大家好,又见面了,我是全栈君。
(一)MySQL CPU 使用率高的原因和解决方法
用户在使用 MySQL 实例时,会遇到 CPU 使用率过高甚至达到 100% 的情况。本文将介绍造成该状况的常见原因以及解决方法,并通过 CPU 使用率为 100% 的典型场景,来分析引起该状况的原因及其相应的解决方案。
常见原因
系统执行应用提交查询(包括数据修改操作)时需要大量的逻辑读(逻辑 IO,执行查询所需访问的表的数据行数),所以系统需要消耗大量的 CPU 资源以维护从存储系统读取到内存中的数据一致性。
说明:大量行锁冲突、行锁等待或后台任务也有可能会导致实例的 CPU 使用率过高,但这些情况出现的概率非常低,本文不做讨论。
本文通过一个简化的模型来说明系统资源、语句执行成本以及 QPS(Query Per Second 每秒执行的查询数)之间的关系:
-
条件:应用模型恒定(应用没有修改)。
-
avg_lgc_io:执行每条查询需要的平均逻辑 IO。
-
total_lgc_io:实例的 CPU 资源在单位时间内能够处理的逻辑 IO 总量。
-
关系公式:
total_lgc_io = avg_lgc_io x QPS -- 单位时间 CPU 资源 = 查询执行的平均成本 x 单位时间执行的查询数量
解决方法
数据管理(DMS)工具提供了几种辅助排查并解决实例性能问题的功能,主要有:
-
实例诊断报告
-
SQL 窗口提供的查询优化建议和查看执行计划
-
实例会话
其中,实例诊断报告是排查和解决 MySQL 实例性能问题的最佳工具。无论何种原因导致的性能问题,建议您首先参考下实例诊断报告,尤其是诊断报告中的 SQL 优化、会话列表和慢 SQL 汇总分。
另外,如果您需要阿里云的技术支持来解决 CPU 使用率高的状况,请参见 https://market.aliyun.com/store/1682301.html。
避免出现 CPU 使用率达到 100% 的一般原则
-
设置 CPU 使用率告警,实例 CPU 使用率保证一定的冗余度。
-
应用设计和开发过程中,要考虑查询的优化,遵守 MySQL 优化的一般优化原则,降低查询的逻辑 IO,提高应用可扩展性。
-
新功能、新模块上线前,要使用生产环境数据进行压力测试(可以考虑使用阿里云 PTS 压力测试工具)。
-
新功能、新模块上线前,建议使用生产环境数据进行回归测试。
-
建议经常关注和使用 DMS 中的诊断报告。
注意:关于如何访问 DMS 中的诊断报告,请参见 RDS 如何访问诊断报告。
典型示例
以 CPU 使用率为 100% 的典型场景为例,本文介绍了两个引起该状况的原因及其解决方案,即应用负载(QPS)高和查询执行成本(查询访问表数据行数 avg_lgc_io)高。其中,由于查询执行成本高(查询访问表数据行数多)而导致实例 CPU 使用率高是 MySQL 非常常见的问题。
应用负载(QPS)高
-
特征:实例的 QPS(每秒执行的查询次数)高,查询比较简单、执行效率高、优化余地小。
-
表现:没有出现慢查询(或者慢查询不是主要原因),且 QPS 和 CPU 使用率曲线变化吻合。
-
常见场景:该状况常见于应用优化过的在线事务交易系统(例如订单系统)、高读取率的热门 Web 网站应用、第三方压力工具测试(例如 Sysbench)等。
对于由应用负载高导致的 CPU 使用率高的状况,使用 SQL 查询进行优化的余地不大,建议您从应用架构、实例规格等方面来解决,例如:
-
升级实例规格,增加 CPU 资源。
-
增加只读实例,将对数据一致性不敏感的查询(比如商品种类查询、列车车次查询)转移到只读实例上,分担主实例压力。
-
使用阿里云 DRDS 产品,自动进行分库分表,将查询压力分担到多个 RDS 实例上。
-
使用阿里云 Memcache 或者云 Redis 产品,尽量从缓存中获取常用的查询结果,减轻 RDS 实例的压力。
-
对于查询数据比较静态、查询重复度高、查询结果集小于 1 MB 的应用,考虑开启查询缓存(Query Cache)。
注意:能否从开启查询缓存(Query Cache)中获益需要经过测试,具体设置请参见 RDS for MySQL 查询缓存(Query Cache)的设置和使用。
-
定期归档历史数据、采用分库分表或者分区的方式减小查询访问的数据量。
-
尽量优化查询,减少查询的执行成本(逻辑 IO,执行需要访问的表数据行数),提高应用可扩展性。
查询执行成本(查询访问表数据行数 avg_lgc_io)高(我们属于这种)
现象描述
-
特征:实例的 QPS(每秒执行的查询次数)不高;查询执行效率低、执行时需要扫描大量表中数据、优化余地大。
-
表现:存在慢查询,QPS 和 CPU 使用率曲线变化不吻合。
-
原因分析:由于查询执行效率低,为获得预期的结果即需要访问大量的数据(平均逻辑 IO高),在 QPS 并不高的情况下(例如网站访问量不大),就会导致实例的 CPU 使用率高。
解决方案
解决该状况的原则是:定位效率低的查询、优化查询的执行效率、降低查询执行的成本。
-
通过如下方式定位效率低的查询:
-
通过
show processlist;或show full processlist;命令查看当前执行的查询,如下图所示:
对于查询时间长、运行状态(State 列)是“Sending data”、“Copying to tmp table”、“Copying to tmp table on disk”、“Sorting result”、“Using filesort”等都可能是有性能问题的查询(SQL)。
注意:
-
若在 QPS 高导致 CPU 使用率高的场景中,查询执行时间通常比较短,
show processlist;命令或实例会话中可能会不容易捕捉到当前执行的查询。您可以通过执行如下命令进行查询:explain select b.* from perf_test_no_idx_01 a, perf_test_no_idx_02 b where a.created_on >= 2015-01-01 and a.detail = b.detail
- 您可以通过执行类似
kill 101031643;的命令来终止长时间执行的会话,终止会话请参见 RDS for MySQL 如何终止会话。关于长时间执行会话的管理,请参见 RDS for MySQL 管理长时间运行查询
-
-
(二)mysql查看当前实时连接数
静态查看:
SHOW PROCESSLIST;
SHOW FULL PROCESSLIST;
SHOW VARIABLES LIKE '%max_connections%';
SHOW STATUS LIKE '%Connection%'; 实时查看:
mysql> show status like 'Threads%';
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| Threads_cached | 58 |
| Threads_connected | 57 | ###这个数值指的是打开的连接数
| Threads_created | 3676 |
| Threads_running | 4 | ###这个数值指的是激活的连接数,这个数值一般远低于connected数值
+-------------------+-------+
Threads_connected 跟show processlist结果相同,表示当前连接数。准确的来说,Threads_running是代表当前并发数
这是是查询数据库当前设置的最大连接数
mysql> show variables like '%max_connections%';
+-----------------+-------+
| Variable_name | Value |
+-----------------+-------+
| max_connections | 100 |
+-----------------+-------+
可以在/etc/my.cnf里面设置数据库的最大连接数
max_connections = 1000(三)Mysql配置文件/etc/my.cnf解析
# 客户端设置
[client]
port = 3306
# 默认情况下,socket文件应为/usr/local/mysql/mysql.socket,所以可以ln -s xx /tmp/mysql.sock
socket = /tmp/mysql.sock
# 服务端设置
[mysqld]
##########################################################################################################
# 基础信息
#Mysql服务的唯一编号 每个mysql服务Id需唯一
server-id = 1
#服务端口号 默认3306
port = 3306
# 启动mysql服务进程的用户
user = mysql
##########################################################################################################
# 安装目录相关
# mysql安装根目录
basedir = /usr/local/mysql-5.7.21
# mysql数据文件所在位置
datadir = /usr/local/mysql-5.7.21/data
# 临时目录 比如load data infile会用到,一般都是使用/tmp
tmpdir = /tmp
# 设置socke文件地址
socket = /tmp/mysql.sock
##########################################################################################################
# 事务隔离级别,默认为可重复读(REPEATABLE-READ)。(此级别下可能参数很多间隙锁,影响性能,但是修改又影响主从复制及灾难恢复,建议还是修改代码逻辑吧)
# 隔离级别可选项目:READ-UNCOMMITTED READ-COMMITTED REPEATABLE-READ SERIALIZABLE
# transaction_isolation = READ-COMMITTED
transaction_isolation = REPEATABLE-READ
##########################################################################################################
# 数据库引擎与字符集相关设置
# mysql 5.1 之后,默认引擎就是InnoDB了
default_storage_engine = InnoDB
# 内存临时表默认引擎,默认InnoDB
default_tmp_storage_engine = InnoDB
# mysql 5.7新增特性,磁盘临时表默认引擎,默认InnoDB
internal_tmp_disk_storage_engine = InnoDB
#数据库默认字符集,主流字符集支持一些特殊表情符号(特殊表情符占用4个字节)
character-set-server = utf8
#数据库字符集对应一些排序等规则,注意要和character-set-server对应
collation-server = utf8_general_ci
# 设置client连接mysql时的字符集,防止乱码
# init_connect='SET NAMES utf8'
# 是否对sql语句大小写敏感,默认值为0,1表示不敏感
lower_case_table_names = 1
##########################################################################################################
# 数据库连接相关设置
# 最大连接数,可设最大值16384,一般考虑根据同时在线人数设置一个比较综合的数字,鉴于该数值增大并不太消耗系统资源,建议直接设10000
# 如果在访问时经常出现Too Many Connections的错误提示,则需要增大该参数值
max_connections = 10000
# 默认值100,最大错误连接数,如果有超出该参数值个数的中断错误连接,则该主机将被禁止连接。如需对该主机进行解禁,执行:FLUSH HOST
# 考虑高并发场景下的容错,建议加大。
max_connect_errors = 10000
# MySQL打开的文件描述符限制,默认最小1024;
# 当open_files_limit没有被配置的时候,比较max_connections*5和ulimit -n的值,哪个大用哪个,
# 当open_file_limit被配置的时候,比较open_files_limit和max_connections*5的值,哪个大用哪个。
open_files_limit = 65535
# 注意:仍然可能出现报错信息Can't create a new thread;此时观察系统cat /proc/mysql进程号/limits,观察进程ulimit限制情况
# 过小的话,考虑修改系统配置表,/etc/security/limits.conf和/etc/security/limits.d/90-nproc.conf
# MySQL默认的wait_timeout 值为8个小时, interactive_timeout参数需要同时配置才能生效
# MySQL连接闲置超过一定时间后(单位:秒,此处为1800秒)将会被强行关闭
interactive_timeout = 1800
wait_timeout = 1800
# 在MySQL暂时停止响应新请求之前的短时间内多少个请求可以被存在堆栈中
# 官方建议back_log = 50 + (max_connections / 5),封顶数为900
back_log = 900
##########################################################################################################
# 数据库数据交换设置
# 该参数限制服务器端,接受的数据包大小,如果有BLOB子段,建议增大此值,避免写入或者更新出错。有BLOB子段,建议改为1024M
max_allowed_packet = 128M
##########################################################################################################
# 内存,cache与buffer设置
# 内存临时表的最大值,默认16M,此处设置成128M
tmp_table_size = 64M
# 用户创建的内存表的大小,默认16M,往往和tmp_table_size一起设置,限制用户临师表大小。
# 超限的话,MySQL就会自动地把它转化为基于磁盘的MyISAM表,存储在指定的tmpdir目录下,增大IO压力,建议内存大,增大该数值。
max_heap_table_size = 64M
# 表示这个mysql版本是否支持查询缓存。ps:SHOW STATUS LIKE 'qcache%',与缓存相关的状态变量。
# have_query_cache
# 这个系统变量控制着查询缓存工能的开启的关闭,0时表示关闭,1时表示打开,2表示只要select 中明确指定SQL_CACHE才缓存。
# 看业务场景决定是否使用缓存,不使用,下面就不用配置了。
query_cache_type = 0
# 默认值1M,优点是查询缓冲可以极大的提高服务器速度, 如果你有大量的相同的查询并且很少修改表。
# 缺点:在你表经常变化的情况下或者如果你的查询原文每次都不同,查询缓冲也许引起性能下降而不是性能提升。
query_cache_size = 64M
# 只有小于此设定值的结果才会被缓冲,保护查询缓冲,防止一个极大的结果集将其他所有的查询结果都覆盖。
query_cache_limit = 2M
# 每个被缓存的结果集要占用的最小内存,默认值4kb,一般不怎么调整。
# 如果Qcache_free_blocks值过大,可能是query_cache_min_res_unit值过大,应该调小些
# query_cache_min_res_unit的估计值:(query_cache_size - Qcache_free_memory) / Qcache_queries_in_cache
query_cache_min_res_unit = 4kb
# 在一个事务中binlog为了记录SQL状态所持有的cache大小
# 如果你经常使用大的,多声明的事务,你可以增加此值来获取更大的性能.
# 所有从事务来的状态都将被缓冲在binlog缓冲中然后在提交后一次性写入到binlog中
# 如果事务比此值大, 会使用磁盘上的临时文件来替代.
# 此缓冲在每个连接的事务第一次更新状态时被创建
binlog_cache_size = 1M
#*** MyISAM 相关选项
# 指定索引缓冲区的大小, 为MYISAM数据表开启供线程共享的索引缓存,对INNODB引擎无效。相当影响MyISAM的性能。
# 不要将其设置大于你可用内存的30%,因为一部分内存同样被OS用来缓冲行数据
# 甚至在你并不使用MyISAM 表的情况下, 你也需要仍旧设置起 8-64M 内存由于它同样会被内部临时磁盘表使用.
# 默认值 8M,建议值:对于内存在4GB左右的服务器该参数可设置为256M或384M。注意:该参数值设置的过大反而会是服务器整体效率降低!
key_buffer_size = 64M
# 为每个扫描MyISAM的线程分配参数设置的内存大小缓冲区。
# 默认值128kb,建议值:16G内存建议1M,4G:128kb或者256kb吧
# 注意,该缓冲区是每个连接独占的,所以总缓冲区大小为 128kb*连接数;极端情况128kb*maxconnectiosns,会超级大,所以要考虑日常平均连接数。
# 一般不需要太关心该数值,稍微增大就可以了,
read_buffer_size = 262144
# 支持任何存储引擎
# MySQL的随机读缓冲区大小,适当增大,可以提高性能。
# 默认值256kb;建议值:得参考连接数,16G内存,有人推荐8M
# 注意,该缓冲区是每个连接独占的,所以总缓冲区大小为128kb*连接数;极端情况128kb*maxconnectiosns,会超级大,所以要考虑日常平均连接数。
read_rnd_buffer_size = 1M
# order by或group by时用到
# 支持所有引擎,innodb和myisam有自己的innodb_sort_buffer_size和myisam_sort_buffer_size设置
# 默认值256kb;建议值:得参考连接数,16G内存,有人推荐8M.
# 注意,该缓冲区是每个连接独占的,所以总缓冲区大小为 1M*连接数;极端情况1M*maxconnectiosns,会超级大。所以要考虑日常平均连接数。
sort_buffer_size = 1M
# 此缓冲被使用来优化全联合(full JOINs 不带索引的联合)
# 类似的联合在极大多数情况下有非常糟糕的性能表现,但是将此值设大能够减轻性能影响.
# 通过 “Select_full_join” 状态变量查看全联合的数量
# 注意,该缓冲区是每个连接独占的,所以总缓冲区大小为 1M*连接数;极端情况1M*maxconnectiosns,会超级大。所以要考虑日常平均连接数。
# 默认值256kb;建议值:16G内存,设置8M.
join_buffer_size = 1M
# 缓存linux文件描述符信息,加快数据文件打开速度
# 它影响myisam表的打开关闭,但是不影响innodb表的打开关闭。
# 默认值2000,建议值:根据状态变量Opened_tables去设定
table_open_cache = 2000
# 缓存表定义的相关信息,加快读取表信息速度
# 默认值1400,最大值2000,建议值:基本不改。
table_definition_cache = 1400
# 该参数是myssql 5.6后引入的,目的是提高并发。
# 默认值1,建议值:cpu核数,并且<=16
table_open_cache_instances = 2
# 当客户端断开之后,服务器处理此客户的线程将会缓存起来以响应下一个客户而不是销毁。可重用,减小了系统开销。
# 默认值为9,建议值:两种取值方式,方式一,根据物理内存,1G —> 8;2G —> 16; 3G —> 32; >3G —> 64;
# 方式二,根据show status like 'threads%',查看Threads_connected值。
thread_cache_size = 16
# 默认值256k,建议值:16/32G内存,512kb,其他一般不改变,如果报错:Thread stack overrun,就增大看看,
# 注意,每个线程分配内存空间,所以总内存空间。。。你懂得。
thread_stack = 512k
##########################################################################################################
# 日志文件相关设置,一般只开启三种日志,错误日志,慢查询日志,二进制日志。普通查询日志不开启。
# 普通查询日志,默认值off,不开启
general_log = 0
# 普通查询日志存放地址
general_log_file = /usr/local/mysql-5.7.21/log/mysql-general.log
# 全局动态变量,默认3,范围:1~3
# 表示错误日志记录的信息,1:只记录error信息;2:记录error和warnings信息;3:记录error、warnings和普通的notes信息。
log_error_verbosity = 2
# 错误日志文件地址
log_error = /usr/local/mysql-5.7.21/log/mysql-error.log
# 开启慢查询
slow_query_log = 1
# 开启慢查询时间,此处为1秒,达到此值才记录数据
long_query_time = 3
# 检索行数达到此数值,才记录慢查询日志中
min_examined_row_limit = 100
# mysql 5.6.5新增,用来表示每分钟允许记录到slow log的且未使用索引的SQL语句次数,默认值为0,不限制。
log_throttle_queries_not_using_indexes = 0
# 慢查询日志文件地址
slow_query_log_file = /usr/local/mysql-5.7.21/log/mysql-slow.log
# 开启记录没有使用索引查询语句
log-queries-not-using-indexes = 1
# 开启二进制日志
log_bin = /usr/local/mysql-5.7.21/log/mysql-bin.log
# mysql清除过期日志的时间,默认值0,不自动清理,而是使用滚动循环的方式。
expire_logs_days = 0
# 如果二进制日志写入的内容超出给定值,日志就会发生滚动。你不能将该变量设置为大于1GB或小于4096字节。 默认值是1GB。
max_binlog_size = 1000M
# binlog的格式也有三种:STATEMENT,ROW,MIXED。mysql 5.7.7后,默认值从 MIXED 改为 ROW
# 关于binlog日志格式问题,请查阅网络资料
binlog_format = row
# 默认值N=1,使binlog在每N次binlog写入后与硬盘同步,ps:1最慢
# sync_binlog = 1
##########################################################################################################
# innodb选项
# 说明:该参数可以提升扩展性和刷脏页性能。
# 默认值1,建议值:4-8;并且必须小于innodb_buffer_pool_instances
innodb_page_cleaners = 4
# 说明:一般8k和16k中选择,8k的话,cpu消耗小些,selcet效率高一点,一般不用改
# 默认值:16k;建议值:不改,
innodb_page_size = 16384
# 说明:InnoDB使用一个缓冲池来保存索引和原始数据, 不像MyISAM.这里你设置越大,你在存取表里面数据时所需要的磁盘I/O越少.
# 在一个独立使用的数据库服务器上,你可以设置这个变量到服务器物理内存大小的60%-80%
# 注意别设置的过大,会导致system的swap空间被占用,导致操作系统变慢,从而减低sql查询的效率
# 默认值:128M,建议值:物理内存的60%-80%
innodb_buffer_pool_size = 512M
# 说明:只有当设置 innodb_buffer_pool_size 值大于1G时才有意义,小于1G,instances默认为1,大于1G,instances默认为8
# 但是网络上有评价,最佳性能,每个实例至少1G大小。
# 默认值:1或8,建议值:innodb_buffer_pool_size/innodb_buffer_pool_instances >= 1G
innodb_buffer_pool_instances = 1
# 说明:mysql 5.7 新特性,defines the chunk size for online InnoDB buffer pool resizing operations.
# 实际缓冲区大小必须为innodb_buffer_pool_chunk_size*innodb_buffer_pool_instances*倍数,取略大于innodb_buffer_pool_size
# 默认值128M,建议值:默认值就好,乱改反而容易出问题,它会影响实际buffer pool大小。
innodb_buffer_pool_chunk_size = 128M
# 在启动时把热数据加载到内存。默认值为on,不修改
innodb_buffer_pool_load_at_startup = 1
# 在关闭时把热数据dump到本地磁盘。默认值为on,不修改
innodb_buffer_pool_dump_at_shutdown = 1
# 说明:影响Innodb缓冲区的刷新算法,建议从小到大配置,直到zero free pages;innodb_lru_scan_depth * innodb_buffer_pool_instances defines the amount of work performed by the page cleaner thread each second.
# 默认值1024,建议值: 未知
innodb_lru_scan_depth = 1024
# 说明:事务等待获取资源等待的最长时间,单位为秒,看具体业务情况,一般默认值就好
# 默认值:50,建议值:看业务。
innodb_lock_wait_timeout = 60
# 说明:设置了Mysql后台任务(例如页刷新和merge dadta from buffer pool)每秒io操作的上限。
# 默认值:200,建议值:方法一,单盘sata设100,sas10,raid10设200,ssd设2000,fushion-io设50000;方法二,通过测试工具获得磁盘io性能后,设置IOPS数值/2。
innodb_io_capacity = 2000
# 说明:该参数是所有缓冲区线程io操作的总上限。
# 默认值:innodb_io_capacity的两倍。建议值:例如用iometer测试后的iops数值就好
innodb_io_capacity_max = 4000
# 说明:控制着innodb数据文件及redo log的打开、刷写模式,三种模式:fdatasync(默认),O_DSYNC,O_DIRECT
# fdatasync:数据文件,buffer pool->os buffer->磁盘;日志文件,buffer pool->os buffer->磁盘;
# O_DSYNC: 数据文件,buffer pool->os buffer->磁盘;日志文件,buffer pool->磁盘;
# O_DIRECT: 数据文件,buffer pool->磁盘; 日志文件,buffer pool->os buffer->磁盘;
# 默认值为空,建议值:使用SAN或者raid,建议用O_DIRECT,不懂测试的话,默认生产上使用O_DIRECT
innodb_flush_method = O_DIRECT
# 说明:mysql5.7之后默认开启,意思是,每张表一个独立表空间。
# 默认值1,开启
innodb_file_per_table = 1
# 说明:The path where InnoDB creates undo tablespaces.通常等于undo log文件的存放目录。
# 默认值./;自行设置
innodb_undo_directory = /usr/local/mysql-5.7.21/log
# 说明:The number of undo tablespaces used by InnoDB.等于undo log文件数量。5.7.21后开始弃用
# 默认值为0,建议默认值就好,不用调整了。
innodb_undo_tablespaces = 0
# 说明:定义undo使用的回滚段数量。5.7.19后弃用
# 默认值128,建议不动,以后弃用了。
innodb_undo_logs = 128
# 说明:5.7.5后开始使用,在线收缩undo log使用的空间。
# 默认值:关闭,建议值:开启
innodb_undo_log_truncate = 1
# 说明:结合innodb_undo_log_truncate,实现undo空间收缩功能
# 默认值:1G,建议值,不改。
innodb_max_undo_log_size = 1G
# 说明:重作日志文件的存放目录
innodb_log_group_home_dir = /usr/local/mysql-5.7.21/log
# 说明:日志文件的大小
# 默认值:48M,建议值:根据你系统的磁盘空间和日志增长情况调整大小
innodb_log_file_size = 128M
# 说明:日志组中的文件数量,mysql以循环方式写入日志
# 默认值2,建议值:根据你系统的磁盘空间和日志增长情况调整大小
innodb_log_files_in_group = 3
# 此参数确定些日志文件所用的内存大小,以M为单位。缓冲区更大能提高性能,但意外的故障将会丢失数据。MySQL开发人员建议设置为1-8M之间
innodb_log_buffer_size = 16M
# 说明:可以控制log从系统buffer刷入磁盘文件的刷新频率,增大可减轻系统负荷
# 默认值是1;建议值不改。系统性能一般够用。
innodb_flush_log_at_timeout = 1
# 说明:参数可设为0,1,2;
# 参数0:表示每秒将log buffer内容刷新到系统buffer中,再调用系统flush操作写入磁盘文件。
# 参数1:表示每次事物提交,将log buffer内容刷新到系统buffer中,再调用系统flush操作写入磁盘文件。
# 参数2:表示每次事物提交,将log buffer内容刷新到系统buffer中,隔1秒后再调用系统flush操作写入磁盘文件。
innodb_flush_log_at_trx_commit = 1
# 说明:限制Innodb能打开的表的数据,如果库里的表特别多的情况,请增加这个。
# 值默认是2000,建议值:参考数据库表总数再进行调整,一般够用不用调整。
innodb_open_files = 8192
# innodb处理io读写的后台并发线程数量,根据cpu核来确认,取值范围:1-64
# 默认值:4,建议值:与逻辑cpu数量的一半保持一致。
innodb_read_io_threads = 4
innodb_write_io_threads = 4
# 默认设置为 0,表示不限制并发数,这里推荐设置为0,更好去发挥CPU多核处理能力,提高并发量
innodb_thread_concurrency = 0
# 默认值为4,建议不变。InnoDB中的清除操作是一类定期回收无用数据的操作。mysql 5.5之后,支持多线程清除操作。
innodb_purge_threads = 4
# 说明:mysql缓冲区分为new blocks和old blocks;此参数表示old blocks占比;
# 默认值:37,建议值,一般不动
innodb_old_blocks_pct = 37
# 说明:新数据被载入缓冲池,进入old pages链区,当1秒后再次访问,则提升进入new pages链区。
# 默认值:1000
innodb_old_blocks_time=1000
# 说明:开启异步io,可以提高并发性,默认开启。
# 默认值为1,建议不动
innodb_use_native_aio = 1
# 说明:默认为空,使用data目录,一般不改。
innodb_data_home_dir=/usr/local/mysql-5.7.21/data
# 说明:Defines the name, size, and attributes of InnoDB system tablespace data files.
# 默认值,不指定,默认为ibdata1:12M:autoextend
innodb_data_file_path = ibdata1:12M:autoextend
# 说明:设置了InnoDB存储引擎用来存放数据字典信息以及一些内部数据结构的内存空间大小,除非你的数据对象及其多,否则一般默认不改。
# innodb_additional_mem_pool_size = 16M
# 说明:The crash recovery mode。只有紧急情况需要恢复数据的时候,才改为大于1-6之间数值,含义查下官网。
# 默认值为0;
#innodb_force_recovery = 0
##########################################################################################################
# 其他。。。。
# 参考http://www.kuqin.com/database/20120815/328905.html
# skip-external-locking
# 禁止MySQL对外部连接进行DNS解析,使用这一选项可以消除MySQL进行DNS解析的时间。
# 缺点:所有远程主机连接授权都要使用IP地址方式,因为只认得ip地址了。
# skip_name_resolve = 0
# 默认值为off,timestamp列会自动更新为当前时间,设置为on|1,timestamp列的值就要显式更新
explicit_defaults_for_timestamp = 1
[mysqldump]
# quick选项强制 mysqldump 从服务器查询取得记录直接输出而不是取得所有记录后将它们缓存到内存中
quick
max_allowed_packet = 16M
[mysql]
# mysql命令行工具不使用自动补全功能,建议还是改为
# no-auto-rehash
auto-rehash
socket = /tmp/mysql.sock
(四)操作
操作一:修改my.cnf 配置文件
max_connections = 10000
max_connect_errors = 10000
open_files_limit = 65535
#20200304新增参数 该参数是myssql 5.6后引入的,目的是提高并发。
# 默认值1,建议值:cpu核数,并且<=16
table_open_cache_instances = 4重启数据库,使生效
service mysql restart操作二:由此可见最大的变13万行数据,而建的表没有添加索引,CPU可像而知.
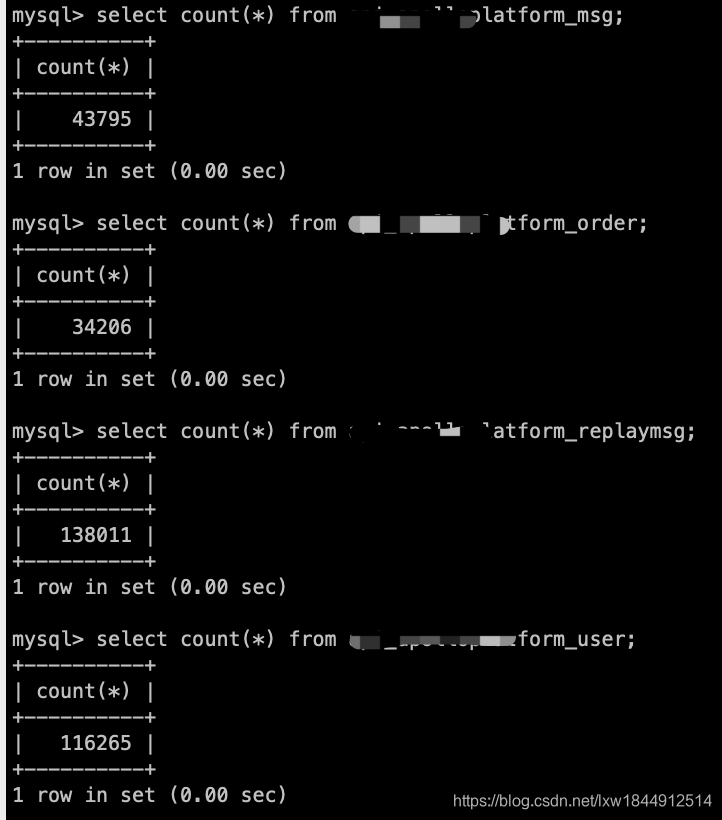
所以,需要给数据表添加索引,将数据表导入本地(可忽略)
1. 导出一个表
mysqldump -u 用户名 -p 数据库名 表名> 导出的文件名
mysqldump -u dbuser -p dbname users> dbname_users.sql
2.导入数据(注意sql文件的路径)
mysql>source /home/abc/abc.sql;
方法二:
mysql -u用户名 -p密码 数据库名 < 数据库名.sql
#mysql -uabc_f -p abc < abc.sql添加索引:
#创建普通的索引
alter table `table_name` add index `index_name` (`字段名`)
#创建主键索引
alter table `table_name` add primary key (`字段名`)
#创建 唯一索引
alter table `table_name` add unique (`字段名`)
#创建全文的索引
alter table `table_name` add fulltext (`字段名`)
#创建多个索引
alter table `table_name` add index `index_Name`(`column`,`column1`,`column_N`.......)
下面是删除索引的语句
drop index `index_name` on `table_name`
alter table `table_name` drop index `index_name`

#给api_apolloplatform_user 表添加普通索引
alter table api_apolloplatform_user add index index_account(account);
alter table api_apolloplatform_user add index index_platformInfo(platformInfo);下面是添加索引的优缺点:(可以掌握下)
优点:
可能有人知道索引的作用的是什么,例如知道索引可以提高查询效率,减少查询时编列全表,或者说,有了索引可按特定的序列进行排序等等。还可以加快表与表之间的连接。 在使用分组和排序子句进行数据检索时,可以显著的减少查询的时间。
缺点:创建了索引,当然就需要我们去维护索引了,维护是需要时间,随着索引的增加而增加。索引还会占用物理空间,我们数据库的数据表是占用物理空间,索引也是要占用一定的空间,而且当时我们需要创建聚集索引的时候消耗就更大了。还有就是我们平时的数据操作了,当我们需要频繁对一张表进行删除,插入操作的时候,索引要动态的变化,消耗很多的性能。
如何查看mysql日志文件位置
登录mysql终端
日志文件路径
mysql> show variables like 'general_log_file';
+------------------+------------------------------------+
| Variable_name | Value |
+------------------+------------------------------------+
| general_log_file | /usr/local/mysql/data/localhost.log |
+------------------+------------------------------------+
1 row in set (0.00 sec)错误日志文件路径
mysql> show variables like 'log_error';
+---------------+------------------------------------+
| Variable_name | Value |
+---------------+------------------------------------+
| log_error | /usr/local/mysql/data/localhost.err |
+---------------+------------------------------------+
1 row in set (0.00 sec)慢查询日志文件路径
mysql> show variables like 'slow_query_log_file';
+---------------------+-----------------------------------------+
| Variable_name | Value |
+---------------------+-----------------------------------------+
| slow_query_log_file | /usr/local/mysql/data/localhost-slow.log |
+---------------------+-----------------------------------------+
1 row in set (0.01 sec)
参考:https://www.cnblogs.com/jimmyshan-study/p/11013662.html
https://www.cnblogs.com/wyy123/p/9258513.html
https://blog.csdn.net/lqzhang_11/article/details/81543350
发布者:全栈程序员-用户IM,转载请注明出处:https://javaforall.cn/111894.html原文链接:https://javaforall.cn
【正版授权,激活自己账号】: Jetbrains全家桶Ide使用,1年售后保障,每天仅需1毛
【官方授权 正版激活】: 官方授权 正版激活 支持Jetbrains家族下所有IDE 使用个人JB账号...
