大家好,又见面了,我是你们的朋友全栈君。
作者:Gidi Shperber
在本文中,你将学习什么是doc2vec,它是如何构建的,它与word2vec有什么关系,你能用它做什么,并且没有复杂的数学公式。
介绍
文本文档的量化表示在机器学习中是一项具有挑战性的任务。很多应用都需要将文档量化处理,例如:文档检索,web搜索,垃圾邮件过滤,主题建模等。
但是,要做到这一点好的方法不多。很多方法使用众所周知但简单化的词袋方法(BOW),但结果将大多是很一般,因为BOW在很多方面没有考虑周全,例如没有考虑单词排序。
潜在Dirichlet分配(LDA)也就是主题建模(从文本中提取主题/关键字)的常用技术,但它很难调整,结果很难评估。
在这篇文章中,我将回顾doc2vec方法,这是一个由Mikilov和Le在2014年提出的概念,我们会在本文中多次提及。值得一提的是,Mikilov也是word2vec的作者之一。
Doc2vec是一个非常好的技术。它易于使用,效果很好,而且从名称上可以理解,很大程度上基于word2vec。所以我们首先简单介绍一下word2vec。
word2vec
word2vec是一个众所周知的概念,用于将单词转换成用户向量来表示。
关于word2vec有很多关于word2vec的好教程,比如这个和还有这个,但是如果描述doc2vec时不涉word2vec的话会忽视很多东西,所以在这里我会给word2vec做个简介。
一般来说,当你想用单词构建一些模型时,只需对单词进行标记或做独热编码,这是一种合理的方法。然而,当使用这种编码时,词语的意义将会失去。例如,如果我们将“巴黎”编码为id_4,将“法国”编码为id_6,将“权力”编码为id_8,则“法国”将与“巴黎”具有“法国”和“权利”相同的关系。但事实上我们更希望在词义上“法国”和“巴黎”比“法国”和“权力”更接近。
word2vec,在本文中于2013年提出,旨在为您提供:每个单词的向量化表示,能够捕获上述关系。这是机器学习中更广泛概念的一部分 – 特征向量。
这种表示形式包含了单词之间的不同关系,如同义词,反义词或类比,如下所示:
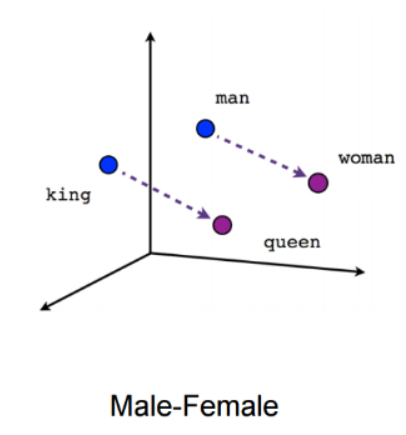

图1.国外与王后就像于男人与女人,如果创建word2vec时不考虑这种关系,那是错误的 。
Word2vec 算法
word2vec有2种算法:连续词袋模型(CBOW)和Skip-Gram模型。
连续词袋模型(CBOW)
连续词袋模型会在当前单词的周围创建一个滑动窗口,从“上下文” -也就是用它周围的单词预测当前词。 每个单词都表示为一个特征向量。 经过训练以后后,这些向量就成为单词向量。
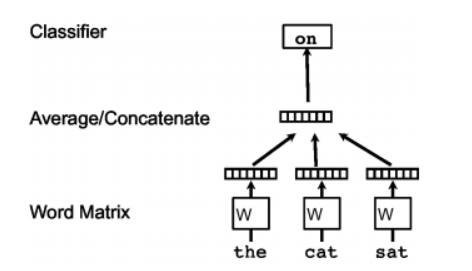
图2.CBOW算法草图:用用周围的(上下文)单词“the”“cat”“sat”来预测当前的单词“on”
正如前面所说的,相似单词的向量以不同的距离相互靠近,而且它们还包含了数值上的关系,例如来自上方的king-queen = man。
Skip gram
第二种算法(在同一篇论文中描述,并且在这里很好地解释)实际上与CBOW相反:我们不是每次都预测一个单词,而是使用1个单词来预测周围的单词。 Skip gram比CBOW慢得多,但是对于不经常使用的单词,它被认为更准确。

图2.Skip-gram模型,用一个词来预测它周围的词
Doc2vec
在了解word2vec之后,将更容易理解doc2vec的工作原理。
如上所述,doc2vec的目标是创建文档的向量化表示,而不管其长度如何。 但与单词不同的是,文档并没有单词之间的逻辑结构,因此必须找到另一种方法。
Mikilov和Le使用的概念很简单但很聪明:他们使用了word2vec模型,并添加了另一个向量(下面的段落ID),如下所示:
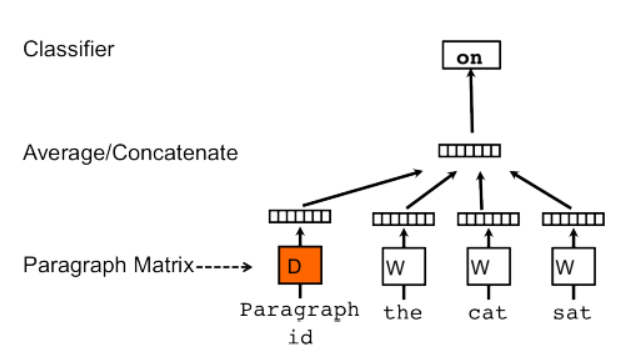
图3. PV-DM 模型
如果您对上面的草图感到熟悉,那是因为它是CBOW模型的一个小扩展。 它不是仅是使用一些单词来预测下一个单词,我们还添加了另一个特征向量,即文档Id。
因此,当训练单词向量W时,也训练文档向量D,并且在训练结束时,它包含了文档的向量化表示。
上面的模型称为段落向量的分布式记忆的版本(PV-DM)。 它充当记忆器,它能记住当前上下文中缺少的内容 – 或者段落的主题。 虽然单词向量表示单词的概念,但文档向量旨在表示文档的概念。
如在doc2vec中,另一种类似于skip-gram的算法,段落向量的分布式词袋版本(PV-DBOW)
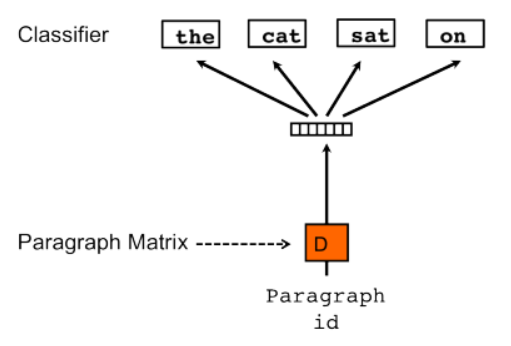
图4.PV-DBOW模型
该算法实际上更快(与word2vec相反)并且消耗更少的内存,因为不需要保存词向量。
在论文中,作者建议使用两种算法的组合,尽管PV-DM模型是优越的,并且通常会自己达到最优的结果。
doc2vec模型的使用方式:对于训练,它需要一组文档。 为每个单词生成词向量W,并为每个文档生成文档向量D. 该模型还训练softmax隐藏层的权重。 在推理阶段,可以呈现新文档,并且固定所有权重以计算文档向量。
评估模型和一些想法
这种无监督模型的问题在于,他们没有接受过训练来完成他们想要的任务(因为没有标签)。 例如,训练word2vec以完成语料库中的周围单词记忆,但它常用于估计单词之间的相似性或相互关系。 因此,测量这些算法的性能可能具有挑战性。 我们已经看到了“国王与王后就像男人和女人”的例子,但我们想要形成一种严格的方式来评估机器学习模型。
因此,在训练这些算法时,我们应该注意相关的指标。 word2vec的一个可能的度量标准是对上述示例的概括,并且被称为类比推理。 它包含许多类比组合,这里有一些:
- happy happily — furious furiously
- immediate immediately — infrequent infrequently
- slowing slowed — sleeping slept
- spending spent — striking struck
我们要做的就是在计算这些可类比的单词时要让这些单词对之间的距离非常接近。
数据集可在http://download.tensorflow.org/data/questions-words.txt 获得。
论文中描述在2个任务中测试了Doc2vec:第一个是情感分析任务,第二个类似于上面的类比推理任务。
这是文章中的3段。 这些段落的数据集用于比较模型。 很容易看出哪两段内容应该更接近:

这个数据集(据我所知没有共享)它用于比较一些模型,而doc2vec的效果是最好的:

现实生活中的应用 – ScaleAbout
我的一个客户ScaleAbout使用机器学习方法将YouTube视频“影响者”与文章内容进行匹配。 Doc2vec似乎是这种匹配的比较好方法。
以下是ScaleAbout所做的一个示例,它根据文章的内容来推荐视频,如在一篇文章描述如何制作树桩灯,那么你便可以在文章在底部看到4个关于木工工作的相关视频:
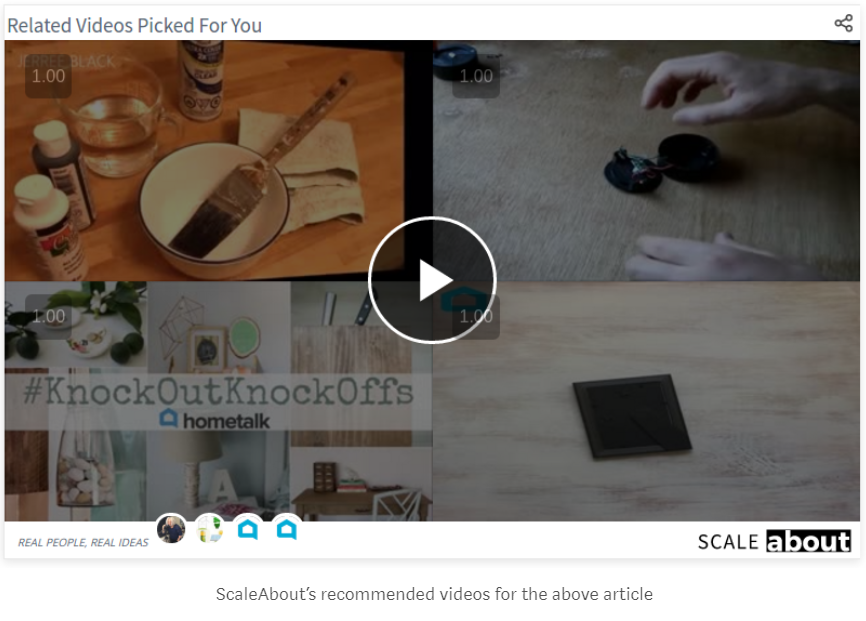
ScaleAbout的模型使用打标机制来为视频和文章(“主题建模”)打上标签然后测量标签之间的距离。
ScaleAbout有一些文本语料库,与其客户的主题相关。 例如,对于诸如文章的发布者,存在关于“DIY”的100K左右的手动打标的文档。 每篇文章有17种可能的标签(例如,“家居装饰”,“园艺”,“重塑和翻新”等)。 对于这个实验,我们决定尝试使用doc2vec和其他一些模型来预测标签。
ScaleAbout目前的最佳模型是一个卷积神经网络,在word2vec之上,在预测文档的标签时达到了大约70%的准确率。
Doc2vec模型本身是一种无监督的方法,所以应该稍微调整一下“参与”这个比赛。 幸运的是,在大多数情况下,我们可以使用一些技巧:如果你还记得,在图3中我们添加了另一个文档向量,它对每个文档都是唯一的。 如果你考虑一下,可以添加更多的向量,这些向量不必是唯一的:例如,如果我们有文档的标签(就像我们实际拥有的那样),我们可以添加它们,并将它们表示为向量。
此外,它们不必是唯一的。 这样,我们可以将17个标签中的一个添加到唯一文档标签中,并为它们创建doc2vec表示! 如:
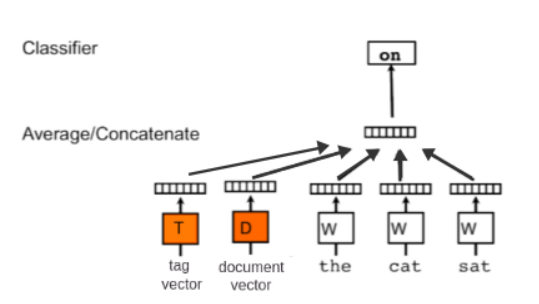
图5.使用tag向量的doc2vec 模型
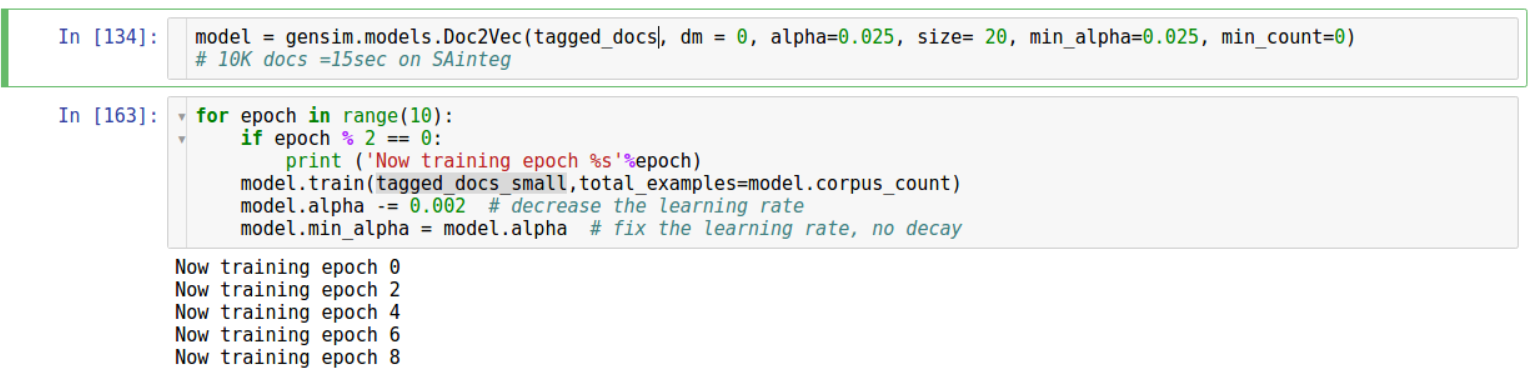
我们将使用doc2vec的gensim实现。 这是gensim TaggedDocument对象的样子:

使用gensim doc2vec非常简单。 与往常一样,模型应该初始化,训练几个周期:
然后我们可以检查每个唯一文档与每个标签的相似度,就像这样:

它将预测与文档具有最高相似度的标签。
使用这种方法,我们只训练了100K文章中的10K文档,我们达到了74%的准确率,比以前更好。
总结
我们已经看到,通过一些调整,我们可以从已经非常有用的word2vec模型中获得更多。 这很好,因为如前所述,在我看来,标记和匹配文档的表示还有很长的路要走。
此外,这表明这是一个很好的例子,说明机器学习模型如何在他们训练的特定任务之外封装更多的能力。 这可以在深度CNN中看到,其被训练用于对象分类,但是也可以用于语义分割或聚类图像。
总而言之,如果您有一些与文档相关的任务 – 这对您来说可能是一个很好的模型!

发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/125541.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
