http://blog.csdn.net/q602075961/article/details/71076390
2、项目中,优化mysql之前,首先要开启慢查询日志,在分析慢查询日志.
1,查看所有日志状态: show variables like ‘%quer%’;2,查看慢查询状态:show variables like ‘show%’
linux 启用MySQL慢查询
代码如下
vim /etc/my.cnf
Windows下开启MySQL慢查询
MySQL在Windows系统中的配置文件一般是是my.ini找到[mysqld]下面加上
补充:
在my.cnf或者my.ini中添加log-queries-not-using-indexes参数,表示记录下没有使用索引的查询。比如:
代码如下
log-slow-queries=/data/mysqldata/slowquery.log # 慢查询日志存放路径与名称查询时间超过5s的查询语句# 列出没有使用索引的查询语句
3、如何分析sql查询
explain返回各列的含义
extra列需要注意的返回值
Using filesort:看到这个的时候,查询就需要优化了。MYSQL需要进行额外的步骤来发现如何对返回的行排序。它根据连接类型以及存储排序键值和匹配条件的全部行的行指针来排序全部行
Using temporary看到这个的时候,查询需要优化了。这里,MYSQL需要创建一个临时表来存储结果,这通常发生在对不同的列集进行ORDER BY上,而不是GROUP BY上
3.1 MySql内部函数explain(查询sql的执行计划)使用方法以及返回各列的含义
explain返回各列的含义
table:显示这一行的数据是关于哪张表的
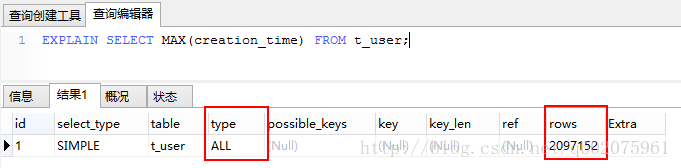
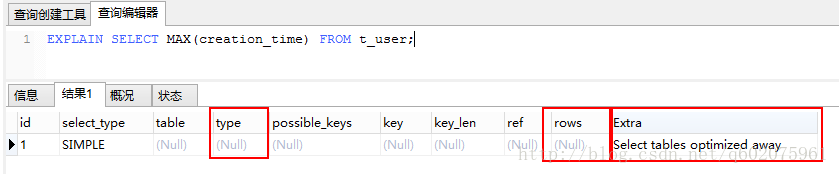
type:这是重要的列,显示连接使用了何种类型。从最好到最差的连接类型为const、eq_reg、ref、range、index 和ALL
possible_keys:显示可能应用在这张表中的索引。如果为空,没有可能的索引。
key:实际使用的索引。如果为NULL,则没有使用索引。
keyjen:使用的索引的长度。在不损失精确性的情况下,长度越短越好
ref:显示索引的哪一列被使用了,如果可能的话,是一个常数
rows: MYSQL认为必须检查的用来返回请求数据的行数
实例1:mysql函数【max()】,最后一位注册用户的信息
进行查询操作, 图一是没有加索引,图二是加了索引的,查询出来的type和rows字段也不相同。(参照上图字段段含义)
图一:
图二:
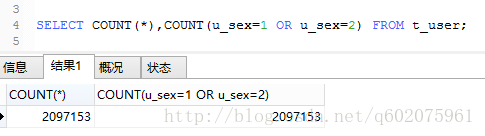
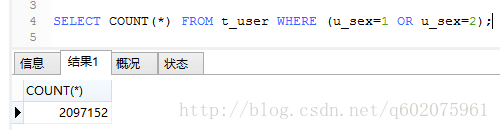
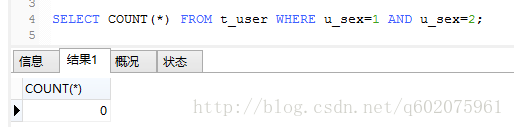
实例2: mysql函数【 count() 】,获取注册用户男女人数
显然图三不是这个查询方法不是咱们想要的结果,图四和图五也一样,利用count()函数的特性null不统计,得到了我们想要的结果(图六)。
图三:
图四:
图五:
图六:
3.2 子查询的优化,通常情况下把子查询优化为join查询,但在优化的时候需要注意关联建是否有一对多的关系,要特别注意重复数据
实例3:如图七和图八
图七:
图八:
3.3 GROUP BY的优化
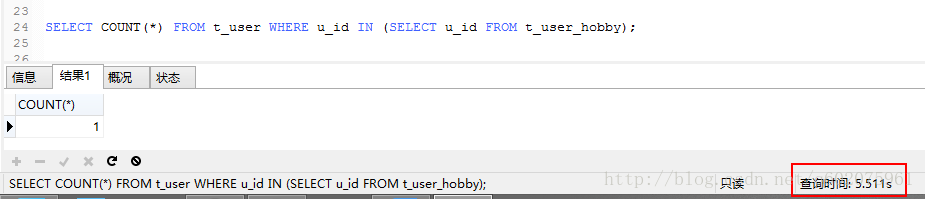
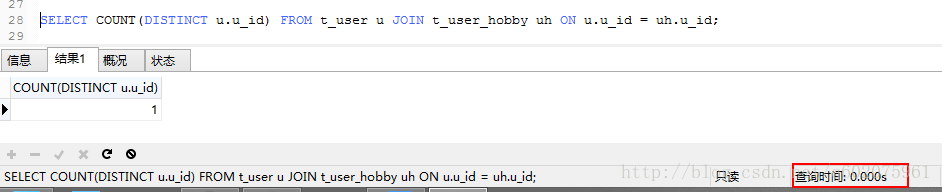
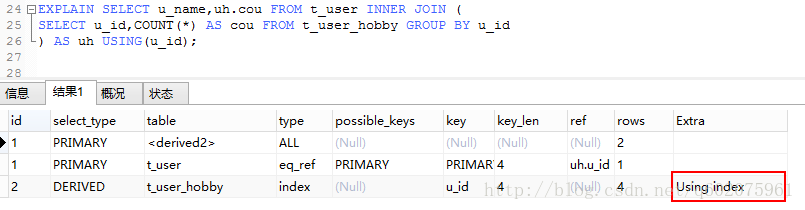
实例4:获取每个用户爱好的数量。使用sql执行计划来排查,图九使用GROUP BY查询,关联的表会产生临时表和按照文件排序,sql优化之后(图十)就直接按照索引来查询,避免临时表的产生和文件形式排序。在数据量大的时候会大大减少对服务器的IO访问。
图九:
图十:
实例5:使用LIMIT一般都伴随着ORDER BY(如图十一),如果是没有索引的字段排序的的话会按照文件排序,全表查询会加大对服务器IO的访问。
图十一:
优化方案一:使用主键进行排序,不会造成全表扫描,会减少对服务器IO的访问 。但是还有一个问题,当所查询的条数越往后,所扫描的条数也会越多(如图十三)
图十二:
图十三:
优化方案二:可以获取上一个主键的id来做一个范围查询来减少对服务器IO的访问(如图十四),但是因此还会出现另一个问题,要保证主键ID是连续的,当主键ID中间有缺少,会对我们查询出来的数据不对。
图十四:
优化方案三:可以添加一个字段用于LIMIT查询,再加上索引,就和主键id产生同样的效果,但是这样会产生很多麻烦。
4 .1、如何选择合适的列建立索引
说明:
1、如果一个索引可以包含所有字段的话,就称之为覆盖索引。当一张表里的数据少的话,就可以使用覆盖索引,这样就可以读取索引而不用读取表了。
2、索引字段越小越好,因为数据库里的数据是已页存储的,如果IO一次读取一页的数据很多,这样的话就可以提高服务器IO的效率。
3、在建立联合索引的时候,一定要把离散度大的放在前面,这样的话效果比较好
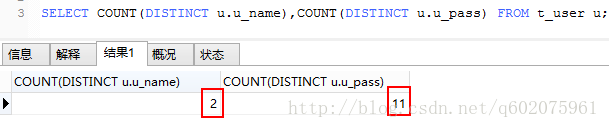
实例6:通过count函数统计唯一值,值大的离散度就大,也就是说u_pass的离散度比大u_name,所以应该使用index(u_pass,u_name)
4.2、索引的维护和优化
4.2.1重复索引
4.2.2冗余索引
4.2.3检查重复及冗余索引的工具
4.2.4删除不用的索引
说明:由于业务变更有些原来使用的索引现在不使用了也是需要清除的,这也是索引优化的一个方面了!注意:再次的强调SQL和索引的优化对于数据库的优化是相当重要的,这一层的优化如果做好了,其他的优化也能起到一些作用否则其他的优化所能起到的作用是微乎其微的,这一层的优化也是成本最低效果最好的一层了,所以对于数据库的优化最好重点放在这一层。
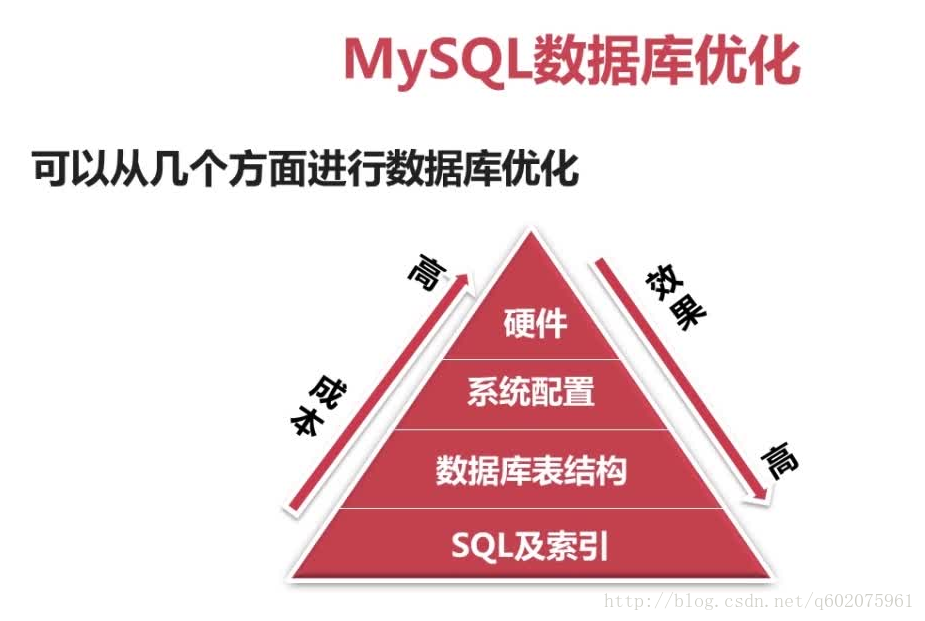
5、数据库结构优化
5.1选择合适的数据类型
数据类型的选择,重点在于合适
1.使用可以存下你的数据的最小的数据类型。
2.使用简单的数据类型。Int要比varchar类型在mysql处理上简单。
3.尽可能的使用not null定义字段。
4.尽量少用text类型,非用不可时最好考虑分表。
实例:int、bigint、smallint 和 tinyint范围
使用整数数据的精确数字数据类型。
bigint
从 -2^63 (-9223372036854775808) 到 2^63-1 (9223372036854775807) 的整型数据(所有数字)。存储大小为 8 个字节。
int
从 -2^31 (-2,147,483,648) 到 2^31 – 1 (2,147,483,647) 的整型数据(所有数字)。存储大小为 4 个字节。int 的 SQL-92 同义字为 integer。
smallint
从 -2^15 (-32,768) 到 2^15 – 1 (32,767) 的整型数据。存储大小为 2 个字节。
tinyint
从 0 到 255 的整型数据。存储大小为 1 字节。
注释
在支持整数值的地方支持 bigint 数据类型。但是,bigint 用于某些特殊的情况,当整数值超过 int 数据类型支持的范围时。
在数据类型优先次序表中,bigint 位于 smallmoney 和 int 之间。
实例:时间使用int类型
实例:IP地址使用bigint类型
5.2 表的范式化
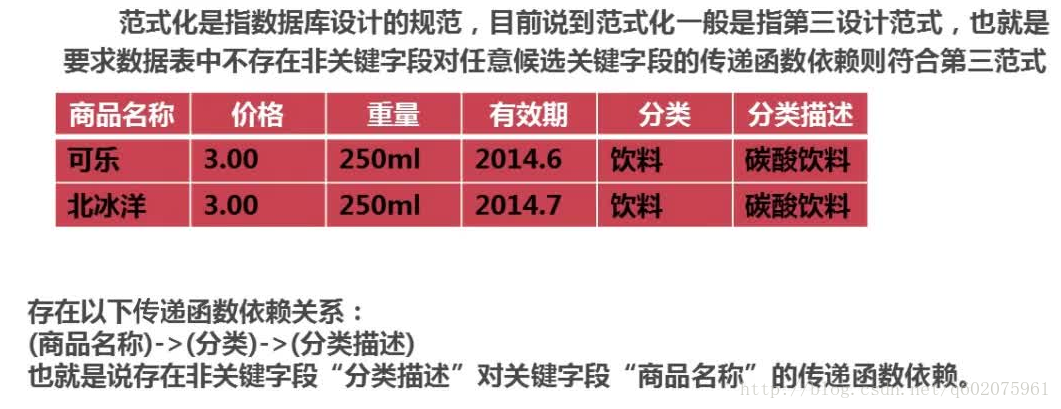
什么是范式化?
实例:
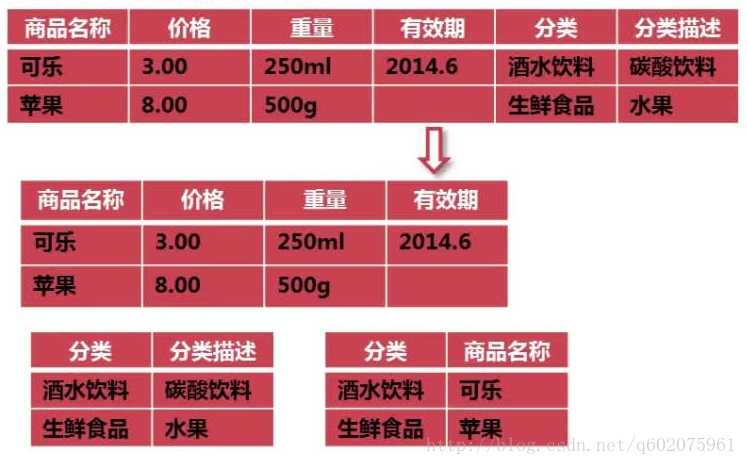
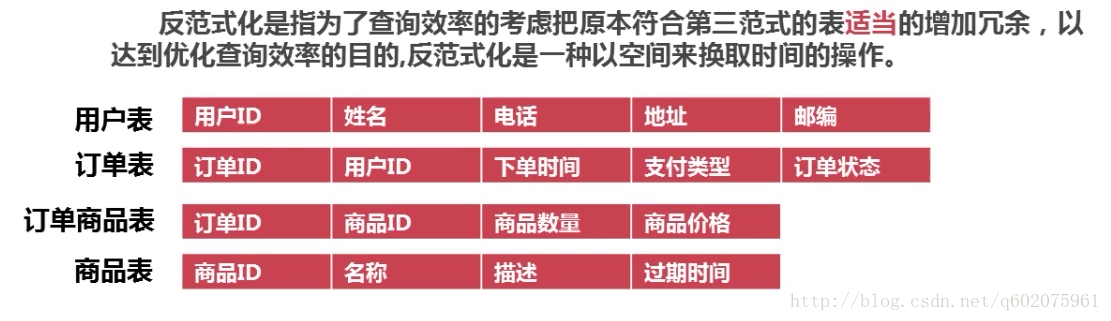
5.3 表的反范式化的使用
如我要查询订单商品表的下单人,电话,地址,订单id和下单时间sql语句如下:
使用反范式化的表结构
sqi语句的查询效率也会提升很多,数据库表结构的设计对sql的优化也起到了很大的作用
5.4 表的垂直拆分
5.5 表的水行拆分
当表的数据比较多的时候,可以选择将表进行水平拆分,水平拆分的本质并没有改变表的结构仅是将原本存放在同一个表中的数据放到了多个结构一样的表中。
水平拆分的方法:
6 系统配置优化
6.1操作系统优化
6.2 MySql配置优化
SELECT engine,ROUND(SUM(data_length+index_length)/1024/2014,1) AS “Total MB” FROM INFORMATION_SCHEMA.TABLES WHERE table_schema not in (“information_schema”,”performance_schema”) GROUP BY ENGINE;
mysql常用配置参数1
mysql常用配置参数2
mysql常用配置参数3
mysql常用配置参数4
mysql常用配置参数5
6.3 MySql 第三方配置工具
https://tools.percona.com/wizard
配置MySQL的配置文件使用工具更方便,主要就是调整配置的参数,值调整成什么样的参数才是合适的,估计需要补充各种基础知识不是三言两语说的清楚的。就是将文本的配置方式变成了界面式的配置方式,不过经验在此时就非常的重要了,否则压根判断不出什么样的配置才是适合的配置!
7 服务器硬件优化
模拟数据库数据和sql语句下载: