大家好,又见面了,我是你们的朋友全栈君。
文章目录
一、Quartz的核心概念
1.任务job
job就是想要实现的任务类,每一个job必须实现job接口,且实现接口中的 excute()方法。
2.触发器Trigger
Trigger为你执行任务的触发器,可以设置特定时间执行该任务
Trigger主要包含SimpleTrigger和CronTrigger两种
3.调度器Scheduler
Scheduler为任务的调度器,它会将任务job及触发器Trigger整合起来,负责基于Trigger设定的时间来执行job
4.Quartz的体系结构
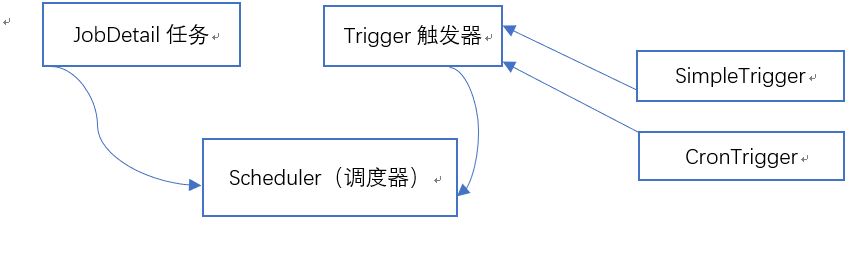

5.Quartz的核心组件
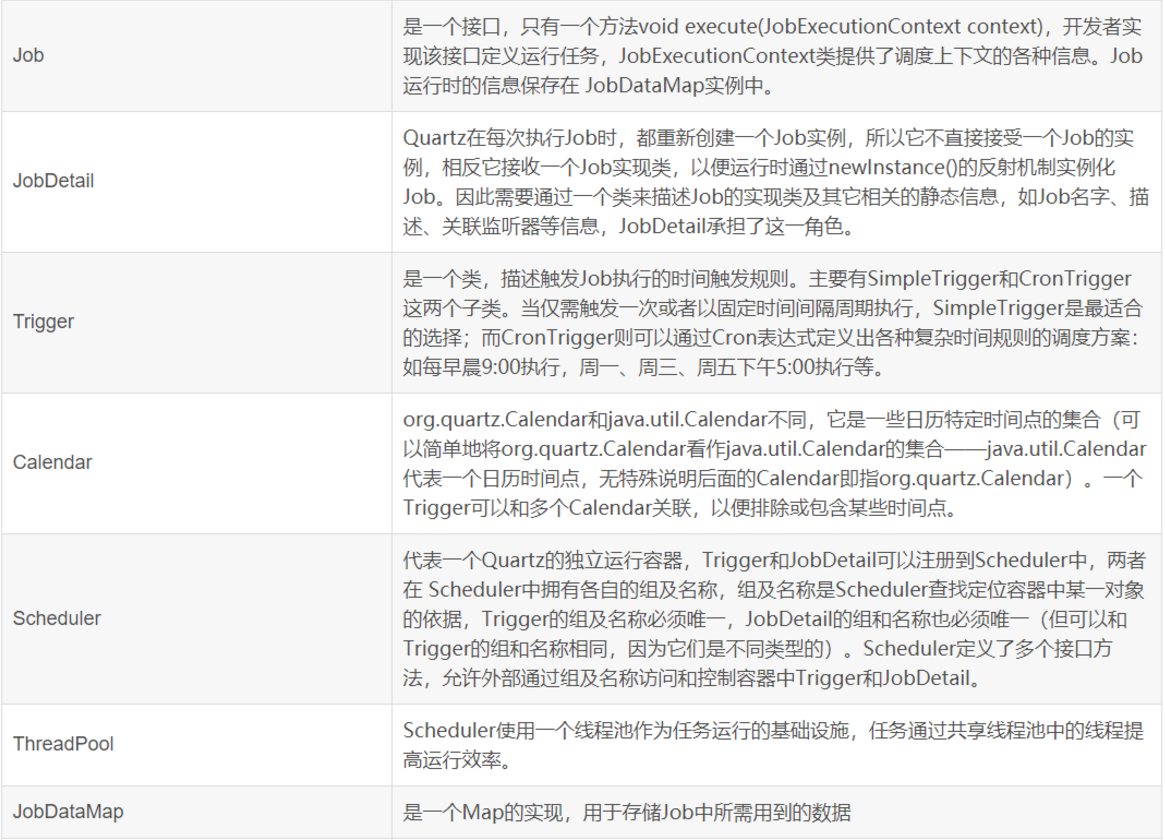
二、Quartz的基本功能
pom.xml文件中添加quartz相关jar包的坐标
<dependency>
<groupId>org.quartz-scheduler</groupId>
<artifactId>quartz</artifactId>
<version>2.3.0</version>
</dependency>
<dependency>
<groupId>org.quartz-scheduler</groupId>
<artifactId>quartz-jobs</artifactId>
<version>2.2.1</version>
</dependency>
1.首先创建一个Myjob工作类并实现Job接口,并重写里面的execute方法,为了直观的观察定时任务,我们在里面输出当前时间
/** * Created by yan on 2019/1/27. */
public class MyJob implements Job {
@Override
public void execute(JobExecutionContext context) throws JobExecutionException {
System.out.print("quartz:I coming--------");
System.out.println((new SimpleDateFormat("yyyy-MM-dd HH-mm-ss")).format(new Date()));
}
}
2.创建一个MyScheduler
/** * Created by yan on 2019/1/27. */
public class MyScheduler {
public static void main(String[] args) {
//创建一个JobDetail实例
JobDetail jobDetail = JobBuilder.newJob(MyJob.class)
.withIdentity("jobDetail","group1")//jobdetail的唯一标示
.build();
//创建一个Trigger实例
Trigger trigger = TriggerBuilder.newTrigger().withIdentity("trigger","group1")//Trigger的唯一标识
.startNow() //简单的定时器 每2秒钟执行一次 执行到永远
.withSchedule(SimpleScheduleBuilder.simpleSchedule().withIntervalInSeconds(2).repeatForever())
.build();
//创建Scheduler实例
//通过SchedulerFactory创建
SchedulerFactory schedulerFactory = new StdSchedulerFactory();
try {
Scheduler scheduler = schedulerFactory.getScheduler();
//使用scheduler将jobDetail和trigger结合起来
scheduler.scheduleJob(jobDetail,trigger);
//开始
scheduler.start();
} catch (SchedulerException e) {
e.printStackTrace();
}
}
}
OutPut:
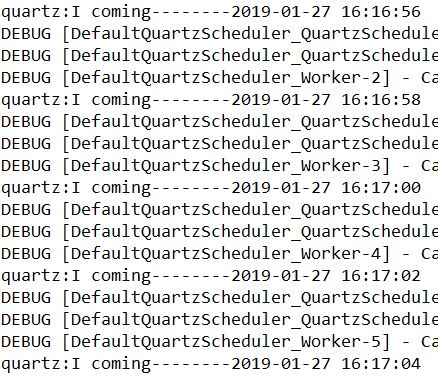
Scheduler实例创建的两种方式
//通过SchedulerFactory创建
SchedulerFactory schedulerFactory = new StdSchedulerFactory();
scheduler = schedulerFactory.getScheduler();
//通过StdSchedulerFactory创建
Scheduler scheduler = StdSchedulerFactory.getDefaultScheduler();//类名.方法(static)
JobDataMap 介绍
JobDataMap介绍
1).
- 在进行任务调度时,JobDataMap存储在JobExecutionContext中 ,非常方便获取。
- JobDataMap可以用来装载任何可序列化的数据对象,当job实例对象被执行时这些参数对象会传递给它。
- JobDataMap实现了JDK的Map接口,并且添加了非常方便的方法用来存取基本数据类型。
我们从底层代码中查看JobDataMap Implement Map



JobDatamap Implement Map 确认无误
2).
Job实现类中添加setter方法对应JobDataMap的键值,Quartz框架默认的JobFactory实现类在初始化job实例对象时会
自动地调用这些setter方法。
3).
如果遇到同名的key,Trigger中的.usingJobData(“message”, “新年快乐”)
会覆盖
JobDetail的.usingJobData(“message”, “新年不快乐”)。
//jobDetail中添加JobDataMap
.usingJobData("message","祝大家新年快乐")
//trigger中添加JobDataMap
.usingJobData("message","祝大家新年长胖20斤")
//MyJob实现类中 private message ,并给set方法
private String message;
public void setMessage(String message) {
this.message = message;
}
System.out.println(message);
运行OutPut:

有状态Job和无状态Job
有状态的Job可以理解为多次Job调用期间可以持有一些状态信息,这些状态信息存储在JobDataMap中,
而默认的无状态job每次调用时都会创建一个新的JobDataMap。
//jobDetail中添加JobDataMap
.usingJobData("count",1)
//MyJob中private count 并给set方法
private Integer count;
public void setCount(Integer count) {
this.count = count;
}
count++;
System.out.println(count);
context.getJobDetail().getJobDataMap().put("count",count);
OutPut:
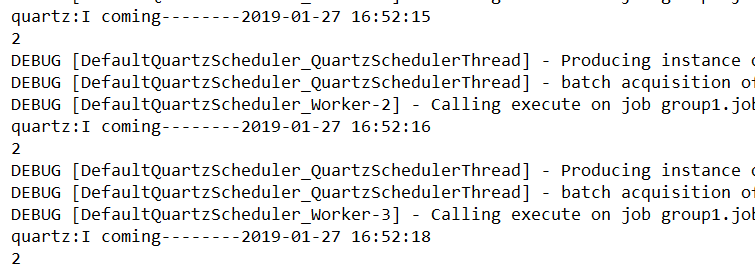
默认给定无状态的Job,可以通过注解的方式改变Job的状态为有状态的Job
//在MyJob类上添加
@PersistJobDataAfterExecution //可以将无状态的job转变为有状态的job
Trigger触发器
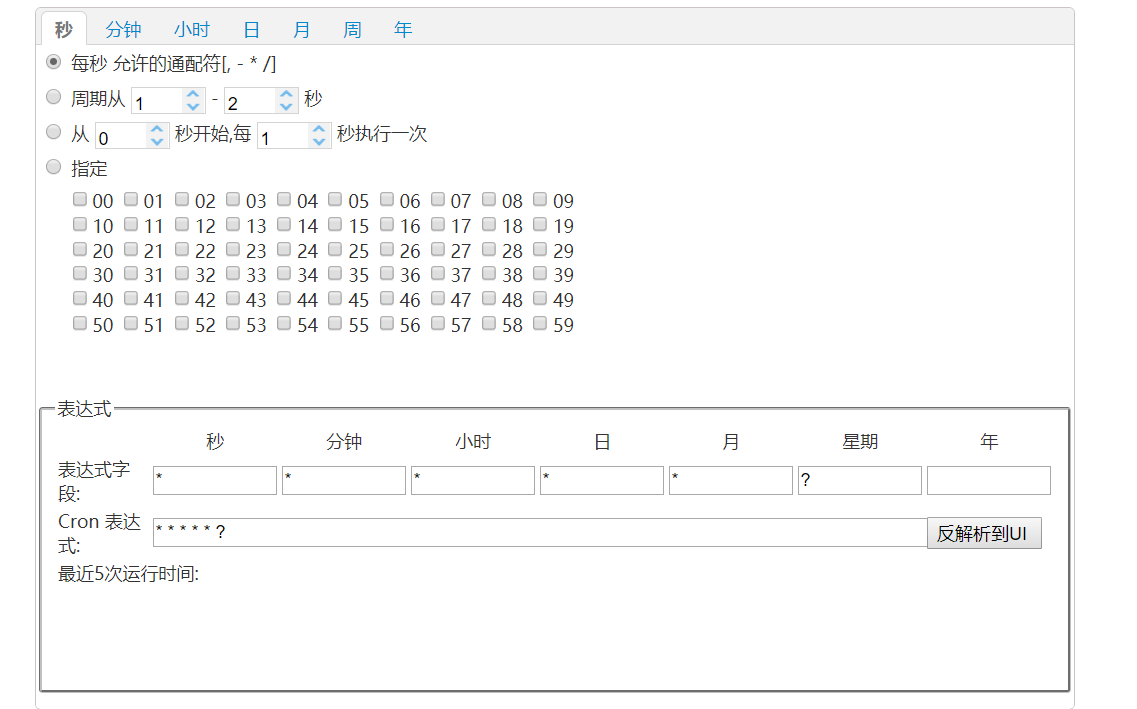
上面的代码我们使用的是SimpleTrigger(简单的触发器),这种触发器只能完成一定频率的触发任务(即:每隔多长时间触发),这显然不能满足我们对定时任务的需求,因此CronTrigger便横空出世
如果你需要像日历那样按日程来触发任务,而不是像SimpleTrigger 那样每隔特定的间隔时间触发,CronTriggers通常比SimpleTrigger更有用,因为它是基于日历的作业调度器。
使用CronTrigger,你可以指定诸如“每隔周五的晚上8:00”,或者“每个工作日的9:30”或者“从每个周一、周三、周五的上午9:00到上午10:00之间每隔五分钟”这样日程安排来触发。甚至,象SimpleTrigger一样,CronTrigger也有一个startTime以指定日程从什么时候开始,也有一个(可选的)endTime以指定何时日程不再继续。

当然这些表达式是不需要死记硬背的,我们可以通过网上的Cron表达式生成器进行转换
Cron表达式转换
//SimpleTrigger的创建
.withSchedule(SimpleScheduleBuilder.simpleSchedule().withIntervalInSeconds(2).repeatForever()
//CronTrigger的创建
.withSchedule(CronScheduleBuilder.cronSchedule("0 13 17 ? 1 ? *"))
Quartz监听
Quartz的监听器用于当任务调度中你所关注事件发生时,能够及时获取这一事件的通知。类似于任务执行过程中的邮件、短信类的提醒。Quartz监听器主要有JobListener、TriggerListener、SchedulerListener三种,顾名思义,分别表示任务、触发器、调度器对应的监听器。三者的使用方法类似,在开始介绍三种监听器之前,需要明确两个概念:全局监听器与非全局监听器,二者的区别在于:
全局监听器能够接收到所有的Job/Trigger的事件通知,
而非全局监听器只能接收到在其上注册的Job或Trigger的事件,不在其上注册的Job或Trigger则不会进行监听。
1.JobListener
public class MyJobListener implements JobListener {
//获取listener的名称
@Override
public String getName() {
String name = getClass().getSimpleName();
return name;
}
//Scheduler在JobDetail将要被执行时调用这个方法
@Override
public void jobToBeExecuted(JobExecutionContext context) {
String jobName = context.getJobDetail().getKey().getName();
System.out.println("Job的名称是:"+jobName+"Scheduler在JobDetail将要被执行时调用这个方法");
}
//Scheduler在JobDetail即将被执行,但又被TriggerListerner否决时会调用该方法
@Override
public void jobExecutionVetoed(JobExecutionContext context) {
String jobName = context.getJobDetail().getKey().getName();
System.out.println("Job的名称是:"+jobName+"Scheduler在JobDetail即将被执行,但又被TriggerListerner否决时会调用该方法");
}
//Scheduler在JobDetail被执行之后调用这个方法
@Override
public void jobWasExecuted(JobExecutionContext context, JobExecutionException jobException) {
String jobName = context.getJobDetail().getKey().getName();
System.out.println("Job的名称是:"+jobName+"Scheduler在JobDetail被执行之后调用这个方法");
}
}
2.TriggerListener
public class MyTriggerListener implements TriggerListener {
private String name;
public MyTriggerListener(String name) {
this.name = name;
}
@Override
public String getName() {
return name;
}
//triggerFired方法:当与监听器相关联的Trigger被触发,Job上的execute()方法将被执行时,Scheduler就调用该方法。
@Override
public void triggerFired(Trigger trigger, JobExecutionContext context) {
String triggerName = trigger.getKey().getName();
System.out.println(triggerName + " 被触发");
}
//vetoJobExecution方法:在 Trigger 触发后,Job 将要被执行时由 Scheduler
// 调用这个方法。TriggerListener 给了一个选择去否决 Job 的执行。
// 假如这个方法返回 true,这个 Job 将不会为此次 Trigger 触发而得到执行。
@Override
public boolean vetoJobExecution(Trigger trigger, JobExecutionContext context) {
String triggerName = trigger.getKey().getName();
System.out.println(triggerName + " 没有被触发");
return true; // true:表示不会执行Job的方法
}
//triggerMisfired方法:Scheduler 调用这个方法是在 Trigger 错过触发时。
// 你应该关注此方法中持续时间长的逻辑:在出现许多错过触发的 Trigger 时,长逻辑会导致骨牌效应。你应当保持这上方法尽量的小。
@Override
public void triggerMisfired(Trigger trigger) {
String triggerName = trigger.getKey().getName();
System.out.println(triggerName + " 错过触发");
}
//triggerComplete方法:Trigger 被触发并且完成了 Job 的执行时,Scheduler 调用这个方法。
@Override
public void triggerComplete(Trigger trigger, JobExecutionContext context, Trigger.CompletedExecutionInstruction triggerInstructionCode) {
String triggerName = trigger.getKey().getName();
System.out.println(triggerName + " 完成之后触发");
}
}
3.SchedulerListener(重写的方法很多,我也不清楚怎么使用)
1) jobScheduled方法:用于部署JobDetail时调用
2) jobUnscheduled方法:用于卸载JobDetail时调用
3) triggerFinalized方法:当一个 Trigger 来到了再也不会触发的状态时调用这个方法。除非这个 Job 已设置成了持久性,否则它就会从 Scheduler 中移除。
4) triggersPaused方法:Scheduler 调用这个方法是发生在一个 Trigger 或 Trigger 组被暂停时。假如是 Trigger 组的话,triggerName 参数将为 null。
5) triggersResumed方法:Scheduler 调用这个方法是发生成一个 Trigger 或 Trigger 组从暂停中恢复时。假如是 Trigger 组的话,假如是 Trigger 组的话,triggerName 参数将为 null。参数将为 null。
6) jobsPaused方法:当一个或一组 JobDetail 暂停时调用这个方法。
7) jobsResumed方法:当一个或一组 Job 从暂停上恢复时调用这个方法。假如是一个 Job 组,jobName 参数将为 null。
8) schedulerError方法:在 Scheduler 的正常运行期间产生一个严重错误时调用这个方法。
9) schedulerStarted方法:当Scheduler 开启时,调用该方法
10) schedulerInStandbyMode方法: 当Scheduler处于StandBy模式时,调用该方法
11) schedulerShutdown方法:当Scheduler停止时,调用该方法
12) schedulingDataCleared方法:当Scheduler中的数据被清除时,调用该方法。
public class MySchedulerListener implements SchedulerListener {
@Override
public void jobScheduled(Trigger trigger) {
}
@Override
public void jobUnscheduled(TriggerKey triggerKey) {
}
@Override
public void triggerFinalized(Trigger trigger) {
}
@Override
public void triggerPaused(TriggerKey triggerKey) {
}
@Override
public void triggersPaused(String triggerGroup) {
}
@Override
public void triggerResumed(TriggerKey triggerKey) {
}
@Override
public void triggersResumed(String triggerGroup) {
}
@Override
public void jobAdded(JobDetail jobDetail) {
}
@Override
public void jobDeleted(JobKey jobKey) {
}
@Override
public void jobPaused(JobKey jobKey) {
}
@Override
public void jobsPaused(String jobGroup) {
}
@Override
public void jobResumed(JobKey jobKey) {
}
@Override
public void jobsResumed(String jobGroup) {
}
@Override
public void schedulerError(String msg, SchedulerException cause) {
}
@Override
public void schedulerInStandbyMode() {
}
@Override
public void schedulerStarted() {
}
@Override
public void schedulerStarting() {
}
@Override
public void schedulerShutdown() {
}
@Override
public void schedulerShuttingdown() {
}
@Override
public void schedulingDataCleared() {
}
}
Quartz.properties
默认路径:quartz-2.3.0中的org.quartz中的quartz.properties
我们也可以在项目的资源下添加quartz.properties文件,去覆盖底层的配置文件。
组成部分
- 调度器属性
org.quartz.scheduler.instanceName属性用来区分特定的调度器实例,可以按照功能用途来给调度器起名。
org.quartz.scheduler.instanceId属性和前者一样,也允许任何字符串,但这个值必须在所有调度器实例中是唯一的,尤其是在一个集群环境中,作为集群的唯一key。假如你想Quartz帮你生成这个值的话,可以设置为AUTO。
- 线程池属性
threadCount
处理Job的线程个数,至少为1,但最多的话最好不要超过100,在多数机器上设置该值超过100的话就会显得相当不实用了,特别是在你的 Job 执行时间较长的情况下
threadPriority
线程的优先级,优先级别高的线程比级别低的线程优先得到执行。最小为1,最大为10,默认为5
org.quartz.threadPool.class
#===============================================================
#Configure Main Scheduler Properties 调度器属性
#===============================================================
#调度器的实例名
org.quartz.scheduler.instanceName = QuartzScheduler
#调度器的实例ID,大多数情况设置为auto即可
org.quartz.scheduler.instanceId = AUTO
====================================
#Configure JobStore 作业存储设置
#===============================================================
#要使 Job 存储在内存中需通过设置 org.quartz.jobStrore.class 属性为 org.quartz.simpl.RAMJobStore
org.quartz.jobStore.class = org.quartz.simpl.RAMJobStore
#===============================================================
#Configure Plugins 插件配置
#===============================================================
org.quartz.plugin.jobInitializer.class =
org.quartz.plugins.xml.JobInitializationPlugin
org.quartz.plugin.jobInitializer.overWriteExistingJobs = true
org.quartz.plugin.jobInitializer.failOnFileNotFound = true
org.quartz.plugin.jobInitializer.validating=false
#===============================================================
#Configure ThreadPool 线程池属性
#===============================================================
#处理Job的线程个数,至少为1,但最多的话最好不要超过100,在多数机器上设置该值超过100的话就会显得相当不实用了,特别是在你的 Job 执行时间较长的情况下
org.quartz.threadPool.threadCount = 5
#线程的优先级,优先级别高的线程比级别低的线程优先得到执行。最小为1,最大为10,默认为5
org.quartz.threadPool.threadPriority = 5
#一个实现了 org.quartz.spi.ThreadPool 接口的类,Quartz 自带的线程池实现类是 org.quartz.smpl.SimpleThreadPool
org.quartz.threadPool.class = org.quartz.simpl.SimpleThreadPool
#===========================
基本功能测试完成,下面可以学习一下spring整合quartz
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/125582.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
