println(head.value);
process(head.left);
// 2
//System.out.println(head.value);
process(head.right);
// 3
//System.out.println(head.value);
}
public static class Node {
public int value;
Node left;
Node right;
public Node(int data) {
this.value = data;
}
}
//打印时机:向右走之前
public static void morrisIn(Node head) {
if (head == null) {
return;
}
Node cur1 = head;//当前节点
Node cur2 = null;//最右
while (cur1 != null) {
cur2 = cur1.left;
//左孩子不为空
if (cur2 != null) {
while (cur2.right != null && cur2.right != cur1) {
cur2 = cur2.right;
}//找到最右
//右指针为空,指向cur1,cur1向左继续
if (cur2.right == null) {
cur2.right = cur1;
cur1 = cur1.left;
continue;
} else {
cur2.right = null;
}//右指针不为空,设为空
}
System.out.print(cur1.value + " ");
cur1 = cur1.right;
}
System.out.println();
}
//打印时机(第一次遇到):发现左子树最右的孩子右指针指向空,或无左子树。
public static void morrisPre(Node head) {
if (head == null) {
return;
}
Node cur1 = head;
Node cur2 = null;
while (cur1 != null) {
cur2 = cur1.left;
if (cur2 != null) {
while (cur2.right != null && cur2.right != cur1) {
cur2 = cur2.right;
}
if (cur2.right == null) {
cur2.right = cur1;
System.out.print(cur1.value + " ");
cur1 = cur1.left;
continue;
} else {
cur2.right = null;
}
} else {
System.out.print(cur1.value + " ");
}
cur1 = cur1.right;
}
System.out.println();
}
//逆序打印所有右边界
public static void morrisPos(Node head) {
if (head == null) {
return;
}
Node cur1 = head;
Node cur2 = null;
while (cur1 != null) {
cur2 = cur1.left;
if (cur2 != null) {
while (cur2.right != null && cur2.right != cur1) {
cur2 = cur2.right;
}
if (cur2.right == null) {
cur2.right = cur1;
cur1 = cur1.left;
continue;
} else {
cur2.right = null;
printEdge(cur1.left);
}
}
cur1 = cur1.right;
}
printEdge(head);
System.out.println();
}
//逆序打印
public static void printEdge(Node head) {
Node tail = reverseEdge(head);
Node cur = tail;
while (cur != null) {
System.out.print(cur.value + " ");
cur = cur.right;
}
reverseEdge(tail);
}
//逆序(类似链表逆序)
public static Node reverseEdge(Node from) {
Node pre = null;
Node next = null;
while (from != null) {
next = from.right;
from.right = pre;
pre = from;
from = next;
}
return pre;
}
public static void main(String[] args) {
Node head = new Node(4);
head.left = new Node(2);
head.right = new Node(6);
head.left.left = new Node(1);
head.left.right = new Node(3);
head.right.left = new Node(5);
head.right.right = new Node(7);
morrisIn(head);
morrisPre(head);
morrisPos(head);
}
}第二节
2.1睡眠排序
这是那个员工写的睡眠排序,写完就被开除了哈哈哈哈。
![超硬核!小白读了这篇文章,就能在算法圈混了[通俗易懂]](https://img-blog.csdnimg.cn/20191216215059411.png)
![超硬核!小白读了这篇文章,就能在算法圈混了[通俗易懂]](https://img-blog.csdnimg.cn/20191216215112637.png)
![超硬核!小白读了这篇文章,就能在算法圈混了[通俗易懂]](https://img-blog.csdnimg.cn/20191216215004511.png)
它的基本思想是:
主要是根据CPU的调度算法实现的,对一组数据进行排序,不能存在负数值,这个数是多大,那么就在线程里睡眠它的10倍再加10,不是睡眠和它的数值一样大的原因是,当数值太小时,误差太大,睡眠的时间不比输出的时间少,那么就会存在不正确的输出结果。
按道理,他的程序也没问题啊,老板为什么要开除他?应用程序中出 BUG 不是很正常的事吗?但他这种排序思维,能写出这样的隐藏 BUG 也是绝了,创造性的发明了 “休眠排序” 算法,系统里面还不知道有多少这样的坑,不开除他开除谁啊?
如果非要说一个原因,我感觉,这哥们是故意这么写的,造成查询速度较慢,之后下个迭代优化,查询速度瞬间提上来了,这可是为公司做出大贡献了,年底了,奖励个优秀个人奖…..
2.2会死的兔子
斐波那契数列(Fibonacci sequence),又称黄金分割数列、因数学家列昂纳多·斐波那契(Leonardoda Fibonacci)以兔子繁殖为例子而引入,故又称为“兔子数列”。
这个例子是:刚开始,有一只兔子,这只兔子长到两岁的时候可以生一只小兔子,以后每年都可以生一只小兔子,而且兔子不会死。求第n年有几只兔子?
我们这么想:
今年的总数=去年的总数+今年的新出生的兔子,
而今年新出生的兔子=今年成熟了的兔子数量(每只成熟的兔子生一只小兔),
那今年成熟了的兔子数量又是什么呢?其实就是前年的兔子总数,因为前年的兔子,不管几岁,到今年一定成熟,可以生新兔子了。而去年的没有成熟,不能生兔子。
所以今年的总数=去年的总数+前年的总数。
F(n)=F(n-1)+F(n-2)。
这个数列就是1、1、2、3、5、8、13、21、34、……
在数学上,斐波那契数列以如下被以递推的方法定义:F(1)=1,F(2)=1, F(n)=F(n-1)+F(n-2)(n>=3,n∈N*)在现代物理、准晶体结构、化学等领域,斐波纳契数列都有直接的应用,为此,美国数学会从1963年起出版了以《斐波纳契数列季刊》为名的一份数学杂志,用于专门刊载这方面的研究成果。
解题也非常容易
解法一:完全抄定义
def f(n):
if n==1 or n==2:
return 1
return f(n-1)+f(n-2)分析一下,为什么说递归效率很低呢?咱们来试着运行一下就知道了:
比如想求f(10),计算机里怎么运行的?
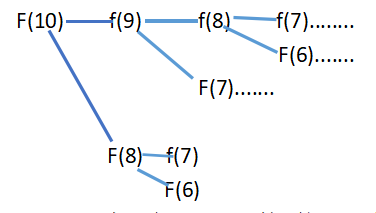
想算出f(10),就要先算出F(9),
想算出f(9),就要先算出F(8),
想算出f(8),就要先算出F(7),
想算出f(7),就要先算出F(6)……
兜了一圈,我们发现,有相当多的计算都重复了,比如红框部分:
![超硬核!小白读了这篇文章,就能在算法圈混了[通俗易懂]](https://img-blog.csdnimg.cn/20190906185552723.png)
那如何解决这个问题呢?问题的原因就在于,我们算出来某个结果,并没有记录下来,导致了重复计算。那很容易想到如果我们把计算的结果全都保存下来,按照一定的顺序推出n项,就可以提升效率
解法2:
def f1(n):
if n==1 or n==2:
return 1
l=[0]*n #保存结果
l[0],l[1]=1,1 #赋初值
for i in range(2,n):
l[i]=l[i-1]+l[i-2] #直接利用之前结果
return l[-1]可以看出,时间o(n),空间o(n)。
继续思考,既然只求第n项,而斐波那契又严格依赖前两项,那我们何必记录那么多值浪费空间呢?只记录前两项就可以了。
解法3:
def f2(n):
a,b=1,1
for i in range(n-1):
a,b=b,a+b
return a但是就有这么一个问题:兔子也会死
出生到死亡只有三年,即n年出生,n+3年死去。
出生一年以后可以生育,也就是n+1年开始生育,一年可以生一只宝宝。
如果你硬要推今年的总数,你会发现相当困难。
这时我们换一个思路:
定义f(n)为第n年新出生的动物个数,则f(n)=f(n-1)+f(n-2),前两项为1,而每年的总数也就是三项求和而已。
每年出生的数量为1,1,2,3,5,8,13,21
每年总数就是1,2,4,10,16,26,42
发现依旧是前两项加起来。
所以当我们按老思路解不出新的变形题,这时不妨换个思路,可能会有奇效,你想到了吗?
2.3矩阵快速幂
还是上面的斐波那契数列问题(兔子不会死),这种递推的题,一般无法突破O(N)时间的魔咒,但是我们可以利用矩阵快速幂的方法写出O(logN)的方法,是不是很神奇?
![超硬核!小白读了这篇文章,就能在算法圈混了[通俗易懂]](https://img-blog.csdnimg.cn/20191216221708681.png)
public static int[][] matrixPower(int[][] m, int p) {
int[][] res = new int[m.length][m[0].length];
for (int i = 0; i < res.length; i++) {
res[i][i] = 1;
}
int[][] tmp = m;
for (; p != 0; p >>= 1) {
if ((p & 1) != 0) {
res = muliMatrix(res, tmp);
}
tmp = muliMatrix(tmp, tmp);
}
return res;
}
public static int[][] muliMatrix(int[][] m1, int[][] m2) {
int[][] res = new int[m1.length][m2[0].length];
for (int i = 0; i < m1.length; i++) {
for (int j = 0; j < m2[0].length; j++) {
for (int k = 0; k < m2.length; k++) {
res[i][j] += m1[i][k] * m2[k][j];
}
}
}
return res;
} public static int f3(int n) {
if (n < 1) {
return 0;
}
if (n == 1 || n == 2) {
return 1;
}
int[][] base = { { 1, 1 }, { 1, 0 } };
int[][] res = matrixPower(base, n - 2);
return res[0][0] + res[1][0];
}值得思考的是,当我们一项一项的一维计算到达维度极限时,提高一个维度的计算就突破了时间极限,那么是否有三维的计算的解法?
2.4摔手机/摔鸡蛋
如果对算法感兴趣的朋友,可能会知道下面这道题:
leetcode的hard难度(我认为应该出一个顶级难度):
你将获得 K 个鸡蛋,并可以使用一栋从 1 到 N 共有 N 层楼的建筑。
每个蛋的功能都是一样的,如果一个蛋碎了,你就不能再把它掉下去。
你知道存在楼层 F ,满足 0 <= F <= N 任何从高于 F 的楼层落下的鸡蛋都会碎,从 F 楼层或比它低的楼层落下的鸡蛋都不会破。
每次移动,你可以取一个鸡蛋(如果你有完整的鸡蛋)并把它从任一楼层 X 扔下(满足 1 <= X <= N)。
你的目标是确切地知道 F 的值是多少。
无论 F 的初始值如何,你确定 F 的值的最小移动次数是多少?
示例 1:
输入:K = 1, N = 2
输出:2
解释:鸡蛋从 1 楼掉落。如果它碎了,我们肯定知道 F = 0 。
否则,鸡蛋从 2 楼掉落。如果它碎了,我们肯定知道 F = 1 。
如果它没碎,那么我们肯定知道 F = 2 。
因此,在最坏的情况下我们需要移动 2 次以确定 F 是多少。
蓝桥杯:
x星球的居民脾气不太好,但好在他们生气的时候唯一的异常举动是:摔手机。
各大厂商也就纷纷推出各种耐摔型手机。x星球的质监局规定了手机必须经过耐摔测试,并且评定出一个耐摔指数来,之后才允许上市流通。
x星球有很多高耸入云的高塔,刚好可以用来做耐摔测试。塔的每一层高度都是一样的,与地球上稍有不同的是,他们的第一层不是地面,而是相当于我们的2楼。
如果手机从第7层扔下去没摔坏,但第8层摔坏了,则手机耐摔指数=7。
特别地,如果手机从第1层扔下去就坏了,则耐摔指数=0。如果到了塔的最高层第n层扔没摔坏,则耐摔指数=n
为了减少测试次数,从每个厂家抽样3部手机参加测试。
某次测试的塔高为1000层,如果我们总是采用最佳策略,在最坏的运气下最多需要测试多少次才能确定手机的耐摔指数呢?
请填写这个最多测试次数。
注意:需要填写的是一个整数,不要填写任何多余内容
答案19
问法不同,但是实际上是一个问题。
读完题后,我们追求的不是要写出得数(至少对于本博客是不够的),而是用代码实现方法,并思考是否可以优化。
其实本题的方法是非常多种多样的。非常适合锻炼思维。
我们把问题扩展到n个手机来思考。
手机k个,楼n层,最终结果M次。
时空复杂度目录
暴力: O(N!)
DP: O(N*N*K) O(N*K)
压空间: O(N*N*K) O(N)
四边形不等式优化 O(N*N)
换思路: O(K*M)
最优: O(K*M) O(N)
文末有测试,大家可以去直观感受一下各方法运行的效率
二分
容易想到二分思路:不断二分范围,取中点,测验是否会摔坏,然后缩小一半范围,继续尝试,很显然,答案为logN(2为底)
但是,二分得出的答案是不对的。注意:我们要保证在都手机摔完之前,能确定耐摔指数到底是多少。
举例:
我们在500楼摔坏了,在250楼摔,又坏了。接下来,我们只能从1楼开始一层一层试
因为如果我们在125层摔坏了,就没有手机可以用,也就是永远都测不出来,而这是不被允许的。其实我们连测第2层都不敢测,因为在第2层摔坏了,我们就无法知道手机在第一层能否被摔坏。所以只有一部手机时,我们只敢从第一层开始摔。
尝试较优的策略
既然二分是不对的,我们继续分析:摔手机的最优策略到底是如何的。
只有一部手机时,我们只敢从第一层开始摔。
有两部手机的时候,我们就敢隔层摔了,因为一部手机坏了,我们还有另一部来继续试。
这时就有点意思了,我们分析情况:
情况1)假设我们第一部手机在i层摔坏了,然后最坏情况还要试多少次?这时我们还剩一部手机,所以只敢一层一层试,最坏情况要试到i-1层,共试了i次。
情况2)假设我们第一部手机在i层试了,但是没摔坏,然后最坏情况还要试多少次?(这时发现算情况2时依旧是相似的问题,确定了可以用递归来解。)
最优解(最小值)是决策后两种情况的最差情况(最大值),我们的本能感觉应该就是让最差情况好一点,让最好情况差一点,这样比较接近正确答案。比如两部手机,一百层,我们可以在50层摔,没坏,这一次就很赚,我们没摔坏手机还把范围缩小了50层。如果坏了,就比较坑了,我们要从1试到50。虽然可能缩小一半,但是最坏情况次数太多,所以肯定要从某个低于五十的层开始尝试。
(以上几行是为了让读者理解决策,下面正文分析)
归纳表达式
假设我们的楼一共n层,我们的i可以取1-n任意值,有很多种可能的决策,我们的最小值设为f(n,k),n代表楼高(范围为1-100或101-200其实都一样),k代表手机数.
我们假设的决策是在第i楼扔
对于情况一,手机少了一部,并且我们确定了范围,一定在第i楼以下,所以手机-1,层数为i-1,这时f(n,k)=f(i-1,k-1).+1
对于情况二,手机没少,并且我们确定了范围,一定在第i楼之上,所以手机数不变,而层数-i层,这时f(n,k)=f(n-i,k).+1
归纳出
f(n,k)=min( max(f(i-1,k-1) ,f(n-i,k) ) i取1-n任意数 )+1
简单总结:怎么确定第一个手机在哪扔?每层都试试,哪层的最坏情况(max)最好(min),就去哪层扔。
写出暴力递归
按照分析出来的表达式,我们可以写出暴力递归:
public static int solution1(int nLevel, int kChess) {
if (nLevel == 0) {
return 0;
}//范围缩小至0
if (kChess == 1) {
return nLevel;
}//每层依次试
int min = Integer.MAX_VALUE;//取不影响结果的数
for (int i = 1; i != nLevel + 1; i++) {
//尝试所有决策,取最优
min = Math.min(
min,
Math.max(Process1(i - 1, kChess - 1),Process1(nLevel - i, kChess)));
}
return min + 1;//别忘了加上本次
}
改为动态规划
具体思路如下
https://blog.csdn.net/hebtu666/article/details/79912328
public static int solution2(int nLevel, int kChess) {
if (kChess == 1) {
return nLevel;
}
int[][] dp = new int[nLevel + 1][kChess + 1];
for (int i = 1; i != dp.length; i++) {
dp[i][1] = i;
}
for (int i = 1; i != dp.length; i++) {
for (int j = 2; j != dp[0].length; j++) {
int min = Integer.MAX_VALUE;
for (int k = 1; k != i + 1; k++) {
min = Math.min(min,
Math.max(dp[k - 1][j - 1], dp[i - k][j]));
}
dp[i][j] = min + 1;
}
}
return dp[nLevel][kChess];
}
压缩空间
我们发现,对于状态转移方程,只和上一盘排的dp表和左边的dp表有关,所以我们不需要把值全部记录,用两个长度为n的数组不断更新即可(具体对dp压缩空间的思路,也是很重要的,我在其它文章中有提过,在这里就不写了)
public static int solution3(int nLevel, int kChess) {
if (kChess == 1) {
return nLevel;
}
int[] preArr = new int[nLevel + 1];
int[] curArr = new int[nLevel + 1];
for (int i = 1; i != curArr.length; i++) {
curArr[i] = i;
}//初始化
for (int i = 1; i != kChess; i++) {
//先交换
int[] tmp = preArr;
preArr = curArr;
curArr = tmp;
//然后打新的一行
for (int j = 1; j != curArr.length; j++) {
int min = Integer.MAX_VALUE;
for (int k = 1; k != j + 1; k++) {
min = Math.min(min, Math.max(preArr[k - 1], curArr[j - k]));
}
curArr[j] = min + 1;
}
}
return curArr[curArr.length - 1];
}
四边形不等式优化
四边形不等式是一种比较常见的优化动态规划的方法
定义:如果对于任意的a1≤a2<b1≤b2,有m[a1,b1]+m[a2,b2]≤m[a1,b2]+m[a2,b1],那么m[i,j]满足四边形不等式。
对s[i,j-1]≤s[i,j]≤s[i+1,j]的证明:
设mk[i,j]=m[i,k]+m[k,j],s[i,j]=d
对于任意k<d,有mk[i,j]≥md[i,j](这里以m[i,j]=min{m[i,k]+m[k,j]}为例,max的类似),接下来只要证明mk[i+1,j]≥md[i+1,j],那么只有当s[i+1,j]≥s[i,j]时才有可能有mk[i+1,j]≥md[i+1,j]
(mk[i+1,j]-md[i+1,j])-(mk[i,j]-md[i,j])
=(mk[i+1,j]+md[i,j])-(md[i+1,j]+mk[i,j])
=(m[i+1,k]+m[k,j]+m[i,d]+m[d,j])-(m[i+1,d]+m[d,j]+m[i,k]+m[k,j])
=(m[i+1,k]+m[i,d])-(m[i+1,d]+m[i,k])
∵m满足四边形不等式,∴对于i<i+1≤k<d有m[i+1,k]+m[i,d]≥m[i+1,d]+m[i,k]
∴(mk[i+1,j]-md[i+1,j])≥(mk[i,j]-md[i,j])≥0
∴s[i,j]≤s[i+1,j],同理可证s[i,j-1]≤s[i,j]
证毕
通俗来说,
优化策略1)我们在求k+1手机n层楼时,最后发现,第一个手机在m层扔导致了最优解的产生。那我们在求k个手机n层楼时,第一个手机的策略就不用尝试m层以上的楼了。
优化策略2)我们在求k个手机n层楼时,最后发现,第一个手机在m层扔导致了最优解的产生。那我们在求k个手机n+1层楼时,就不用尝试m层以下的楼了。
public static int solution4(int nLevel, int kChess) {
if (kChess == 1) {
return nLevel;
}
int[][] dp = new int[nLevel + 1][kChess + 1];
for (int i = 1; i != dp.length; i++) {
dp[i][1] = i;
}
int[] cands = new int[kChess + 1];
for (int i = 1; i != dp[0].length; i++) {
dp[1][i] = 1;
cands[i] = 1;
}
for (int i = 2; i < nLevel + 1; i++) {
for (int j = kChess; j > 1; j--) {
int min = Integer.MAX_VALUE;
int minEnum = cands[j];
int maxEnum = j == kChess ? i / 2 + 1 : cands[j + 1];
//优化策略
for (int k = minEnum; k < maxEnum + 1; k++) {
int cur = Math.max(dp[k - 1][j - 1], dp[i - k][j]);
if (cur <= min) {
min = cur;
cands[j] = k;//最优解记录层数
}
}
dp[i][j] = min + 1;
}
}
return dp[nLevel][kChess];
}注:对于四边形不等式的题目,比赛时不需要严格证明
通常的做法是打表出来之后找规律,然后大胆猜测,显然可得。(手动滑稽)
换一种思路
有时,最优解并不是优化来的。
当你对着某个题冥思苦想了好久,无论如何也不知道怎么把时间优化到合理范围,可能这个题的最优解就不是这种思路,这时,试着换一种思路思考,可能会有奇效。
(比如训练时一道贪心我死活往dp想,肝了两个小时以后,不主攻这个方向的队友三分钟就有贪心思路了,泪目,不要把简单问题复杂化)
我们换一种思路想问题:
原问题:n层楼,k个手机,最多测试次数
反过来看问题:k个手机,扔m次,最多能确定多少层楼?
我们定义dp[i][j]:i个手机扔j次能确定的楼数。
分析情况:依旧是看第一部手机在哪层扔的决策,同样,我们的决策首先要保证能确定从1层某一段,而不能出现次数用完了还没确定好的情况。以这个为前提,保证了每次扔的楼层都是最优的,就能求出结果。
依旧是取最坏情况:min(情况1,情况2)
情况1)第一个手机碎了,我们就需要用剩下的i-1个手机和j-1次测试次数往下去测,dp[i-1][j-1]。那我们能确定的层数是无限的,因为本层以上的无限层楼都不会被摔坏。dp[i-1][j-1]+无穷=无穷
情况2)第一个手机没碎,那我们就看i个手机扔j-1次能确定的楼数(向上试)+当前楼高h
归纳表达式,要取最差情况,所以就是只有情况2:dp[i][j]=dp[i-1][j-1]+h
那这个h到底是什么呢?取决于我敢从哪层扔。因为次数减了一次,我们还是要考虑i个球和j-1次的最坏情况能确定多少层,我才敢在层数+1的地方扔。(这是重点)
也就是dp[i][j-1]的向上一层:h=dp[i][j-1]+1
总:min(情况1,情况2)=min(无穷,dp[i-1][j-1]+dp[i][j-1]+1)=dp[i-1][j-1]+dp[i][j-1]+1
这是解决k个手机,扔m次,最多能确定多少层楼?
原问题是n层楼,k个手机,最多测试次数。
所以我们在求的过程中,何时能确定的层数大于n,输出扔的次数即可
最优解
我们知道完全用二分扔需要logN+1次,这也绝对是手机足够情况下的最优解,我们做的这么多努力都是因为手机不够摔啊。。。。所以当我们的手机足够用二分来摔时,直接求出logN+1即可。
当然,我们求dp需要左边的值和左上的值:
![超硬核!小白读了这篇文章,就能在算法圈混了[通俗易懂]](https://img-blog.csdnimg.cn/2018120417550852.png)
依旧可以压缩空间,从左往右更新,previous记录左上的值。
求自己时也要注意记录,否则更新过后,后面的要用没更新过的值(左上方)就找不到了。
记录之后,求出当前数值,把记录的temp值给了previous即可。
public static int solution5(int nLevel, int kChess) {
int bsTimes = log2N(nLevel) + 1;
if (kChess >= bsTimes) {
return bsTimes;
}
int[] dp = new int[kChess];
int res = 0;
while (true) {
res++;//压缩空间记得记录次数
int previous = 0;
for (int i = 0; i < dp.length; i++) {
int tmp = dp[i];
dp[i] = dp[i] + previous + 1;
previous = tmp;
if (dp[i] >= nLevel) {
return res;
}
}
}
}
public static int log2N(int n) {
int res = -1;
while (n != 0) {
res++;
n >>>= 1;
}
return res;
}测试:
暴力: O(N!)
DP: O(N*N*K) O(N*K)
压空间: O(N*N*K) O(N)
四边形不等式优化 O(N*N)
最优: O(K*M) O(N)
long start = System.currentTimeMillis();
solution1(30, 2);
long end = System.currentTimeMillis();
System.out.println("cost time: " + (end - start) + " ms");
start = System.currentTimeMillis();
solution2(30, 2);
end = System.currentTimeMillis();
System.out.println("cost time: " + (end - start) + " ms");
start = System.currentTimeMillis();
solution3(30, 2);
end = System.currentTimeMillis();
System.out.println("cost time: " + (end - start) + " ms");
start = System.currentTimeMillis();
solution4(30, 2);
end = System.currentTimeMillis();
System.out.println("cost time: " + (end - start) + " ms");
start = System.currentTimeMillis();
solution5(30, 2);
end = System.currentTimeMillis();
System.out.println("cost time: " + (end - start) + " ms");
/*
结果:
cost time: 7043 ms
cost time: 0 ms
cost time: 0 ms
cost time: 0 ms
cost time: 0 ms
*/暴力时间实在是太久了,只测一个30,2
后四种方法测的大一些(差点把电脑测炸了,cpu100内存100):
solution(100000, 10):
solution2 cost time: 202525 ms
solution3 cost time: 38131 ms
solution4 cost time: 11295 ms
solution5 cost time: 0 ms
感受最优解的强大:
solution5(1000 000 000,100):0 ms
solution5(1000 000 000,10):0 ms
最优解永远都是0 ms,我也是服了。。
对比方法,在时间复杂度相同的条件下,空间复杂度一样会影响时间,因为空间太大的话,申请空间是相当浪费时间的。并且空间太大电脑会炸,所以不要认为空间不重要。
第三节
3.1斐波那契之美
斐波那契数列(Fibonacci sequence),又称黄金分割数列、因数学家列昂纳多·斐波那契(Leonardoda Fibonacci)以兔子繁殖为例子而引入,故又称为“兔子数列”。
这个数列就是1、1、2、3、5、8、13、21、34、……
在数学上,斐波那契数列以如下被以递推的方法定义:F(1)=1,F(2)=1, F(n)=F(n-1)+F(n-2)(n>=3,n∈N*)在现代物理、准晶体结构、化学等领域,斐波纳契数列都有直接的应用,为此,美国数学会从1963年起出版了以《斐波纳契数列季刊》为名的一份数学杂志,用于专门刊载这方面的研究成果。
但是斐波那契的知识不止于此,它还有很多惊艳到我的地方,下面我们就一起了解一下:
- 随着数列项数的增加,前一项与后一项之比越来越逼近黄金分割的数值0.6180339887..
- 从第二项开始,每个奇数项的平方都比前后两项之积多1,每个偶数项的平方都比前后两项之积少1。(注:奇数项和偶数项是指项数的奇偶,而并不是指数列的数字本身的奇偶,比如第五项的平方比前后两项之积多1,第四项的平方比前后两项之积少1)
- 斐波那契数列的第n项同时也代表了集合{1,2,…,n}中所有不包含相邻正整数的子集个数。
- f(0)+f(1)+f(2)+…+f(n)=f(n+2)-1
- f(1)+f(3)+f(5)+…+f(2n-1)=f(2n)
- f(2)+f(4)+f(6)+…+f(2n) =f(2n+1)-1
- [f(0)]^2+[f(1)]^2+…+[f(n)]^2=f(n)·f(n+1)
- f(0)-f(1)+f(2)-…+(-1)^n·f(n)=(-1)^n·[f(n+1)-f(n)]+1
- f(m+n)=f(m-1)·f(n-1)+f(m)·f(n) (利用这一点,可以用程序编出时间复杂度仅为O(log n)的程序。)
真的不禁感叹:真是一个神奇的数列啊
3.2桶排序
我们都知道,基于比较的排序,时间的极限就是O(NlogN),从来没有哪个排序可以突破这个界限,如速度最快的快速排序,想法新颖的堆排序,分治的归并排序。
但是,如果我们的排序根本就不基于比较,那就可能突破这个时间。
桶排序不是基于比较的排序方法,只需对号入座。将相应的数字放进相应编号的桶即可。
当要被排序的数组内的数值是均匀分配的时候,桶排序使用线性时间o(n)
对于海量有范围数据十分适合,比如全国高考成绩排序,公司年龄排序等等。
l=list(map(int,input().split(" ")))
n=max(l)-min(l)
p=[0]*(n+1)#为了省空间
for i in l:
p[i-min(l)]=1#去重排序,做标记即可
for i in range(n):
if p[i]==1:#判断是否出现过
print(i+min(l),end=" ")当然,基数排序是桶排序的改良版,也是非常好的排序方法,具体操作是:把数字的每一位都按桶排序排一次,因为桶排序是稳定的排序,因此从个位进行桶排序,然后十位进行桶排序。。。直到最高位,排序结束。
这样极大的弱化了桶排序范围有限的弱点,比如范围1-100000需要准备100000个铜,而基数排序只要10个铜就够了(因为一共就十个数字。)。
想出这个排序的人也是个天才啊。。。选择合适的场合使用觉得有很好的效果。
3.3快速排序
快速排序(Quicksort)是对冒泡排序的一种改进。
快速排序由C. A. R. Hoare在1962年提出。它的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
分三区优化1:
在使用partition-exchange排序算法时,如快速排序算法,我们会遇到一些问题,比如重复元素太多,降低了效率,在每次递归中,左边部分是空的(没有元素比关键元素小),而右边部分只能一个一个递减移动。结果导致耗费了二次方时间来排序相等元素。这时我们可以多分一个区,即,小于区,等于区,大于区。(传统快排为小于区和大于区)
下面我们通过一个经典例题来练习这种思想。
荷兰国旗问题
”荷兰国旗难题“是计算机科学中的一个程序难题,它是由Edsger Dijkstra提出的。荷兰国旗是由红、白、蓝三色组成的。
现在有若干个红、白、蓝三种颜色的球随机排列成一条直线。现在我们的任务是把这些球按照红、白、蓝排序。
样例输入
3
BBRRWBWRRR
RRRWWRWRB
RBRW
样例输出
RRRRRWWBBB
RRRRRWWWB
RRWB
思路:
现在我们的思路就是把未排序时前部和后部分别排在数组的前面和后面,那么中部自然就排好了。
设置两个标志位head指向数组开头,tail指向数组末尾,now从头开始遍历:
(1)如果遍历到的位置为1,那么它一定是属于前部,于是就和head交换值,然后head++,now++;
(2)如果遍历到的位置为2,说明属于中部,now++;
(3)如果遍历到的位置为3,说明属于后部,于是就和tail交换值,然而,如果此时交换后now指向的值属于前部,那么就执行(1),tail–;
废话不多说,上代码。
#include<iostream>
#include<algorithm>
using namespace std;
const int maxn = 100 + 5;
int n;
string str;
int main(){
cin>>n;
while(n--){
cin>>str;
int len=str.size();
int now=0,ans=0;
int head=0,tail=len-1;
while(now<=tail){
if(str[now]=='R'){
swap(str[head],str[now]);
head++;
now++;
}
else if(str[now]=='W'){
now++;
}
else{
swap(str[now],str[tail]);
tail--;
}
}
cout<<str<<endl;
}return 0;
}快排分三区以后降低了递归规模,避免了最差情况,性能得到改进。
但是还是存在退化情况:
随机化快排优化2:
快速排序的最坏情况基于每次划分对主元的选择。基本的快速排序选取第一个元素作为主元。这样在数组已经有序的情况下,每次划分将得到最坏的结果。比如1 2 3 4 5,每次取第一个元素,就退化为了O(N^2)。一种比较常见的优化方法是随机化算法,即随机选取一个元素作为主元。
这种情况下虽然最坏情况仍然是O(n^2),但最坏情况不再依赖于输入数据,而是由于随机函数取值不佳。实际上,随机化快速排序得到理论最坏情况的可能性仅为1/(2^n)。所以随机化快速排序可以对于绝大多数输入数据达到O(nlogn)的期望时间复杂度。
def gg(a,b):
global l
if a>=b:#注意停止条件,我以前没加>卡了半小时
return
x,y=a,b
import random#为了避免遇到基本有序序列退化,随机选点
g=random.randint(a,b)
l[g],l[y]=l[y],l[g]#交换选中元素和末尾元素
while a<b:
if l[a]>l[y]:#比目标元素大
l[a],l[b-1]=l[b-1],l[a]#交换
b=b-1#大于区扩大
#注意:换过以后a不要加,因为新换过来的元素并没有判断过
else:a=a+1#小于区扩大
l[y],l[a]=l[a],l[y]#这时a=b
#现在解释a和b:a的意义是小于区下一个元素
#b是大于区的第一个元素
gg(x,a-1)#左右分别递归
gg(a+1,y)
l=list(map(int,input().split(" ")))
gg(0,len(l)-1)
print(l)3.4BFPRT
我们以前写过快排的改进求前k大或前k小,但是快排不可避免地存在退化问题,即使我们用了随机数等优化,最差情况不可避免的退化到了O(N^2),而BFPRT就解决了这个问题,主要的思想精华就是怎么选取划分值。
我们知道,经典快排是选第一个数进行划分。而改进快排是随机选取一个数进行划分,从概率上避免了基本有序情况的退化。而BFPRT算法选划分值的规则比较特殊,保证了递归最小的缩减规模也会比较大,而不是每次缩小一个数。
这个划分值如何划分就是重点。
如何让选取的点无论如何都不会太差。
1、将n个元素划分为n/5个组,每组5个元素
2、对每组排序,找到n/5个组中每一组的中位数;
3、对于找到的所有中位数,调用BFPRT算法求出它们的中位数,作为划分值。
下面说明为什么这样找划分值。
![超硬核!小白读了这篇文章,就能在算法圈混了[通俗易懂]](https://img-blog.csdn.net/20181016112714281)
我们先把数每五个分为一组。
同一列为一组。
排序之后,第三行就是各组的中位数。
我们把第三行的数构成一个数列,递归找,找到中位数。
这个黑色框为什么找的很好。
因为他一定比A3、B3大,而A3、B3、C3又在自己的组内比两个数要大。
我们看最差情况:求算其它的数都比c3大,我们也能在25个数中缩小九个数的规模。大约3/10.
我们就做到了最差情况固定递减规模,而不是可能缩小的很少。
下面代码实现:
public class BFPRT {
//前k小
public static int[] getMinKNumsByBFPRT(int[] arr, int k) {
if (k < 1 || k > arr.length) {
return arr;
}
int minKth = getMinKthByBFPRT(arr, k);
int[] res = new int[k];
int index = 0;
for (int i = 0; i != arr.length; i++) {
if (arr[i] < minKth) {
res[index++] = arr[i];
}
}
for (; index != res.length; index++) {
res[index] = minKth;
}
return res;
}
//第k小
public static int getMinKthByBFPRT(int[] arr, int K) {
int[] copyArr = copyArray(arr);
return select(copyArr, 0, copyArr.length - 1, K - 1);
}
public static int[] copyArray(int[] arr) {
int[] res = new int[arr.length];
for (int i = 0; i != res.length; i++) {
res[i] = arr[i];
}
return res;
}
//给定一个数组和范围,求第i小的数
public static int select(int[] arr, int begin, int end, int i) {
if (begin == end) {
return arr[begin];
}
int pivot = medianOfMedians(arr, begin, end);//划分值
int[] pivotRange = partition(arr, begin, end, pivot);
if (i >= pivotRange[0] && i <= pivotRange[1]) {
return arr[i];
} else if (i < pivotRange[0]) {
return select(arr, begin, pivotRange[0] - 1, i);
} else {
return select(arr, pivotRange[1] + 1, end, i);
}
}
//在begin end范围内进行操作
public static int medianOfMedians(int[] arr, int begin, int end) {
int num = end - begin + 1;
int offset = num % 5 == 0 ? 0 : 1;//最后一组的情况
int[] mArr = new int[num / 5 + offset];//中位数组成的数组
for (int i = 0; i < mArr.length; i++) {
int beginI = begin + i * 5;
int endI = beginI + 4;
mArr[i] = getMedian(arr, beginI, Math.min(end, endI));
}
return select(mArr, 0, mArr.length - 1, mArr.length / 2);
//只不过i等于长度一半,用来求中位数
}
//经典partition过程
public static int[] partition(int[] arr, int begin, int end, int pivotValue) {
int small = begin - 1;
int cur = begin;
int big = end + 1;
while (cur != big) {
if (arr[cur] < pivotValue) {
swap(arr, ++small, cur++);
} else if (arr[cur] > pivotValue) {
swap(arr, cur, --big);
} else {
cur++;
}
}
int[] range = new int[2];
range[0] = small + 1;
range[1] = big - 1;
return range;
}
//五个数排序,返回中位数
public static int getMedian(int[] arr, int begin, int end) {
insertionSort(arr, begin, end);
int sum = end + begin;
int mid = (sum / 2) + (sum % 2);
return arr[mid];
}
//手写排序
public static void insertionSort(int[] arr, int begin, int end) {
for (int i = begin + 1; i != end + 1; i++) {
for (int j = i; j != begin; j--) {
if (arr[j - 1] > arr[j]) {
swap(arr, j - 1, j);
} else {
break;
}
}
}
}
//交换值
public static void swap(int[] arr, int index1, int index2) {
int tmp = arr[index1];
arr[index1] = arr[index2];
arr[index2] = tmp;
}
//打印
public static void printArray(int[] arr) {
for (int i = 0; i != arr.length; i++) {
System.out.print(arr[i] + " ");
}
System.out.println();
}
public static void main(String[] args) {
int[] arr = { 6, 9, 1, 3, 1, 2, 2, 5, 6, 1, 3, 5, 9, 7, 2, 5, 6, 1, 9 };
// sorted : { 1, 1, 1, 1, 2, 2, 2, 3, 3, 5, 5, 5, 6, 6, 6, 7, 9, 9, 9 }
printArray(getMinKNumsByBFPRT(arr, 10));
}
}这个办法解决了最差的退化情况,在一大堆数中求其前k大或前k小的问题,简称TOP-K问题。目前解决TOP-K问题最有效的算法即是BFPRT算法,其又称为中位数的中位数算法,该算法由Blum、Floyd、Pratt、Rivest、Tarjan提出 ,让我们永远记住这群伟大的人。
第四节
4.1防止新手错误的神级代码
#define ture true
#define flase false
#difine viod void
#define mian main
#define ; ;
以后有新手问题就把这几行代码给他就好啦。
4.2不用额外空间交换两个变量
a = 5
b = 8
#计算a和b两个点到原点的距离之和,并且赋值给a
a = a+b
#使用距离之和减去b到原点的距离
#a-b 其实就是a的原值(a到原点的距离),现在赋值给了b
b = a-b
#再使用距离之和减去b (a到原点的距离)
#得到的是b的原值(b到原点的距离),现在赋值给了a
a = a-b
4.3八皇后问题神操作
是一个以国际象棋为背景的问题:如何能够在 8×8 的国际象棋棋盘上放置八个皇后,使得任何一个皇后都无法直接吃掉其他的皇后?为了达到此目的,任两个皇后都不能处于同一条横行、纵行或斜线上。八皇后问题可以推广为更一般的n皇后摆放问题:这时棋盘的大小变为n1×n1,而皇后个数也变成n2。而且仅当 n2 ≥ 1 或 n1 ≥ 4 时问题有解。
皇后问题是非常著名的问题,作为一个棋盘类问题,毫无疑问,用暴力搜索的方法来做是一定可以得到正确答案的,但在有限的运行时间内,我们很难写出速度可以忍受的搜索,部分棋盘问题的最优解不是搜索,而是动态规划,某些棋盘问题也很适合作为状态压缩思想的解释例题。
进一步说,皇后问题可以用人工智能相关算法和遗传算法求解,可以用多线程技术缩短运行时间。本文不做讨论。
(本文不展开讲状态压缩,以后再说)
一般思路:
N*N的二维数组,在每一个位置进行尝试,在当前位置上判断是否满足放置皇后的条件(这一点的行、列、对角线上,没有皇后)。
优化1:
既然知道多个皇后不能在同一行,我们何必要在同一行的不同位置放多个来尝试呢?
我们生成一维数组record,record[i]表示第i行的皇后放在了第几列。对于每一行,确定当前record值即可,因为每行只能且必须放一个皇后,放了一个就无需继续尝试。那么对于当前的record[i],查看record[0…i-1]的值,是否有j = record[k](同列)、|record[k] – j| = | k-i |(同一斜线)的情况。由于我们的策略,无需检查行(每行只放一个)。
public class NQueens {
public static int num1(int n) {
if (n < 1) {
return 0;
}
int[] record = new int[n];
return process1(0, record, n);
}
public static int process1(int i, int[] record, int n) {
if (i == n) {
return 1;
}
int res = 0;
for (int j = 0; j < n; j++) {
if (isValid(record, i, j)) {
record[i] = j;
res += process1(i + 1, record, n);
}
}//对于当前行,依次尝试每列
return res;
}
//判断当前位置是否可以放置
public static boolean isValid(int[] record, int i, int j) {
for (int k = 0; k < i; k++) {
if (j == record[k] || Math.abs(record[k] - j) == Math.abs(i - k)) {
return false;
}
}
return true;
}
public static void main(String[] args) {
int n = 8;
System.out.println(num1(n));
}
}
位运算优化2:
分析:棋子对后续过程的影响范围:本行、本列、左右斜线。
![超硬核!小白读了这篇文章,就能在算法圈混了[通俗易懂]](https://img-blog.csdnimg.cn/20181129150412832.png)
黑色棋子影响区域为红色
1)本行影响不提,根据优化一已经避免
2)本列影响,一直影响D列,直到第一行在D放棋子的所有情况结束。
3)左斜线:每向下一行,实际上对当前行的影响区域就向左移动
比如:
尝试第二行时,黑色棋子影响的是我们的第三列;
尝试第三行时,黑色棋子影响的是我们的第二列;
尝试第四行时,黑色棋子影响的是我们的第一列;
尝试第五行及以后几行,黑色棋子对我们并无影响。
4)右斜线则相反:
随着行序号增加,影响的列序号也增加,直到影响的列序号大于8就不再影响。
我们对于之前棋子影响的区域,可以用二进制数字来表示,比如:
每一位,用01代表是否影响。
比如上图,对于第一行,就是00010000
尝试第二行时,数字变为00100000
第三行:01000000
第四行:10000000
对于右斜线的数字,同理:
第一行00010000,之后向右移:00001000,00000100,00000010,00000001,直到全0不影响。
同理,我们对于多行数据,也同样可以记录了
比如在第一行我们放在了第四列:
![超硬核!小白读了这篇文章,就能在算法圈混了[通俗易懂]](https://img-blog.csdnimg.cn/20181129151741248.png)
第二行放在了G列,这时左斜线记录为00100000(第一个棋子的影响)+00000010(当前棋子的影响)=00100010。
到第三行数字继续左移:01000100,然后继续加上我们的选择,如此反复。
这样,我们对于当前位置的判断,其实可以通过左斜线变量、右斜线变量、列变量,按位或运算求出(每一位中,三个数有一个是1就不能再放)。
具体看代码:
注:怎么排版就炸了呢。。。贴一张图吧
![超硬核!小白读了这篇文章,就能在算法圈混了[通俗易懂]](https://img-blog.csdnimg.cn/20181129154913198.png)
public class NQueens {
public static int num2(int n) {
// 因为本方法中位运算的载体是int型变量,所以该方法只能算1~32皇后问题
// 如果想计算更多的皇后问题,需使用包含更多位的变量
if (n < 1 || n > 32) {
return 0;
}
int upperLim = n == 32 ? -1 : (1 << n) - 1;
//upperLim的作用为棋盘大小,比如8皇后为00000000 00000000 00000000 11111111
//32皇后为11111111 11111111 11111111 11111111
return process2(upperLim, 0, 0, 0);
}
public static int process2(int upperLim, int colLim, int leftDiaLim,
int rightDiaLim) {
if (colLim == upperLim) {
return 1;
}
int pos = 0; //pos:所有的合法位置
int mostRightOne = 0; //所有合法位置的最右位置
//所有记录按位或之后取反,并与全1按位与,得出所有合法位置
pos = upperLim & (~(colLim | leftDiaLim | rightDiaLim));
int res = 0;//计数
while (pos != 0) {
mostRightOne = pos & (~pos + 1);//取最右的合法位置
pos = pos - mostRightOne; //去掉本位置并尝试
res += process2(
upperLim, //全局
colLim | mostRightOne, //列记录
//之前列+本位置
(leftDiaLim | mostRightOne) << 1, //左斜线记录
//(左斜线变量+本位置)左移
(rightDiaLim | mostRightOne) >>> 1); //右斜线记录
//(右斜线变量+本位置)右移(高位补零)
}
return res;
}
public static void main(String[] args) {
int n = 8;
System.out.println(num2(n));
}
}
完整测试代码:
32皇后:结果/时间
暴力搜:时间就太长了,懒得测。。。
![超硬核!小白读了这篇文章,就能在算法圈混了[通俗易懂]](https://img-blog.csdnimg.cn/20181129154155159.png)
public class NQueens {
public static int num1(int n) {
if (n < 1) {
return 0;
}
int[] record = new int[n];
return process1(0, record, n);
}
public static int process1(int i, int[] record, int n) {
if (i == n) {
return 1;
}
int res = 0;
for (int j = 0; j < n; j++) {
if (isValid(record, i, j)) {
record[i] = j;
res += process1(i + 1, record, n);
}
}
return res;
}
public static boolean isValid(int[] record, int i, int j) {
for (int k = 0; k < i; k++) {
if (j == record[k] || Math.abs(record[k] - j) == Math.abs(i - k)) {
return false;
}
}
return true;
}
public static int num2(int n) {
if (n < 1 || n > 32) {
return 0;
}
int upperLim = n == 32 ? -1 : (1 << n) - 1;
return process2(upperLim, 0, 0, 0);
}
public static int process2(int upperLim, int colLim, int leftDiaLim,
int rightDiaLim) {
if (colLim == upperLim) {
return 1;
}
int pos = 0;
int mostRightOne = 0;
pos = upperLim & (~(colLim | leftDiaLim | rightDiaLim));
int res = 0;
while (pos != 0) {
mostRightOne = pos & (~pos + 1);
pos = pos - mostRightOne;
res += process2(upperLim, colLim | mostRightOne,
(leftDiaLim | mostRightOne) << 1,
(rightDiaLim | mostRightOne) >>> 1);
}
return res;
}
public static void main(String[] args) {
int n = 32;
long start = System.currentTimeMillis();
System.out.println(num2(n));
long end = System.currentTimeMillis();
System.out.println("cost time: " + (end - start) + "ms");
start = System.currentTimeMillis();
System.out.println(num1(n));
end = System.currentTimeMillis();
System.out.println("cost time: " + (end - start) + "ms");
}
}
4.4马拉车——字符串神级算法
Manacher’s Algorithm 马拉车算法操作及原理
package advanced_001;
public class Code_Manacher {
public static char[] manacherString(String str) {
char[] charArr = str.toCharArray();
char[] res = new char[str.length() * 2 + 1];
int index = 0;
for (int i = 0; i != res.length; i++) {
res[i] = (i & 1) == 0 ? '#' : charArr[index++];
}
return res;
}
public static int maxLcpsLength(String str) {
if (str == null || str.length() == 0) {
return 0;
}
char[] charArr = manacherString(str);
int[] pArr = new int[charArr.length];
int C = -1;
int R = -1;
int max = Integer.MIN_VALUE;
for (int i = 0; i != charArr.length; i++) {
pArr[i] = R > i ? Math.min(pArr[2 * C - i], R - i) : 1;
while (i + pArr[i] < charArr.length && i - pArr[i] > -1) {
if (charArr[i + pArr[i]] == charArr[i - pArr[i]])
pArr[i]++;
else {
break;
}
}
if (i + pArr[i] > R) {
R = i + pArr[i];
C = i;
}
max = Math.max(max, pArr[i]);
}
return max - 1;
}
public static void main(String[] args) {
String str1 = "abc1234321ab";
System.out.println(maxLcpsLength(str1));
}
}
问题:查找一个字符串的 最长回文子串
首先叙述什么是回文子串:回文:就是对称的字符串,或者说是正反一样的
小问题一:请问,子串和子序列一样么?请思考一下再往下看
当然,不一样。子序列可以不连续,子串必须连续。
举个例子,”123”的子串包括1,2,3,12,23,123(一个字符串本身是自己的最长子串),而它的子序列是任意选出元素组成,他的子序列有1,2,3,12,13,23,123,””,空其实也算,但是本文主要是想叙述回文,没意义。
小问题二:长度为n的字符串有多少个子串?多少个子序列?
子序列,每个元素都可以选或者不选,所以有2的n次方个子序列(包括空)
子串:以一位置开头,有n个子串,以二位置开头,有n-1个子串,以此类推,我们发现,这是一个等差数列,而等差序列求和,有n*(n+1)/2个子串(不包括空)。
(这里有一个思想需要注意,遇到等差数列求和,基本都是o(n^2)级别的)
4.4一、分析枚举的效率
好,我们来分析一下暴力枚举的时间复杂度,上文已经提到过,一个字符串的所有子串,数量是o(n^2)级别,所以光是枚举出所有情况时间就是o(n^2),每一种情况,你要判断他是不是回文的话,还需要o(n),情况数和每种情况的时间,应该乘起来,也就是说,枚举时间要o(n^3),效率太低。
4.4二、初步优化
思路:我们知道,回文全是对称的,每个回文串都会有自己的对称轴,而两边都对称。我们如果从对称轴开始, 向两边阔,如果总相等,就是回文,扩到两边不相等的时候,以这个对称轴向两边扩的最长回文串就找到了。
举例:1 2 1 2 1 2 1 1 1
我们用每一个元素作为对称轴,向两边扩
0位置,左边没东西,只有自己;
1位置,判断左边右边是否相等,1=1所以接着扩,然后左边没了,所以以1位置为对称轴的最长回文长度就是3;
2位置,左右都是2,相等,继续,左右都是1,继续,左边没了,所以最长为5
3位置,左右开始扩,1=1,2=2,1=1,左边没了,所以长度是7
如此把每个对称轴扩一遍,最长的就是答案,对么?
你要是点头了。。。自己扇自己两下。
还有偶回文呢,,比如1221,123321.这是什么情况呢?这个对称轴不是一个具体的数,因为人家是偶回文。
问题三:怎么用对称轴向两边扩的方法找到偶回文?(容易操作的)
我们可以在元素间加上一些符号,比如/1/2/1/2/1/2/1/1/1/,这样我们再以每个元素为对称轴扩就没问题了,每个你加进去的符号都是一个可能的偶数回文对称轴,此题可解。。。因为我们没有错过任何一个可能的对称轴,不管是奇数回文还是偶数回文。
那么请问,加进去的符号,有什么要求么?是不是必须在原字符中没出现过?请思考
其实不需要的,大家想一下,不管怎么扩,原来的永远和原来的比较,加进去的永远和加进去的比较。(不举例子说明了,自己思考一下)
好,分析一波时间效率吧,对称轴数量为o(n)级别,每个对称轴向两边能扩多少?最多也就o(n)级别,一共长度才n; 所以n*n是o(n^2) (最大能扩的位置其实也是两个等差数列,这么理解也是o(n^2),用到刚讲的知识)
小结:
这种方法把原来的暴力枚举o(n^3)变成了o(n^2),大家想一想为什么这样更快呢?
我在kmp一文中就提到过,我们写出暴力枚举方法后应想一想自己做出了哪些重复计算,错过了哪些信息,然后进行优化。
看我们的暴力方法,如果按一般的顺序枚举,012345,012判断完,接着判断0123,我是没想到可以利用前面信息的方法,因为对称轴不一样啊,右边加了一个元素,左边没加。所以刚开始,老是想找一种方法,左右都加一个元素,这样就可以对上一次的信息加以利用了。
暴力为什么效率低?永远是因为重复计算,举个例子:12121211,下标从0开始,判断1212121是否为回文串的时候,其实21212和121等串也就判断出来了,但是我们并没有记下结果,当枚举到21212或者121时,我们依旧是重新尝试了一遍。(假设主串长度为n,对称轴越在中间,长度越小的子串,被重复尝试的越多。中间那些点甚至重复了n次左右,本来一次搞定的事)
还是这个例子,我换一个角度叙述一下,比较直观,如果从3号开始向两边扩,121,21212,最后扩到1212121,时间复杂度o(n),用枚举的方法要多少时间?如果主串长度为n,枚举尝试的子串长度为,3,5,7….n,等差数列,大家读到这里应该都知道了,等差数列求和,o(n^2)。
4.4三、Manacher原理
首先告诉大家,这个算法时间可以做到o(n),空间o(n).
好的,开始讲解这个神奇的算法。
首先明白两个概念:
最右回文边界R:挺好理解,就是目前发现的回文串能延伸到的最右端的位置(一个变量解决)
中心c:第一个取得最右回文边界的那个中心对称轴;举个例子:12121,二号元素可以扩到12121,三号元素 可以扩到121,右边界一样,我们的中心是二号元素,因为它第一个到达最右边界
当然,我们还需要一个数组p来记录每一个可能的对称轴最后扩到了哪里。
有了这么几个东西,我们就可以开始这个神奇的算法了。
为了容易理解,我分了四种情况,依次讲解:
假设遍历到位置i,如何操作呢
![超硬核!小白读了这篇文章,就能在算法圈混了[通俗易懂]](https://img-blog.csdn.net/201804042148055)
1)i>R:也就是说,i以及i右边,我们根本不知道是什么,因为从来没扩到那里。那没有任何优化,直接往右暴力 扩呗。
(下面我们做i关于c的对称点,i’)
2)i<R:,
三种情况:
i’的回文左边界在c回文左边界的里面
i’回文左边界在整体回文的外面
i’左边界和c左边界是一个元素
(怕你忘了概念,c是对称中心,c它当初扩到了R,R是目前扩到的最右的地方,现在咱们想以i为中心,看能扩到哪里。)
按原来o(n^2)的方法,直接向两边暴力扩。好的,魔性的优化来了。咱们为了好理解,分情况说。首先,大家应该知道的是,i’其实有人家自己的回文长度,我们用数组p记录了每个位置的情况,所以我们可以知道以i’为中心的回文串有多长。
2-1)i’的回文左边界在c回文的里面:看图
![超硬核!小白读了这篇文章,就能在算法圈混了[通俗易懂]](https://img-blog.csdn.net/20180404214835460)
我用这两个括号括起来的就是这两个点向两边扩到的位置,也就是i和i’的回文串,为什么敢确定i回文只有这么长?和i’一样?我们看c,其实这个图整体是一个回文串啊。
串内完全对称(1是括号左边相邻的元素,2是右括号右边相邻的元素,34同理),
由此得出结论1:
由整体回文可知,点2=点3,点1=点4
当初i’为什么没有继续扩下去?因为点1!=点2。
由此得出结论2:点1!=点2
因为前面两个结论,所以3!=4,所以i也就到这里就扩不动了。而34中间肯定是回文,因为整体回文,和12中间对称。
2-2)i’回文左边界在整体回文的外面了:看图
![超硬核!小白读了这篇文章,就能在算法圈混了[通俗易懂]](https://img-blog.csdn.net/20180404214906183)
这时,我们也可以直接确定i能扩到哪里,请听分析:
当初c的大回文,扩到R为什么就停了?因为点2!=点4———-结论1;
2’为2关于i’的对称点,当初i’左右为什么能继续扩呢?说明点2=点2’———结论2;
由c回文可知2’=3,由结论2可知点2=点2’,所以2=3;
但是由结论一可知,点2!=点4,所以推出3!=4,所以i扩到34为止了,34不等。
而34中间那一部分,因为c回文,和i’在内部的部分一样,是回文,所以34中间部分是回文。
2-3)最后一种当然是i’左边界和c左边界是一个元素
![超硬核!小白读了这篇文章,就能在算法圈混了[通俗易懂]](https://img-blog.csdn.net/2018040421493390)
点1!=点2,点2=点3,就只能推出这些,只知道34中间肯定是回文,外边的呢?不知道啊,因为不知道3和4相不相等,所以我们得出结论:点3点4内肯定是,继续暴力扩。
原理及操作叙述完毕,不知道我讲没讲明白。。。
4.4四、代码及复杂度分析
看代码大家是不是觉得不像o(n)?其实确实是的,来分析一波。。
首先,我们的i依次往下遍历,而R(最右边界)从来没有回退过吧?其实当我们的R到了最右边,就可以结束了。再不济i自己也能把R一个一个怼到最右
我们看情况一和四,R都是以此判断就向右一个,移动一次需要o(1)
我们看情况二和三,直接确定了p[i],根本不用扩,直接遍历下一个元素去了,每个元素o(1).
综上,由于i依次向右走,而R也没有回退过,最差也就是i和R都到了最右边,而让它们移动一次的代价都是o(1)的,所以总体o(n)
可能大家看代码依旧有点懵,其实就是code整合了一下,我们对于情况23,虽然知道了它肯定扩不动,但是我们还是给它一个起码是回文的范围,反正它扩一下就没扩动,不影响时间效率的。而情况四也一样,给它一个起码是回文,不用验证的区域,然后接着扩,四和二三的区别就是。二三我们已经心中有B树,它肯定扩不动了,而四确实需要接着尝试。
(要是写四种情况当然也可以。。但是我懒的写,太多了。便于理解分了四种情况解释,code整合后就是这样子)
我真的想象不到当初发明这个算法的人是怎么想到的,向他致敬。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/126303.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
