大家好,又见面了,我是你们的朋友全栈君。
KS(Kolmogorov-Smirnov):KS用于模型风险区分能力进行评估, 指标衡量的是好坏样本累计分部之间的差值。
好坏样本累计差异越大,KS指标越大,那么模型的风险区分能力越强。
k s = m a x ( C u m . B i B a d t o t a l − C u m . G i G o o d t o t a l ) ks = max(\frac{Cum. B_i}{Bad_{total}} – \frac{Cum.G_i}{Good_{total}}) ks=max(BadtotalCum.Bi−GoodtotalCum.Gi)
上面是ks的简单介绍,相信大家看了这几句话和一个公式,肯定还是不懂ks到底是个什么。我也是研究了一下,终于搞清楚了ks的具体计算方式。搞清楚了计算方式后,ks的含义自然就清楚了。
下面我会详细讲解实现方法,相信如果你看完本文章,肯定可以理解ks。以下内容均为个人纯手打,难免有些疏漏,如有错误,请大家指出。
本文会介绍两种计算ks的方法:
第一种是我自己手动写代码实现的,可以帮助你理解ks含义;
第二种是sklearn模块里面的roc_curve函数计算,通过第一种方法理解了ks后,实际应用中使用第二种方法,更方便。
ks的计算流程
话不多说,先看代码,后面会解释代码,顺便解释清楚ks含义。
import numpy as np
import pandas as pd
def ks(df, y_true, y_pre, num=10, good=0, bad=1):
# 1.将数据从小到大平均分成num组
df_ks = df.sort_values(y_pre).reset_index(drop=True)
df_ks['rank'] = np.floor((df_ks.index / len(df_ks) * num) + 1)
df_ks['set_1'] = 1
# 2.统计结果
result_ks = pd.DataFrame()
result_ks['group_sum'] = df_ks.groupby('rank')['set_1'].sum()
result_ks['group_min'] = df_ks.groupby('rank')[y_pre].min()
result_ks['group_max'] = df_ks.groupby('rank')[y_pre].max()
result_ks['group_mean'] = df_ks.groupby('rank')[y_pre].mean()
# 3.最后一行添加total汇总数据
result_ks.loc['total', 'group_sum'] = df_ks['set_1'].sum()
result_ks.loc['total', 'group_min'] = df_ks[y_pre].min()
result_ks.loc['total', 'group_max'] = df_ks[y_pre].max()
result_ks.loc['total', 'group_mean'] = df_ks[y_pre].mean()
# 4.好用户统计
result_ks['good_sum'] = df_ks[df_ks[y_true] == good].groupby('rank')['set_1'].sum()
result_ks.good_sum.replace(np.nan, 0, inplace=True)
result_ks.loc['total', 'good_sum'] = result_ks['good_sum'].sum()
result_ks['good_percent'] = result_ks['good_sum'] / result_ks.loc['total', 'good_sum']
result_ks['good_percent_cum'] = result_ks['good_sum'].cumsum() / result_ks.loc['total', 'good_sum']
# 5.坏用户统计
result_ks['bad_sum'] = df_ks[df_ks[y_true] == bad].groupby('rank')['set_1'].sum()
result_ks.bad_sum.replace(np.nan, 0, inplace=True)
result_ks.loc['total', 'bad_sum'] = result_ks['bad_sum'].sum()
result_ks['bad_percent'] = result_ks['bad_sum'] / result_ks.loc['total', 'bad_sum']
result_ks['bad_percent_cum'] = result_ks['bad_sum'].cumsum() / result_ks.loc['total', 'bad_sum']
# 6.计算ks值
result_ks['diff'] = result_ks['bad_percent_cum'] - result_ks['good_percent_cum']
# 7.更新最后一行total的数据
result_ks.loc['total', 'bad_percent_cum'] = np.nan
result_ks.loc['total', 'good_percent_cum'] = np.nan
result_ks.loc['total', 'diff'] = result_ks['diff'].max()
result_ks = result_ks.reset_index()
return result_ks
接下来看一下生成的 result_ks 结果,如下图,代码和结果结合起来看更容易理解:
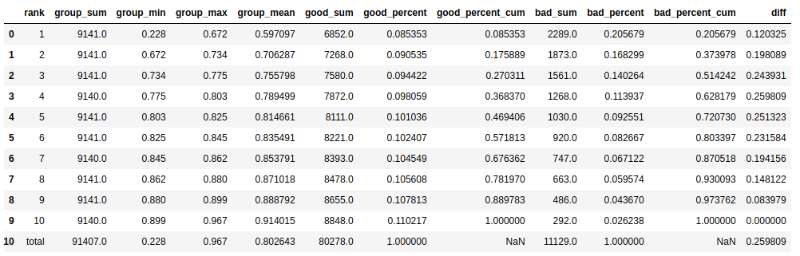

讲解之前先说一下函数中各个参数的含义。
df 是pandas的DataFrame表,表中必须包含两列:预测值和真实值。
预测值即模型预测的结果,一般为范围在0~1之间的概率值;
真实值是实际的好坏用户的label,一般为0或1,代表着好用户或者坏用户。
本文中使用的df前几列如下图。
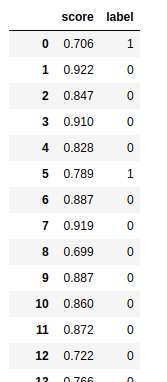
y_true是真实值在df表中的列名,此处为“label”;
y_pre是预测值在df表中的列名,此处为“score”;
num是需要分组的数量,具体含义后面会说;
good和bad是真实值中0和1代表的含义,如果好用户用0表示,那么good=0、bad=1,反之亦然。
下面按照代码中的注释分步讲解。
- 先将
df按照score列从小到大进行排序。排序完成后,如果num=10,则将所有的样本划分为10个区间,新增rank列,此列对每个区间从上到下使用1~10个数字标记。为了方便之后求和统计,新增set_1列,此列所有值均为1; - 对
score列进行统计,group_sum为每个区间的个数,相应的max、min、mean为区间的最大值、最小值和平均值; - 在最后新增一行
total,进行整列数据的统计; - 好用户统计,
good_sum列中计算了每个区间的好用户数量,good_percent列中则是每个区间的好用户数占全部好用户数的比例。最重要的是计算good_percent_cum,计算各行的累加值占好用户数量的比例,不理解的话建议搜索cumsum好好看看。其实这里计算的good_percent_cum就是就是在不同阈值下的TPR,true positive rate; - 坏用户统计,与好用户计算方法一致,
bad_percent_cum计算的是不同阈值下的FPR,false positive rate; diff列中保存bad_percent_cum - good_percent_cum的结果, 两列的差值的最大值即为ks;- 最后更新一下
total中的内容。
以上就是ks的全部计算步骤,其实结果生成那么多列,大部分都是帮助理解数据结构,真正用于计算的也就是good_percent_cum、bad_percent_cum这两列,ks其实也是max(df['good_percent_cum'] - df['bad_percent_cum'])。ks越大,表示计算预测值的模型区分好坏用户的能力越强。
| ks值 | 含义 |
|---|---|
| > 0.3 | 模型预测性较好 |
| 0,2~0.3 | 模型可用 |
| 0~0.2 | 模型预测能力较差 |
| < 0 | 模型错误 |
ks曲线绘制
import matlibplot.pyplot as plt
import seaborn as sns
sns.set()
def ks_curve(df, num=10):
# 防止中文乱码
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus']=False
ks_value = df['diff'].max()
# 获取绘制曲线所需要的数据
x_curve = range(num + 1)
y_curve1 = [0] + list(df['bad_percent_cum'].values[:-1])
y_curve2 = [0] + list(df['good_percent_cum'].values[:-1])
y_curve3 = [0] + list(df['diff'].values[:-1])
# 获取绘制ks点所需要的数据
df_ks_max = df[df['diff'] == ks_value]
x_point = [df_ks_max['rank'].values[0], df_ks_max['rank'].values[0]]
y_point = [df_ks_max['bad_percent_cum'].values[0], df_ks_max['good_percent_cum'].values[0]]
# 绘制曲线
plt.plot(x_curve, y_curve1, label='bad', linewidth=2)
plt.plot(x_curve, y_curve2, label='good', linewidth=2)
plt.plot(x_curve, y_curve3, label='diff', linewidth=2)
# 标记ks
plt.plot(x_point, y_point, label='ks - {:.2f}'.format(ks_value), color='r', marker='o', markerfacecolor='r', markersize=5)
plt.scatter(x_point, y_point, color='r')
plt.legend()
plt.show()
return ks_value
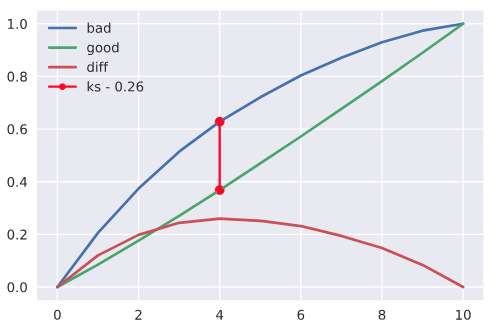
运行下面代码,得到ks曲线图
result_ks = ks(df, 'label', 'score')
ks_curve(result_ks)
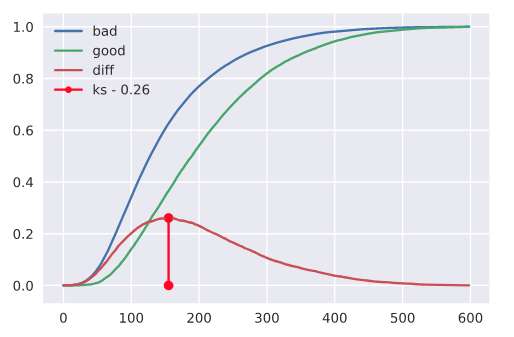
roc_curve函数实现
上面说了计算ks其实只用得到关键的两列,而这两列可以通过sklearn.metrics中函数roc_curve直接获取。
下面代码中,ks_value即为ks值。
from sklearn.metrics import roc_curve
fpr, tpr, thresholds= roc_curve(df.label, df.score)
ks_value = max(abs(fpr-tpr))
# 画图,画出曲线
plt.plot(fpr, label='bad')
plt.plot(tpr, label='good')
plt.plot(abs(fpr-tpr), label='diff')
# 标记ks
x = np.argwhere(abs(fpr-tpr) == ks_value)[0, 0]
plt.plot((x, x), (0, ks_value), label='ks - {:.2f}'.format(ks_value), color='r', marker='o', markerfacecolor='r', markersize=5)
plt.scatter((x, x), (0, ks_value), color='r')
plt.legend()
plt.show()
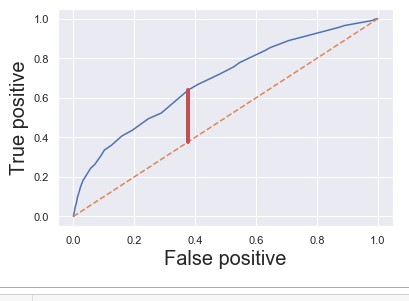
最后,讲另外一种画法。
ks_value = max(abs(fpr-tpr))
# 画图,画出曲线
plt.plot(fpr, tpr)
plt.plot([0,1], [0,1], linestyle='--')
# 标记ks
x = np.argwhere(abs(fpr-tpr) == ks_value)[0, 0]
plt.plot([fpr[x], fpr[x]], [fpr[x], tpr[x]], linewidth=4, color='r')
# plt.scatter((x, x), (0, ks_value), color='r')
plt.xlabel('False positive', fontsize=20)
plt.ylabel('True positive', fontsize=20)
plt.show()
X轴的含义
看两张ks图,X轴的含义其实是区间序号,第一张图划分了10个区间,所以X轴是0~10。
第二个sklearn会根据你的数据大小进行划分区间,这里我使用的数据量比较大,划分了600个区间计算的,所以X轴范围是0~600。
本文引用:
神秘的KS值和GINI系数
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/125470.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
