转发请注明引用和原文博客(http://www.cnblogs.com/wenBlog)
简介
之前已经写过两篇介绍列存储索引的文章,但是只有非聚集列存储索引,今天再来简单介绍一下聚集的列存储索引,也就是可更新列存储索引。在SQL Server 2012中首次引入了基于列存储数据格式的存储方式。叫做“列存储索引”。前一篇我已经比较了行存储索引与非聚集的列存储索引(http://www.cnblogs.com/wenBlog/p/5682024.html)。其中对于在小表的指定值或者小范围的查询来讲,尤其针对事务性的负载行存储是很合适的。但是对于分析性负载像数据仓库和BI,在查询中将会对大量数据进行全扫描,例如事实表,这时候列存储索引就是更好地选择。
列存储索引结构
在列存储索引中,数据按照独立列组织到一起形成索引结构。每列都数据都位于被高度压缩的数据集中,叫做数据段。这个数据段只包含该列的值,对于大型表它分到多个数据段中,每个数据段中只含有100万行数据,这就叫做行组、数据段由一个或者多个数据页组成。数据将在内存和硬盘上以数据段的形式传输。
这种索引提高了数据仓库的查询效率。这种通过压缩获得数据格式要比B-Tree结构的压缩率高7倍多。同时由于列存储索引使用了批处理模式执行,数据处理也是批处理的,较少了CPU的使用。列存储索引强化了检索数据的速度,与行存储不同的是不用查询所有列。因为这个原因,更少数据被读取到内存中,再到处理器缓存处理。相关的这些因素都会减少硬盘IO,提高整体查询的性能。
在2014中列存储索引有以下限制:
最多支持1024列在你的索引中;
列存储索引不能被定义为唯一性索引;
不能创建视图;
不能包含稀疏列;
不能使用ALTER INDEX来修改索引,只能drop然后重新创建;
不能使用INCLUDE关键字。
不能排序列;
不能使用FILESTREAM属性。
当然还有一些数据类型不能包含在列存储索引中(binary , varbinary , ntext , text, , image, varchar(max) , nvarchar(max), uniqueidentifier, rowversion , sql_variant,精度大于18 的decimal,CLR 和xml等)
另一方面,对于索引列900字节的限制也不适用与列存储索引。
在SQL Server2012 中,只能创建非聚集列存储索引,并且不能更新。为了更新你必须删除索引,然后进行插入、更新或者删除的操作后在重建索引。
在2014中列存储索引得到了不小的提升,比如消除了只读限制。增加了聚集列存储索引,列存储索引作为了表的存储方式,存储表的数据。
比较聚集和非聚集列存储索引
区别 |
聚集列存储索引 |
非聚集列存储索引 |
| 索引列 | 需要指定列上创建 | 所有列都包含在内 |
| 存储 | 额外增加百分之10的空间作为索引 | 压缩十倍的数据量,如果表之前是页压缩,则可以压缩5倍左右 |
| 更新 | 是 | 否 |
| 排序 | 在创建之前进行排序 | 否 |
列存储索引的结构图:


如图增量存储部分我们叫做deltastore,用于存储不够最小行组大小的数据。流程就是将行数据提取成列数据,然后进行压缩存储,多余的部分放到deltastore中。
聚集索引插入、删除和更新实现逻辑:
插入新行的时候,值被存储在deltastore中,直到达到最小rowgroup(行组)大小时,然后压缩并移动到列存储数据段中。
删除数据时,行将被删除从deltastore存储中,但是在列存储索引数据段中只是被标记为删除,除非重建后才会被真的删除。
更新的时候,在deltastore存储中行数据被删除,然后在列存储数据段中被标记为删除,新的列别插入到deltastore中。
最后当重建索引的时。SQLServer将会删除所有标记为删除的数据段,数据存储在deltastore中的将与数据段中的数据合并,然后进行压缩。
下面我们来展示下如何从列存储索引中获得性能:
我们首先创建一个事实表在数据库中脚本如下:
1 USE SQLShackDemo 2 3 GO 4 --创建表 5 CREATE TABLE [dbo].[FactFinance]( 6 7 [FinanceKey] [int] NOT NULL, 8 9 [DateKey] [int] NOT NULL, 10 11 [OrganizationKey] [int] NOT NULL, 12 13 [DepartmentGroupKey] [int] NOT NULL, 14 15 [ScenarioKey] [int] NOT NULL, 16 17 [AccountKey] [int] NOT NULL, 18 19 [Amount] [float] NOT NULL, 20 21 [Date] [datetime] NULL 22 23 ) ON [PRIMARY] 24 25 GO 26 27 --创建聚集索引: 28 29 CREATE CLUSTERED INDEX [IX_FactFinance_FinanceKey_DateKey] ON [dbo].[FactFinance] ( [FinanceKey],[DateKey]) 30 GO 31 32 33 --查询表: 34 35 SELECT [FinanceKey] 36 37 ,[DateKey] 38 39 ,[OrganizationKey] 40 41 ,[DepartmentGroupKey] 42 43 FROM [FactFinance]

让我们检查下聚集索引扫描操作符,Estimated I/O Cost(估计IO花销) 的值为0.183866,Estimated CPU Cost(估计CPU花销)为0.0435069,为了比较列索引的值,我们先记住:

现在我们创建列存储索引在非聚集索引:
CREATE NONCLUSTERED COLUMNSTORE INDEX [IX_FactFinance_FinanceKey_DateKey_OrganizationKey_DepartmentGroupKey] ON [FactFinance] ([FinanceKey],[DateKey],[OrganizationKey],[DepartmentGroupKey]) GO SELECT [FinanceKey] ,[DateKey] ,[OrganizationKey] ,[DepartmentGroupKey] FROM [FactFinance]

这个列存储索引扫描操作符如下所示:
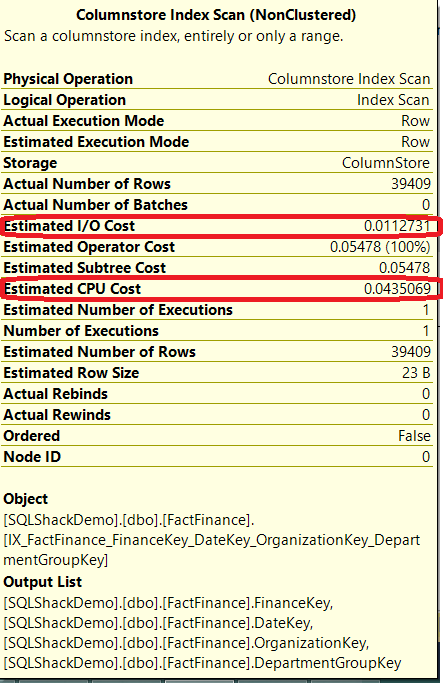
如上所示,Estimated I/O Cost从0.183866下降到0.0112731,这是因为SQL引擎只检索需要的列,节省了IO和内存资源。Estimated CPU的时间没有变化。
IO强化与之前相比是明显的,我们也可以比较两个查询,启用I/O statistics,检查IO的hits 表现如下:
SET STATISTICS IO ON GO SELECT [FinanceKey] ,[DateKey] ,[OrganizationKey] ,[DepartmentGroupKey] FROM [FactFinance] with (index (IX_FactFinance_FinanceKey_DateKey)) GO SELECT [FinanceKey] ,[DateKey] ,[OrganizationKey] ,[DepartmentGroupKey] FROM [FactFinance] with (index(IX_FactFinance_FinanceKey_DateKey_OrganizationKey_DepartmentGroupKey))
正如所示,比较执行计划,使用列存储索引的要比行索引的好四倍,那么期望一下处理大数据时的10倍性能:
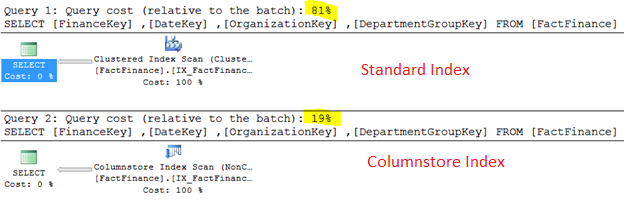
当比较逻辑读时你也能发现相似的结果。明显这个逻辑读也是四倍+关系。

那么我们可以根据下图概括一下传统的行索引与列存储所以的一般性区别:

列存储索引的创建
也能够使用SSMS创建索引: Indexes -> New Index ->Non-Clustered Columnstore Index 如下:
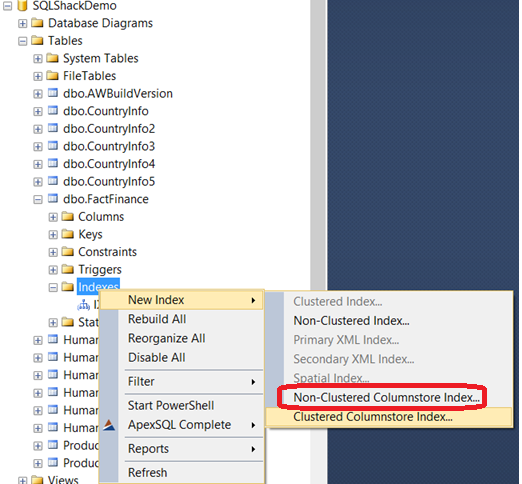
与非聚集索引创建类似,选择列,然后这些列没有排序也不能使用Include选项:
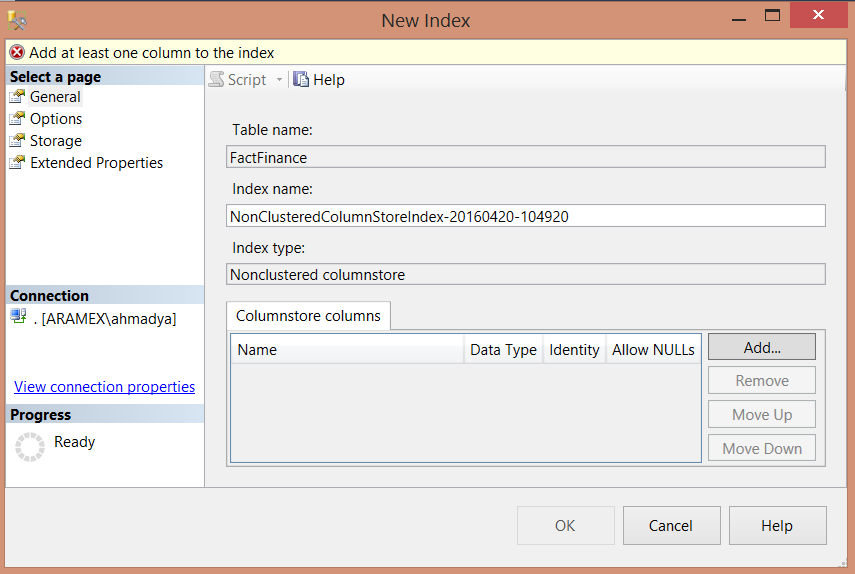
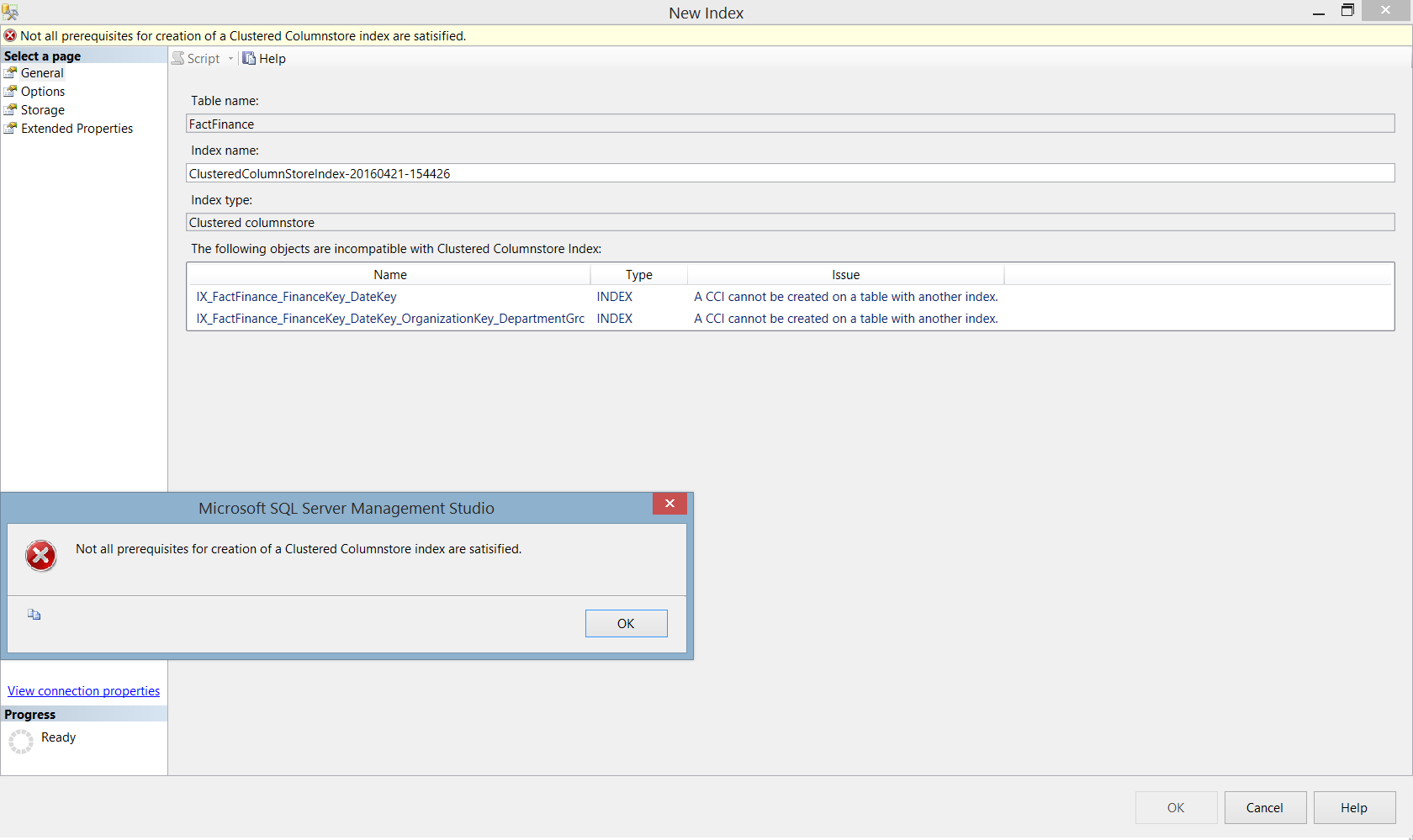
下图中我在SQL Server2014 企业版中,创建聚集索引:
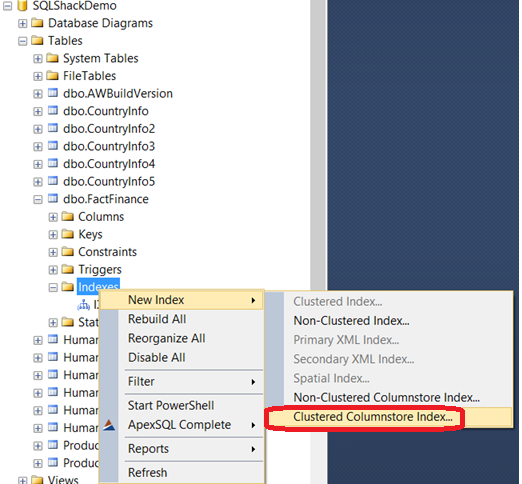
需要注意的是如果在表上已经有其他索引,尝试创建聚集列存储索引就会出现错误,正如我们之前说的,同一个表中不能或者其他索引:
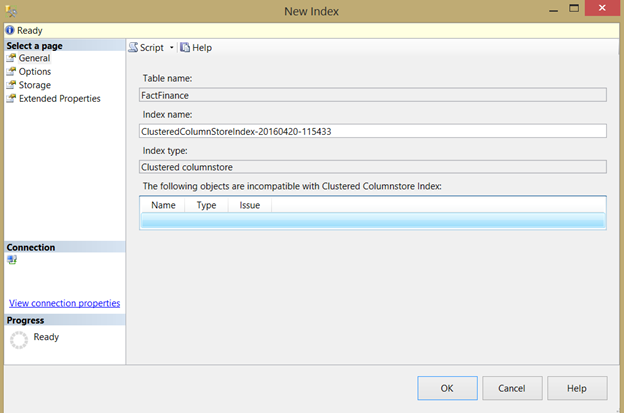
不用选择列,所有数据都包含在内了:
几个好的应用场景:
如果你有大型的事实表并且存在查询问题的,或者SSAS存在其他性能问题的,列存储是一个不错的方案。一下两种情况是经过测试的比较好的应用场景:
- 对于高频率响应的报表/仪表板,尤其分析当性能表现不佳的时候,会有很不错的性能。
- 对于ETL的过程来讲,源数据的列存储索引将会极大提高性能,如果数据足够大甚至可以考虑临时创建列存储索引。然后执行ETL。
总结:
列存储索引是一个使用SQL Server性能优化的方案,通过减少IO消耗,尤其对数据仓库和BI查询都是由明显性能提升。它通过排序数据作为列存储,然后压缩,并使用批处理来处理数据。当然,必须要确保使用列存储索引的使用带来了好处,而不会引起其他性能问题才能使用。比如需要注意使用的硬件环境和数据,如果没有join、过滤、或者聚合导出巨大的数据量没有足够的内存则将被暂时放入硬盘进行switch off,从而引起查询性能下降。尽量在使用之前在测试环境中测试是否适合使用,同时还要关注其他环节是否受影响。
补充,在2016中增加的几个我认为不错新的feature:
基于聚集列存储索引的 B 树索引;
基于内存优化表的列存储索引;
CREATE TABLE 和 ALTER TABLE 中的列存储索引的压缩延迟选项;
单线程查询的批处理执行。
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/119700.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
