大家好,又见面了,我是你们的朋友全栈君。
实验一:鸢尾花数据集分类
一、问题描述
利用机器学习算法构建模型,根据鸢尾花的花萼和花瓣大小,区分鸢尾花的品种。实现一个基础的三分类问题。


二、数据集分析
- Iris 鸢尾花数据集内包含 3 种类别,分别为山鸢尾(Iris-setosa)、变色鸢尾(Iris-versicolor)和维吉尼亚鸢尾(Iris-virginica)。
- 数据集共 150 条记录,每类各 50 个数据,每条记录有花萼长度、花萼宽度、花瓣长度、花瓣宽度4项特征,通过这4个特征预测鸢尾花卉属于哪一品种。
- iris数据集包含在sklearn库当中,具体在sklearn\datasets\data文件夹下,文件名为iris.csv。
- 通常数据文件存储在\Python36\Lib\site-packages\sklearn\datasets\data\iris.csv。
- 打开iris.csv,数据格式如下:
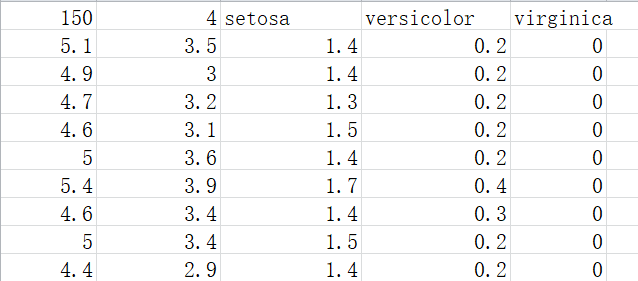
- 第一行数据意义为:
150:数据集中数据的总条数
4:特征值的类别数,即花萼长度、花萼宽度、花瓣长度、花瓣宽度。
setosa、versicolor、virginica:三种鸢尾花名 - 从第二行及以下数据的意义为:
第一列为花萼长度值
第二列为花萼宽度值
第三列为花瓣长度值
第四列为花瓣宽度值
第五列对应是种类(三类鸢尾花分别用0,1,2表示)
三、代码实现
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
iris_data = load_iris()
# 该函数返回一个Bunch对象,它直接继承自Dict类,与字典类似,由键值对组成。
# 可以使用bunch.keys(),bunch.values(),bunch.items()等方法。
print(type(iris_data))
# data里面是花萼长度、花萼宽度、花瓣长度、花瓣宽度的测量数据,格式为 NumPy数组
print(iris_data['data']) # 花的样本数据
print("花的样本数量:{}".format(iris_data['data'].shape))
print("花的前5个样本数据:{}".format(iris_data['data'][:5]))
# 0 代表 setosa, 1 代表 versicolor,2 代表 virginica
print(iris_data['target']) # 类别
print(iris_data['target_names']) # 花的品种
# 构造训练数据和测试数据
X_train,X_test,y_train,y_test = train_test_split(\
iris_data['data'],iris_data['target'],random_state=0)
print("训练样本数据的大小:{}".format(X_train.shape))
print("训练样本标签的大小:{}".format(y_train.shape))
print("测试样本数据的大小:{}".format(X_test.shape))
print("测试样本标签的大小:{}".format(y_test.shape))
# 构造KNN模型
knn = KNeighborsClassifier(n_neighbors=1)
# knn = KNeighborsClassifier(n_neighbors=3)
# 训练模型
knn.fit(X_train,y_train)
y_pred = knn.predict(X_test)
# 评估模型
print("模型精度:{:.2f}".format(np.mean(y_pred==y_test)))
print("模型精度:{:.2f}".format(knn.score(X_test,y_test)))
# 做出预测
X_new = np.array([[1.1,5.9,1.4,2.2]])
prediction = knn.predict(X_new)
print("预测的目标类别是:{}".format(prediction))
print("预测的目标类别花名是:{}".format(iris_data['target_names'][prediction]))
补充说明:
- 样本和特征:机器学习中每个个体叫做样本,其属性叫做特征。在本例中,每朵鸢尾花就是一个样本,每朵鸢尾花的花萼长度、宽度、花瓣长度、宽带就是特征。
- 训练数据和测试数据
-
训练数据:用于构建模型。
- 测试数据:用于评估模型性能。
- 利用scikit-learn中的train_test_split函数将原始数据集分为训练数据和测试数据,75%的数据用作训练集,25%用作测试集。
- scikit-learn中的数据通常用大写的X表示,标签用小写的y表示,f(X)= y, X是函数的输入,是一个二维矩阵,小写的y是输出的一维数组。
- 该函数需要设置random_state,给其赋一个值,当多次运行此段代码能够得到完全一样的结果。若不设置此参数则会随机选择一个种子,执行结果也会因此而不同了。虽然可以对random_state进行调参,但是调参后在训练集上表现好的模型未必在陌生训练集上表现好,所以一般会随便选取一个random_state的值作为参数。
- predict方法进行预测的时候,该函数的输入数据必须是二维数组,因此首先将建立的一维数组转换为二维数组的一行。
- KNN对象的score方法用于计算测试集的精度。
-
四、KNN算法
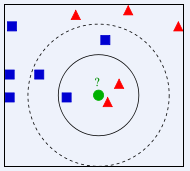 KNN,全称为K Nearest Neighbors,又叫K最近邻算法,是机器学习算法中最简单的分类算法之一。其核心思想是,如果一个样本在特征空间中的K个最相邻的样本中的大多数属于某一类别,则该样本也属于这个类别,并具有这个类别上样本的特性。K就是最近的样本的个数,其取值至关重要,关系最终的分类结果。
KNN,全称为K Nearest Neighbors,又叫K最近邻算法,是机器学习算法中最简单的分类算法之一。其核心思想是,如果一个样本在特征空间中的K个最相邻的样本中的大多数属于某一类别,则该样本也属于这个类别,并具有这个类别上样本的特性。K就是最近的样本的个数,其取值至关重要,关系最终的分类结果。
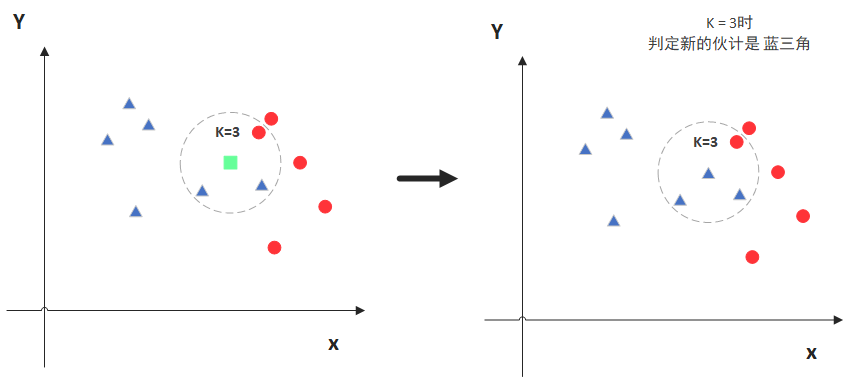
如上图所示,绿色的点为要进行分类的点。如果K=3,与之最近的三个点中,蓝色三角形多,那么绿色的点被归为蓝色三角形一类;如果K=5,与之最近的五个点中,红色圆形多,那么绿色的点被归为红色圆形一类。从此可以得出,K值的选取将影响分类结果。
另外一个重要的因素是点距离的计算。常见的距离度量方式有曼哈顿距离、欧式距离等等。通常KNN采用欧式距离。以二维平面为例,二维空间中两个点的欧式距离计算公示如下:
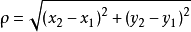
将其拓展到多维空间,公示则变为如下:
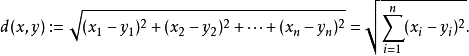
KNN简单的将预测点与所有点距离进行计算后排序,选出前面K个值查看类别,类别多的自然归类。
版权声明:本文内容由互联网用户自发贡献,该文观点仅代表作者本人。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如发现本站有涉嫌侵权/违法违规的内容, 请发送邮件至 举报,一经查实,本站将立刻删除。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/125624.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
